
문제 3. 다음은 ABC증권회사의 회원정보를 모델링 한 것이다. 회원정보는 수퍼타입이고 개인회원과 법인회원 정보는 서브타입이다. 애플리케이션에 회원정보를 조회하는 경우는 항상 개인회원과 법인회원을 동시에 조회하는 특성이 있을 때 수퍼타입과 서브타입을 변환하는 방법으로 가장 올바른 것은?
1) ONE TO ONE
2) PLUS TYPE
3) SINGLE TYPE
4) 정답 없음
문제 3 해설
주어진 상황에서는 수퍼타입(회원정보)과 서브타입(개인회원, 법인회원)을 모델링할 때, 애플리케이션에서 항상 개인회원과 법인회원 정보를 동시에 조회하는 특성을 고려해야 합니다. 이 경우, 가장 효율적인 방법은 하나의 테이블에 모든 정보를 통합해서 관리하는 방법입니다. 이런 방식을 '싱글 테이블 상속(Single Table Inheritance)'이라고 합니다.
싱글 테이블 상속(Single Table Inheritance) 방식은 수퍼타입과 모든 서브타입의 데이터를 하나의 테이블에 저장하는 방식입니다. 이 방식에서는 서브타입을 구분할 수 있는 구분자(예: 회원 유형)가 필요하며, 테이블에는 모든 가능한 속성이 포함됩니다. 각 행은 구분자에 따라 개인회원 또는 법인회원으로 해석됩니다.
따라서 주어진 선택지 중에서 올바른 변환 방법을 나타내는 용어는 제시된 바와 같이 3) SINGLE TYPE입니다. 하지만, 정확한 용어는 'Single Table Inheritance'입니다. 선택지에 'SINGLE TYPE'이 가장 가까운 의미를 가지고 있으나, 데이터 모델링 용어로 정확하게 매칭되는 것은 아닙니다. 실제로는 'SINGLE TABLE Inheritance'가 정확한 용어이므로, 주어진 선택지 중에서는 '정답 없음'에 가깝지만, 의도한 바는 'SINGLE TYPE'을 선택하라는 것으로 보입니다.
결론적으로, 주어진 문제의 의도에 가장 부합하는 선택지는 3) SINGLE TYPE이지만, 이 용어는 표준 데이터 모델링 용어와 정확히 일치하지 않습니다. 그러므로, 가장 적합한 답변을 선택하는 데 주의가 필요합니다.

문제 6. 엔터티의 종류 중 다:다 관계를 해소하려는 목적으로 인위적으로 만들어진 엔터티는 무엇인가?
1) 기본 엔터티
2) 행위 엔터티
3) 교차 엔터티
4) 종속 엔터티
문제 6 해설
다:다(Many-to-Many) 관계를 해소하기 위해 인위적으로 생성되는 엔터티를 교차 엔터티(Cross Entity) 또는 연결 엔터티(Associative Entity), 조인 테이블(Join Table) 등으로 부릅니다. 이 엔터티는 두 개 이상의 엔터티 간의 다대다 관계를 표현할 때 사용되며, 각 엔터티에서의 관계를 하나의 레코드로 매핑하여 다대다 관계를 두 개의 일대다(One-to-Many) 관계로 분해합니다.
따라서 주어진 선택지 중 올바른 답은 3) 교차 엔터티입니다.
행위 vs 교차 vs 종속 엔터티
각 엔터티의 개념과 차이점을 이해하기 위해 간단히 설명하겠습니다:
2) 행위 엔터티 (Action Entity)
- 행위 엔터티는 두 개 이상의 엔터티 간의 특정 행위나 이벤트를 나타내기 위해 사용됩니다. 이는 엔터티들 사이의 관계를 기록하며, 그 관계가 발생하는 과정이나 결과 등의 정보를 포함할 수 있습니다. 예를 들어, '주문'이라는 행위 엔터티는 '고객' 엔터티와 '제품' 엔터티 간의 구매 행위를 나타낼 수 있습니다.
3) 교차 엔터티 (Cross Entity)
- 교차 엔터티는 주로 다대다 관계를 해소하기 위해 사용되는 엔터티입니다. 두 개의 엔터티 사이에 다대다 관계가 있을 때, 이를 두 개의 일대다 관계로 변환하기 위해 사용됩니다. 교차 엔터티는 각 관계에 대한 구체적인 정보(예: 관계의 속성)를 포함할 수 있습니다. 이 엔터티는 연결 엔터티 또는 조인 테이블이라고도 불립니다.
4) 종속 엔터티 (Dependent Entity)
- 종속 엔터티는 다른 엔터티에 종속적인 엔터티로, 주로 다른 엔터티 없이는 존재할 수 없는 정보를 관리합니다. 종속 엔터티는 부모 엔터티의 키를 외래 키로 포함하여 부모 엔터티와의 관계를 명시합니다. 예를 들어, '주소' 엔터티가 '사람' 엔터티에 종속될 수 있으며, 각 '주소'는 특정 '사람'에 속해 있음을 나타냅니다.
차이점
- 행위 엔터티는 특정 행위나 이벤트의 발생을 나타내며, 복잡한 관계나 프로세스를 모델링할 때 유용합니다.
- 교차 엔터티는 다대다 관계를 일대다 관계로 변환하는 데 사용되며, 두 엔터티 간의 연결을 관리합니다.
- 종속 엔터티는 다른 엔터티에 종속적이며, 그 존재가 다른 엔터티에 의해 정의되는 정보를 담고 있습니다.
각각의 엔터티 유형은 데이터 모델링 과정에서 특정 상황이나 요구 사항에 맞게 선택하여 사용됩니다.
문제 10. 식별자 중에서 비즈니스 프로세스에 의하여 만들어지는 식별자로 대체여부로 분리되는 식별자는 무엇인가?
1) 본질 식별자
2) 단일 식별자
3) 내부 식별자
4) 인조 식별자
문제 10 해설 ❓
정답 : 1
해설 : 대체여부에 따라서 본질 식별자와 인조 식별자로 분류되고 → 본질 식별자는 비즈니스 프로세스에 의해서 만들어지는 식별자이다.
문제 12. 주어진 데이터에서 아래의 SQL문이 수행된 결과로 옳은 것은?
[SQLD_39_12]
COL1 COL2
---------------
100 100
NULL 60
NULL NULL
[SQL]
SELECT COALESCE(COL1,COL2*50,50)
FROM SQLD_39_12;1) 100,3000,50
2) 100,NULL,50
3) 100,60,50
4) 100,3000,NULL
문제 12 - COALESCE
- NULL이 아닌 첫 번째 값을 반환한다.
문제 21. 다음 계층형 쿼리문에 대한 설명으로 옳지 않은 것은?
[SQLD39_21]
ID PARENT_ID NAME PARENT_NAME DEPTH
-------------------------------------------
3 0 A 1
4 0 B 1
5 3 C A 2
6 3 D A 2
7 3 E A 2
8 3 F A 2
9 6 G F 3
10 4 H B 2
11 4 I B 2
SELECT ID, PARENT_ID, NAME, PARENT_NAME
FROM SQLD39_21
WHERE PARENT_ID NOT IN(3)
START WITH PARENT_ID = 0
CONNECT BY PRIOR ID = PARENT_ID
ORDER SIBLINGS BY PARENT_ID ASC, ID ASC;1) PARENT_ID가 0이라도 3이 포함되면 전개를 멈춘다.
2) 순방향 전개다.
3) 중복이 생겼을 때 루프를 돌지 않기 위해 NO CYCLE 옵션을 사용할 수 있다.
4) ORDER SIBLINGS BY를 하면 전체 테이블 기준으로 정렬한다.
문제 21 해설
계층형 쿼리문에 대한 설명 중 옳지 않은 것을 찾는 문제입니다. 각 선택지를 분석해 보겠습니다:
1) PARENT_ID가 0이라도 3이 포함되면 전개를 멈춘다. - 이 설명은 부분적으로 올바른 것처럼 보일 수 있습니다. WHERE PARENT_ID NOT IN(3) 조건에 의해 PARENT_ID가 3인 행은 조회에서 제외되지만, PARENT_ID가 0인 행 중에서 시작하여 PARENT_ID가 3인 자식 레코드를 제외하고 전개는 계속됩니다. 이 문장의 표현이 다소 혼동을 줄 수 있지만, 쿼리의 WHERE 조건이 계층 전개를 직접적으로 멈추게 하는 것은 아니므로 정확하지 않은 해석일 수 있습니다.
2) 순방향 전개다. - 계층형 쿼리는 START WITH에서 시작하여 CONNECT BY를 통해 하위 레벨로 전개하는 순방향 전개 방식을 사용합니다. 이 설명은 올바릅니다.
3) 중복이 생겼을 때 루프를 돌지 않기 위해 NO CYCLE 옵션을 사용할 수 있다. - 계층형 쿼리에서 무한 루프를 방지하기 위해 CONNECT BY 절에 NOCYCLE 옵션을 사용할 수 있습니다. 이 설명은 올바른 기능의 설명이지만, 주어진 쿼리 예제에는 NOCYCLE 옵션이 명시적으로 포함되어 있지 않습니다. 그럼에도 불구하고 이 옵션의 존재 자체에 대한 설명은 올바릅니다.
4) ORDER SIBLINGS BY를 하면 전체 테이블 기준으로 정렬한다. - ORDER SIBLINGS BY는 형제 노드 간의 정렬 순서를 지정합니다. 이는 전체 테이블을 기준으로 정렬하는 것이 아니라, 같은 부모를 가진 노드들 사이의 정렬 순서를 결정합니다. 따라서 이 설명은 잘못되었습니다.
정답은 4) ORDER SIBLINGS BY를 하면 전체 테이블 기준으로 정렬한다.입니다. 이는 ORDER SIBLINGS BY의 실제 작동 방식을 잘못 설명하고 있습니다.
- ORDER SIBLINGS BY: 전체테이블 X, 형제 노드 간의 정렬 순서를 지정
문제 30. 다음의 SUB QUERY의 유형은 무엇인가?
SELECT A.EMPNO, A.ENAME
FROM EMP A
WHERE A.EMPNO = (SELECT 1 FROM
EMP_T B WHERE A.EMPNO = B.EMPNO);1) SERVICE 서브쿼리
2) EARLY FILTER형 서브쿼리
3) CORRELATED 서브쿼리
4) LOOPING 서브쿼리
문제 30 해설
제시된 서브 쿼리의 유형을 파악하고 각 보기의 설명을 제공하겠습니다.
제시된 서브 쿼리의 유형
SELECT A.EMPNO, A.ENAME
FROM EMP A
WHERE A.EMPNO = (SELECT 1 FROM EMP_T B WHERE A.EMPNO = B.EMPNO);이 서브 쿼리는 3) CORRELATED 서브쿼리(Correlated Subquery)입니다. 상관 서브 쿼리는 외부 쿼리의 컬럼을 참조하는 내부 쿼리입니다. 내부 쿼리(SELECT 1 FROM EMP_T B WHERE A.EMPNO = B.EMPNO)가 외부 쿼리(SELECT A.EMPNO, A.ENAME FROM EMP A)의 A.EMPNO를 참조하여 실행되기 때문에, 이 서브 쿼리는 상관 서브 쿼리의 특징을 가지고 있습니다. 상관 서브 쿼리는 외부 쿼리의 각 행에 대해 내부 쿼리가 실행되므로, 외부 쿼리와 내부 쿼리 사이에는 상관 관계가 있습니다.
다른 보기 설명
1) SERVICE 서브쿼리 - 이 용어는 일반적인 SQL 서브 쿼리 유형으로 분류되지 않습니다. SQL 문서나 표준에서는 "서비스 서브 쿼리"라는 용어를 사용하지 않으므로, 이 옵션은 오해의 소지가 있거나 잘못된 용어일 수 있습니다.
2) EARLY FILTER형 서브쿼리 - 이 용어 역시 일반적인 SQL 서브 쿼리 유형 중 하나로 인정받는 표준 용어는 아닙니다. 그러나 이 용어가 사용된다면, 쿼리 처리 과정에서 조기에 필터링을 수행하여 효율성을 높이는 서브 쿼리의 형태를 의미할 수 있습니다. 하지만 정확한 용어 사용에 주의가 필요합니다.
4) LOOPING 서브쿼리 - 이 용어도 표준 SQL 용어는 아니며, 일반적으로 사용되는 서브 쿼리 분류에 속하지 않습니다. 상관 서브 쿼리가 외부 쿼리의 각 행에 대해 반복적으로 실행되는 것과 관련 있을 수 있지만, "루핑 서브 쿼리"라는 용어는 특정 상황이나 구현에 따라 다르게 해석될 수 있습니다.
정리하자면, 주어진 문제에서 올바른 답은 3) CORRELATED 서브쿼리이며, 나머지 보기는 표준 SQL 용어와는 다소 거리가 있는 표현입니다. 상관 서브 쿼리는 외부 쿼리와 내부 쿼리가 서로 연관되어 있는 경우를 지칭합니다.
서브쿼리 종류 정리 🚀
SQL에서 사용되는 서브쿼리(Subquery)는 주 쿼리(Query) 내에 포함된 쿼리로, 데이터를 검색, 필터링, 비교 또는 계산하는 데 사용됩니다. 서브쿼리는 그 사용 방식과 위치에 따라 다양한 종류로 분류될 수 있습니다. 여기 몇 가지 주요 서브쿼리 유형을 소개하겠습니다:
1. 상관 서브쿼리 (Correlated Subquery)
- 상관 서브쿼리는 주 쿼리의 각 행에 대해 실행되는 서브쿼리로, 서브쿼리가 주 쿼리의 컬럼을 참조합니다. 이러한 서브쿼리는 주 쿼리와 '상관관계'가 있으며, 주 쿼리의 현재 행에 대한 정보를 기반으로 결과를 반환합니다.
2. 비상관 서브쿼리 (Non-correlated Subquery)
- 비상관 서브쿼리는 주 쿼리의 데이터와 독립적으로 실행되며, 주 쿼리의 어떤 행에도 의존하지 않습니다. 이러한 서브쿼리는 한 번만 실행되며, 그 결과는 주 쿼리에서 사용됩니다.
3. 스칼라 서브쿼리 (Scalar Subquery)
- 스칼라 서브쿼리는 단일 행과 단일 컬럼(즉, 하나의 값)만 반환하는 서브쿼리입니다. 이는 SELECT 문의 컬럼 목록, WHERE 절, HAVING 절 등에서 사용될 수 있으며, 하나의 값으로 평가됩니다.
4. 인라인 뷰 (Inline View)
- 인라인 뷰는 FROM 절에서 사용되는 서브쿼리로, 임시 테이블처럼 동작합니다. 이를 통해 복잡한 쿼리를 더 간단하게 만들거나, 계산된 결과를 기반으로 추가 조회를 수행할 수 있습니다.
5. 존재 서브쿼리 (Exists Subquery)
- 존재 서브쿼리는 주로 EXISTS 연산자와 함께 사용되며, 서브쿼리가 결과를 반환하는지 여부를 확인하는 데 사용됩니다. 이 유형의 서브쿼리는 조건의 참/거짓을 판별하는 데 사용되며, 서브쿼리의 실제 결과값은 중요하지 않습니다.
6. 다중 행 서브쿼리 (Multi-row Subquery)
- 다중 행 서브쿼리는 여러 행을 반환할 수 있으며, IN, ANY, ALL 연산자와 함께 사용됩니다. 이러한 서브쿼리는 주 쿼리의 조건과 여러 행의 결과를 비교하는 데 사용됩니다.
서브쿼리는 복잡한 데이터 검색 요구를 충족시키기 위해 SQL에서 광범위하게 사용됩니다. 올바르게 사용될 때, 서브쿼리는 데이터 분석, 보고, 및 의사 결정 지원 시스템에서 강력한 도구가 될 수 있습니다.
문제 45. 다음( )에 올바른 것을 작성하시오.
ABC기업에 새로운 DBA가 입사를 했다.
팀장은 DBA에게 권한을 할당하려고 하는데
GRANT DBA TO USERA; 라는 SQL문을 실행 했다.
이 때 GRANT문에 사용된 DBA는
권한들을 묶어서 한꺼번에 부여하는 ( ) 이라고 한다.문제 45 해설
SQL에서 GRANT 문을 사용하여 사용자에게 권한을 부여할 때, "DBA"와 같이 특정 권한들을 묶어서 한 번에 부여할 수 있는 개념을 롤(Role) 이라고 합니다. 따라서, 빈칸에 들어갈 올바른 단어는 "롤"입니다.
즉, 문장은 다음과 같이 완성됩니다:
ABC기업에 새로운 DBA가 입사를 했다. 팀장은 DBA에게 권한을 할당하려고 하는데 GRANT DBA TO USERA; 라는 SQL문을 실행 했다. 이 때 GRANT문에 사용된 DBA는 권한들을 묶어서 한꺼번에 부여하는 롤 이라고 한다.
문제 46. 아래의 SQL문을 순차적으로 수행한 결과값을 작성하시오.
CREATE TABLE SQLD39_46 (N1 NUMBER);
INSERT INTO SQLD39_46 VALUES(1);
INSERT INTO SQLD39_46 VALUES(2);
CREATE TABLE TMP_SQLD39_46 (N1 NUMBER);
INSERT INTO TMP_SQLD39_46 VALUES(1);
TRUNCATE TABLE TMP_SQLD39_46;
ROLLBACK;
COMMIT;
SELECT SUM(N1) FROM SQLD39_46;문제 46 정답
: 3
- CREATE TABLE, TRUNCATE TABLE을 수행하면 즉각 커밋이 된다.
- 트랜잭션이 그 순간 커밋되었다고 생각하면 됨.
- DDL은 그냥 커밋됨
CREATE, TRUNCATE, ALTER, DROP : 전부 DDL, COMMIT 완료됨.문제 49. 주어진 데이터에서 아래의 SQL문을 실행한 행(Row)의 건수는?
[SQLD39_49]
COL1 COL2 COL3
-----------------
1 1 3
1 2 3
2 1 3
3 1 3
3 2 3
[SQLD39_49_2]
COL1 COL2 COL3
-----------------
1 1 3
1 2 3
2 1 3
3 1 3
3 2 3
[SQL]
SELECT COUNT(*)
FROM SQLD39_49 A, SQLD39_49_2 B
WHERE A.COL1 = B.COL1;문제 49 해설
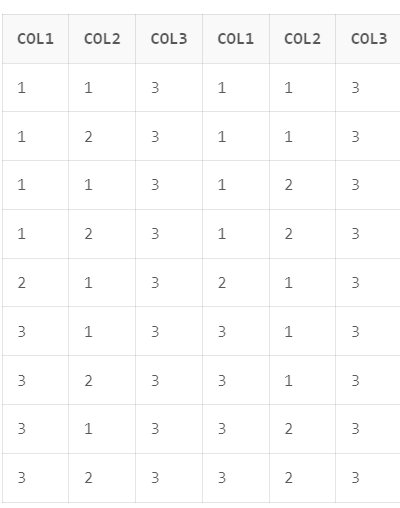
- JOIN 하면 다음과 같이 나온다.
- 1인컬럼이 2개씩, 2가 1개씩, 3이 2개씩이다.
2*2 + 1*1 + 2*2 = 9개