2024년 2월 24일 세미나 내용
Goal
Researching the impact of self-supervised pretraining on ViT features
Motivation
- Transformers have recently emerged as an alternative to convolutional neural networks for visual recognition
- ViT are competitive with convnets but, they don’t have clear benefits over the convnets(More computationally demanding, require more training data)
- The success of Transformers in vision can be explained by the use of super-vision in the pretraining of model(Self-supervised pretraining)
Contribution
Identified several properties that only emerge with self-supervised ViT
Self-supervised ViT features contain the scene layout and object boundaries
Self-supervised ViT features perform well with a basic k-NN without any finetuning(78.3% top-1 accuracy on ImageNet)
DINO simplifies self-supervised training by predicting the output of a teacher network
Framework is flexible and works on both convnets and ViTs without the need to modify the architecture
Validated the synergy between DINO and ViT by outperforming previous self-supervised features on the ImageNet linear classification benchmark

Approach
SSL with Knowledge Distillation
Knowledge Distillation is a learning paradigm that training a student network to match the output of a given teacher network
Given an input image x, both networks output probability distributions over K dimensions denoted by P(s) and P(t)
The Probability P is obtained by normalizing the output of the network g with a softmax function
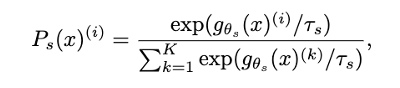
𝝉_𝒔 > 0 a temperature parameter that controls the sharpness of the output distribution
Learning to match the distributions by minimizing the cross-entropy loss
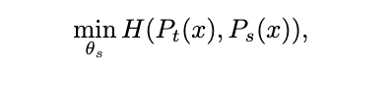
This set contains two global views and several local views
All crops are passed through the student while only the global views are passed through the teacher(Encouraging “local-to-global” correspondences)
Both networks share the same architecture g with different sets of parameters and learn the parameters by minimizing with SGD
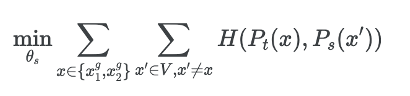

Teacher Network
No teacher network given a priori, built from past iterations of the student network
Freezing the teacher network over an epoch works well in this framework
The update rule is θt←λθt+(1−λ)θs
Following a cosine schedule from 0.996 to 1 during training
Originally the momentum encoder has been introduced a s a substitute for a queue in contrastive learning
However, in this framework, the role differs since no queue nor a contrastive loss, closer to the role of the mean teacher used in self-training
Network Architecture
The neural network g is composed of a backbone f and projection head h
H: 𝐠= 𝐡∘𝒇
The projection head consists of a 3-layer multi-layer perceptron
ViT architectures do not use batch normalization by default
Applying DINO to ViT, no BN in the projection heads
Avoiding collapse
The framework can be stabilized with multiple normalizations, it can also work with only a centering and sharpening of the momentum teacher outputs to avoid model collapse
Centering prevents one dimension to dominate but encourages collapse to the uniform distribution
Sharpening has the opposite effect(Encouraging one dimension to dominate)
Applying both operations balances their effects which is sufficient to avoid collapse in presence of a momentum teacher
Centering operation only depends on first-order batch statistics and can be interpreted as adding a bias term c to the teacher
Center c is updated with an exponential moving average
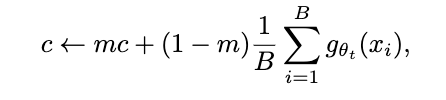
Output sharpening is obtained by using a low value for the temperature in the teacher softmax normalization
Implementation and evaluation protocols
Vision Transformer
Following the mechanism of the Vision Transformer(ViT)
Implementation used in DeiT
Input grid of non-overlapping contiguous image patches of resolution N * N(typically N = 16 or N = 8)
The patches are passed through a linear layer to form a set of embeddings
The role of this token is to aggregate information from the entire sequence and attach the projection head h at its output(CLS token)
The set of patch token and CLS token are fed to a standard Transformer network with a pre-norm layer normalization
Updating the token representations by looking at the other token repensentations with an attention mechanism
Implementation details
Pretrained the models on the ImageNet dataset
Batch size of 1024, adamw optimizer
Distributed over 16 GPUs when using ViT-S/16
The learning rate is linearly ramped up during the first 10 epochs to its base value
Lr = 0.0005 * batchsize/256
The weight decay follows a cosine schedule from 0.04 to 0.4
Attention head and segmentation


Fig1. Self-attention from ViT model with the test image
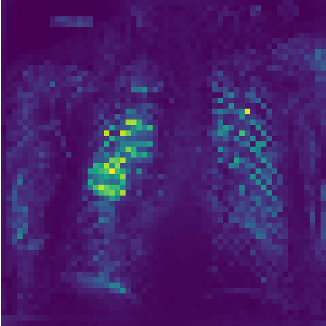
Fig2. Segmentation and attention result of patient with pneumonia
Gradient 기반의 모델만 보다가 새로운 방식의 모델을 보니 흥미로운 논문이라는 생각이 듭니다. 앞으로도 다양하고 깊은 논문을 찾아 읽어야할 것 같습니다.
