
안녕하세요 오늘은 자바에서 자주 사용하게 되는 자료구조인 HashMap, HashSet 에 대해서 알아보겠습니다.
(아래 내용은 쉬운코드 유튜브의 HashMap을 정리한 내용입니다 (맵(map)과 해시 테이블(hash table))
키워드
- hash, hash function
- capacity, load factor
- separate chaining
HashMap
Map은 Key - Value 형태의 pair를 저장하는 추상 자료 구조이며 이를 구현한 것이 HashMap 입니다. 여기서 key 는 유니크한 값으로 유지되어야 하며 동일한 key를 가지는 pair는 하나만 존재합니다.
이 Map 자료구조는 예를 들어 전화번호부나 가수 인기투표와 같이 key 들이 중복이 발생하면 안되는 하나의 key에 대응하여 값을 가지는 상황에서 사용할 수 있습니다.
HashMap은 Hash function과 배열을 사용하여 Map을 구현한 자료구조 입니다. 일반적으로 key를 조회할때 상수시간으로 접근하여 빠르게 조회할 수 있는 장점이 있습니다. Hash function은 유니크한 값을 input으로 넣었을때 정수 int 형태의 output으로 반환하는 특징이 있습니다.
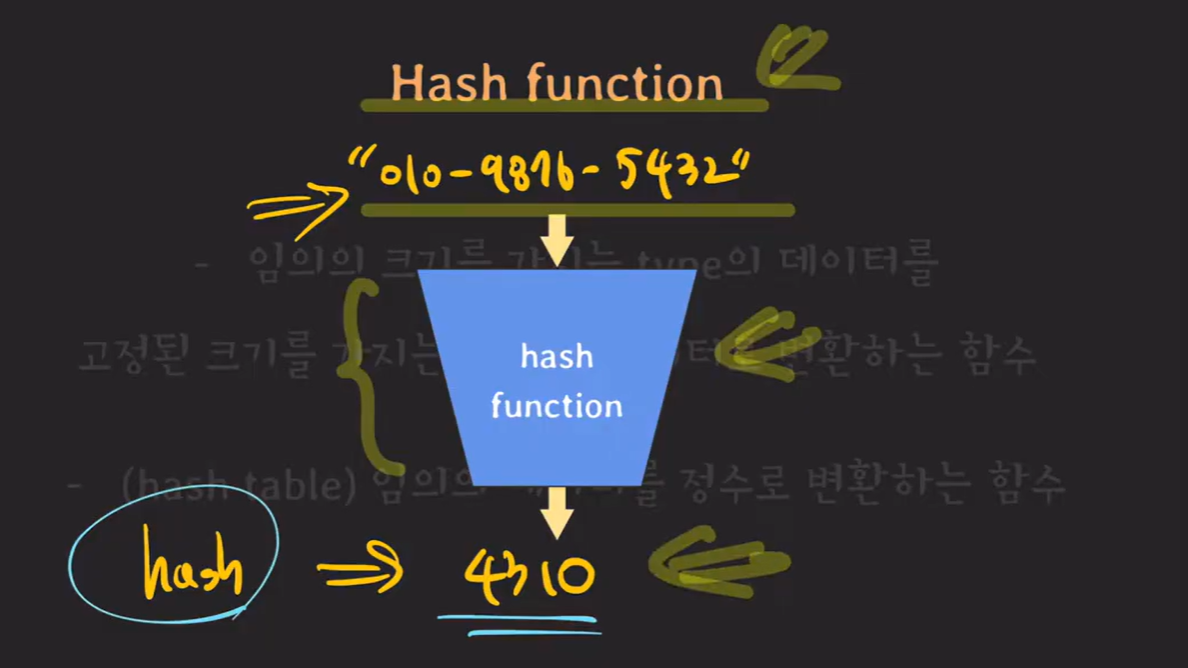
Hash Function이 동작하는 구조는 위와 같습니다.
key 값을 hash function 에 넣으면 hash 정수 int 값이 output으로 나오게 되고 나온 hash 값을 HashMap의 배열 길이인 capacity 값으로 나눈 나머지 값을 인덱스로 하여 해당 버킷에 저장되는 방식입니다.
HashMap에는 capacity (bucket의 길이), load factor (리사이즈 임계 값) 등이 있습니다. 그리고 HashMap은 3가지의 생성자를 지원합니다.
- 기본 생성자: capacity=16, loadFactor=0.75
- capacity 생성자: capacity는 입력받음, loadFactor=0.75
- capacity, loadFactor 생성자: capacity와 loadFactor 모두 입력받음
HashMap에서 capacity default 값은 16이고 max는 약 10억(2의 30승) 입니다. 그리고 capacity는 2의 거듭제곱으로 사용됩니다. 이는 비트 연산과 관련이 있는데요 2의 거듭제곱의 -1을 한 2^n - 1 을 이진수로 표현하게 되면 모든 자리의 값이 1이 되므로 비트 연산시 이를 활용할 수 있기 때문입니다.
예를 들어 100과 2^4 - 1 을 & 연산을 하면 아래와 같아집니다.
0110 0100 (100)
0000 1111 & (2^4 - 1)
------------
000 0100이 말은 hash 값이 100이 나올때 capacity가 2^4 - 1 일경우 hash 값으로는 4가 나오게 되며 이는 어떤 hash 값이던 항상 capacity 인 2^4 - 1 보다 작게나올 수 있음을 보장합니다.
load factor 값은 0.75 로 hashmap이 전체의 75% 이상이 채워지게 되면 다시 리사이즈 재배치를 하여 크기를 2배 늘려주게 됩니다.
putVal()
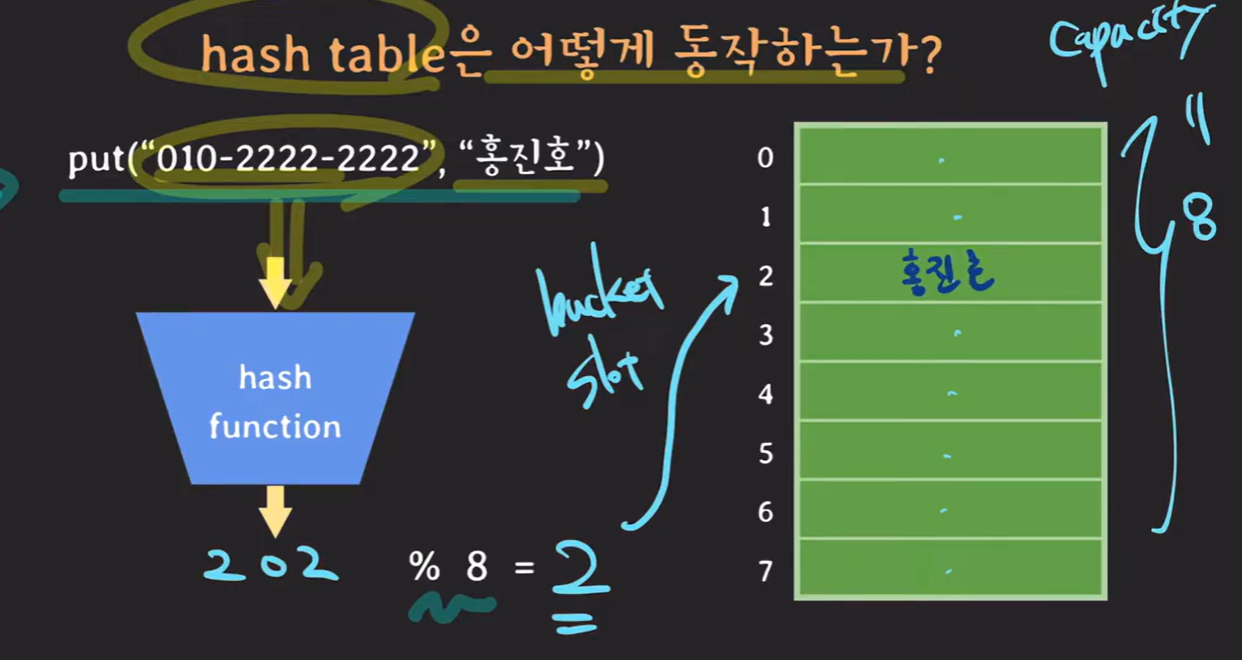
먼저 put 넣는 부분은 hashmap은 bucket을 배열 형태로 가지고 있습니다. 이 bucket 공간중에 특정 인덱스에 해당하는 값을 넣어야 하므로 capacity로 모듈러 연산 즉 hash function을 통해 나온 hash 값과 bucket의 사이즈인 capcacity로 나눈 나머지 값을 가지고 인덱스를 설정하게 되는 것입니다. 위와 같이 202라고 했을때 202를 8로 나눈 나머지는 2가 나오므로 인덱스 2에 값을 넣게 됩니다.
get()
get이 동작하는 방식은 동일하게 key 값을 hash function에 넣은 뒤 결과로 hash 값을 얻어서 capacity에 모듈러 연산을 한 뒤 조회할 인덱스를 얻는다. 해당 위치에서 실제 hash 값이 같은지 판단 후 동일하면 다시 key 값을 비교하여 확인한 뒤 hash, key 값이 매칭이 되면 그때 해당 값을 반환하는 방식으로 동작합니다.
Hash collision, Separate Chaining
Hash collision은 해시 충돌이라고도 하는데 아래 2가지 상황에서 발생합니다.
- key는 다른데 hash 가 같을 경우
- key와 hash 모두 다른데 hash % capacity 결과가 같을때
2가지 모두 모듈러 연산결과값이 동일한 인덱스를 가지는 경우를 의미합니다. 이러한 일이 발생하는 근본적인 원인은 capacity 값이 넣고자 하는 값들의 수보다 작기 때문입니다.
해시 충돌 해결 방법
자바는 separate chaining 기법을 사용합니다. 이는 링크드 리스트와 레드 블랙 트리를 혼용하여 사용한다고 합니다.
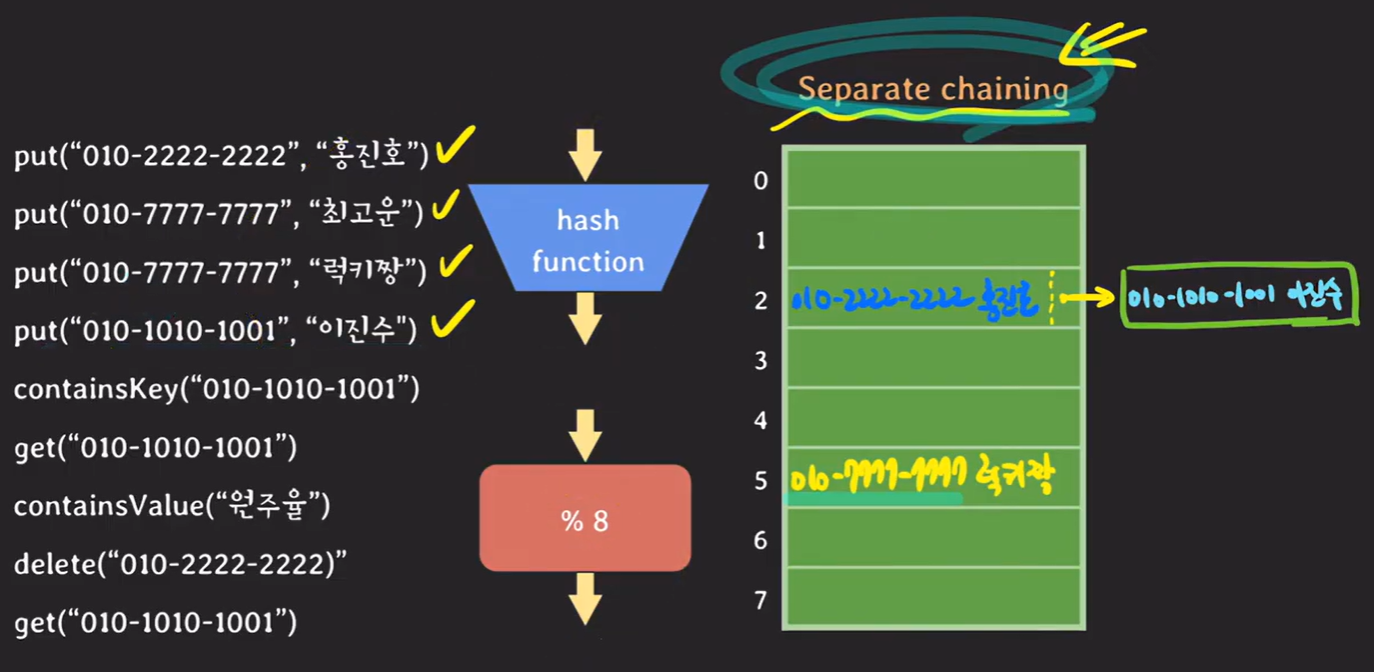
separate chaining 기법은 각 bucket을 리스트로 관리하는 것입니다. 그래서 hash 충돌이 발생시 마지막 노드의 next로 새로운 값을 가르키도록 합니다.
위와 같이 key로 기존에 010-2222-2222 가 있었지만 010-1010-1001 이 동일한 hash를 가져서 충돌이 발생한다고 했을때 010-2222-2222 의 next로 010-1010-1001을 가르키도록 하여 hash 충돌을 해결합니다.
그래서 get과 containsKey가 동작하는 방식도 동일합니다. hash function에 넣어서 얻은 hash 값으로 모듈러 연산을 하여 찾은 index를 통해 해당 bucket의 모든 리스트 값을 찾아보는 것입니다. 이때 각 노드의key 들을 비교하기 전에 hash 를 먼저 확인하여 서로 동일한 hash 값을 가지는지 판단합니다.
containsValue는 hash를 사용하는 것이 아니므로 모든 value 값을 찾아봐야해서 속도가 느립니다.

하지만 동일한 해시 버킷을 사용하는 원소가 많아 지게되면 해당 원소를 찾는데 시간이 길어져 최악의 경우 O(N)으로 증가하게 됩니다. 이로 인해 자바 8 부터는 하나의 버킷에 들어가는 노드 수고 8개가 초과할 경우 자료구조를 레드 블랙 트리로의 변경을 시도합니다. 이 임계값일 지정하는 파라미터는 TREEIFY_THRESHOLD 이며 기본값은 8 입니다. 이 트리화 시도로 인해 버킷 내에서 탐색 시간 복잡도를 O(logN)으로 낮출 수 있습니다.
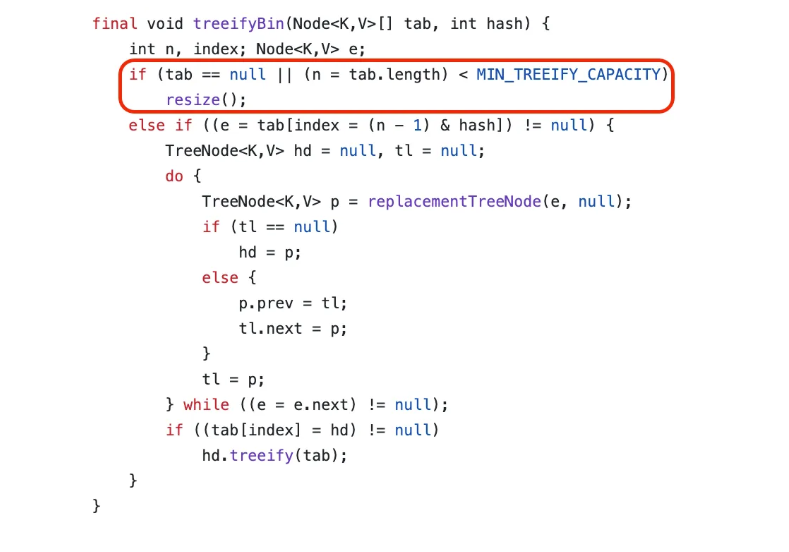
여기서 레드 블랙 트리로 변경하기 전 전체 HashMap의 크기가 64보다 작은 경우 먼저 해시 버킷 배열 확장을 먼저 선행합니다. 왜냐하면 64보다 작을 경우 배열 자체가 적으므로 충돌이 자주 발생할 수 밖에 없기 때문입니다. 이와 관련된 파라미터는 MIN_THREEIFY_CAPACITY 입니다.
delete()
delete 같은 경우는 key를 기준으로 delete를 수행합니다. 그래서 이전과 동일하게 key로 얻은 hash 값을 통해 bucket을 찾고 해당 bucket내에서도 먼저 hash 가 일치하는지 비교후 동일하다면 제거 후 다시 해당 노드의 앞 뒤가 연결되도록 조정을 해줍니다. 레드 블랙 트리의 경우도 삭제 진행 (=형태를 유지)
resize()
리사이즈 발생시 다시 처음부터 계산되지 않습니다. HashMap은 각 노드 데이터를 저장할 때 해시 값을 미리 계산해서 객체 안에 저장해두므로 효율적으로 새 위치를 찾을 수 있습니다.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // 캐싱된 해시값
final K key;
V value;
Node<K,V> next; // Separate Chaining을 위한 다음 노드 참조
// ...
}예를 들어 8에서 16으로 리사이즈되는 과정을 설명해보겠습니다.
리사이즈는 언제 발생하는가 ? (Load Factor)
이전에 설명드린대로 load factor를 활용하여 0.75를 사용하여 데이터가 6개 되는 순간 16으로 늘리게 됩니다. HashMap 용량은 항상 2의 거듭제곱을 사용합니다. 이는 인덱스 계산시 나머지 연산(%) 대신 비트연산 & 을 사용하여 속도를 높이기 위함입니다.
인덱스 계산 공식 index = (capacity - 1) & hash
데이터의 이동
비트 연산으로 인해 우아하게 처리가 됩니다.
용량이 8일때 이진수로는 (8-1) 0111 입니다. 용량이 16일 때 이진수로 (16-1) 1111 입니다. 이때, 기존에 같은 버킷(인덱스) 에 있던 데이터들은 새로 추가된 비트 (8의 자리 비트)가 0이냐 1이냐에 따라 딱 2 부류로 나뉘게 됩니다.
새 비트가 0인 경우: 인덱스가 그대로 유지됩니다
새 비트가 1인 경우: 기존 인덱스 + 8 위치로 이동합니다.
예를 들어 어떤 해시 값이 ...0101 이고, 다른 키의 해시값이 ...1101 이라고 해보면
capacity가 8일때
5&7 = 5번 인덱스
13&7 = 5번 인덱스 (여기서 충돌 발생 separate caining으로 연결됨)
용량이 16으로 커졌을 때
5&15 = 5번 인덱스 (그대로 유지)
13&15 = 13번 인덱스 (5+8 위치로 이동!)
위와 같이 충돌이 났던 데이터들이 아주 깔끔하게 두 그룹으로 나누어져 재배치 됩니다.
이와 같이 데이터가 늘어나도 빠르게 리사이즈가 되므로 충돌을 분산시키고 성능을 유지할 수 있게 됩니다.
HashSet
Set은 데이터를 저장하는 추상 자료형입니다. 데이터의 순서를 보장하지 않으며 중복을 허용하지 않습니다. 그리고 단일 데이터 조회가 List보다 빠릅니다.
Set은
중복된 데이터를 제거해야할때 혹은 데이터의 존재 여부를 확인해야 할때 사용합니다.
Set의 구현체인 HashSet은 내부적으로 HashMap을 사용하고 있습니다. 그래서 add() 메서드는 map.put()을 사용하고 key로 값을 저장하고 value로는 빈 Object()를 넣어주고 있습니다.
값이 존재하는지 판단하는 메서드인 contains() 는 map의 containsKey()를 통해서 하고 있습니다. 그래서 map에 해당 key가 있는지 없는지 여부를 판단하는 것과 동일합니다.
/**
* Constructs a new, empty set; the backing {@code HashMap} instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}...
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
...그렇다면 데이터들을 모두 iteration 반복 하고 싶을때 현재 데이터가 중복이 없고 순서가 상관없을때는 List나 Set 중 아무거나 사용해도 성능이 비슷한지 궁금할 수 있습니다.
만약 Collection에 있는 데이터들에 대해 반복 순회를 해야한다면 List 가 더 성능상 좋습니다 왜냐하면 리스트가 메모리도 적게 사용하고 구현이 단순하게 되어있어 iteration이 비교적 Set보다 빠르기 때문입니다. Set을 iteration 한다는 것은 map 들의 key 들을 모두 순회한다는 것인데 데이터들이 연속적으로 인덱스에 저장되어있는 것이 아니므로 데이터의 메모리 지역성이 낮아서 비교적 느릴 수 있습니다.
Hash

HashSet을 사용할때 주의해야할 부분이 있습니다. 기본적으로 hashCode() 즉 hash function은 객체 메모리 주소로 hash 값인 int 값을 반환합니다. 그래서 객체의 멤버 변수가 같다 하더라도 이는 개발자가 지정한 요소가 같을 뿐이지 객체를 구별하는 용도는 아니므로 동일한 객체로 판단되지 않습니다.
그래서 위 내용으로 print되는 값을 보면 size는 2가 나오게 되고 모두 true가 나오게 됩니다.

하지만 위와 같이 hashCode()와 equals() 를 재정의하게 되면 이제는 hash 를 구할때 메모리 주소값이 아닌 x값과 y값을 기준으로 판단하므로 메모리 주소가 달라도 동일한 hash 값을 가지게 되고 객체가 동일한지 비교할때에도 메모리 주소값이 아닌 x와 y값을 기준으로 판단하게 됩니다. 즉 이 객체는 앞으로 비교할때 x값과 y값을 기준으로 값이 같으면 같은 객체로 판단되게 됩니다.
그래서 print 되는 값을 보면 size는 1이 나오게 되고 모두 true가 나오게 됩니다.
그래서 만약 멤버 변수가 추가되면 이 추가된 변수에 대해서도 반드시 hashCode()와 equals()에도 적용시켜주어야 합니다. 그러지 않으면 값이 동일해도 다른 객체로 판단되게 됩니다.
객체 저장 후 멤버 변수 값이 수정되면 ?

위와 같은 상황에서 print 가 어떻게 되는지 10초간 생각해봅시다.
저는 처음에 모두 true가 나올거라 생각했습니다.
하지만 처음 print()는 true가 나오고 그 다음 print()는 false가 나옵니다.
그 이유는 변경된 멤버 변수의 값으로 다시 contains() 를 조회하기 때문입니다.
다시 hash function이 동작하는 과정을 살펴보면

현재 Set에 c1 객체가 저장되어있는 상태이고 이후 c1의 x 값을 1에서 10으로 변경 후 Set에 해당 객체가 존재하는지 contains() 메서드로 조회하는 상황입니다.
여기에서 저희는 이전에 hashCode() 와 equals()를 재정의 하였습니다. 그러므로 이는 동일한 c1 객체라 하더라도 x값이 1에서 10을 변경되었으므로 hash function을 통해 나오는 hash 값은 다른 값이 나옵니다. 따라서 다른객체로 판단되어 결과는 false로 나오게 됩니다.
이러한 경우를 대비하여 final 이라는 키워드가 있습니다. 이 final 키워드를 사용하게 되면 한 번 할당된 변수는 더이상 변경될 수 없으므로 이후에 할당된 이후에 변경을 시도하려하면 컴파일 에러가 발생하게 됩니다.
느낀 점
데이터의 수가 많은 자료들에 대해 탐색을 위해 hash 라는 것을 사용해서 그 크기가 큰 내용들의 탐색 범위를 어떻게든 작게 줄이려는 것으로 보였다. 탐색 범위를 제한된 리소스 내에서 줄이다 보니 충돌이 발생하게 되고 이에 대해서도 자료구조로 적절하게 해결한 것으로 보인다.
개발을 하면서 자주 사용하는 자료구조들이 어떻게 동작하는지 이해하게 되었으며 마지막 예시의 Set 자료구조의 contains와 같이 의도한 결과가 나오지 않았을때 어디서 문제를 찾고 어떻게 찾아나가야 하는지 알게된 것 같다.
