
문제 7. 다음 보기 중 엔터티, 관계, 속성에 대한 설명으로 올바르지 않은 것은?
1) 한 개의 엔터티는 두 개 이상의 인스턴스의 집합이어야 한다.
2) 엔터티는 관계를 두 개까지만 가질 수 있다.
3) 한 개의 엔터티는 두 개 이상의 속성을 갖는다.
4) 한 개의 속성은 한 개의 속성값을 갖는다.
문제 7 해설
한 개의 엔터티는 두 개 이상의 인스턴스의 집합이어야 한다.: TRUE
- 정답: 2
문제 9. 다음 주어진 그림에 해당하는 ERD 표기법으로 알맞은 것은?
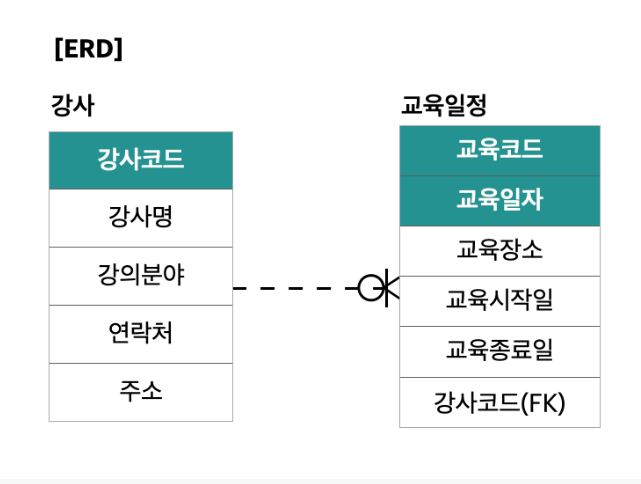
1) Barker
2) IE
3) IE Notation
4) IDEF1X
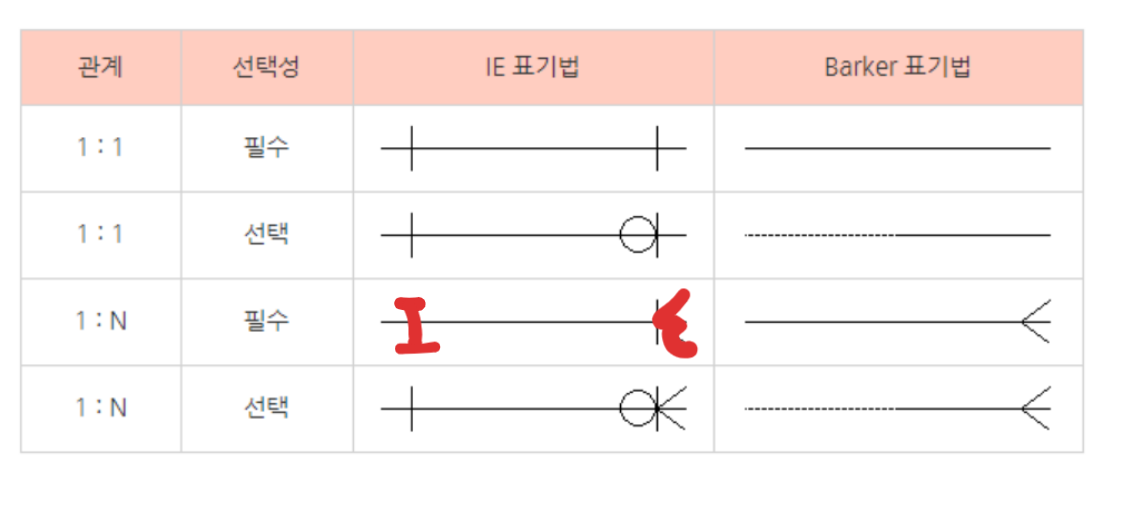
문제 9 해설 👍
- IE, Barker 비교
문제 16. 다음 보기 중 주어진 테이블에 대해서 수행하였을 때 결과값이 다른 것은?
[TEST 16]
MemberID Name
-----------------
NULL 조조
2 여포
3 관우
4 장비
5 조훈
NULL 유비1) SELECT COUNT(3) FROM TEST16;
2) SELECT COUNT(MemberID) FROM TEST16;
3) SELECT COUNT(NULLIF (MemberID, NULL)) FROM TEST16;
4) SELECT COUNT(*) FROM TEST16 WHERE MemberID IS NOT NULL;
문제 16 해설 ✔️
- 기본적으로 count에 100이 들어가든, 3이 들어가든, 1이 들어가든 그냥 상수 취급이므로 모든 갯수를 다 센다(count(*))과 같다.
- 그러나 NULL인 것은 세지 않음.
- 따라서 NULLIF로 NULL 처리된 아이들은 세지 않는다.
문제 17. 다음 주어진 테이블에서 해당 SQL문을 실행한 결과로 알맞은 것은?
[TEST17]
COL1 COL2
-------------
NULL A
1 B
2 C
3 D
4 E
[SQL]
SELECT*FROM TEST17 WHERE COL1 IN(1, 2, NULL);
1) 2)
COL1 COL2 COL1 COL2
------------- -------------
1 B 2 B
2 C 2 C
3) 4)
COL1 COL2 COL1 COL2
------------- -------------
1 B NULL A
2 C 1 B
3 D 2 C
4 E 3 D
4 E문제 17 해설
- IN 연산자 안에 NULL이 들어가도 없는 것과 같은 취급을 함
- NULL도 정답에 포함되어야할 것 같은데 아니다.
문제 20. SELECT NVL(COUNT(*), 9999) FROM TABLE WHERE 1 = 2 의 결과값은?
1) 9999
2) 0
3) NULL
4) 1
문제 20 헷갈리는 것 정리 📋
- NVL(NULL임?, NULL이면 이걸로 대체)
- NVL2(NULL임?, NULL 아니면 이거, NULL이면 이거)
- NVL2 헷갈리는데 그냥 NVL에서 중간에 꼽사리 꼈다고 생각하자.
- NULL값을 처리해야 하는 경우가 많고, 대체하려면 이 함수를 사용한다고 생각하면 되겠다.
문제 27. 릴레이션 EMP, DEPT가 다음과 같이 정의되어 있다. 사원이 한명도 없는 부서(DEPTNO)를 검색하는 질의를 작성했을때, 가장 거리가 먼 것은?(단, EMP의 DEPTNO은 DEPT의 DEPTNO을 참조하는 외래키이다.)
EMP(EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
DEPT(DEPTNO, DNAME, LOC)
1)
SELECT DEPTNO FROM DEPT
WHERE DEPTNO NOT IN
(SELECT DEPTNO FROM EMP);
2)
SELECT DEPTNO FROM DEPT A
WHERE NOT EXISTS
(SELECT * FROM EMP B WHERE
A.DEPTNO = B.DEPTNO);
3)
SELECT B.DEPTNO FROM EMP A
RIGHT OUTER JOIN
DEPT B ON A.DEPTNO = B.DEPTNO
WHERE EMPNO IS NULL;
4)
SELECT DEPTNO FROM DEPT
WHERE DEPTNO <> ANY (SELECT
DEPTNO FROM EMP);문제 27 해설 ❓
이 문제는 SQL 질의문에 대한 이해를 바탕으로, 사원이 한 명도 없는 부서(DEPTNO)를 찾는 네 가지 다른 방식의 SQL 질의문 중 가장 거리가 먼 것을 찾는 것입니다. 각 옵션을 분석해 보겠습니다.
-
첫 번째 옵션은
NOT IN을 사용하여EMP테이블에 없는DEPT테이블의DEPTNO를 찾습니다. 이 방식은EMP테이블에 해당 부서번호가 전혀 나타나지 않은 경우에만 해당 부서번호를 반환합니다. -
두 번째 옵션은
NOT EXISTS를 사용하여,EMP테이블에 특정 부서번호가 존재하지 않는DEPT테이블의DEPTNO를 찾습니다.NOT IN방식과 유사하게 작동하지만, 서브쿼리를 이용해 좀 더 명시적으로 해당 부서번호가EMP테이블에 존재하는지를 체크합니다. -
세 번째 옵션은
RIGHT OUTER JOIN을 사용하여DEPT테이블과EMP테이블을 조인하고,EMPNO가NULL인 경우(즉,EMP테이블에 해당 부서번호가 없는 경우)를 찾습니다. 이 방식은 두 테이블을 조인하여 결과를 도출하는 방식으로, 물리적으로 가장 멀리 떨어진 방식이라고 볼 수 있습니다. -
네 번째 옵션은
<> ANY를 사용하여,EMP테이블에 있는 어느DEPTNO와도 다른DEPT테이블의DEPTNO를 찾습니다. 이 방식은 문제의 의도와 맞지 않는 방식입니다. 왜냐하면ANY조건은EMP테이블에 존재하는 어떤DEPTNO와도 다르다는 조건을 만족하는DEPTNO를 찾지만, 실제로는 적어도 하나의DEPTNO가EMP테이블에 존재할 경우 해당DEPTNO는 결과에서 제외됩니다. 이는 사원이 한 명도 없는 부서를 찾는 것과는 거리가 멉니다.
따라서, 가장 거리가 먼 것은 옵션 4입니다. 이 옵션은 사원이 한 명도 없는 부서를 찾기 위한 목적과 가장 거리가 멀며, 질의의 의도와 맞지 않는 방식으로 작동합니다.
문제 28. 다음 릴레이션에 대하여 아래와 같이 인덱스를 생성하였다. 다음 중 생성된 인덱스에 의하여 검색속도를 향상시킬 수 있는 질의로 가장 적절하지 않은 것은?
[릴레이션]
ARTICLES(ID, TITLE, JOURNAL, ISSUE, YEAR, STARTPAGE, ENDPAGE, TR_ID)
[인덱스]
CREATE INDEX IDX1 ON ARTICLES(YEAR, STARTPAGE);
CREATE INDEX IDX2 ON ARTICLES(STARTPAGE, ENDPAGE);
CREATE INDEX IDX3 ON ARTICLES(JOURNAL, ISSUE, YEAR);
1) 2)
SELECT TITLE FROM ARTICLES SELECT TITLE FROM ARTICLES
WHERE JOURNAL = 'JACM' AND WHERE ENDPAGE - STARTPAGE > 50;
ISSUE = 55;
3) 4)
SELECT TITLE FROM ARTICLES SELECT TITLE FROM ARTICLES
WHERE YEAR > 1995 AND WHERE JOURNAL = 'JACM';
YEAR < 2000;
문제 28 해설 ❓
인덱스는 데이터베이스에서 데이터를 빠르게 찾기 위한 구조로, 특정 열(들)에 대해 생성됩니다. 생성된 인덱스를 기반으로 각 질의의 검색 속도가 어떻게 향상될 수 있는지 살펴보겠습니다.
1) 첫 번째 질의는 JOURNAL과 ISSUE를 조건으로 사용합니다. 이는 IDX3 인덱스(JOURNAL, ISSUE, YEAR)를 활용할 수 있으므로, 검색 속도가 향상될 수 있습니다.
2) 두 번째 질의는 ENDPAGE - STARTPAGE > 50라는 계산 조건을 사용합니다. 이러한 종류의 계산 조건은 인덱스를 직접적으로 활용할 수 없습니다. 왜냐하면, 인덱스는 특정 열의 값에 기반한 검색에 최적화되어 있으며, 두 열의 값을 사용한 계산 결과에 기반한 검색은 인덱스의 도움을 받기 어렵기 때문입니다.
3) 세 번째 질의는 YEAR 열에 대한 범위 검색을 사용합니다. 이는 IDX1 인덱스(YEAR, STARTPAGE)를 부분적으로 활용할 수 있으므로, 검색 속도에 도움이 될 수 있습니다. 비록 STARTPAGE는 조건에 사용되지 않지만, 인덱스의 첫 번째 컬럼인 YEAR가 사용되므로 인덱스의 효과를 일부 받을 수 있습니다.
4) 네 번째 질의는 JOURNAL을 조건으로 사용합니다. 이는 IDX3 인덱스(JOURNAL, ISSUE, YEAR)를 활용할 수 있으므로, 검색 속도가 향상될 수 있습니다. 하지만 이 질의는 ISSUE나 YEAR 같은 다른 조건들을 포함하지 않아, 인덱스 IDX3의 첫 번째 컬럼만을 사용하게 됩니다.
결론적으로, 가장 적절하지 않은 질의는 2번입니다. 이 질의는 생성된 인덱스에 의하여 검색 속도를 향상시킬 수 없는 유일한 경우로, 두 열의 값에 기반한 계산 조건을 포함하기 때문입니다. 나머지 질의들은 생성된 인덱스를 통해 검색 속도를 어느 정도 향상시킬 수 있습니다.
문제 30. 아래의 보기가 설명하는 것으로 알맞은 것은?
[보기]
- SQL이 데이터베이스에서 실행될 때 실행 절차 및
방법을 표현하여 DBA에게 알려준다.
- 옵티마이저의 종류를 확인할 수 있는 RULE, COST가 표현되고
SQL이 내부적으로 어떤 방식으로 실행되었는지 확인 할 수 있다.1) 실행계획
2) 내부계획
3) 절차계획
4) 표현계획
문제 30 해설
- 실행계획, 외우자.
연산자 실행 순서 🚀
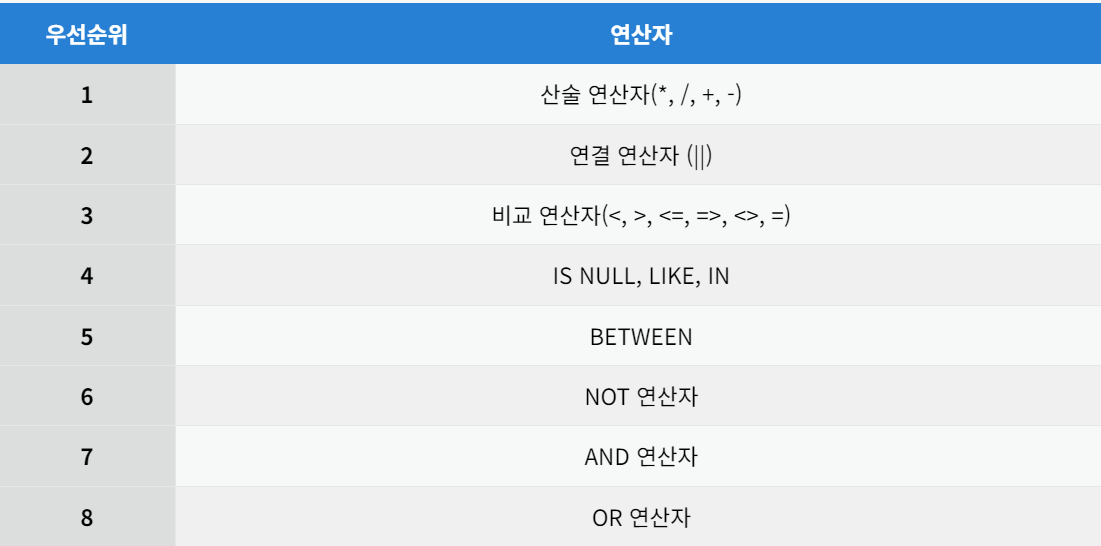
- 산열비널비나앤오 BNAO
순수 관계 연산자 🚀

- 정보처리기사에서 지긋지긋하게 보던 녀석이다.
- 셀프조인으로 일단 셋 외우고, 디비전은 그냥 외우자.
문제 46. 주어진 보기의 SQL1에 대한 결과와 동일한 결과를 반환하도록 SQL2의 ( )을 작성하시오.
[SQL1]
SELECT COL1, COL2, COUNT(*)
FROM TEST46
GROUP BY ROLLUP(COL1, COL2);
[SQL2]
SELECT COL1, COL2, COUNT(*)
FROM TEST46
GROUP BY GROUPING SETS( );문제 47 해설 ✏️
정답 : (COL1, COL2),(COL1),()
- GROUPING SETS에 대한 정확한 학습 필요할듯.

문제 50. TEST50 테이블에는 총 5건의 행이 있다. 다음 빈칸에 올바른 것을 작성하시오.
[SQL]
SELECT COUNT(*) FROM TEST50
( ) TEST50;
[RESULT]
COUNT(*)
----------
25문제 50 해설 ✔️
주어진 SQL 쿼리와 결과를 보면, TEST50 테이블에서 총 25건의 행이 반환되었다고 합니다. 이 테이블에는 총 5건의 행이 있다고 했을 때, 25건의 결과가 나오려면 각 행이 5번씩 반복되어야 합니다. 이는 테이블을 자기 자신과 조인할 경우 발생할 수 있는 현상입니다.
SQL에서 테이블을 자기 자신과 조인하여 각 행을 여러 번 반복시키려면, 테이블을 카테시안 곱(Cartesian product)으로 조인해야 합니다. 카테시안 곱은 모든 가능한 행의 조합을 반환하는데, 여기서는 5건의 행이 각각 다른 5건의 행과 조합되어 총 25(5x5)건의 결과를 생성합니다.
따라서, 빈칸에 들어갈 SQL 구문은 테이블을 자기 자신과 카테시안 곱으로 조인하는 명령어입니다. SQL에서 이를 수행하는 가장 간단한 방법은 , (콤마)를 사용하는 것입니다. 콤마는 FROM 절에서 여러 테이블을 나열할 때 사용되며, 조인 조건 없이 모든 테이블의 카테시안 곱을 반환합니다. 하지만, 최신 SQL 관례에서는 명시적인 JOIN 구문을 권장하므로, CROSS JOIN을 사용하는 것이 더 명확할 수 있습니다.
그러나 이 문제의 형식과 명시된 결과를 고려할 때, 가장 간단하고 직관적인 방법으로 빈칸을 채우려면 ,를 사용하는 것이 적절합니다. 따라서 올바른 답변은:
, TEST50이렇게 하면 TEST50 테이블이 자기 자신과 카테시안 곱으로 조인되어, 5x5=25건의 결과가 생성됩니다.
문제 50 해설2 ✔️
FULL OUTER JOIN을 사용하는 경우에 대해 설명하겠습니다. FULL OUTER JOIN은 두 테이블 간의 조인을 수행할 때, 양쪽 테이블의 모든 행을 포함하되, 조인 조건에 맞지 않는 행에 대해서는 NULL 값을 채워 넣는 조인 방식입니다. 즉, 양쪽 테이블의 모든 데이터를 결과에 포함시키며, 한쪽에만 존재하는 데이터도 결과에 포함됩니다.
문제 상황에서 TEST50 테이블에 총 5건의 행이 있고, 이 테이블을 자기 자신과 FULL OUTER JOIN으로 조인한다고 가정하면, 결과는 어떻게 될까요? 조인 조건을 명시하지 않으면, 이는 기본적으로 카테시안 곱을 생성하는 것과 유사하게 동작할 수 있습니다. 하지만, FULL OUTER JOIN의 주요 목적과 사용 사례는 두 테이블 간의 모든 데이터를 포함시키면서, 한쪽 테이블에만 있는 데이터도 결과에 포함시키는 것입니다. 이는 주로 두 데이터 집합의 차이를 비교하거나 합치기 위해 사용됩니다.
문제에서 요구하는 것은 단순히 TEST50 테이블의 데이터를 5배로 증가시켜 총 25건의 결과를 만드는 것입니다. FULL OUTER JOIN을 사용하면, 조인 조건에 따라 결과가 달라질 수 있으며, 조인 조건을 명시하지 않는 한 (또는 조건이 없이 사용한다면), 실제로는 적절한 사용 사례가 아닙니다. 또한, FULL OUTER JOIN은 두 테이블 간의 모든 데이터를 합치려는 목적에 더 적합하며, 이 문제에서 요구하는 단순한 카테시안 곱을 생성하는 것과는 다른 목적을 가지고 있습니다.
따라서, 문제의 요구 사항에 따라 단순히 테이블의 모든 행 조합을 생성하려면 , (콤마)를 사용하는 것이나 CROSS JOIN이 더 적절합니다. FULL OUTER JOIN은 이 경우에는 가장 적절하지 않은 선택으로 볼 수 있습니다.
