들어가기에 앞서
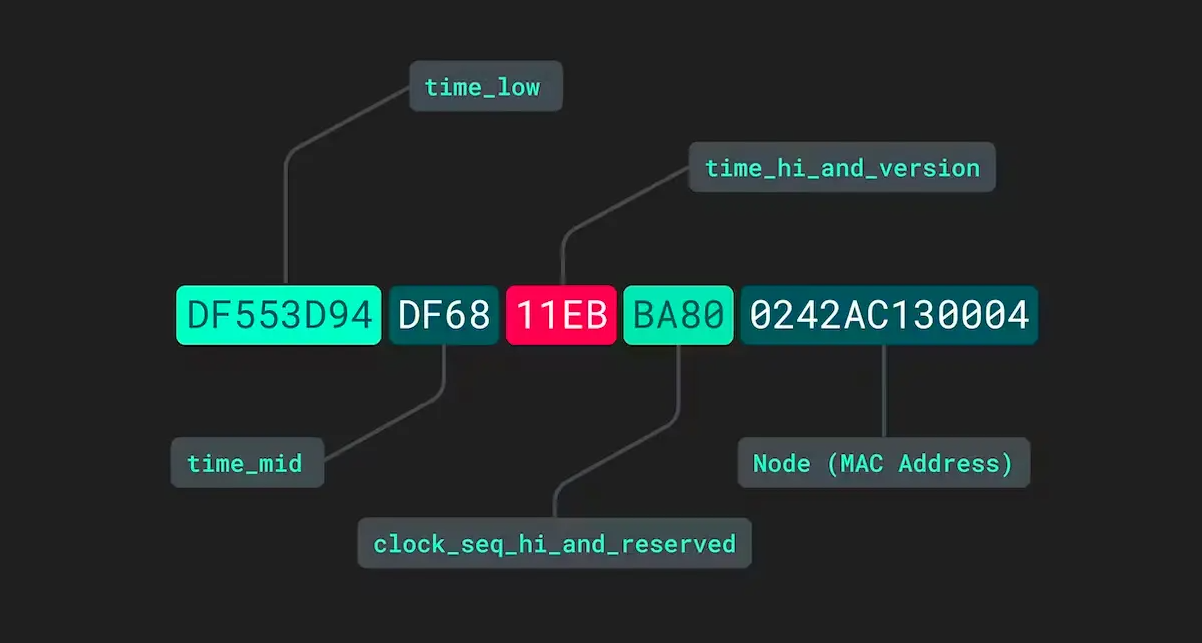
지난시간에 토스가 생각하는 좋은 객체 ID(Object ID) 만들기 에 대해서 알아보았어요.
이제 어떤 ID가 좋은 ID인지 알아보았으니 제가 구현한 좋은 ID를 설명해보고 어떻게 하면 더 활용할 수 있는지 알아보겠습니다.
객체 ID 생성기
저번시간에 저희가 객체 ID를 만들때 고려할 점으로 3가지를 알아보았습니다.
- 고유성
- 식별 가능성
- 보안성
ID 생성 로직 과정
위 3가지를 고려한 ID 생성기의 로직은 아래와 같아요.
사진 제거 후 다이어그램으로 표현
생각보다 잘 안보이네요 .. 죄송합니다
ID 생성 동작 원리
이제 하나씩 설명드려볼게요
위 로직을 요약하면
문자열 입력 -> 16진수 변환 -> 10진수 변환 -> 2진수 변환 -> shift 연산 -> 10진수 변환 -> 문자열 변환
순으로 이어지게 되요.
여기서 16진수로 변환했던 이유는 shift 변환을 쉽게 하기 위함 입니다.
2진수에서는 문자열로 바로 변환이 가능하여 굳이 16진수를 거치지 않았어요.
여기에서 어떻게 위 3가지를 만족시킬 수 있었을까요 ?
그건 아래와 같이 해보았어요.
고유성 : 시간을 밀리초 단위로 받아 랜덤하게 문자열을 생성
식별가능성 : 생성하려고 하는 Entity를 식별하여 문자열 앞에 붙임
보안성 : 2진수의 shift 연산을 통해 완전히 다른 64bit 문자열을 생성
그럼 위와 같은 로직을 만들기 위해 어떤 고민을 했는지 함께 알아볼게요!
보안성을 어떻게 구현 할까

보안성이라는 목표를 이루기 위해서는 예측할 수 없어야 합니다.
ID가 생성되는 과정이 노출된다 하더라도 실제 ID를 알 수 없어야 한다고 생각했어요.
그래서 이를 위해서는 Input되는 값을 알 수 없어야 한다고 생각했고 그래서 시간을 사용하기로 했습니다.
사용자가 생성되는 시간에 대해 밀리세컨드 단위를 사용하게 되면 쉽게 예측할 수 없다고 생각했기 때문이에요.
그래서 시간을 사용하기 위해 아래 선택지 중 최종적으로 Instant 를 사용하기로 하였습니다.
- Date
- LocalDateTime
- Instant
이유는 Date 클래스의 경우 mutable 하여 Thread 에서 값을 참조하고 변경할 수 있습니다.
LocalDateTime의 경우 Instant에 비해 연산 속도가 느립니다.
왜냐하면 내부적으로 Instant 형으로 바꾼 뒤 ZoneOffset으로 한 번 바꾼 뒤 EpochSecond로 바꾼 뒤에야 LocalDateTime으로 표현되기 때문입니다.
Instant 는 1970 년 1월 1일 UTC의 첫번째 순간 이후로 현재 시간까지 나노초를 나타낸 값이라고 합니다. 그리고 숫자 자료형을 통해 연산을 하여 속도가 Local, Offset, ZonedDateTime과 비교했을때 빠르다고 합니다.
이러한 이유로 Instant를 채택하였습니다.
그래서 최종적으로는 사용자의 이름 4자리 + 나노초 숫자 4자리를 mix하여 문자열을 생성하고 이 문자열을 분해, 연산, 결합 하여 다시 새로운 문자열을 생성하도록 하였어요.
동작 과정
아래부터는 총 3단계로 구성된 분해 -> 연산 -> 결합 과정을 거치게 되면서 저희가 원하는 목표인 고유성을 만족하는 로직을 차근차근히 알아볼게요.
분해
분해 과정에서는 먼저 문자열을 16진수로 변환합니다. 16진수의 형태는 0x3F 와 같이 변환되며 이때 2번째 자리의 경우 숫자, 문자에 대해 판단하여 문자일 경우 소문자로 바뀌는 현상이 있어 이를 대문자로 변환하는 로직을 추가하였습니다.
char c = mixedString.charAt(i);
String hex = Integer.toHexString(c);
hexSb.append(hex.charAt(0));
hexSb.append(Character.isDigit(hex.charAt(1)) ? hex.charAt(1) : Character.toUpperCase(hex.charAt(1)));그리고 16진수를 다시 10진수로 변환하였으며 10진수를 다시 2진수로 변환하였습니다. 이 과정에서 8bit를 모두 표현하고 최종 결과는 64bit 여야하므로 2진수에 대해서 .replace() 메서드를 사용하였습니다. 예를 들어 십진수 6에 대해 2진수로 표현하게 되면 110 이 나오게 되고 이렇게 추가해버리게 되면 bit가 엇갈리에 되어 최종적으로는 64bit가 생성되지 못하고 연산이 꼬이게 됩니다.
int value;
char ch = hexSb.charAt(i);
if (Character.isDigit(ch)) {
value = Character.digit(ch, 16);
} else {
value = Character.digit(ch, 16);
}
String.format("%4s", Integer.toBinaryString(value)).replace(' ', '0');그래서 이렇게 4자리수를 보장하고 공백에 대해서는 0을 넣는 방식으로 진행하였습니다.
최종적으로 64bit가 완성되면 아래와 같은 형태를 띄게 됩니다.
01100010001100000110001100110000010100110000011001000011연산
위에서 결과로 나온 64bit의 2진수에 대해 shift연산, name 길이정보, shift 연산을 순차적으로 진행해줍니다.
먼저 4bit에 대해 shift연산을 수행해줍니다. 이는 단순히 문자열을 자르는 방식으로 진행되어요.
그리고 입력한 이름의 길이 정보를 넣습니다.
예를 들어 "jonghun" 이라는 문자열을 이름으로 입력하였을 경우 7이라는 숫자가 나오게 됩니다.
이를 2진수로 변환하면 0111 형태를 띄게되고 이를 끝에 붙여줍니다.
위 2진수의 예시로는 아래와 같이 변환이 진행됩니다.
00100011000001100011001100000101001100000110010000110111
그리고 다시 1bit에 대해 left shift 연산을 수행하게 되면
01000110000011000110011000001010011000001100100001101110
와 같이 최종적으로 변환됩니다.
결합
여기까지 따라오셨다면 정말 수고 많으셨습니다 ! 이제 마지막 결합 파트입니다.
저희는 위 2진수를 다시 문자열로 만드는 것이 최종 목표입니다.
그 전에 아스키범위안에 속하는지를 판단하고 만약 속하지 않는다면 1의 보수법을 취해줍니다.
for (int i = 0; i < binary.length(); i++) {
char bit = binary.charAt(i);
if (bit == '0') {
result.append('1');
} else if (bit == '1') {
result.append('0');
} else {
// 예외 처리: 0 또는 1이 아닌 문자가 있을 경우
throw new IllegalArgumentException("Invalid binary input");
}
}이후 각 2진수에 대해 다시 8bit 단위로 나누어 줍니다.
나누어진 8bit를 10진수로 변환합니다. 이 과정에서는 각각 4bit로 각각 나누고 앞쪽의 4bit에 대해서 2^4 를 곱해주어 10진수 변환을 진행하였습니다.
그리고 이 과정에서 매칭을 위해 Hashmap 을 사용하였어요.
(Hashmap에 대해서는 아래에서 자세하게 다루었습니다.)
10진수 변환까지 마친 뒤 이를 문자열로 변환 후 순차적으로 합치는 과정으로 ID 생성을 마무리 하였습니다.
int first = Integer.parseInt(binary.substring(0, 4), 2);
int last = Integer.parseInt(binary.substring(4, 8), 2);
int decimalNumber = (first * (int)Math.pow(2, 4)) + last;
if (!isValidAscii(decimalNumber)) {
decimalNumber = asciiMap.get(decimalNumber);
}
// 10진수를 char 으로 변환
char asciiChar = (char) decimalNumber;위와 같이 생성함으로써 보안성이라는 목표를 이루어내기 위해 노력하였습니다.
식별 가능성 ?
ID의 식별 가능성 부분은 비교적 쉽게 구현하였습니다.
해당 Entity를 생성시 어떤 종류의 Entity인지 구분하여 prefix로 붙여주었습니다.
아래의 예시코드를 통해 살펴보아요.
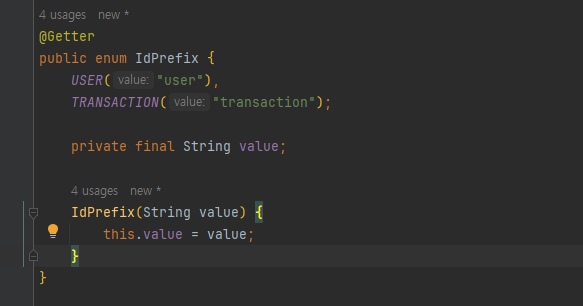
위와 같이 enum 을 생성하였으며 사용할때에는
String generatedId = hash(s, createAt);
generatedId = idPrefix.getValue() + "-" + generatedId;와 같이 사용하여 앞에 "user-" 가 붙도록 하였습니다.
이렇게 사용하게 되면 실제 ID의 형태는 다음과 같아요.
user-FsO0xq16
고유성 보장은 어떻게 ?
Entity를 식별하기 위해서는 고유해야합니다. 즉 1개만 존재해야 해요.
고유성을 어떻게 보장할까요 ?
현재로써는 4자리의 이름과 4자리의 숫자를 Input으로 받음으로써 고유성을 보장한다고 하지만
만약 동일한 이름을 가진 사용자 가 밀리세컨드 단위까지 일치 한 상황에서 생성한다면 ?
이라는 가정을 둔다면 현재 로직 상에서는 고유성을 보장할 수 없습니다. (왜냐하면 동일한 Input이 형성되므로 이는 동일한 Output을 내도록 설계되었기 때문입니다.)
이를 위해 유일성이 깨지면 안되므로 조금 더 고민이 필요합니다.
현재 테스트 중 동일한 ID가 생성되어 해결 이후 수정 예정입니다!
shift연산 오류로 현재 해결하였습니다!!
구현시 마주한 문제
아래에서는 구현하는 도중 마주한 문제들에 대해 어떻게 대처하였는지 작성해보았어요.
문자 -> 2진수 예상밖의 변환
문제발생
입력부분에서 8이 입력되었을 경우
제가 기존에 기대하는 2진수의 형태는0000 1000이었지만실제로는
0011 1000이 들어오는 상황이 발생했어요.
이유는 입력시 십진수 8이 아니고 '8' 인 문자(char)가 들어왔기 때문인데
이때 '8' 을 16진수로 변환시 0x08이 아닌 0x38 을 나타내었습니다.
위 8숫자를 제가 원하는 0000 1000 으로 할지 아니면 그대로 0011 1000 으로 할지 고민하였는데
(즉, 이걸 다시 십진수로 변환할 지 아니면 그대로 사용할지 고민)
여기서 저는 개발자가 기대한 변환 vs 2진수 형태 복잡성(암호화에 기여) 사이의 트레이드 오프로 생각하였어요.
기존에 내가 기대한 변환과 다르므로 로직 과정을 이해하는데
?가 발생vs
'8' 로 들어오게되면 16진수로 표현시 0x08이 아닌 0x38 로 변환됨 이는 다시 2진수로 변환하는 과정에서 3부분이 0000이 아닌 0011 로 변환
이는 조금 더 2진수의 형태 (0000 -> 0011) 가 비교적 복잡하게 됨 이는 나중에 left shift 연산시 암호화에 더 기여하지 않을까 ? 라고 생각하였었습니다.
그래서 이 형태를 그대로 사용하기로 했습미다.
하지만 글을 쓰는 시점에 다시 생각해보니
-> 아님 어차피 컴퓨터가 +- 연산하는 것이므로 크게 상관없다는 것을 깨달았습니다.
그리고 저는 또 다른 설득가능한 이유를 찾기 위해 고민을 해보았습니다. 그래서 다시 개발자가 기대한 변환에 대해 그 시각을 조금 바꿔보면 어떨까 싶었습니다.
애초에 입력을 받을때에는 숫자가 아닌 문자열 이므로 이는 아스키코드로 변환시0x08이 아닌 0x38 이 맞다고 생각을 바꾸어 해보니 스스로 납득이 가였습니다.
그래서 문자열을 십진수로 변환하지 않고 그대로 사용하기로 하였습니다.
범위 변환
문제발생
1bit 만큼 left shift 한 뒤 이를 다시 문자열로 변환하기 위해 16진수로 변환 후 문자열로 변환하려는 과정에서 문제 발생
8bit는 2 ^ 8 개만큼의 표현이 가능 최대 십진수 256까지가 나왔습니다.
하지만 아스키코드는 0부터 127내에서 다루어져야 하므로 이를 조절하는 로직이 필요했어요.
그래서 저는 이 부분을 1의 보수법으로 해결하였습니다.
가장 앞쪽의 bit가 1일 경우 127을 초과하므로
1인지 아닌지를 판단 하여 1이면 0으로 바꾸어주고 0이면 1로 바꾸어주는 방식으로 해결하였어요.
아스키 코드 내의 글자, 숫자 매칭
문제발생
암호화를 위해 십진수를 아스키코드와 일대일 매칭시 식별이 어려운 글자에 대해서도 매칭되는 현상
아스키코드에는 글자, 숫자 뿐 아니라 다른 형태의 문자들이 많습니다.
아래의 사진을 보시면
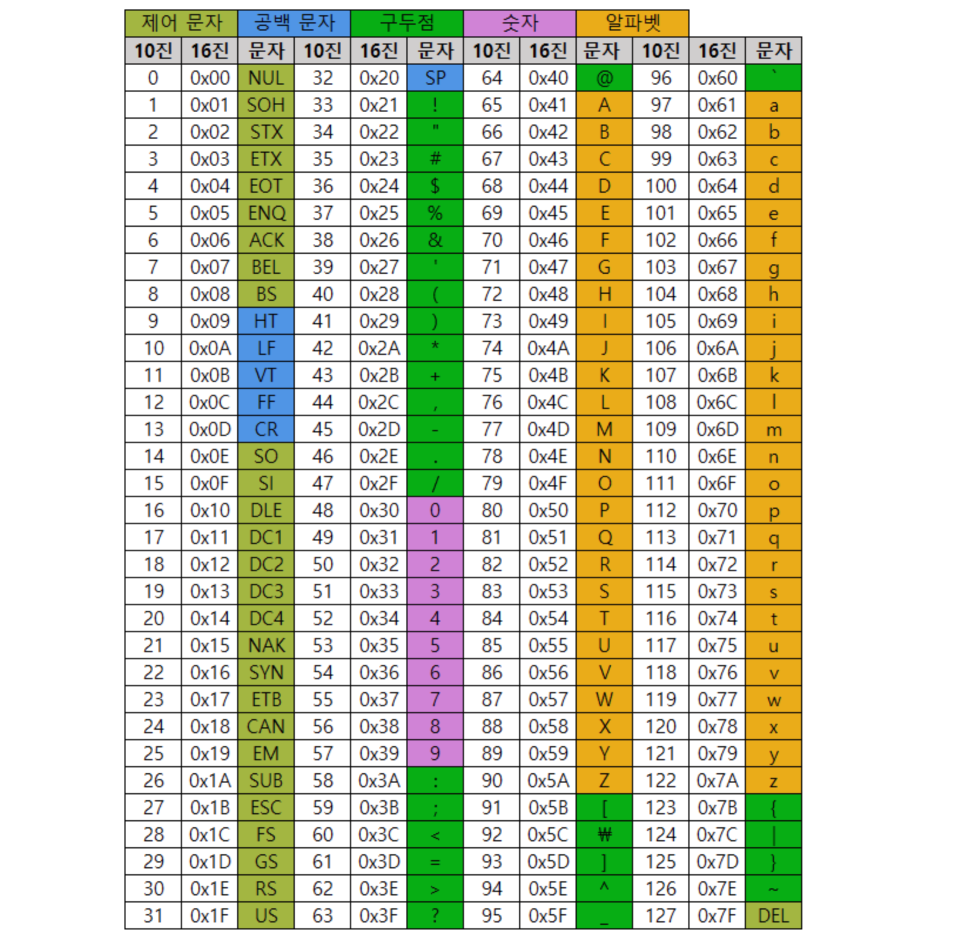
실제 숫자, 문자의 개수와 나머지의 개수가 서로 거의 비슷합니다. (실제로 4개차이로 나머지가 더 많음)
그렇다 보니 글자, 숫자가 아닌 범위에 대해서는 따로 처리가 필요하였어요.
즉 아스키코드 내의 숫자, 문자의 범위가 0~127 범위의 십진수에 대해 일대일 매칭이 되지 않으므로 이 범위에 대한 처리가 필요했습니다.
제가 예상한 로직은 10진수를 받아와서 해당하는 아스키코드 내에 매칭되는 문자열로 변환하는 것이었고 이 매칭을 위해 여러가지 고민을 하였습니다.
1. Hash 함수
Hash 함수를 만들어 0~127 범위의 특정 숫자가 들어올때 일정한 숫자가 나오도록 설계하여 일대일 매칭이 되도록 한다.
2. Hashset 생성
Hashset을 만들어서 나머지 범위에 대해 모두 직접 일대일 매칭을 시켜준다.
1번으로 시도하려 하였으나 숫자의 범위가 그리 많은 것도 아니고 굳이 이를 위해 복잡한 함수, 로직이 필요할까 생각이 들었습니다.
그래서 2번으로 진행하였습니다.
범위를 늘려가며 순차적으로 진행하되 다만 4개가 더 많으니 123 부터는 다시 처음으로 돌아가 문자 0에 대해 매칭되도록 하였습니다.
아래는 해당 생성 과정입니다.
private void initializeAsciiMap() {
// ASCII_DIGIT_START - 48
int v = ASCII_DIGIT_START;
for (int i = 0; i < 10; i++) {
asciiMap.put(i, v);
v++;
}
// ASCII_UPPER_CASE_START - 65
v = ASCII_UPPER_CASE_START;
for (int i = 10; i < 36; i++) {
asciiMap.put(i, v);
v++;
}
// ASCII_LOWER_CASE_START - 97
v = ASCII_LOWER_CASE_START;
for (int i = 36; i < 48; i++) {
asciiMap.put(i, v);
v++;
}
// 중간값 계산
v = 109;
for (int i = 58; i < 65; i++) {
asciiMap.put(i, v);
v++;
}
// 중간값 계산
v = 115;
for (int i = 91; i < 97; i++) {
asciiMap.put(i, v);
v++;
}
// ASCII_DIGIT_START - 48
v = ASCII_DIGIT_START;
for (int i = 123; i < 128; i++) {
asciiMap.put(i, v);
v++;
}
}에러 Cannot invoke "java.lang.Integer.intValue()" because the return value of "java.util.HashMap.get(Object)" is null
모든 로직을 구현 후 실제로 생성을 시도하였을때 Null 에러를 보게 되었어요.
처음에는 HashMap 객체가 null이라는 줄 알고 초기화, Bean 등록 문제로 착각하였습니다.
저는 분명 @Component 를 선언하여 Bean 등록을 하였고 이를 사용할때에는 @RequiredArgsConstructor을 통해 생성자 주입을 하여 생성 및 초기화 하는데는 문제가 없다고 판단하였어요.
그리고 initializeAsciiMap() 메서드를 통해 모든 값들을 넣어주어서 왜 Null이 나오는지 알 수 없었습니다.
나중에 알고보니 기존에 진행하였던 1의 보수 메서드가 정확하게 동작하지 않아 127이상의 숫자에 대해 HashMap에서 get()을 하려고 시도하니 가져올 객체가 null인 상황이었습니다.
Error 메세지도 다시 잘 읽어보니
Hashmap.get(Object) is null즉 Hashmap에서 get()을 시도하니 null이 었다는 것이었습니다. 이 말인 즉슨 Hashmap은 생성되었고 이 Hashmap에 get()을 했을때 반환값으로 null이 나옴으로써 에러가 발생한 것이었습니다.
다시 한 번 에러를 잘 읽어야겠다는 생각이 들었습니다.
마무리
이렇게 엔티티 ID 생성기를 직접 구현해보았어요! 하지만 아직 채우지 못한 요구사항이 존재해요. 바로 정렬 입니다!
이에 대해 궁금하신 분들은 아래 블로그도 한 번씩 방문 부탁드려요 :)
