
문제 7. 아래의 ERD 에 대한 반정규화 기법으로 적절하지 않은 것은?
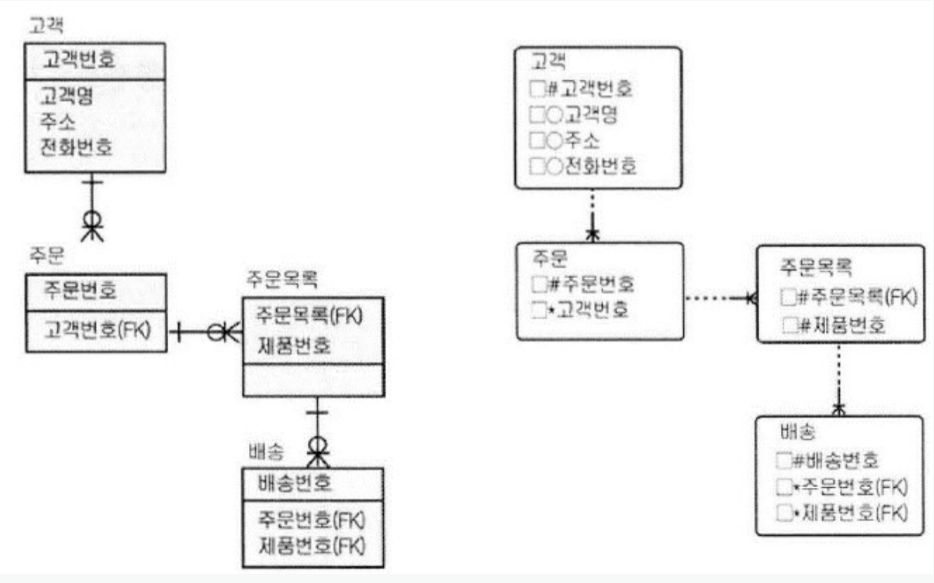
1) 배송 테이블에서 고객의 정보를 찾는 빈도가 높을 경우 고객과 배송 테이블의 관계를 추가하는 관계의 반정규화를 한다.
2) 주문목록 테이블에서 고객이 정보를 찾는 빈도가 높을 경우 고객과 주문 테이블의 비식별자 관계를 식별자 관계로 한다.
3) 주문 테이블에서 항상 고객명을 같이 조회하는 경우 고객 테이블의 고객명을 주문 테이블에 넣컬럼의 반정규화를 한다.
4) 주문과 주문목록, 배송 테이블의 모든 컬럼을 고객 (최상위 테이블) 테이블에 모두 넣는 반정규화를 한다.
문제 7 정답
정답 : 4
문제 7 해설
반정규화는 데이터베이스 설계에서 성능 향상, 조회 성능 최적화, 관리의 편의성을 목적으로 데이터 중복을 허용하고, 정규화된 데이터 모델을 재구성하는 과정입니다. 반정규화를 잘못 적용하면 데이터 무결성 문제나 업데이트 시의 복잡성 증가와 같은 부작용이 발생할 수 있습니다.
이 문제에서 각 옵션을 살펴보겠습니다:
1) 관계의 반정규화: 고객 정보와 배송 정보가 자주 함께 조회될 경우, 두 테이블 사이에 직접적인 관계를 추가하여 성능을 향상시킬 수 있습니다. 이는 적절한 반정규화 기법 중 하나입니다.
2) 비식별자 관계를 식별자 관계로 변경: 이는 특정 상황에서 조회 성능을 향상시키기 위해 적용할 수 있는 방법입니다. 고객과 주문 테이블 간의 관계를 더 명확하게 식별 가능하게 만들어, 데이터 접근성을 개선할 수 있습니다. ✏️
3) 컬럼의 반정규화: 주문 테이블에서 항상 고객명을 함께 조회한다면, 고객명을 주문 테이블에 추가하는 것은 조회 성능 최적화를 위해 적절할 수 있습니다. 이는 반정규화의 흔한 예시 중 하나입니다.
4) 모든 컬럼을 상위 테이블에 통합: 이 옵션은 고객 테이블에 주문, 주문목록, 배송 테이블의 모든 컬럼을 넣는 것을 제안합니다. 이는 심각한 데이터 중복을 초래하고, 업데이트 시 복잡성과 데이터 무결성 문제를 발생시킬 수 있는 매우 비효율적이고 극단적인 방법입니다. 관리와 업데이트가 매우 복잡해지며, 실제 환경에서는 권장되지 않는 접근 방식입니다.
따라서, 적절하지 않은 반정규화 기법은 4번입니다. 4번은 데이터의 중복을 극도로 높이고, 데이터 무결성을 유지하기 어렵게 만들며, 관리의 복잡성을 대폭 증가시키는 방법이기 때문입니다.
비식별자 관계를 식별자 관계로 변경 ✏️
비식별자 관계와 식별자 관계는 데이터베이스 설계에서 테이블 간의 관계를 정의할 때 사용하는 두 가지 방법입니다. 이 두 방법의 차이점을 이해하는 것은 데이터 모델링에서 중요합니다.
비식별자 관계 (Non-Identifying Relationship)
- 정의: 비식별자 관계에서는 한 테이블이 다른 테이블의 기본 키를 외래 키로 포함하지만, 이 외래 키가 자식 테이블의 기본 키 구성 요소가 아닌 경우를 말합니다.
- 특징: 외래 키가 NULL이 될 수 있으며, 자식 테이블의 레코드가 부모 테이블의 특정 레코드와 관련이 없을 수 있습니다.
- 예시: 고객 테이블과 주문 테이블 간의 관계에서, 주문 테이블에는 고객 ID가 외래 키로 포함되어 고객 정보를 참조하지만, 주문 테이블의 각 레코드는 반드시 고객 ID를 포함하지 않아도 됩니다(예: 익명 주문).
식별자 관계 (Identifying Relationship)
- 정의: 식별자 관계에서는 한 테이블의 기본 키가 다른 테이블의 기본 키 구성 요소로 포함되는 관계입니다. 이는 부모 테이블의 기본 키가 자식 테이블의 기본 키에 직접적으로 기여하는 경우를 말합니다.
- 특징: 외래 키가 항상 자식 테이블의 기본 키 일부이며, NULL이 될 수 없습니다. 이는 자식 테이블의 레코드가 반드시 특정 부모 레코드와 연관되어야 함을 의미합니다.
- 예시: 주문 테이블이 고객 ID를 기본 키의 일부로 사용하여 각 주문이 특정 고객에게 속해 있음을 명확히 식별하는 경우.
비식별자 관계를 식별자 관계로 변경하는 이유
- 데이터 무결성 보장: 식별자 관계는 자식 테이블의 레코드가 반드시 부모 테이블의 특정 레코드와 연관되어 있도록 함으로써 데이터 무결성을 강화합니다.
- 조회 성능 향상: 자식 테이블에서 부모 테이블로의 조인 연산이 자주 발생하는 경우, 식별자 관계는 이러한 조인 연산의 성능을 향상시킬 수 있습니다. 왜냐하면 관계가 데이터 구조에 더 명확하게 정의되어 있기 때문입니다.
- 데이터 모델의 명확성: 식별자 관계는 데이터 모델을 더 명확하게 만들어, 개발자와 데이터 분석가가 시스템을 이해하기 쉽게 합니다.
비식별자 관계를 식별자 관계로 변경하는 것은 특정 상황에서 매우 유용할 수 있지만, 데이터 모델의 복잡성과 무결성 요구 사항을 신중하게 고려해야 합니다. 변경으로 인해 데이터베이스 설계가 더 복잡해지거나, 특정 요구 사항
(예: 익명 사용자의 데이터 처리)을 만족시키기 어려워질 수 있기 때문입니다.
문제 12. 다음의 SCRIPT 를 수행한 후 보기의 SQL 을 수행할 때 잘못된 것은?
<SCRIPT>
CREATE TABLE SQLD_34_12 (N1 NUMBER, N2 NUMBER);
INSERT INTO SQLD_34_12 VALUES (1,10);
INSERT INTO SQLD_34_12 VALUES (2,20);1) SELECT N1 FROM SQLD_34_12 ORDER BY N2;
2) SELECTFROM SQLD_34_12 ORDER BY 2;
3) SELECT N1 FROM (SELECTFROM SQLD_34_12) ORDER BY N2;
4) SELECT N1 FROM (SELECT*FROM SQLD_34_12) ORDER BY 2;
문제 12 정답
정답 : 4 ✔️
- 맞춘 문제지만 햇갈려서 넣었다.
- select에 없는 컬럼이어도 from 절에 있는 컬럼이면 문제 없다.
- 그러나 2개의 컬럼이 있을 때 3번 컬럼으로 조회하라는 명령은 오류난다.
문제 13. PROCEDURE, TRIGGER 에 대한 설명 중 가장 잘못된 것은?
1) PROCEDURE, TRIGGER 모두 EXECUTE 명령어로 수행된다.
2) PROCEDURE, TRIGGER 모두 CREATE 명령어로 생성한다.
3) PROCEDURE 는 COMMIT, ROLLBACK 명령어를 사용할 수 있다.
4) TRIGGER 는 COMMIT, ROLLBACK 명령어를 사용할 수 없다.
문제 13 정답
정답 : 1
문제 13 해설

문제에서 주어진 선택지들 중 가장 잘못된 것에 대해 설명하겠습니다:
1) PROCEDURE, TRIGGER 모두 EXECUTE 명령어로 수행된다.
- 이 설명은 부분적으로 잘못되었습니다. 프로시저는 EXECUTE 또는 CALL 명령어로 직접 수행될 수 있습니다. 반면에, 트리거는 데이터베이스에서 특정 이벤트(예: 테이블에 대한 INSERT, UPDATE, DELETE)가 발생할 때 자동으로 실행되므로, 사용자가 EXECUTE 명령어로 직접 수행하지 않습니다.
2) PROCEDURE, TRIGGER 모두 CREATE 명령어로 생성한다.
- 이 설명은 정확합니다. 프로시저와 트리거 모두 CREATE PROCEDURE, CREATE TRIGGER 명령어를 사용하여 생성됩니다.
3) PROCEDURE 는 COMMIT, ROLLBACK 명령어를 사용할 수 있다.
- 이 설명은 정확합니다. 프로시저 내부에서는 트랜잭션을 관리하는 COMMIT과 ROLLBACK 명령어를 사용할 수 있습니다.
4) TRIGGER 는 COMMIT, ROLLBACK 명령어를 사용할 수 없다.
- 이 설명도 기본적으로 정확합니다. 트리거 내에서는 일반적으로 COMMIT과 ROLLBACK 명령어를 사용할 수 없습니다. 트리거는 이미 진행 중인 트랜잭션의 일부로 실행되며, 트리거가 자체적으로 트랜잭션을 제어하는 것은 데이터 무결성을 위협할 수 있기 때문입니다. 하지만, 일부 데이터베이스 시스템에서는 특정 조건 하에서 트리거 내에서 COMMIT과 ROLLBACK을 사용할 수 있는 방법을 제공할 수도 있습니다. 그러나 표준적인 접근법은 아닙니다.
따라서, 가장 잘못된 설명은 1번입니다. 트리거는 사용자가 EXECUTE 명령어로 직접 실행할 수 없으며, 대신 특정 데이터베이스 이벤트에 의해 자동으로 실행됩니다.
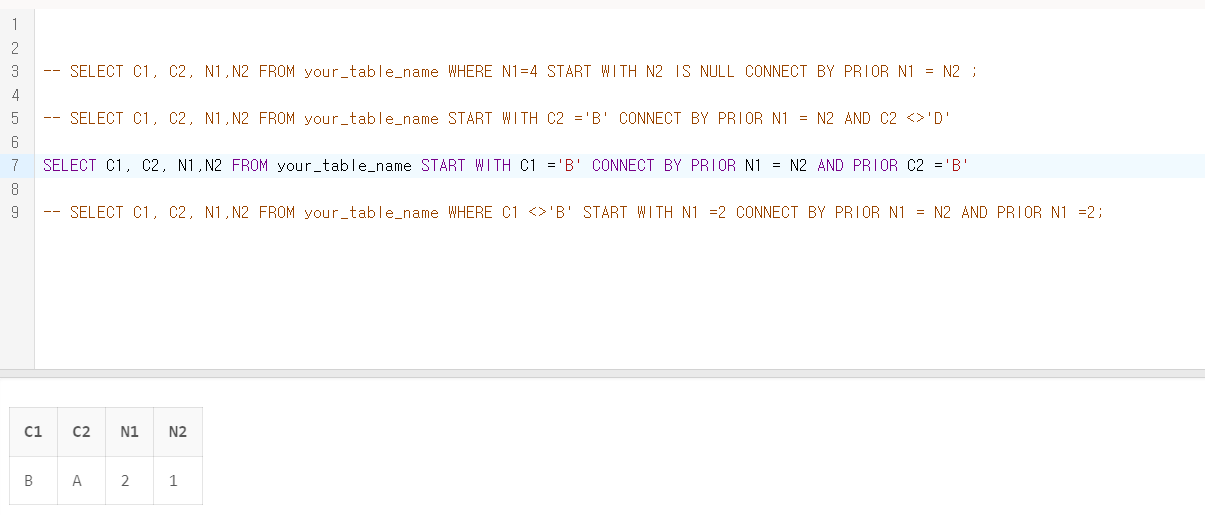
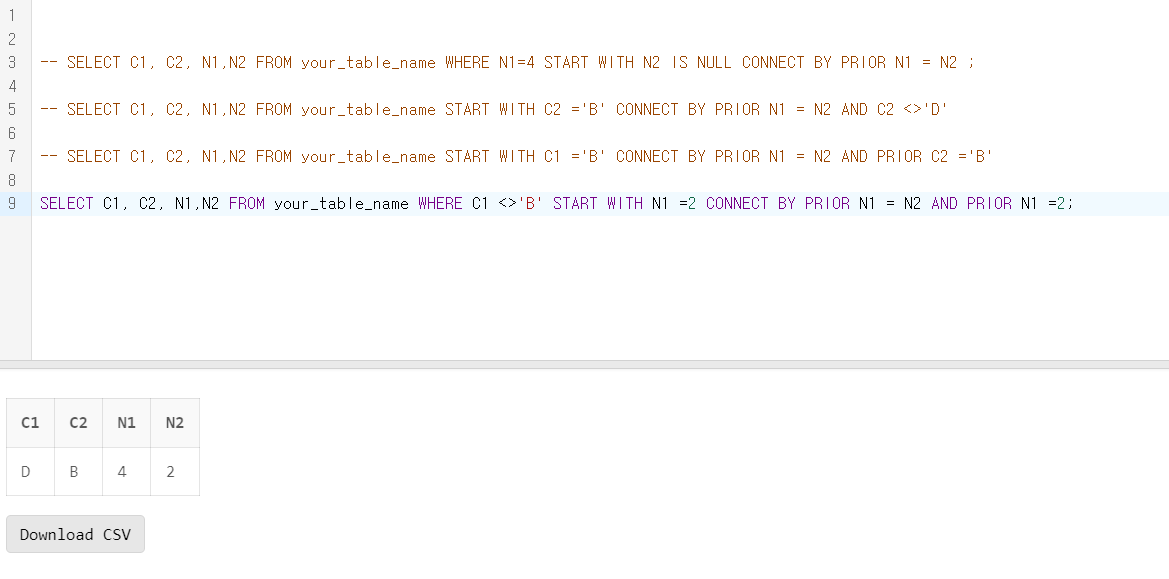
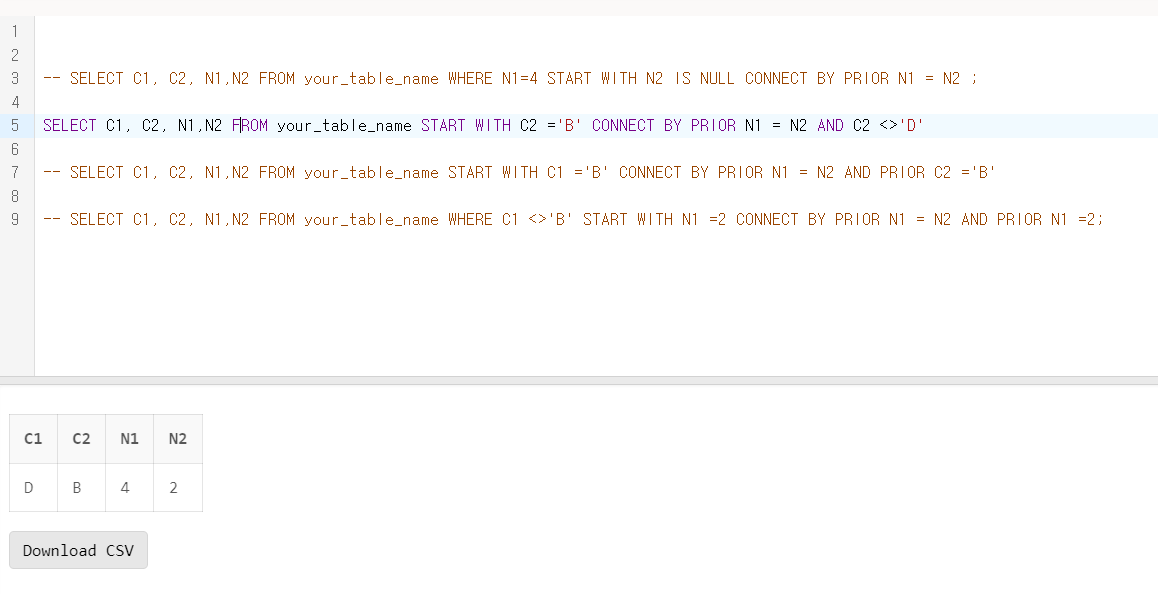
문제 19. 아래의 테이블에 대한 SQL중 결과가 다른 하나는 무엇인가?
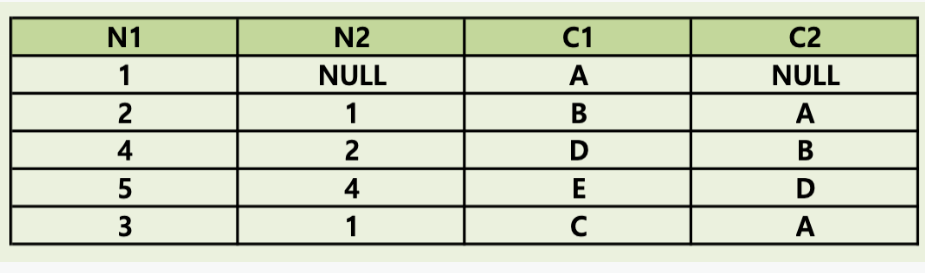
1) SELECT C1, C2, N1,N2 FROM SQLD_34_19 WHERE N1=4 START WITH N2 IS NULL CONNECT BY PRIOR N1 = N2 ;
2) SELECT C1, C2, N1,N2 FROM SQLD_34_19 START WITH C2 ='B' CONNECT BY PRIOR N1 = N2 AND C2 <>'D'
3) SELECT C1, C2, N1,N2 FROM SQLD_34_19 START WITH C1 ='B' CONNECT BY PRIOR N1 = N2 AND PRIOR C2 ='B'
4) SELECT C1, C2, N1,N2 FROM SQLD_34_19 WHERE C1 <>'B' START WITH N1 =2 CONNECT BY PRIOR N1 = N2 AND PRIOR N1 =2;
문제 19 정답
- 3번
직접 해보면, 🚀
문제 23. 아래의 테이블에 대한 SQL 결과로 올바른 것은?
<SQL>
SELECT COUNT(*)
FROM SQLD_34_23
HAVING COUNT(*) > 41) 공집합이다 (0 Rows)
2) 0
3) 1
4) 2
문제 23 정답
정답: 1
문제 23 해설
SQL에서 HAVING 절은 보통 GROUP BY 절과 함께 사용되어 그룹화 된 결과에 대한 조건을 제공합니다. HAVING 절이 단독으로 사용될 때, 그것은 GROUP BY 절이 생략된 것으로 간주되며 전체 결과 집합에 대해 조건을 적용합니다.
제공된 SQL 쿼리는:
SELECT COUNT(*)
FROM SQLD_34_23
HAVING COUNT(*) > 4이 쿼리는 SQLD_34_23 테이블의 전체 행 수를 계산하고, 그 수가 4보다 클 경우에만 결과를 반환하도록 요청합니다. GROUP BY 절이 없으므로, 전체 테이블에 대한 단일 행 카운트만 반환됩니다.
- 옵션 1) 공집합이다 (0 Rows): 테이블에 4개 이상의 행이 없다면,
COUNT(*)는 4보다 큰 값을 반환하지 않으므로 결과는 공집합이 됩니다. - 옵션 2) 0: 이는
COUNT(*)의 결과가 아니며, 유효한 출력이 아닙니다.HAVING절이 참이 아니면 아무것도 반환하지 않습니다. - 옵션 3) 1: 테이블에 4개 이상의 행이 있으면,
COUNT(*)는 4보다 큰 값을 반환하고, 이 경우 쿼리는 단일 행 결과(전체 행 수)를 반환합니다. - 옵션 4) 2: 이 결과는 유효하지 않습니다.
COUNT(*)는 전체 행 수를 반환하고HAVING조건에 의해 결과가 필터링됩니다. 단일 집계 결과만 반환되므로 결과 행 수가 2일 수는 없습니다.
테이블에 5개 이상의 행이 있는 경우 쿼리는 행 수를 반환합니다(즉, COUNT(*)의 결과는 1). 테이블에 4개 이하의 행이 있다면 쿼리는 아무 것도 반환하지 않습니다(즉, 공집합).
문제 25. 아래의 테이블에 대한 SELECT 결과 건수로 알맞은 것은?
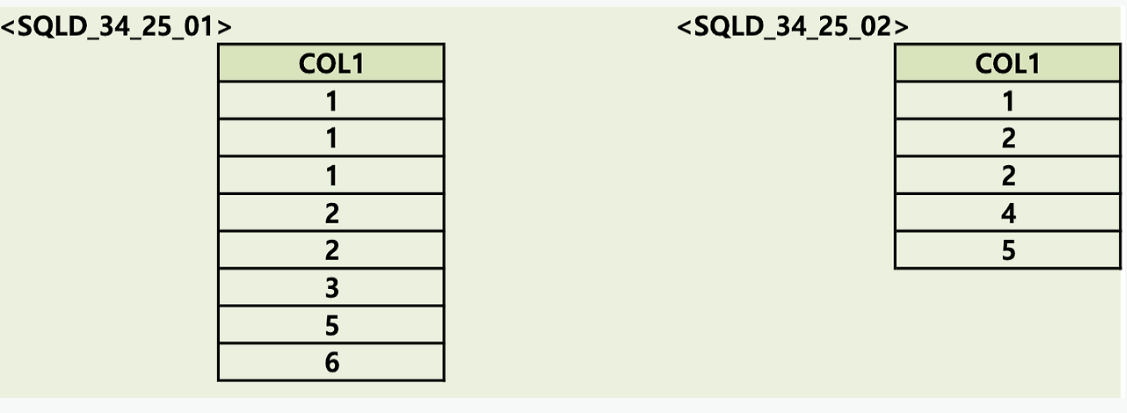
<SQL>
SELECT DISTINCT COL1
FROM SQLD_34_25_01
UNION ALL
SELECT COL1
FROM SQLD_34_25_021) 4
2) 6
3) 8
4) 10
문제 25 정답
정답 : 4
해설 : UNION ALL (합집합)
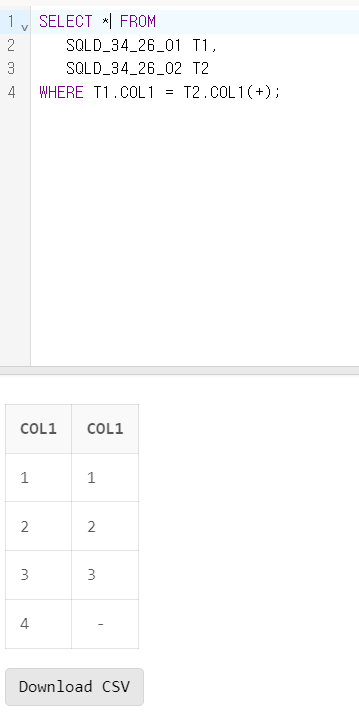
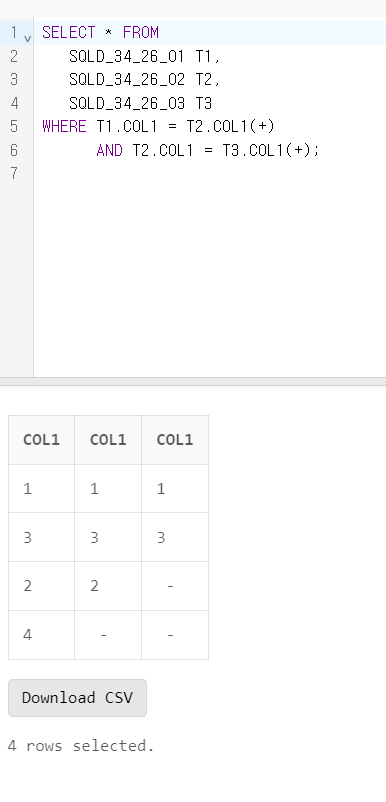
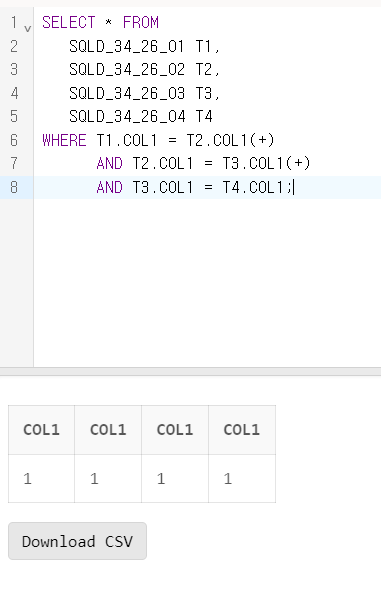
문제 26. 아래와 같은 테이블이 있다. 스크립트를 수행한 후의 결과로 가장 올바른 것은?
<SQLD_34_26_01> <SQLD_34_26_02> <SQLD_34_26_03> <SQLD_34_26_04>
COL1 COL1 COL1 COL1
---- ---- ---- ----
1 1 1 1
2 2 NULL 2
3 3 3 5
4 NULL 5 6
<SQL>
SELECT COUNT(*) FROM
SQLD_34_26_01 T1,
SQLD_34_26_02 T2,
SQLD_34_26_03 T3,
SQLD_34_26_04 T4
WHERE T1.COL1 = T2.COL1(+)
AND T2.COL1 = T3.COL1(+)
AND T3.COL1 = T4.COL1;1) 1
2) 2
3) 3
4) 4
문제 26 정답
정답 : 1
문제 26 해설
이 SQL 쿼리는 Oracle SQL에서 구식 조인 문법을 사용하여 네 개의 테이블(SQLD_34_26_01, SQLD_34_26_02, SQLD_34_26_03, SQLD_34_26_04)을 조인하는 것입니다. (+) 기호는 오라클에서 아우터 조인을 나타냅니다.
우리가 이해해야 할 핵심은 다음과 같습니다:
T1.COL1 = T2.COL1(+)는T1이T2와 왼쪽 아우터 조인을 수행한다는 것을 의미합니다.T2테이블의COL1에 해당하는 값이 없는 경우 NULL이 허용됩니다.T2.COL1 = T3.COL1(+)는T2가T3와 왼쪽 아우터 조인을 수행한다는 것을 의미합니다. 여기서도T3의COL1에 해당하는 값이 없으면 NULL이 허용됩니다.T3.COL1 = T4.COL1는T3와T4사이의 내부 조인을 나타냅니다. 여기서는 두 테이블 모두 일치하는 값이 있어야 결과에 나타납니다.
이제 조인된 결과의 개수를 계산해야 합니다.
먼저, T1과 T2 사이에는 COL1 값 1, 2, 3에 대한 매칭이 있습니다. T2에 NULL 값이 있지만 아우터 조인 때문에 T1의 값은 여전히 포함됩니다.
다음으로, T2와 T3 사이에서도 아우터 조인이 수행되고 있습니다. T2의 1, 2, 3 값이 T3의 1, NULL, 3과 매칭됩니다. 이 경우, T2의 2는 T3에 해당하는 값이 없으므로 조인 결과에 포함되지 않습니다.
마지막으로, T3와 T4 사이의 조인은 내부 조인입니다. T3의 값 1, NULL, 3은 T4의 1, 2, 5, 6과 매칭됩니다. 여기서 오직 T3의 1만이 T4의 1과 매칭됩니다.
따라서, 최종 결과는 T1, T2, T3, T4의 COL1이 모두 1인 단일 행이 됩니다. 그러므로 올바른 답변은 1) 1입니다.
직접 해보기 🚀
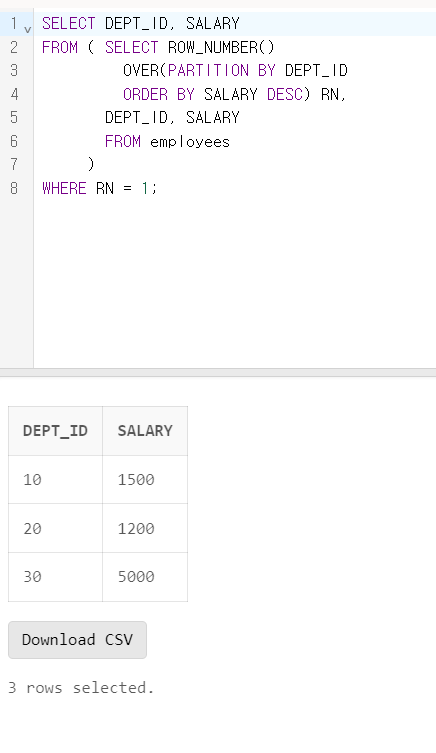
문제 27. 아래 테이블에 대해 수행된 SQL결과와 보기의 SQL의 결과가 같은 것으로 올바른 것은?
<SQLD_34_27>
<SQL>
SELECT DEPT_ID, SALARY
FROM ( SELECT ROW_NUMBER()
OVER(PARTITION BY DEPT_ID
ORDER BY SALARY DESC) RN,
DEPT_ID, SALARY
FROM SQLD_34_27
)
WHERE RN = 1;1)
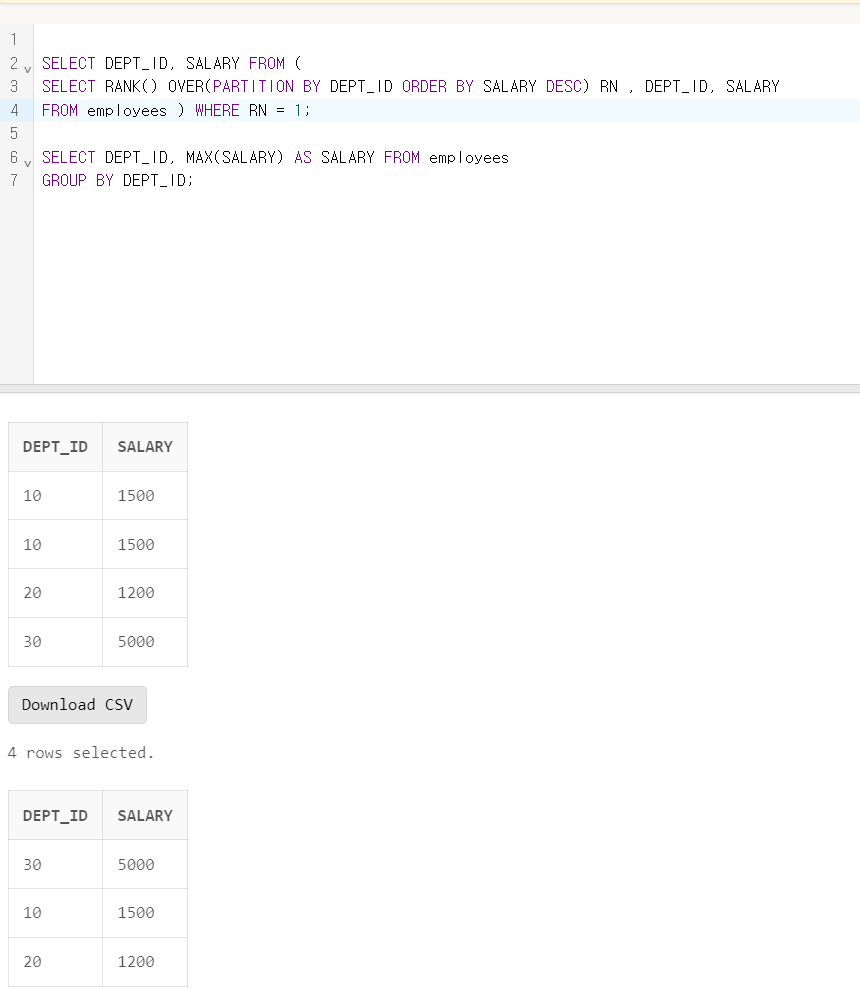
SELECT DEPT_ID, SALARY FROM (
SELECT RANK() OVER(PARTITION BY DEPT_ID ORDER BY SALARY DESC) RN , DEPT_ID, SALARY
FROM SQLD_34_27 ) WHERE RN = 1
2)
SELECT DEPT_ID, MAX(SALARY) AS SALARY FROM SQLD_34_27
GROUP BY DEPT_ID
3)
SELECT DEPT_ID, SALARY
FROM SQLD_34_27
WHERE ROWNUM =1
ORDER BY DEPT_ID, SALARY DESC ;
4)
SELECT DEPT_ID, SALARY
FROM SQLD_34_27
WHERE SALARY = (SELECT MAX(SALARY) FROM SQLD_34_27 )
문제 27 정답
정답: 2
문제 27 직접 해보기
- 지문
- 보기(가장 헷갈렸던 둘)
문제 28. 순번을 구하는 그룹함수가 아닌 것은?
1) RANK
2) ROW_NUMBER
3) DENSE_RANK
4) RATIO_TO_REPORT
문제 28 정답
정답 : 4
해설 : RATIO_TO_REPORT (전체 SUM값에 대한 행별 칼럼값, 0~1 사이값)
문제 30. 아래의 SQL을 ORACLE 과 SQL SERVER에서 수행할 때 SQL에 대해 틀린 설명은? (AUTO COMMIT은 FALSE로 설정)
<SCRIPT>
UPDATE SQLD_34_30 SET N1=3 WHERE N2=1;
CREATE TABLE SQLD_34_30_TEMP (N1 NUMBER);
ROLLBACK;1) SQL SERVER 의 경우 ROLLBACK 이 된 후 UPDATE 와 CREATE 구문 모두 취소된다
2) SQL SERVER 의 경우 ROLLBACK 이 된 후 SQLD_34_21_TEMP 는 만들어지지 않는다.
3) ORACLE 의 경우 ROLLBACK 이 된 후 UPDATE 와 CREATE 구문 모두 취소된다.
4) ORACLE 의 경우 UPDATE 는 취소되지 않는다.
문제 30 정답
- 정답 : 3
해설 : oracle 의 경우 기본 값이 auto commit off 로 ddl 이 일어날 경우 묵시적 commit 이 됨 (설정 불가), sql server 의 경우 기본 값이 auto commit on 으로 false 가 될 경우 ddl 도 묵시적 commit 이 되지 않음
1) SQL 서버의 경우, AUTO COMMIT 꺼두면 UPDATE, CREATE 모두 취소되고 다시 테이블이 생성되지 않음
2) 오라클은 DDL의 AUTO COMMIT이 기본이기 때문에 CREATE 취소되지 않고, UPDATE도 취소 X
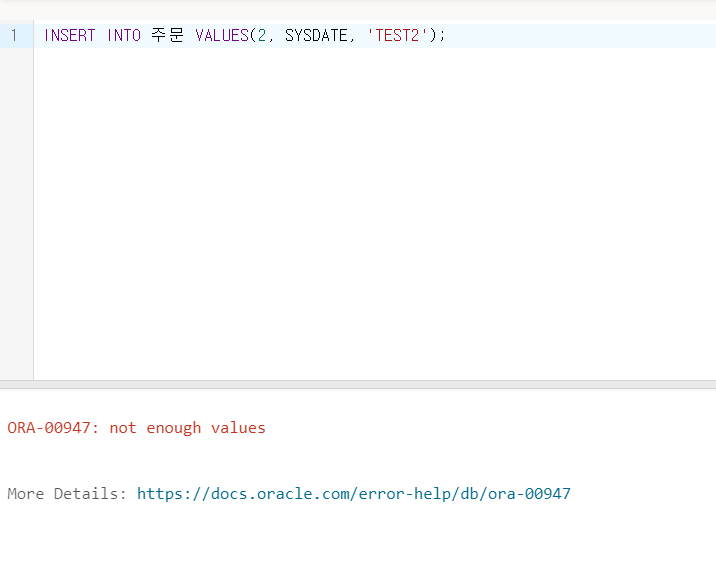
문제 36. 아래의 SQL문을 수행한 결과로 잘못된 것은?
CREATE TABLE 주문 (
C1 NUMBER(10),
C2 DATE,
C3 VARCHAR(10),
C4 NUMBER DEFAULT 100
);
INSERT INTO 주문 (C1,C2,C3) VALUES (1, SYSDATE, 'TEST1');1) INSERT INTO 주문 VALUES(2, SYSDATE, 'TEST2');
2) DELETE 주문
3) DELETE FROM 주문;
4) UPDATE 주문 SET C1=1;
문제 36 정답
정답: 1번
문제 42. 다음중 Window function 에 대한 설명중 적절한 것은?
1) Partition 과 Group By 구문은 의미적으로 완전히 다르다
2) Sum,max, min 등과 같은 집계 window function을 사용할 때 window 절과 함께 사용하면 집계의 대상이 되는 레코드 범위를 지정할 수 있다
3) Window function 처리로 인해 결과 건수가 줄어들 수 있다
4) GROUP BY 구문과 Window function 은 병행하여 사용 할 수 있다
문제 42 정답
2번
윈도우 함수 = 순위 함수
문제 42 해설
Window function(윈도우 함수)은 SQL에서 특정 범위의 행 집합에 대해 계산을 수행하는 함수입니다. 이 함수들은 데이터의 요약, 분석, 레포팅 등을 위해 사용됩니다. 각각의 선택지를 분석해보겠습니다:
1) Partition 과 Group By 구문은 의미적으로 완전히 다르다: 이 설명은 부분적으로 맞고 부분적으로 틀렸습니다. PARTITION BY와 GROUP BY는 데이터를 세분화하는 방식에서 유사성을 가지고 있지만, PARTITION BY는 윈도우 함수 내에서만 사용되며 결과 행의 수를 변경하지 않는 반면, GROUP BY는 집계 함수와 함께 사용되어 결과 집합의 행 수를 줄입니다. 그러나 이 설명만으로는 적절한 것으로 보기 어렵습니다.
2) Sum, max, min 등과 같은 집계 window function을 사용할 때 window 절과 함께 사용하면 집계의 대상이 되는 레코드 범위를 지정할 수 있다: 이 설명은 정확합니다. 윈도우 함수를 사용할 때, WINDOW 절을 통해 특정 행의 집합(예: 현재 행부터 시작하여 이전 10행 등)에 대한 연산을 수행하도록 범위를 지정할 수 있습니다. 따라서, 이는 윈도우 함수의 주요 기능 중 하나를 잘 설명하고 있습니다.
3) Window function 처리로 인해 결과 건수가 줄어들 수 있다: 이 설명은 틀렸습니다. 윈도우 함수는 입력으로 받은 테이블의 행 수를 변경하지 않습니다. 대신, 각 행에 대해 추가적인 계산 결과를 제공합니다. 따라서 윈도우 함수의 사용은 결과 건수의 감소를 일으키지 않습니다.
4) GROUP BY 구문과 Window function은 병행하여 사용할 수 있다: 이 설명도 정확합니다. GROUP BY로 집계된 결과에 대해 윈도우 함수를 적용할 수 있으며, 이를 통해 더 복잡한 데이터 분석과 요약을 수행할 수 있습니다. 예를 들어, 각 그룹 내에서 최댓값을 가진 행을 찾는 등의 작업이 가능합니다.
결론적으로, 이 중에서 적절한 설명은 2) Sum, max, min 등과 같은 집계 window function을 사용할 때 window 절과 함께 사용하면 집계의 대상이 되는 레코드 범위를 지정할 수 있다와 4) GROUP BY 구문과 Window function은 병행하여 사용할 수 있다입니다. 하지만 가장 적절한 하나를 선택해야 한다면, 윈도우 함수의 주요 특징을 잘 설명하고 있는 2번 선택지가 더 적절할 것입니다.
문제 49. 아래와 같은 데이터를 가진 테이블에 대한 SQL을 수행했을 때 결과가 다음과 같다. SQL을 완성하시오.
<SQL>
SELECT VAL, COUNT(*) AS CNT
FROM (
SELECT ( )(4) OVER (ORDER BY COL1) AS VAL
FROM SQLD_34_X7
)
WHERE 1=1
GROUP BY VAL
ORDER BY 1;
문제 49 정답
정답 : NTILE
문제 50. 아래의 SQL 결과를 출력하는 SQL을 완성하시오.
SELECT EMPLOYEE_ID,
DEPARTMENT_ID,
LAST_NAME,
SALARY,
LAG(SALARY, ( )) OVER(PARTITION BY DEPARTMENT_ID ORDER BY SALARY)
AS BEFORE_SALARY
FROM SQLD_50
WHERE EMPLOYEE_ID < 190;
문제 50 정답
정답: 2
LAG? ❓
LAG(expr [,offset] [,default]) OVER([partition_by_clause] order_by_clause)
LEAD(expr [,offset] [,default]) OVER([partition_by_clause] order_by_clause)LAG 함수 : 이전 행의 값을 리턴
LEAD 함수 : 다음 행의 값을 리턴
expr : 대상 컬럼명
offset : 값을 가져올 행의 위치 기본값은 1, 생략가능
default : 값이 없을 경우 기본값, 생략가능
partition_by_clause : 그룹 컬럼명, 생략가능
order_by_clause : 정렬 컬럼명, 필수
기본 사용법
SELECT empno
, ename
, job
, sal
, LAG(empno) OVER(ORDER BY empno) AS empno_prev
, LEAD(empno) OVER(ORDER BY empno) AS empno_next
FROM emp
WHERE job IN ('MANAGER', 'ANALYST', 'SALESMAN')