Abstract and Paper Information
Contextrast, contrastive learning-based semantic segmentation method that allows to capture local/global contexts and comprehend their relationships
Contextual contrastive learning(CCL)
Boundary-aware negative(BANE)
CCL: obtains local/global context from multi-scale feature aggregation and inter/intra-relationshop of features
BANE: Selects embedding features along the boundaries of incorrectly predicted regions to employ them as harder negative samples
Contrastive learning aims to make the networks understand the semantic context better during the training process
Previous researches overlooked the significance of multi-scale features
Extract Multi-scale embedding features from multiple encoder layers
CCL is proposed to acquire embedding features from multiple encoder layers (local and global contexts)
Representative anchors in each layer, semantic centroids
Anchors of the last layer are used to update anchors in each layer
BANE: focused boundary region
Sample negative examples along the boundaries of incorrectly predicted regions
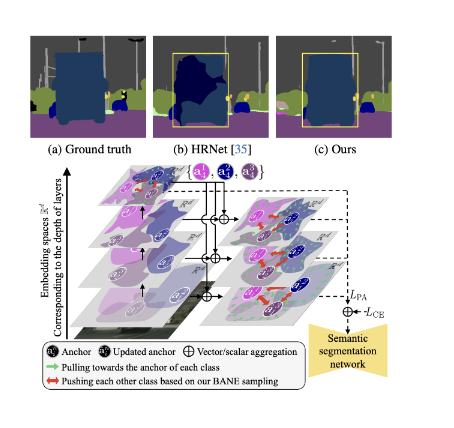
Methods
Representative anchors
-
Multi-scale-aware salient features implicitly representing the class by leveraging hierarchical design
-
Sample the features corresponding to the boundaries within the regions that were incorrectly predicted as the negative samples
CCL
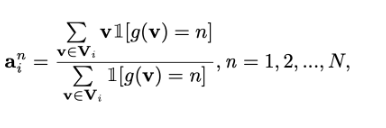
Represent anchor corresponding Ai
Vi is an embedded feature vector set from the feature of the I-th encoder layer’s feature map
V: feature map
g function represents a function that returns the ground truth semantic label of each embedding feature vector
Lower-level anchors Ai are updated with the representative anchor of the last layer
Aˆ i = wlAi + whAI = {aˆ 1 i , aˆ 2 i , ..., aˆ N i }
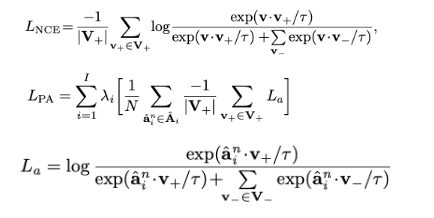
Incorporate InfoNCE(음의 예시들과 덜 유사한 정도 측정) loss and PA loss
-
Pixel-anchor loss aims to optimize embedding features by minimizing the distance between intra-class features and their corresponding representative anchors while maximizing the separation between inter-class features
-
Pixel-anchor loss operates in conjunction with the conventional pixel-wise cross-entropy loss: Complementary approach to enhance segmentation performance
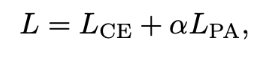
BANE sampling
Effective Negative sampling approach that considers the boundaries of the prediction error to increase the quality
Step1. Decomposing prediction output to class-wise(클래스별) binary error maps
Step2. Distance transform based on the class-wise error maps
Step3. Selecting negative samples
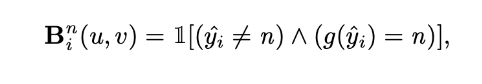
yi(hat) denotes the predicted class for the n-th layer down sampled from the predicted class in the final layer
G: labeling function
Next, B is converted to a class-wise distance map D
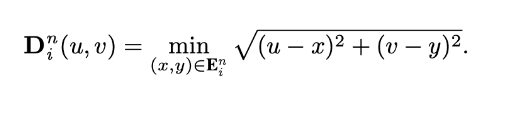
Incorrectly predicted regions: lower value indicates a higher probability of the pixel being on the boundary
Select embedding vectors corresponding to the lower K percentage of the smallest distances in D as negative samples for each n-th representative anchor

결과 및 후기
기존의 탐지 결과에서 Anchor를 조절해 가면서 이전 Layer의 특징을 반영할 수 있도록 모델을 설계한 점이 가장 흥미로웠다.
보통의 경우 최종 Layer의 특징을 반영하는데, 향후 연구를 할 때, 새로운 아이디어를 얻을 수 있을 것 같다.
