
pytorch 특징 및 장점
- 요즘은 다 pytorch로 개발한다.
- OpenAI (텐서플로우는 Google이 만든 것)
- print로 모델 찍으면 잘 찍힌다 (텐서 플로우는 안찍힘)
- 디버깅 용이하다 (텐서플로우는 학습중 디버깅 안됨)
텐서
- 파이토치의 데이터 형태
- 단일 데이터 형식으로 된 자료들의 다차원 행렬
동적 신경망
- 훈련을 반복할 때마다 네트워크 변경이 가능한 신경망을 의미
- 예를들어 학습 중에 은닉층을 추가하거나 제거하는 등 모델의 네트워크 조작이 가능
- 연산 그래프를 정의하는 것과 동시에 값도 초기화되는 'Define by Run' 방식을 사용
torch.autograd
- 자동 미분 패키지
- 일반적으로 신경망에 사소한 변경이 있다면 신경망 구축을 처음부터 다시 시작해야되지만 쉽게 디버깅할 수 있음
torch.nn
- 신경망을 쉽게 구축 가능
torch.multiprocessing
- 동일한 데이터에 다수가 접근 가능
torch.utils
- 모델에 데이터를 제공해주는 역할
텐서를 메모리에 저장하기
- 텐서는 1차원이든 N차원이든 메모리에 저장할 때는 1차원 배열 형태가 됨
- 변환된 1차원 배열을 스토리지라고 함
- 오프셋 / 스트라이드 개념 알아볼 것
anaconda에서 실습
가상환경 만들기
- python 3.10 이상을 설치하면 파이토치와 호환성 문제 있을 수 있어 3.9.0 버전으로 가상환경을 만들자.
conda create -n torch_book python=3.9.0
conda activate torch_book가상환경 목록 확인
conda env listpytorch 설치
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidiajupyter notebook 설치
pip install jupyter notebook
jupyter notebook그 외 라이브러리 설치
pip install matplotlib
pip install seaborn
pip install scikit-learnpytorch 실습
데이터셋 다운로드
import torchvision.transforms as transforms
mnist_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (1.0,))
]) #------ 평균 0.5, 표준편차 1.0으로 데이터를 정규화(normalize)하는 조정
from torchvision.datasets import MNIST
import requests
download_root = './chap02/data/MNIST_DATASET' #------ 내려받을 경로 지정
train_dataset = MNIST(download_root, transform=mnist_transform, train=True, download=True) #------ 학습(training) 데이터셋
valid_dataset = MNIST(download_root, transform=mnist_transform, train=False, download=True) #------ 검증(validation) 데이터셋
test_dataset = MNIST(download_root, transform=mnist_transform, train=False, download=True) #------ 테스트(test) 데이터셋
신경망 만들기
- 계층(Layer) : 모듈 또는 모듈을 구성하는 한 개의 계층
- 모듈 : 한 개 이상의 계층이 모여서 구성된 것
- 모델 : 최종적으로 원하는 네트워크
np.stack vs np.concat
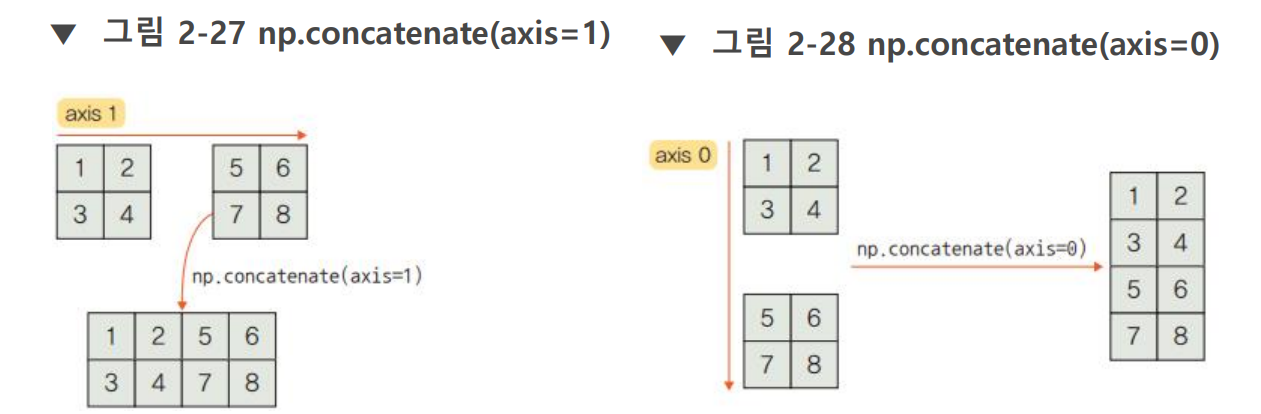
- stack을 늘리려면(차원을 늘리려면) 반드시 배열 크기 똑같아야한다.
np -> torch
categorical_data = torch.tensor(categorical_data, dtype=torch.int64)
categorical_data[:10]ravel(), reshape(), flatten()
a = np.array([[1,2],[3,4]])
print(a.ravel())
print(a.reshape(-1))
print(a.flatten())- 출력 결과
[1 2 3 4]
[1 2 3 4]
[1 2 3 4]모델 네트워크 생성
class Model(nn.Module):
def __init__(self, embedding_size, output_size, layers, p=0.4):
super().__init__()
self.all_embeddings = nn.ModuleList([nn.Embedding(ni, nf) for ni, nf in embedding_size])
self.embedding_dropout = nn.Dropout(p)
all_layers = []
num_categorical_cols = sum((nf for ni, nf in embedding_size))
input_size = num_categorical_cols
for i in layers:
all_layers.append(nn.Linear(input_size, i))
all_layers.append(nn.ReLU(inplace=True))
all_layers.append(nn.BatchNorm1d(i))
all_layers.append(nn.Dropout(p))
input_size = i
all_layers.append(nn.Linear(layers[-1], output_size))
self.layers = nn.Sequential(*all_layers)
def forward(self, x_categorical):
embeddings = []
for i, e in enumerate(self.all_embeddings):
embeddings.append(e(x_categorical[:, i]))
x = torch.cat(embeddings, 1)
x = self.embedding_dropout(x)
x = self.layers(x)
return x모델 만들기
categorical_column_sizes = [len(dataset[column].cat.categories) for column in categorical_columns]
categorical_embedding_sizes = [(col_size, min(50, (col_size+1)//2)) for col_size in categorical_column_sizes]
total_records = 1728
test_records = int(total_records * .2)
categorical_train_data = categorical_data[:total_records - test_records]
categorical_test_data = categorical_data[total_records - test_records:total_records]
train_outputs = outputs[:total_records - test_records]
test_outputs = outputs[total_records - test_records:total_records]
print(categorical_embedding_sizes)
model = Model(categorical_embedding_sizes, 4, [200, 100, 50], p=0.4)
print(model)
개발자 블로그 ^0^