
문제 5. 다음 보기 중 분산 데이터베이스에 대한 특징으로 부적절한 것은?
1) 지역 자치성, 점증적 시스템 용량이 확장된다.
2) 빠른 응답속도와 통신비용을 절감할 수 있다.
3) 데이터 처리 비용이 증대한다.
4) 데이터 무결성을 보장하고 데이터 보안성이 높아진다.
문제 5 해설
정답: 4
분산 데이터베이스는 여러 위치에 분산되어 있는 데이터베이스 시스템을 말합니다. 이 시스템은 여러 장점을 제공하지만, 각 옵션이 그 특성을 정확히 반영하는지를 평가하는 것이 중요합니다. 각 보기를 분석해 보겠습니다.
1) 지역 자치성, 점증적 시스템 용량이 확장된다.
- 분산 데이터베이스는 각 지역에서 자체적으로 데이터를 관리할 수 있으며, 필요에 따라 시스템의 용량을 점진적으로 확장할 수 있습니다. 따라서 이는 분산 데이터베이스의 특징으로 적절합니다.
2) 빠른 응답속도와 통신비용을 절감할 수 있다.
- 사용자가 가까운 위치에서 데이터에 접근할 수 있기 때문에, 응답 속도가 빨라지고 통신 비용이 절감될 수 있습니다. 이 역시 분산 데이터베이스의 장점 중 하나입니다.
3) 데이터 처리 비용이 증대한다.
- 분산 데이터베이스는 데이터를 여러 위치에 분산하여 저장하기 때문에, 일관성을 유지하고 통합 관리하는 데 추가적인 비용이 발생할 수 있습니다. 그러나 이는 필연적으로 증대된다기보다는 관리 및 설계에 따라 달라질 수 있습니다. 분산 처리 시스템의 설계와 최적화에 따라 오히려 전체적인 데이터 처리 비용을 줄일 수도 있습니다. 그러므로 이 옵션은 부분적으로만 적절할 수 있습니다.
4) 데이터 무결성을 보장하고 데이터 보안성이 높아진다.
- 분산 데이터베이스는 데이터 무결성과 보안성을 강화할 수 있는 기능을 제공하지만, 이는 자동으로 보장되는 것은 아닙니다. 오히려 여러 위치에 데이터를 분산 저장함으로써, 무결성 유지와 보안성 확보를 위한 추가적인 노력이 필요할 수 있습니다. 따라서, 이는 분산 데이터베이스의 잠재적인 이점으로 볼 수 있지만, 자동으로 보장되는 특성은 아닙니다.
이 분석을 통해 볼 때, 각 보기가 분산 데이터베이스의 특징을 대체로 잘 반영하고 있으나, "3) 데이터 처리 비용이 증대한다"는 상황에 따라 다를 수 있으므로, 이 보기가 상대적으로 부적절할 수 있습니다. 그러나 분산 데이터베이스 시스템의 설계와 운영 방법에 따라 데이터 처리 비용이 증가할 수도 있고, 효율성이 높아질 수도 있어서, 정답을 판단하는 데 있어 맥락을 고려해야 합니다. 보편적으로 분산 데이터베이스에 대한 이해를 바탕으로 한다면, 이 질문은 다소 모호할 수 있으며, 전문가의 해석에 따라 답변이 달라질 수 있습니다.
문제 11. 아래의 ANSI JOIN SQL에서 가장 올바르지 않은 것은?
1) SELECT EMP.DEPTNO, EMPNO, ENAME, DNAME FROM EMP INNER JOIN DEPT ON EMP.DEPTNO = DEPT.DEPTNO;
2) SELECT EMP.DEPTNO, EMPNO, ENAME, DNAME FROM EMP NATURAL JOIN DEPT;
3) SELECT*FROM DEPT JOIN DEPT_TEMP USING(DEPTNO);
4) SELECT E.EMPNO, E.ENAME, D.DEPTNO, D.DNAME FROM EMP E INNER JOIN DEPT D ON (E.DEPTNO = D.DEPTNO);
문제 11 해설
- 정답 : 2
해설 : NATURAL JOIN에서 EMP.DEPTNO와 같이 OWNER 명을 사용하면 에러 발생
문제 13. UNION에 대한 설명 중 바른 것은?
1) 데이터의 중복 행을 제거한다.
2) 데이터의 중복 행을 포함한다.
3) 정렬 작업을 수행하지 않는다.
4) 두 테이블에 모두 포함된 행을 검색한다.
문제 13 해설
- 정답 : 1
- 해설 : UNION은 중복된 행을 제거하고 정렬한다. UNION ALL은 합집합
문제 13 해설 2
UNION에 대한 설명 중 바른 것을 찾기 위해서는, UNION의 기본적인 특성을 이해해야 합니다.
-
1) 데이터의 중복 행을 제거한다.
- 바른 설명: SQL에서
UNION연산자는 두 개 이상의SELECT문의 결과 집합을 합칠 때 사용됩니다. 이 과정에서 중복되는 행은 자동으로 제거되어, 결과 집합에는 각각의 고유한 행만 포함됩니다. 따라서, 이 설명은UNION에 대해 바르게 설명하고 있습니다.
- 바른 설명: SQL에서
-
2) 데이터의 중복 행을 포함한다.
- 잘못된 설명: 이 설명은
UNION ALL연산자의 특성에 해당됩니다.UNION ALL은UNION과 달리 중복된 행을 제거하지 않고 모든 행을 포함하여 결과 집합을 반환합니다.
- 잘못된 설명: 이 설명은
-
3) 정렬 작업을 수행하지 않는다.
- 잘못된 설명:
UNION연산을 수행할 때, SQL 서버는 결과 집합의 중복을 제거하기 위해 내부적으로 정렬 작업을 수행할 수 있습니다. 따라서, 이 설명은 정확하지 않습니다. 사용자가ORDER BY를 명시적으로 사용하지 않더라도, 중복 제거 과정에서 내부적인 정렬이 일어날 수 있습니다.
- 잘못된 설명:
-
4) 두 테이블에 모두 포함된 행을 검색한다.
- 잘못된 설명: 이 설명은
INNER JOIN또는INTERSECT연산의 특성에 더 가깝습니다.UNION은 두 개 이상의 쿼리 결과를 합치는데, 각 쿼리 결과에 있는 모든 고유 행을 포함합니다. 반면, 두 테이블에 모두 포함된 행만을 검색하는 것은INNER JOIN이나INTERSECT연산의 기능입니다.
- 잘못된 설명: 이 설명은
따라서, 이 중에서 UNION에 대한 설명으로 가장 바른 것은 1) 데이터의 중복 행을 제거한다입니다.
문제 26. 다음 중 데이터 무결성을 보장하기 위한 방법으로 가장 부적절한 것은?
1) 애플리케이션
2) Trigger
3) Lock
4) 제약조건
문제 26 정답
정답 : 3
- 해설 : Lock/Unlock은 병행성 제어(동시성) 기법이다.
- 무결성 : 데이터 임의 갱신으로부터 보호해야 하는 것.
- 제약조건을 넣어서 무결성을 보장하거나, Triger 로직 안에 검사 기능을 넣을 수도 있고, 개발자의 코딩에서 로직을 넣을 수도 있다.
📋 CONNECT BY
- 이 절을 이용하여 계층 질의에서 상위계층(부모행)과 하위계층(자식행)의 관계를 규정할 수 있다.
- PRIOR연산자와 함께 사용하여 계층구조로 표현할 수 있다.
- CONNECT BY PRIOR 자식컬럼 = 부모컬럼 : 부모에서 자식으로 트리 구성 (Top Down)
- CONNECT BY PRIOR 부모컬럼 = 자식컬럼 : 자식에서 부모로 트리 구성 (Bottom Up)
- CONNECT BY NOCYCLE PRIOR: NOCYCLE 파라미터를 이용하여 무한 루프 방지
- 서브 쿼리를 사용할 수 없다.
항상 ⬅️
자식 = 부모 : 부모에서 자식으로(순방향)
부모 = 자식 : 자식에서 부모로(역방향)
문제 30. 다음 중 문자열이 입력될 때 빈 공간으로 채우는 형태의 데이터 타입은?
1) VARCHAR2
2) CHAR
3) DATE
4) NUMBER
문제 30 정답
정답 : 2
해설 : CHAR(10)으로 칼럼을 생성하고 8개의 문자를 입력하면 나머지 2개는 공백으로 입력된다. VARCHAR2는 가변길이 문자열 타입으로 입력한 크기만큼 할당된다.
문제 49. 아래의 SQL에 대한 Column Header를 적으시오(DBMS : Oracle)
<SQL>
SELECT employee_id, DEPARTMENT_ID, SALARY AS " salary"
FROM SQLD_49
WHERE EMPLOYEE_ID < 110;문제 49 정답
정답 : EMPLOYEE_ID, DEPARTMENT_ID, salary
문제 50. 아래 데이터를 가진 테이블에 대한 SQL결과를 적으시오.
[SQLD_50]
COL1 COL2
--------------
1
2
3 1
4 1
5 2
6 2
7 3
8 4
9 5
10 6
- - - - - - -
SELECT COUNt(*)
FROM SQLD_50
WHERE COL1 <> 4
START WITH COL1 = 1
CONNECT BY PRIOR COL1 = COL2;
문제 50 쿼리 ✔️
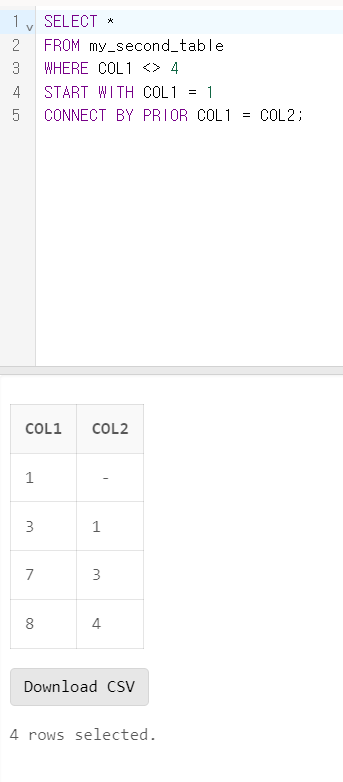
- 정답: 4
문제 50 해설
이 SQL 쿼리는 오라클 데이터베이스의 계층형 쿼리 기능을 사용하여 특정 조건을 만족하는 행의 수를 계산합니다. 계층형 쿼리는 START WITH ... CONNECT BY 구문을 사용하여 데이터 간의 부모-자식 관계를 탐색합니다. 이 쿼리를 분석하고 어떤 결과를 반환하는지, 그리고 그 로직에 대해 설명하겠습니다.
쿼리 분석
SELECT COUNT(*)
FROM my_second_table
WHERE COL1 <> 4
START WITH COL1 = 1
CONNECT BY PRIOR COL1 = COL2;START WITH COL1 = 1: 쿼리는COL1값이 1인 행에서 시작합니다. 이는 쿼리의 '루트' 또는 시작점을 정의합니다.CONNECT BY PRIOR COL1 = COL2: 이 구문은 테이블 내의 행들 사이의 관계를 정의합니다. 여기서는COL1의 값이 이전 행(PRIOR)의COL2값과 같은 행을 찾아 계층을 형성합니다. 즉,COL2가 부모COL1을 가리키는 자식-부모 관계를 형성합니다.WHERE COL1 <> 4: 이 조건은COL1의 값이 4가 아닌 행만을 대상으로 합니다. 계층 구조가 형성된 후에 이 필터가 적용되어 최종 결과에서 제외됩니다.
로직 설명
COL1이 1인 행을 시작점으로 선택합니다.COL1의 값이 다른 행의COL2값과 일치하는 방식으로 연결하여 계층을 형성합니다.- 이 과정에서
COL1값이 4인 행은 제외합니다. - 최종적으로 선택된 행들의 수를 카운트합니다.
결과 예측
이 쿼리를 실행하면 COL1이 1인 행에서 시작하여 계층형 구조를 따라가면서 COL1 값이 4가 아닌 행들을 카운트합니다. 이 테이블 구조와 데이터를 고려했을 때, COL1이 1인 행은 COL2를 통해 COL1이 3인 행으로 연결됩니다. 그러나 COL1이 4인 행은 WHERE 조건에 의해 제외됩니다. 따라서, 계층형 쿼리는 COL1이 1인 행에서 시작하여 COL1이 3인 행으로만 이동할 수 있으며, 이후 연결 가능한 COL1 값이 4인 행은 제외됩니다.
그러나, START WITH에서 COL1이 1인 행을 시작점으로 설정했고, COL1 값이 4인 행을 제외하라는 조건을 더했음에도 불구하고, 실제로 COL1이 4인 행으로 직접 연결되는 행은 없습니다. CONNECT BY 조건에 따라 COL1이 1인 행은 자식이 없으므로, 이 쿼리는 단순히 COL1이 1인 행만을 카운트하는 것으로 보입니다. 따라서, 결과는 1이 될 것으로 예상합니다.
그러나, 제가 설명한 내용은 쿼리의 기본 로직과 예상 결과에 대한 것이며, 실제 결과는 데이터베이스에서 쿼리를 실행해보지 않는 이상 확실하지 않습니다. 오라클의 계층
형 쿼리는 상당히 복잡할 수 있으며, CONNECT BY 조건이나 WHERE 절의 정확한 해석은 실행 컨텍스트에 따라 달라질 수 있습니다.
