면접에서 대답하지 못한 트랜잭션 격리수준, 다시 제대로 정리해보기
어제 면접을 보면서 트랜잭션 관련 질문에 답을 하다가, 개념을 "어렴풋이" 알고 있다는 걸 스스로 느꼈다.
기존에 이 블로그에 정리를 했지만 부족했다.
특히 READ COMMITTED, REPEATABLE READ, SERIALIZABLE 차이를 설명할 때, 단순히 외운 문장만으로는 부족했다.
그래서 이번 기회에 트랜잭션 격리수준을 처음부터 다시 정리해보려고 한다.
이 글은 내가 다시 공부하면서 이해한 내용을 바탕으로 정리한 글이다.
트랜잭션 격리수준이란?
트랜잭션 격리수준(Isolation Level)은 여러 트랜잭션이 동시에 실행될 때,
한 트랜잭션이 다른 트랜잭션의 변경 내용을 어디까지 볼 수 있게 할 것인지를 정하는 기준이다.
쉽게 말하면 이런 문제를 다룬다.
- 어떤 트랜잭션이 아직 커밋하지 않은 값을 다른 트랜잭션이 읽어도 되는가?
- 같은 쿼리를 두 번 실행했을 때 결과가 달라져도 되는가?
- 처음에는 없던 row가 다시 조회했을 때 갑자기 나타나도 되는가?
격리수준이 높아질수록 정합성은 좋아지지만, 일반적으로 동시성과 성능은 더 희생될 수 있다.
격리수준의 4단계
SQL 표준에서 다루는 대표적인 격리수준은 아래 4가지다.
READ UNCOMMITTEDREAD COMMITTEDREPEATABLE READSERIALIZABLE
이 격리수준에 따라 아래 3가지 이상 현상이 허용되거나 방지된다.
Dirty ReadNon-Repeatable ReadPhantom Read
먼저 이상 현상부터 이해하기
격리수준을 이해하기 전에, 각각이 무엇을 막기 위한 것인지부터 이해하는 게 훨씬 쉽다.
1. Dirty Read
Dirty Read는 다른 트랜잭션이 아직 커밋하지 않은 데이터를 읽는 현상이다.
예를 들어:
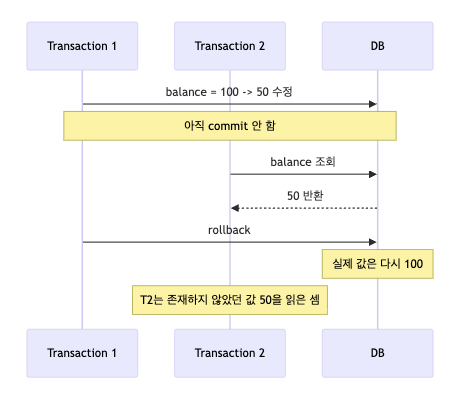
이 경우 T2는 실제로는 확정되지 않은 값을 읽었다.
만약 T1이 나중에 롤백되면, T2는 "존재하지 않았던 데이터"를 읽은 셈이 된다.
이게 바로 Dirty Read다.
2. Non-Repeatable Read
Non-Repeatable Read는 한 트랜잭션 안에서 같은 row를 두 번 읽었는데 값이 달라지는 현상이다.
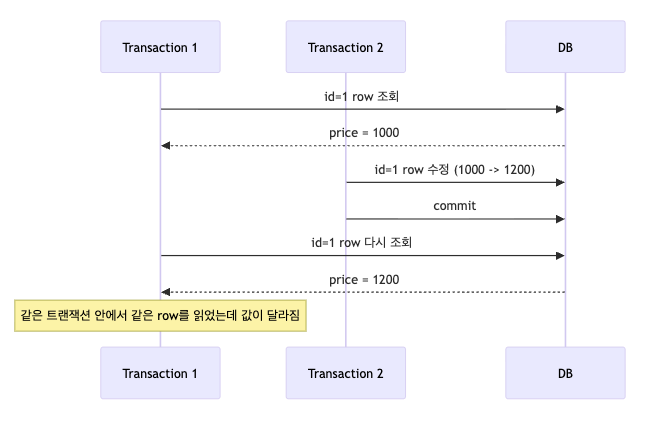
즉, 같은 조건으로 같은 row를 읽었는데 중간에 다른 트랜잭션이 커밋하면서 값이 바뀌어 보이는 것이다.
3. Phantom Read
Phantom Read는 같은 조건으로 다시 조회했는데, 처음에는 없던 row가 나타나거나 있던 row가 사라지는 현상이다.
이건 row의 값이 바뀌는 것이 아니라 조회 결과의 row 집합 자체가 바뀌는 것이 핵심이다.
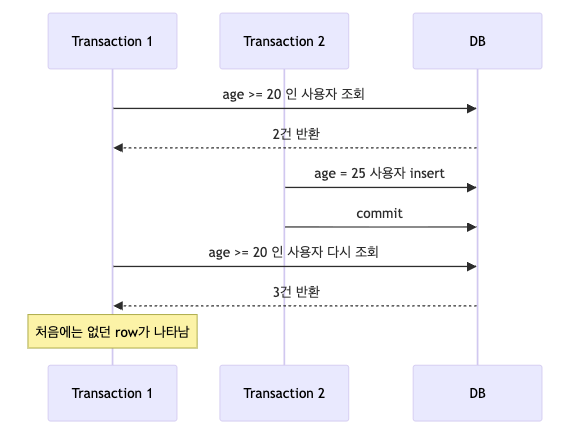
같은 조건으로 조회했는데 "유령처럼" 새로운 row가 나타났다고 해서 Phantom Read라고 부른다.
한 번에 보는 정리 표
| 격리수준 | Dirty Read | Non-Repeatable Read | Phantom Read |
|---|---|---|---|
| READ UNCOMMITTED | 허용 | 허용 | 허용 |
| READ COMMITTED | 방지 | 허용 | 허용 |
| REPEATABLE READ | 방지 | 방지 | 표준상 허용 |
| SERIALIZABLE | 방지 | 방지 | 방지 |
여기서 중요한 점이 하나 있다.
이 표는 표준적인 개념 정리에 가깝다.
실제 DBMS 구현, 특히 MySQL InnoDB는 MVCC와 lock 동작 때문에 체감 동작이 조금 다를 수 있다.
이 부분은 뒤에서 다시 설명하겠다.
아래에서는 트랜잭션 간 격리 수준이 낮은 레벨부터 높은 레벨순으로 살펴보겠다.
READ UNCOMMITTED
개념
가장 낮은 격리수준이다.
말 그대로 커밋되지 않은 값도 읽을 수 있다.
즉, 다른 트랜잭션이 아직 작업 중인 데이터도 조회가 가능하다.
어떤 문제가 생기나?
가장 대표적인 문제가 Dirty Read다.
이전에 보았던 것과 같이 커밋하지 않은 데이터를 읽을 수 있는 문제가 발생한다.

이 수준에서는 정합성 문제가 크기 때문에 실무에서는 거의 사용하지 않는다.
이렇게 되면 T1 이 롤백을 해도 T2 는 변경한 값을 읽기 때문에 T1 이 비즈니스상 의도한 롤백이 되어야 하는 데이터를 T2 는 잘못 읽는 상황이 되므로 시스템에 상당한 혼란을 초래할 수 있다.
정리
- 장점: 동시성은 높을 수 있다.
- 단점: Dirty Read 발생 가능
- 실무 사용성: 매우 낮음
READ COMMITTED
개념
READ COMMITTED는 커밋된 데이터만 읽을 수 있는 격리수준이다.
즉, Dirty Read는 막는다.
다른 트랜잭션이 수정 중이더라도, 커밋되기 전까지는 그 값을 읽지 않는다.
어떤 문제를 막을 수 있나?
Dirty Read는 방지된다.
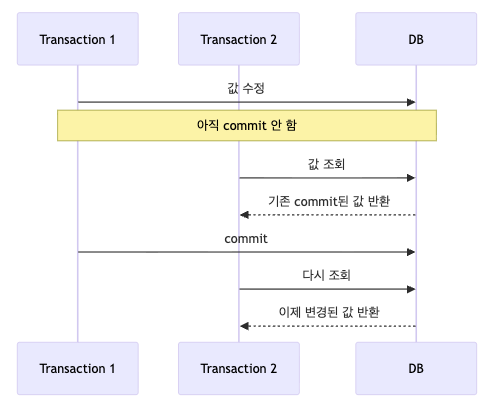
즉, 커밋되지 않은 값은 보이지 않는다.
그런데 왜 문제가 남아있을까?
READ COMMITTED에서는 같은 트랜잭션 안에서도 조회 시점마다 최신 커밋 데이터를 읽을 수 있다.
그래서 같은 row를 두 번 읽었는데 결과가 달라질 수 있다.
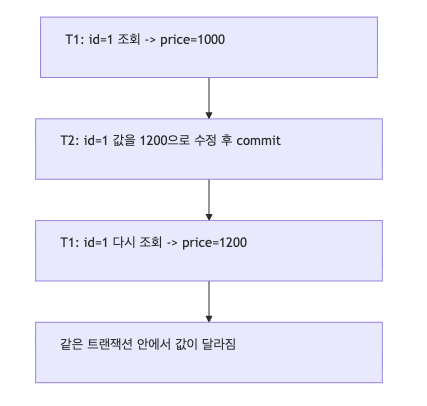
Non-Repeatable Read 예시
같은 트랜잭션에서 데이터 변경 예시
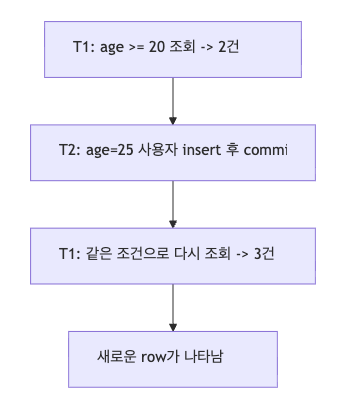
Phantom Read 예시
같은 트랜잭션에서 데이터 추가 예시
정리
- Dirty Read 방지
- Non-Repeatable Read 가능
- Phantom Read 가능
- PostgreSQL 기본 격리수준
실무에서는 많이 사용되는 수준이다.
정합성과 성능 사이에서 현실적인 균형점으로 자주 선택된다.
REPEATABLE READ
개념
REPEATABLE READ는 같은 트랜잭션 안에서 동일한 row를 반복해서 읽을 때 일관된 결과를 보장하는 격리수준이다.
이름 그대로 "반복해서 읽어도 같은 결과"를 목표로 한다.
어떻게 이걸 가능하게 할까?
여기서 등장하는 개념이 MVCC다.
MVCC란?
MVCC(Multi-Version Concurrency Control)는
하나의 데이터에 대해 여러 버전을 관리하면서 읽기와 쓰기 충돌을 줄이는 방식이다.
쉽게 말하면:
- 어떤 트랜잭션이 데이터를 수정하면
- 예전 버전을 바로 없애지 않고
- 읽는 쪽에서는 자신이 봐야 하는 시점의 버전을 읽게 한다
그래서 읽기 트랜잭션은 락으로 막히지 않고도 비교적 일관된 결과를 볼 수 있다.
Undo Log는 뭐고 MVCC와 무슨 관계가 있을까?
MySQL InnoDB 기준으로는 변경 이전 정보가 Undo Log에 저장되고,
트랜잭션은 이 정보를 활용해 이전 버전 데이터를 읽을 수 있다.
즉,
- MVCC는 여러 버전의 데이터를 다루는 큰 개념
- Undo Log는 그걸 구현하는 데 쓰이는 장치 중 하나
REPEATABLE READ에서 보이는 그림
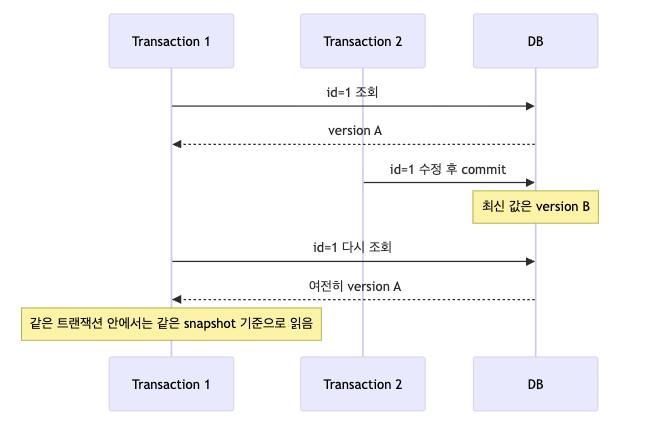
즉, T2가 중간에 값을 바꿔도 T1은 자신이 처음 읽기 시작한 시점의 snapshot을 기준으로 읽는다.
그래서 Non-Repeatable Read를 방지할 수 있다.
그런데 Phantom Read는?
여기서 많이 헷갈린다.
표준적인 설명으로는:
- REPEATABLE READ는 Non-Repeatable Read는 막지만
- Phantom Read는 막지 못한다
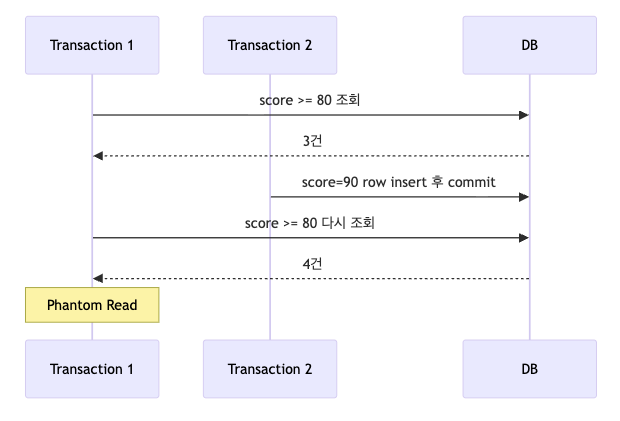
즉 같은 조건으로 다시 조회했을 때 새로운 row가 나타날 수 있다는 뜻이다.
표준적인 Phantom Read 예시
그런데 MySQL InnoDB에서는 왜 다르게 느껴질까?
MySQL InnoDB는 REPEATABLE READ에서 MVCC와 next-key lock 등의 구현 덕분에
일반적인 consistent read에서는 팬텀 리드가 잘 드러나지 않을 수 있다.
즉 아래처럼 단정하면 위험하다.
- REPEATABLE READ에서는 팬텀 리드가 절대 발생하지 않는다
- REPEATABLE READ에서는 팬텀 리드가 무조건 발생한다
더 정확한 표현은 이렇다.
표준 개념상 REPEATABLE READ는 Phantom Read를 완전히 방지하는 수준은 아니다.
하지만 MySQL InnoDB는 MVCC와 lock 구현 때문에 특정 상황에서는 팬텀 리드가 잘 보이지 않을 수 있다.
그런데 왜 MySQL InnoDB에서는 REPEATABLE READ에서 팬텀 리드가 잘 보이지 않을까?
표준적인 설명에서는 REPEATABLE READ에서도 팬텀 리드가 발생할 수 있다고 본다.
하지만 MySQL InnoDB는 MVCC 기반의 consistent read를 사용하기 때문에, 일반적인 SELECT에서는 같은 트랜잭션 안에서 처음 조회한 시점의 snapshot을 계속 기준으로 삼는다.
즉, 조회할 때 매번 현재 테이블의 최신 레코드를 그대로 읽는 것이 아니라,
Read View를 기준으로 내 트랜잭션이 볼 수 있는 버전만 읽는다.
InnoDB에서 각 레코드는 내부적으로 다음과 같은 버전 정보를 가진다.
- 이 레코드를 마지막으로 변경한 트랜잭션 ID
- 이전 버전을 따라갈 수 있는 undo log 포인터
그래서 어떤 트랜잭션이 중간에 새로운 row를 insert하더라도,
현재 트랜잭션의 snapshot 시점보다 나중에 커밋된 데이터라면 그 row는 조회 대상에서 제외된다.
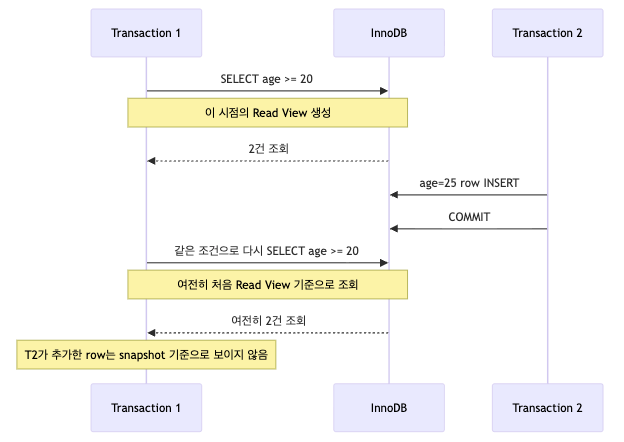
즉, MySQL InnoDB의 REPEATABLE READ에서 일반 조회 시 팬텀 리드가 잘 보이지 않는 이유는
조회 시점마다 최신 테이블 상태를 그대로 읽는 것이 아니라, 트랜잭션이 가진 snapshot과 undo log 기반의 이전 버전을 사용해 일관된 읽기를 제공하기 때문이다.
다만 이 설명은 일반적인 non-locking SELECT(consistent read) 기준이다.
SELECT ... FOR UPDATE 같은 locking read는 동작 방식이 다르고, 이때는 next-key lock 같은 락 개념으로 함께 이해해야 한다.
조금 더 기술적으로 보면: Read View, trx_id, roll_pointer
InnoDB의 MVCC를 조금 더 내부적으로 보면, 각 row에는 현재 버전과 함께 버전 판단에 필요한 정보가 붙어 있다. 대표적으로 많이 언급되는 값이 trx_id와 roll_pointer다.
trx_id- 이 row 버전을 마지막으로 변경한 트랜잭션 ID
roll_pointer- 이전 버전 정보가 저장된 undo log를 따라갈 수 있는 포인터
그리고 트랜잭션이 일반 SELECT를 수행하면, InnoDB는 그 시점의 가시성 기준인 Read View를 만든다. 이 Read View에는 “어떤 트랜잭션의 변경은 볼 수 있고, 어떤 트랜잭션의 변경은 아직 보면 안 되는지”를 판단하기 위한 정보가 들어 있다.
조회 시 InnoDB는 단순히 테이블의 최신 row만 읽는 것이 아니라, 아래와 같은 방식으로 동작한다.
- 현재 row 버전의
trx_id가 내Read View기준에서 보이는지 확인한다. - 보이면 현재 row 버전을 그대로 읽는다.
- 보이지 않으면
roll_pointer를 따라 undo log에 저장된 이전 버전으로 이동한다. Read View에서 보이는 버전을 찾을 때까지 이 과정을 반복한다.
그림으로 보면 아래와 같다.

예를 들어, T1이 처음 조회를 수행해 Read View를 만든 뒤,
그 이후 T2가 새로운 row를 insert하고 commit했다고 가정해보자.
이때 T1이 다시 같은 조건으로 조회하면, 새로 추가된 row는 테이블에는 존재하지만
그 row의 trx_id는 T1의 Read View 기준으로는 “너무 나중에 생긴 버전”이기 때문에 보이지 않는다.
즉 물리적으로 row가 존재하는 것과, 현재 트랜잭션에서 그 row가 가시적(visible) 인 것은 다른 문제다.
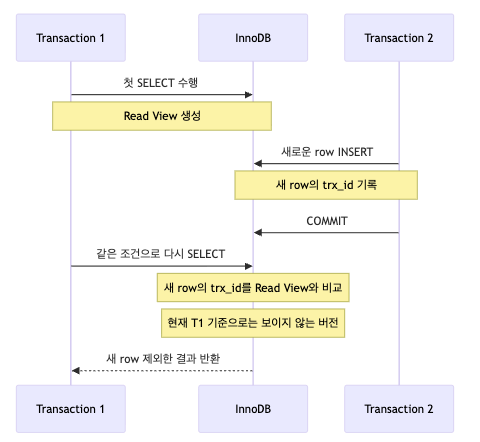
즉, MySQL InnoDB의 REPEATABLE READ에서 일반 조회 시 팬텀 리드가 잘 보이지 않는 이유를 조금 더 기술적으로 표현하면 다음과 같다.
InnoDB는 row의 최신 버전을 무조건 읽는 것이 아니라,
Read View로 가시성을 판단하고, 필요하면 roll_pointer를 따라 undo log의 이전 버전까지 내려가며 현재 트랜잭션에서 볼 수 있는 버전을 찾는다. 그래서 트랜잭션 시작 이후 다른 트랜잭션이 추가한 row라도, 현재 트랜잭션의 snapshot 기준에 맞지 않으면 조회 결과에 나타나지 않는다.
정리
- Dirty Read 방지
- Non-Repeatable Read 방지
- Phantom Read는 표준상 허용
- 단, MySQL InnoDB는 구현 특성상 체감 동작이 다를 수 있음
SERIALIZABLE
개념
SERIALIZABLE은 가장 높은 격리수준이다.
이 수준은 여러 트랜잭션이 동시에 실행되더라도,
결과만 보면 마치 하나씩 순서대로 실행된 것처럼 보이게 하는 수준이다.
즉 가장 안전한 대신, 그만큼 동시성과 성능 비용이 크다.
왜 가장 안전할까?
다른 트랜잭션의 변경으로 인해 읽기 결과가 흔들릴 수 있는 여지를 거의 없애기 때문이다.
어떤 현상을 막을 수 있나?
- Dirty Read 방지
- Non-Repeatable Read 방지
- Phantom Read 방지
즉 가장 강한 정합성을 제공한다.
왜 성능이 떨어질까?
정합성을 보장하려면 충돌 가능성이 있는 작업을 더 많이 제어해야 한다.
그 결과:
- 락 대기 증가
- 동시성 감소
- 처리량 감소
같은 비용이 발생할 수 있다.
주의할 점
SERIALIZABLE의 내부 구현은 DBMS마다 다를 수 있다.
예를 들어:
- 어떤 DB는 락 중심으로 동작하고
- 어떤 DB는 충돌 감지 후 롤백 방식으로 동작하고
- MySQL InnoDB와 PostgreSQL도 구현이 다르다
MySQL InnoDB를 공부할 때 같이 나오는 개념들
격리수준을 공부하다 보면 MySQL InnoDB에서 아래 개념들이 같이 등장한다.
- Record Lock
- Gap Lock
- Next-Key Lock
- MVCC
- Undo Log
MySQL InnoDB의 락을 공부하다 보면 Record Lock, Gap Lock, Next-Key Lock이 자주 등장한다. 처음 보면 모두 비슷해 보이지만, 실제로는 무엇을 잠그는지가 다르다.
핵심은 하나다.
InnoDB는 보통 "테이블 전체"를 잠그기보다,
인덱스를 기준으로 특정 레코드나 레코드 사이 구간을 잠근다.
즉 이 락들은 "행(row) 락"이라고 불리지만, 내부적으로는 인덱스 엔트리와 그 사이 범위를 잠그는 개념에 가깝다.
먼저 큰 그림: InnoDB는 왜 인덱스를 기준으로 락을 잡을까?
InnoDB는 레코드를 찾을 때 인덱스를 따라 탐색한다.
그래서 락도 "내가 실제로 스캔한 인덱스 범위"를 기준으로 잡는 경우가 많다.
예를 들어 아래처럼 인덱스 값이 있다고 가정해보자.
10 20 30 40이때 잠글 수 있는 대상은 크게 3가지다.
- 특정 값 하나: 20
- 값과 값 사이의 빈 구간: (20, 30)
- 특정 값 + 그 앞의 빈 구간: (20, 30] 또는 (10, 20] 같은 범위
이걸 각각 Record Lock, Gap Lock, Next-Key Lock으로 이해하면 쉽다.
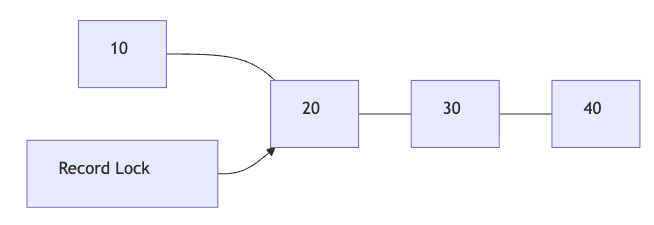
1. Record Lock
개념
Record Lock은 인덱스 레코드 하나 자체를 잠그는 락이다.
즉, 이미 존재하는 특정 row를 대상으로 잡는 락이다.
예를 들어 인덱스 값이 아래와 같을 때:
10 20 30 40
20이라는 인덱스 레코드에만 락을 거는 것이 Record Lock이다.
언제 쓰일까?
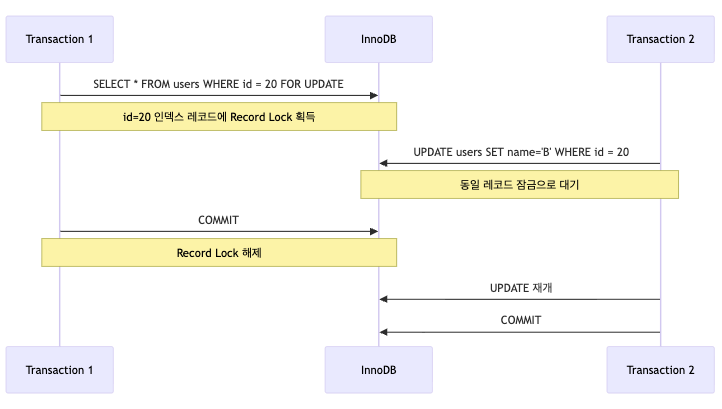
대표적으로 특정 row를 정확히 집어서 수정할 때다.
SELECT * FROM users WHERE id = 20 FOR UPDATE;만약 id가 primary key 또는 unique index라면,
InnoDB는 보통 id = 20인 해당 인덱스 레코드 하나에 락을 건다.
이때 다른 트랜잭션은:
- id = 20 row를 수정하려 하면 대기
- 하지만 id = 25를 insert하거나 id = 30을 수정하는 건 가능할 수 있다
즉 Record Lock은 정확히 그 row만 막는다.
시퀀스 다이어그램 예시
2. Gap Lock
개념
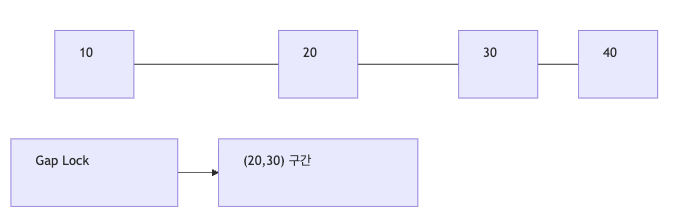
Gap Lock은 인덱스 레코드 사이의 빈 구간(gap) 을 잠그는 락이다.
즉 이미 존재하는 row를 잠그는 게 아니라, 그 사이에 새로운 row가 들어오지 못하게 막는 락이다.
예를 들어 인덱스 값이 아래와 같다면:
10 20 30 40
20과 30 사이의 빈 구간 (20, 30) 자체를 잠글 수 있다.
왜 필요할까?
팬텀 리드를 막기 위해서다.
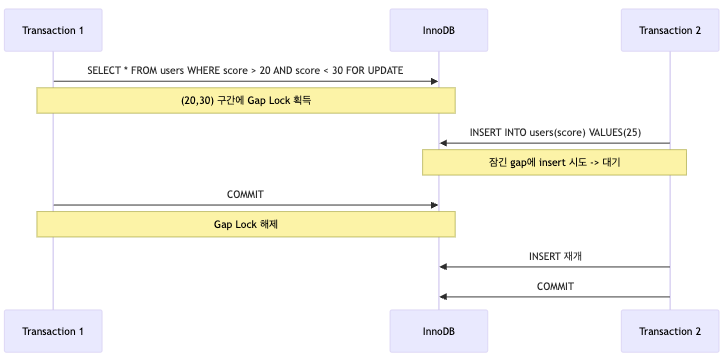
예를 들어 어떤 트랜잭션이:
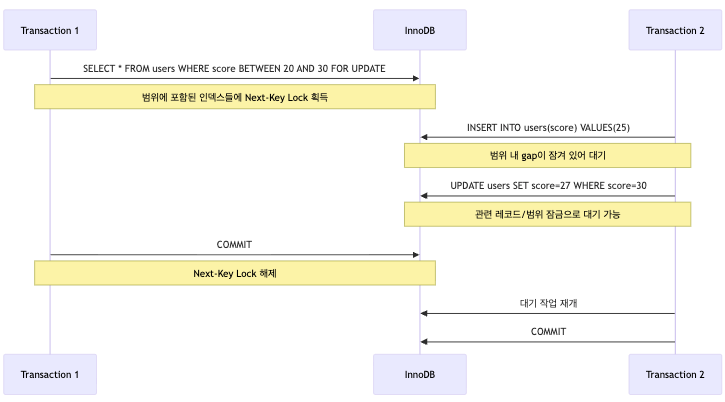
SELECT * FROM users WHERE score BETWEEN 20 AND 30 FOR UPDATE;를 수행했다고 해보자.
이때 단순히 현재 존재하는 20, 25, 30 같은 row만 잠그면,
다른 트랜잭션이 그 사이에 22, 27 같은 새로운 row를 insert할 수 있다.
그렇게 되면 같은 조건으로 다시 조회했을 때
처음에는 없던 row가 새로 나타날 수 있다.
그래서 InnoDB는 경우에 따라 레코드 자체가 아니라 그 사이 공간까지 잠근다.
중요한 특징
Gap Lock은 삽입(insert)을 막기 위한 락이라고 이해하면 된다.
즉:
- 기존 row를 읽거나 수정하는 것 자체보다
- 새로운 row가 그 구간에 들어오는 것을 제어하는 역할이 크다
시퀀스 다이어그램 예시
3. Next-Key Lock
개념
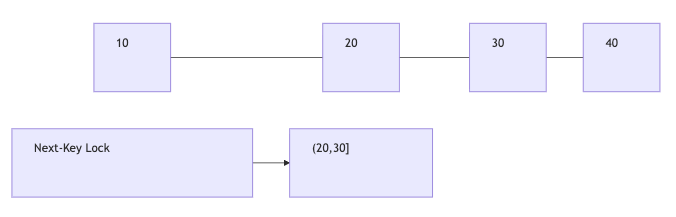
Next-Key Lock은 Record Lock + Gap Lock을 합친 개념이다.
정확히는 특정 인덱스 레코드와 그 앞의 gap을 함께 잠그는 방식으로 이해하면 된다.
예를 들어 인덱스 값이 아래와 같다고 해보자.
10 20 30 40
30에 대한 Next-Key Lock은 보통 (20, 30] 범위를 잠근다고 보면 된다.
즉:
- 30 레코드 자체도 잠그고
- 20과 30 사이에 insert되는 것도 막는다
왜 이렇게 동작할까?
팬텀 리드를 막기 위해서는
"현재 있는 row"만 잠가서는 부족한 경우가 많다.
예를 들어 조건이 범위 검색일 때:
SELECT * FROM users WHERE score >= 20 AND score < 30 FOR UPDATE;현재 score=20, score=24, score=28이 있다고 해도
다른 트랜잭션이 score=26 같은 값을 새로 insert하면 조회 결과가 달라질 수 있다.
그래서 InnoDB는 단순히 현재 row만 잠그지 않고,
그 주변 gap까지 함께 잠가서 범위 내 새로운 insert를 차단한다.
이게 Next-Key Lock이다.
시퀀스 다이어그램 예시
인덱스 기준으로 락이 잡힌다는 말은 정확히 무슨 뜻일까?
이 부분이 가장 중요하다.
InnoDB는 보통 "조건절에 맞는 row"를 추상적으로 잠그는 게 아니라,
실제로 사용한 인덱스 엔트리를 기준으로 잠근다.
즉 락은 논리적인 SQL 문장보다는
실제 실행계획과 인덱스 탐색 경로에 더 가깝다.
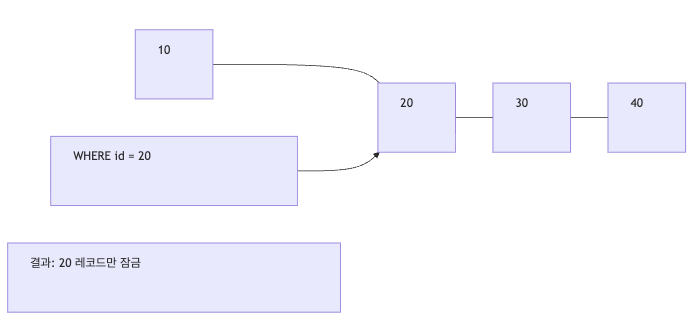
예시 1. PK/Unique Index로 정확히 한 건 조회하는 경우
SELECT * FROM users WHERE id = 10 FOR UPDATE;- id가 PK 또는 unique index라면
- 정확히 id=10 한 건만 찾는다
- 이 경우는 보통 Record Lock 중심으로 동작한다
즉 불필요하게 넓은 범위를 잠그지 않는다.
예시 2. 범위 조회를 하는 경우
SELECT * FROM users WHERE id >= 10 AND id < 20 FOR UPDATE;이 경우는 인덱스 상에서 10 ~ 20 구간을 스캔한다.
그러면 그 범위의 인덱스 레코드들과 그 사이 gap에 대해 락이 걸릴 수 있다.
즉 범위 조건에서는 Next-Key Lock이 등장하기 쉽다.
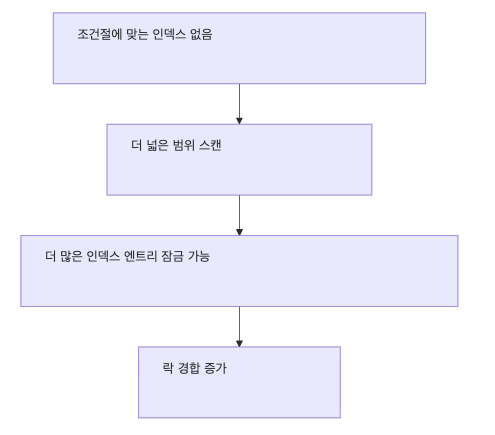
예시 3. 인덱스를 못 타는 경우
이 경우가 더 위험하다.
SELECT * FROM users WHERE name = 'jonghun' FOR UPDATE;만약 name 컬럼에 적절한 인덱스가 없다면,
InnoDB는 원하는 row를 찾기 위해 더 넓은 범위를 스캔해야 한다.
그 결과:
- 예상보다 많은 row가 잠길 수 있고
- 락 범위가 커질 수 있고
- 성능이 급격히 나빠질 수 있다
즉 인덱스 설계가 곧 락 범위 설계라고 봐도 된다.
그림으로 보는 인덱스 락 범위
1. Unique Lookup
2. Range Scan

3. No Proper Index
Record / Gap / Next-Key Lock 차이 한 번에 정리
| 락 종류 | 잠그는 대상 | 목적 |
|---|---|---|
| Record Lock | 특정 인덱스 레코드 | 기존 row 수정/삭제 충돌 제어 |
| Gap Lock | 인덱스 레코드 사이의 빈 구간 | 해당 구간 insert 방지 |
| Next-Key Lock | 레코드 + gap | 범위 조회에서 팬텀 리드 방지 |
왜 이 개념이 중요한가?
이 개념들을 알아야 아래가 이해된다.
- 왜 범위 조회에서 락 경합이 심해지는지
- 왜 인덱스가 없으면 잠금 범위가 커지는지
- 왜 SELECT ... FOR UPDATE가 생각보다 많은 row에 영향을 줄 수 있는지
- 왜 MySQL InnoDB가 팬텀 리드를 제어할 수 있는지
즉, 단순히 "row lock이 걸린다"가 아니라
정확히는 어떤 인덱스 범위가 잠기는가를 이해해야 실무 문제를 설명할 수 있다.
마지막 정리
Record Lock, Gap Lock, Next-Key Lock은 모두 InnoDB의 동시성 제어 핵심 개념이다.
- Record Lock: 기존 인덱스 레코드 하나를 잠근다
- Gap Lock: 레코드 사이의 빈 구간을 잠근다, 주로 insert를 막는다
- Next-Key Lock: 레코드와 gap을 함께 잠근다, 범위 조회와 팬텀 리드 방지에 중요하다
그리고 가장 중요한 포인트는 이것이다.
InnoDB의 락은 보통 "row"를 추상적으로 잠그는 것이 아니라,
실제로 접근한 인덱스 레코드와 그 범위를 기준으로 잡힌다.
그래서 락을 이해하려면 SQL 문장만 보는 게 아니라,
어떤 인덱스를 타는지, 범위 검색인지, unique lookup인지를 함께 봐야 한다.
격리수준을 실무에서 어떻게 바라봐야 할까?
트랜잭션 격리수준은 단순 암기 과목처럼 외우기 쉽다.
하지만 실무에서는 아래 기준으로 보는 게 더 중요하다고 느꼈다.
1. 어떤 이상 현상을 허용할 것인가?
무조건 높은 격리수준이 정답은 아니다.
예를 들어:
- 정합성이 매우 중요한 금융/정산성 로직
- 동시에 여러 사용자가 같은 데이터를 갱신하는 로직
에서는 더 높은 수준이 필요할 수 있다.
반대로:
- 단순 조회
- 약간의 최신성 차이를 허용할 수 있는 기능
에서는 너무 높은 격리수준이 오히려 성능 병목이 될 수 있다.
2. 사용하는 DBMS의 기본 동작을 확인해야 한다
같은 REPEATABLE READ라도 DBMS마다 구현이 다를 수 있다.
예를 들어:
- MySQL InnoDB 기본 격리수준: REPEATABLE READ
- PostgreSQL 기본 격리수준: READ COMMITTED
3. 격리수준만으로 모든 동시성 문제가 해결되지는 않는다
이것도 중요한 포인트다.
격리수준은 "읽기/쓰기 충돌을 어느 정도 허용할지"에 대한 기준일 뿐이다.
실제 서비스에서는 여기에 더해서 아래가 함께 필요할 수 있다.
- unique key
- optimistic lock
- pessimistic lock
- 분산 락
- idempotency
- 재시도 전략
즉, 격리수준은 동시성 제어의 일부이지 전부가 아니다.
최종 정리
트랜잭션 격리수준은 결국
여러 트랜잭션이 동시에 실행될 때 어느 정도 수준까지 서로의 영향을 허용할 것인가를 정하는 기준이다.
정리하면:
- READ UNCOMMITTED
- 커밋 전 데이터도 읽을 수 있음
- Dirty Read 가능
- READ COMMITTED
- 커밋된 데이터만 읽음
- Dirty Read 방지
- Non-Repeatable Read 가능
- REPEATABLE READ
- 같은 트랜잭션 안에서 반복 조회 시 더 일관된 결과 보장
- MVCC와 함께 자주 설명됨
- 표준상 Phantom Read는 완전히 막지 못함
- SERIALIZABLE
- 가장 강한 정합성
- 순차 실행에 가까운 결과 보장
- 성능 비용 큼
이번에 다시 정리하면서 느낀 건,
격리수준은 단순히 "어떤 레벨이 더 높다"로 이해하면 금방 헷갈린다는 점이다.
오히려 아래 두 가지로 이해하는 게 훨씬 기억에 오래 남는다.
- 이 격리수준은 어떤 이상 현상을 막는가?
- 이 DBMS는 그걸 락과 MVCC로 어떻게 구현하는가?
면접에서도 이 관점으로 답했으면 훨씬 명확했을 것 같다.
같이 보면 좋은 키워드
- MVCC
- Undo Log
- Record Lock
- Gap Lock
- Next-Key Lock
- Optimistic Lock
- Pessimistic Lock
참고하며 다시 공부할 포인트
- MySQL InnoDB의 REPEATABLE READ 실제 동작
- PostgreSQL의 READ COMMITTED, SERIALIZABLE 구현 차이
- SELECT ... FOR UPDATE와 일반 SELECT 차이
- 팬텀 리드를 실제 SQL 예제로 재현해보기
면접에서 답을 잘 못한 주제를 그냥 넘기지 않고 다시 정리해보니,
외운 개념이 아니라 "왜 그런 현상이 생기는지"를 기준으로 이해하는 게 훨씬 중요하다는 걸 느꼈다.
