일단 제일 먼저 파이썬을 이용해서 데이터 크롤링을 해보기로 했다. 일단 데이터가 프로젝트의 생명이기도 하고 데이터를 추출해보면서 웹페이지를 어떻게 구상할지도 생각해보는게 좋을 것 같아서 말이다.
근데 사이트 하나를 혼자 힘으로 크롤링해보는건 처음이라 시행 착오가 꽤 될거라고 예상을 하긴 했지만..... 생각보다 너무 고생했다. 조금만 하면 나올 것 같아서 붙잡고 붙잡고 하느라 퀭한 눈으로 일주일을 보냈다. ㅎㅎㅎㅎ
이 고됐던 삽질의 과정을 눈에 보이는 곳에 기록해두고 나중에는 이런 실수들을 줄여가야겠다.
핵심
-
해외의 제로웨이스트 쇼핑몰 2~3곳을 파이썬 bs4 패키지를 이용해 크롤링하여 카테고리별로 DB화한다.
-
첫번째 대상 사이트: 'zero waste store'라는 미국사이트
보러가기 -
크롤링해야하는 데이터 : 카테고리명, 페이지수, 상품 타이틀, 가격, 이미지, 링크(상품 클릭 시 해당 쇼핑몰 상세페이지로 이동할 수 있도록)
-
주의 사항 : 기존에 해봤던 단순히 url과 keyword 따서 get 요청을 하는 식으로 크롤링을 돌리는게 아니라 여러개의 키워드가 있고, 이 키워드별로 여러개의 페이지수가 있다. 여느 쇼핑몰 페이지들이 그렇듯이...
그래서 이 로직을 연결하는게 이번 크롤링의 핵심.
나를 힘들게 한 몇 가지 장애물들 🤦♀️
- 내가 파이썬에 대한 개념 정립이 되어 있지 않은 상태라는.. 나의 무지함이 가장 큰 장애물이었다.... 😂
이를테면 유효범위에 대한 개념이 자바스크립트랑 다른지 함수에서 선언한 변수의 값을 리턴해줘도 함수 밖에서 불러보면 값이 없다고 나왔다...
나중에는 파이썬 기초 개념이 부족하다고 느껴져서 코드카데미로 파이썬 문법, 함수에 대한 부분을 새로 공부했다.
- 어떤 논리적인 과정으로 코드를 짰다기보다는 나오는결과를 보고 이리저리 수정해보면서 결과를 조작해봤기 때문에 나중에 내 코드를 보는데 내가 짰는데도 초면인거 같은 새로운 현상이 나타났다..... 누구냐 넌....
나중에 한참동안 고심했던 문제로 스파르타 오피스아워때 온라인으로 질문을 드렸는데 멘토님도 내 코드를 이해하는데 꽤 걸리셨다..ㅋㅋㅋㅋ 휴,...
진행 과정 로그
4월 6일
- 크롤링 첫 도전. 노마드 크롤링 강의 참고하면서 따라해가며 카테고리, 페이지 수, 제목, 가격 크롤링 했다! 근데 이건 아직 카테고리별로 모든 페이지 상품을 가져오는게 아니라 그냥 시험삼아 한 카테고리만 잡고 해본 상태였다.
4월 7일
-
전날 했던 크롤링을 페이지&카테고리를 url에 get request를 하려고 함수 만들기 시작했다. 하지만 인덴테이션 엉망으로 하고.. 함수도 요상하게 선언해서 만든게 망가졌다. 그러다 전날 추출한 카테고리를 다시 추출하려니 할 수 없어져서 여기에 몇시간을 쏟아부었다.
-
크롤링 할때 아직 find와 select_one의 차이 혹은 select / find_all을 써야하는때의 차이를 잘 구분하지 못해서 계속 에러가난다. 어제 2시간 넘게 걸리면서 안풀린 문제도 결국 이거때문이었다. 그것도 모르고 a태그 안에 있는 텍스트가 추출이 안되니까 pesudo 코드가 있는건지 같은걸 찾아헤맸고...그래도 이렇게 헤맨 덕분에 카테고리 텍스트를 메뉴바에서 크롤링하는것과 + 추가로 href 텍스트도 크롤링해야지만 페이지 url에 적용해서 페이지별 추출을 할 수 있다는걸 깨달았다.
-
내가 계속 해결 못했던 부분 박제
soup = BeautifulSoup(result.text, 'html.parser')
sidebar = soup.find("div", {"class": "sidebar-widget"})
a_tags = sidebar.find_all('a')
key = []
for a_tag in a_tags:
key.append(a_tag['href'])
print(key)4월 8일
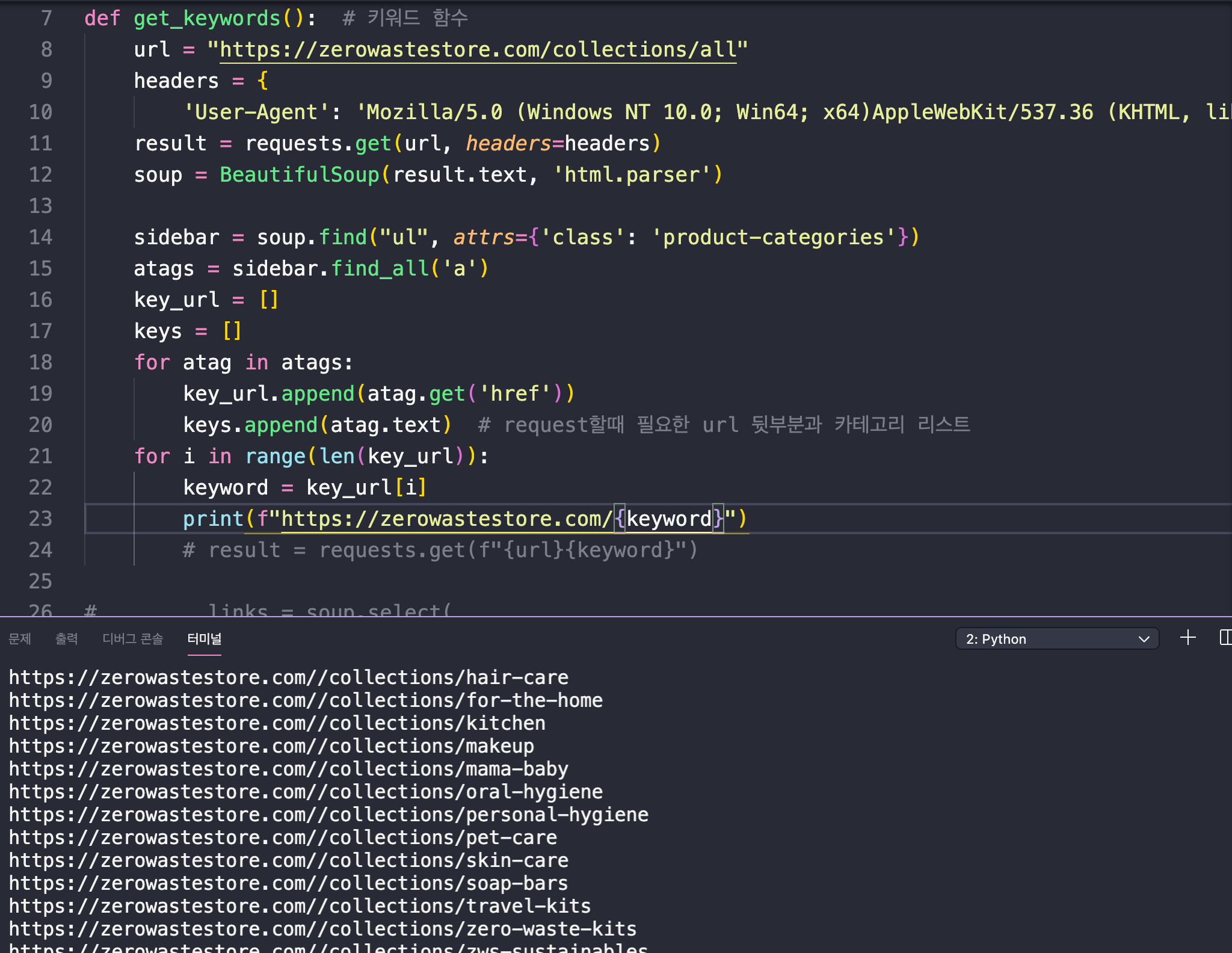
- 드디어 키워드 url 추출 완료했다! 정말 험난했다... href의 텍스트만 출력해야하는데 find['a']['href'] 를 쓰려면 객체를 추출해야해서 find_all로 찾았는데도 저 방법이 실패했다. 결국 돌고 돌아 더 쉬운 방법을 찾았으니.. 그것은 get 하하. 그리고 어제 한 것도 좀 더 정리했다.
result = requests.get(url, headers=headers)
soup = BeautifulSoup(result.text, 'html.parser')
sidebar = soup.find("ul", attrs={'class': 'product-categories'})
atags = sidebar.find_all('a')
key_url = []
keys = []
for atag in atags:
key_url.append(atag.get('href'))
keys.append(atag.text)
return keys, key_url # request할때 필요한 url 뒷부분과 카테고리 리스트
response 200 뜨는거보고 이것도 사진 찍고ㅎㅎㅎ
4월 9일
- 어제 키워드 추출을 마쳤다면 이제는 페이지수 추출이다.
- 어제 새벽까지 매달린끝에 get 요청을 했을때 200이 하나씩 뜨는거 보고 감격의 눈물을 흘릴뻔 한게 우습게도... 오늘 다시 처참히 벽에 부딪쳤다.
- 위기1:
마지막 페이지 숫자를 알아내서 range를 이용한 반복문을 돌리고 싶었다. 그래서 페이지 태그를 모두 찾아 변수 links에 넣고 출력을 해보니 세상에 마상에. '...' 이런 문자가 가운데에 있기도하고, 페이지가 하나인 키워드는 아예 해당 태그가 없어서 빈배열이 나왔다.
이걸 해결할려고 그래도 조건문 생각해서 넣은 나 칭찬해...
for i in range(len(key_url)):
keyword = key_url[i]
result = requests.get(f"https://zerowastestore.com{keyword}")
soup = BeautifulSoup(result.text, 'html.parser')
links = soup.select(
'.products-footer > .shopify-pagination > ul > li > a')
if len(links) is 0:
pages.append(1)
else:
for link in links[:-1]:
pages.append(int(link.text))
if len(pages) < 2:
last_pages.append(pages[0])
else:
last_pages.append(pages[-1]) # 각 카테고리별 마지막 페이지 추출-
위기2:
반복문을 너무 많이 엮어서 이제 로직이 너무 헷갈리는 식으로 함수가 길어졌다.
이런 코드는 전혀 좋은 코드가 아닌데... 무조건 함수를 여러개로 잘라서 붙여야지 가독성이 높아져 에러 고치는것도 쉽다고 배웠다. 근데 함수가 잘라져있을때 값이 연결이 안되어서 그냥 한 함수안에 쭉 넣어버릴 수 밖에 없었고 지금 그게 내 발목을 붙잡고 있다. -
위기3:
키워드 url 추출 + 마지막 페이지 수 추출 = get request (url + 키워드 + 페이지수)로 아이템 정보 크롤링
이 구조가 간단하다고 생각했지만 사실 키워드별로 페이지수가 다르기 때문에 이걸 적절게 맞물린 결과의 url이 나오지 않는다... 아무래도 변수와 값들의 유효범위 같은 부분에 대한 이해가 아직 부족해서 그런것 같다. 3시간을 쏟았는데 아직 해결 못해서 머리 식힐겸 다른 부분 보고 또 도전하겠다. 크롤링하면서 제일 어려웠던 부분...
4월 10일
-
오피스아워때 멘토님께 질문을 해보니 문제의 원인이 밝혀졌다. ㅜㅜ
위에서 돌아가는 반복문과 아래 반복문이 중첩되어서 돌아가고 있었는데 그걸 멈추게 하는 코드를 넣어줬어야 했던 것.... 드디어 카테고리별 페이지가 한번씩 돌아가는 url 주소를 만들었다. (이부분에 대한 코드를 깃헙에 올려놓은줄 알았는데 없네. 아쉽다 ) -
근데 이걸 해결하기가 무섭게 또 에러발생.ㅎㅎㅎ 아이템들이 전체가 다 추출되지 않는다. 시벌탱ㅎㅎㅎㅎ
- 그래도 기분 좋았던건 오늘 도움 주신 멘토님이 혹시 개발자 준비중이시냐고 코드를 보니까 그런거같다고 잘하셨다고 칭찬해주셨다. 헤헤.. 근데 이 코드가 약간 비효율적이니까 객체를 이용해서 카테고리 - 총 페이지수를 연결하는 구조로 하면 더 편할거라고 조언도 해주셨다.
조언 듣고 코드를 아예 새로 갈아엎을까 고민하다가.. 고생한 시간이 너무 아까워서ㅜㅜ 다음 사이트 크롤링할때 한번 시도해볼까한다.
4월 11일 토요일
- 아무리봐도 내가 짠 코드를 나도 잘 읽기 어려울만큼 가독성이 떨어지는거같아서 코드를 다시 정리하기로 했다. 역시 정리해보니 쓸데없이 쓴 코드들도 너무 많았고.. 그걸 좀 간추렸다. (이것도 몇시간 걸린건 비밀)
그리고 드디어 모든 아이템 추출에 성공했다. ㅜㅜ 나 왜울어...
터미널에서 데이터를 하나씩 턱턱 찍어내는데 갑자기 파이썬이 넘나 기특하고 이뻐보이는 매직이 일어났다.ㅠㅠ

그리고 오피스아워때 멘토님이 내가 짠 코드 파악하시느라 중간 중간 프린트를 하시면서 보시는데 그게 꽤 좋은 방법 같아 보였다.
크롤링을 할때 정보를 알아보기 쉽게 구분해주는게 좋은 것 같아서 적용해서 해봤는데 확실히 도움이 됐다. 반복문이 많을때는 특히 이렇게 해야할 것 같다.
soup = BeautifulSoup(result.text, 'html.parser')
links = soup.select(
'.products-footer > .shopify-pagination > ul > li > a')
if len(links) is 0:
pages.append(1)
else:
pages.append(int(links[-2].text))
# print('카테고리: ', keys[i], '****************************')
# 각 카테고리별 페이지 수 만큼 반복되는 반복문 만들기
for j in range(1, pages[i]+1):
res = requests.get(
f"https://zerowastestore.com/{keyword}?page={j}")
data = BeautifulSoup(res.text, 'html.parser')
products = data.find('div', {'class': 'jas_contain'})
product = products.find_all(
'div', {'class': 'product-grid-item'})
for one in product:
title = one.select_one('.product-title').text
price = one.select_one('.price').text
img_h = one.select_one(
'.product-element-top > a').get('href')
img_url = f"https://zerowastestore.com{img_h}"
img_s = one.select_one(
'.product-element-top > a > img').get('src')
img_src = f"https:{img_s}"추출한 소중한 데이터들은 도망갈새라 mongoDB에다가 호다닥 예쁘게 집어넣었다.
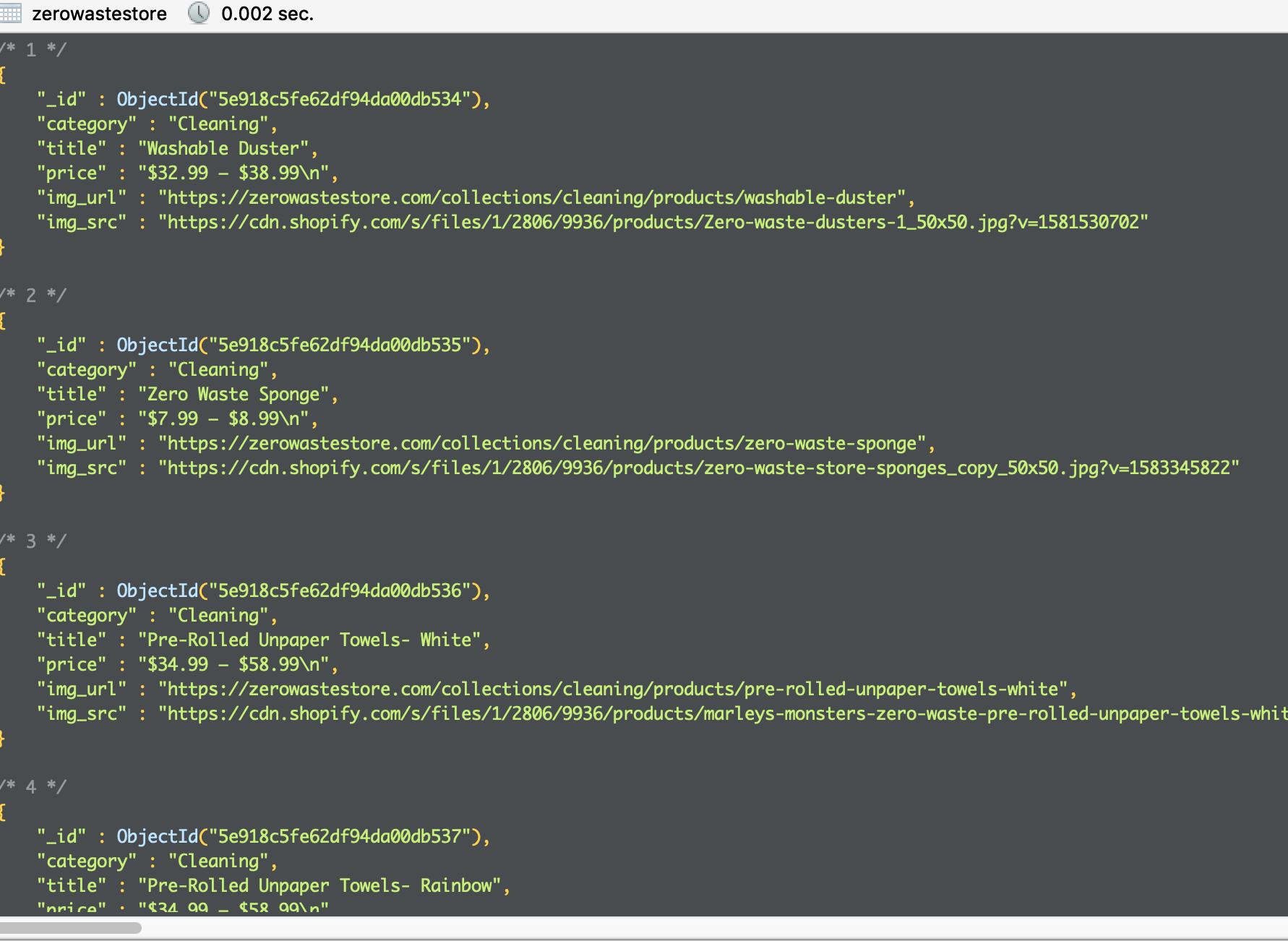
이렇게 첫번째 사이트 크롤링끝이다! (이제 겨우 첫....번째...? 허...)
이제 허버허버 html/css로 페이지 디자인 다듬어서 내 웹페이지에 예쁘게 데이터를 뿌려줘야겠다. 빨리 결과 보고싶다!!!
