2024년 3월 29일 세미나 내용
Goal
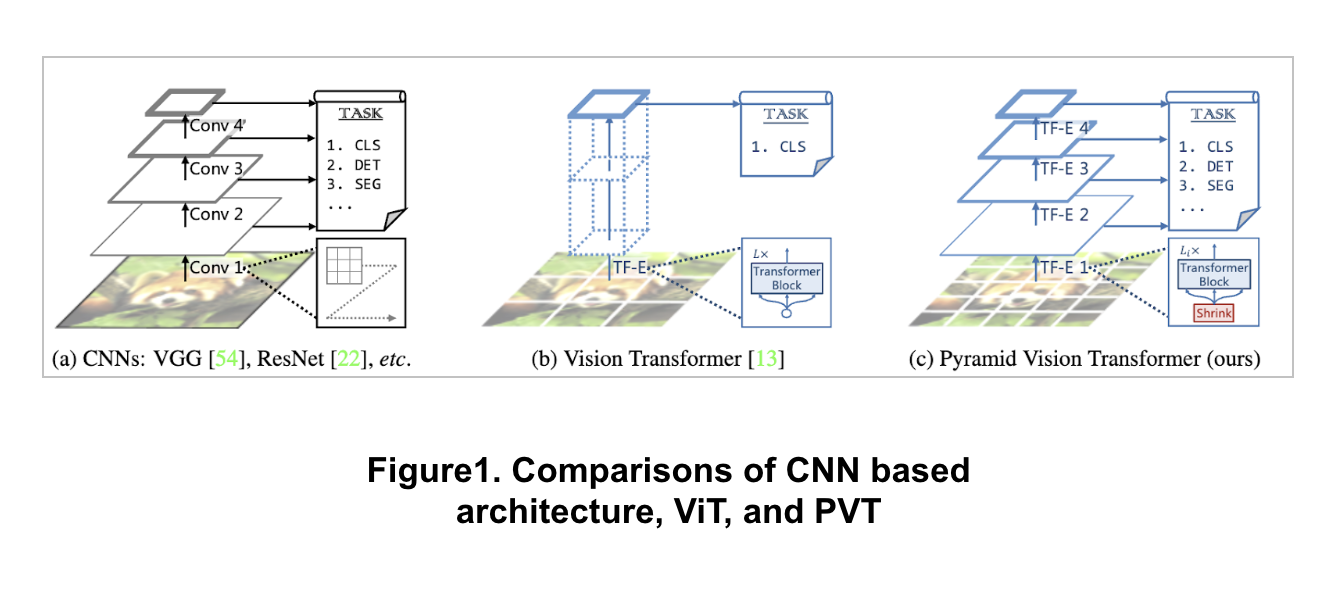
Overcoming the difficulties of porting Transformer to various dense prediction tasks
Motivation
ViT is applicable to image classification, ViT is challenging to directly adapt it to pixel-level dense predictions
Object detection and segmentation
Output feature map is single-scale and low-resolution
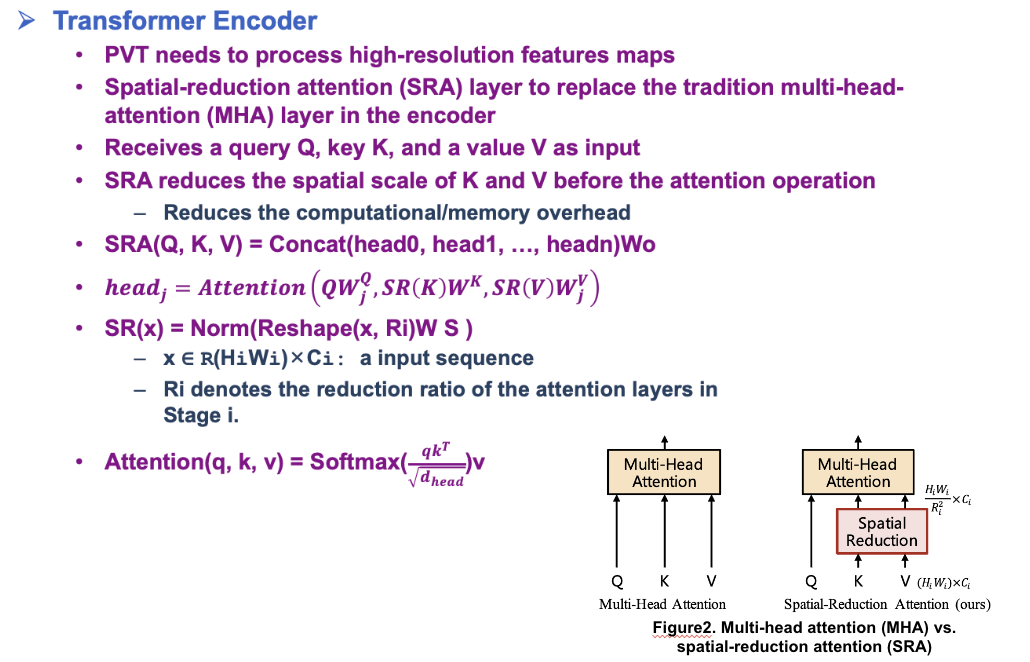
Computational and memory costs are high even for common input image sizes
Contribution
PVT uses a progressive shrinking pyramid to reduce the computations of large feature maps
PVT obtains the advantages of both CNN and Transformer
Unified backbone for vision tasks without convolutions, where it can be used as a replacement for CNN backbones
Improved performance of various tasks, including object detection, instance and semantic segmentation
PVT+RetinaNet achieves 40.4AP on the COCO dataset, surpassing ResNet50+RetinNet (36.3AP)

Application to Downstream Tasks
Image-Level Prediction
Series of PVT models with different scales
PVT Tiny, -Small, -Medium, -Large
Parameter numbers are similar to ResNet18, 50, 101, 152
Pixel-Level Dense Prediction
PVT models to representative dense prediction methods
RetinaNet, Mask R-CNN, Semantic FPN
Initialized the PVT backbone with the weights pre-trained on ImageNet
Used the output feature pyramid as the input of FPN
None of the layers of the PVT are frozen
Bilinear interpolation on the pre-trained position embeddings according to the input resolution
Image Clasification
On the ImageNet 2012 Dataset
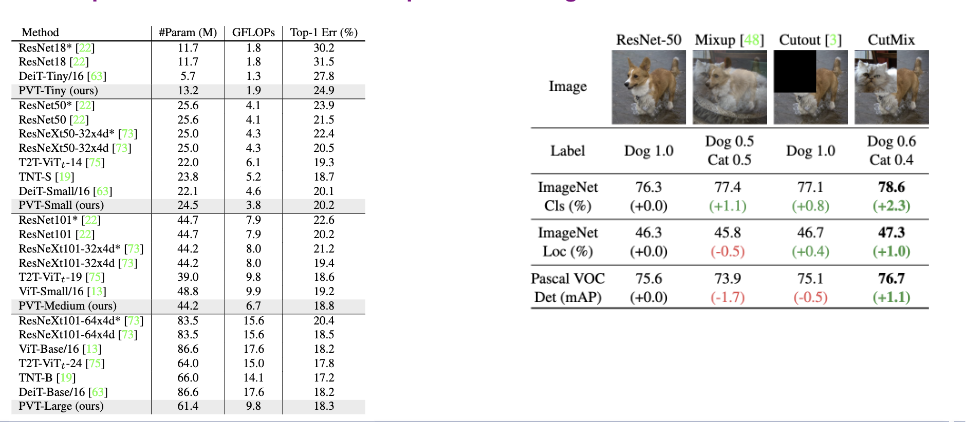
Followed DeiT and apply random cropping, random horizontal flipping, label-smoothing regularization, mixup, CutMix[1], and random erasing
AdamW with a momentum of 0.9, mini-batch size 128
PVT models are superior to conventional CNN backbonds under similar parameter numbers and computational budgets
Object Detection
Conducted on the challenging COCO benchmark
PVT backbones on RetinaNet and Mask R-CNN
Weights pre-trained on ImageNet
Trained with a batch size of 16 on 8 V100 GPUs and optimized by AdamW
PVT-based models significantly surpasses the counterparts
Similar results are found in instance segmentation experiments based on Mask R-CNN
Semantic Segmentation
ADE20K dataset
Evaluated PVT backbones on the basis of Semantic FPN
Backbone is initialized with the weights pre-trained on ImageNet
PVT-based models consistently outperforms the models based on ResNet or ResNeXt
A longer training schedule and multi-scale testing, PVT-Large+Semantic FPN archives the best mIoU of 44.8, very close to the state-of-the-art performance of the ADE20K benchmark
