들어가기에 앞서
여러분들~ 엔티티를 다루면서 ID 또는 식별자에 대해 많이 들어보셨죠 ? 만약 자바, 스프링으로 시작하시게 되면 엔티티객체를 다루게 되실텐데 이때 아래와 같이 @GeneratedValue를 통해 엔티티 생성시 자동으로 +1씩 순차적으로 증가하는 규칙에 따라 엔티티를 식별할때 유용하게 사용할 수 있었을 거에요
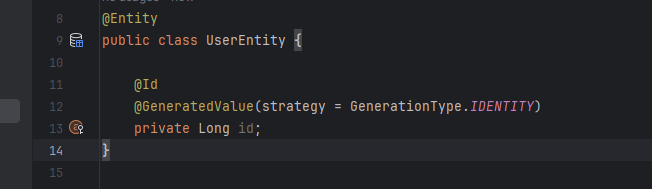
하지만 객체 ID는 시스템에서 매우 중요한 정보이므로 저렇게 두는것은 매우 위험할 수 있어요. 토스에서는 객체 ID를 만들때 아래 3가지에 대해 고려하고 있습니다.
객체 ID를 만들 때 고려할 점
-
고유성 : 전체 시스템내에서 두개 이상의 객체가 동일한 ID를 갖지 않는 것을 의미합니다. 객체 ID가 중복이 된다면 ID만 보고서 어떤 객체인지 식별할 수 없게되어 데이터의 무결성과 일관성을 보장하지 못합니다. 반드시 고유한 값을 가져 식별할 수 있는 값이어야 됩니다.
-
식별 가능성 : 명확한 네이밍, 일관된 구조로 사용하는 개발자가 ID를 보고서 쉽게 예측할 수 있는 방식으로 객체 ID를 만드는 것을 의미합니다. (ID를 보고서 쉽게 예측할 수 있으면 보안에 문제되는거 아닌가요 ?) 여기서 말하는 예측은 객체를 식별하기위한 예측이 아니고 객체가 어떤 종류의 객체인지를 구분하기 위한것을 의미합니다. 예를 들어 접두사를 붙여
user-을 사용하여 객체 ID를 보고서 사용자 객체임을 쉽게 확인할 수 있는 것을 의미합니다. -
보안성 : 객체 ID는 엔티티를 식별하는 용도로 사용되기 때문에 객체 ID는 매우 중요하며 쉽게 예측할 수 없도록 랜덤하게 생성하는 것이 중요합니다. 그리고 길이와 복잡성도 중요하여 어느정도로 숫자와 문자를 혼합하여 조합하는게 좋을지도 보안과 효율성 측면에서 고민을 해보는 것이 좋아요.
여기서 아래에 고유성과 식별 가능성에 대해 조금 더 알아보도록 할게요.
고유성
"하나의 시스템에서 객체를 식별하기위해 ID를 생성시 랜덤으로 생성해야하는건 알겠는데 .. 그러면 랜덤으로 생성하다 ID가 겹쳐져버리게 되면 어떡하지 ?" 라는 걱정이 드실 수 있어요.
여기에 토스는 2가지의 방법을 제시하고 있어요.
UUID VS Hash
| UUID | Hash 함수 | |
|---|---|---|
| 형식 | 32개의 16진수 | 고정된 길이의 이진 문자열 |
| 8-4-4-4-12 와 같이 5개의 그룹으로 구분 | ||
| ex) 550e8400-e29b-41d4-a716-446655440000 | ||
| 생성방법 | UUID4 | SHA-256 알고리즘 |
| 사용 | 보안이나 식별을 위해 랜덤하고 예측 불가능한 식별자가 필요할 때 | 데이터를 빠르고 효율적으로 검색하고 싶을 때, 민감한 정보를 안전하게 저장하고 싶을 때 |
| 장점 | 고유성, 분산시스템에서의 안정 | 일관성, 속도 |
위 2가지를 보고 느낀점은 안정적인 고유성 vs 빠른 검색 에서의 트레이드 오프로 보여져요. 각 장점을 보고 상황에 맞게 사용하는 것이 중요하다고 생각되어요.
저는 데이터 식별시 빠른 속도를 기대하고 아래에서는 Hash 함수를 Java로 직접 만들며 사용해볼게요.
식별 가능성
한마디로 사람이 읽을 수 있는 디자인 이에요. 아래 사진은 토스에서 사용하고 있는 키 값이에요.

이 값을 보고 10초동안 생각을 해보세요.
생각해보셨나요 ? 여기서 유추할 수 있는 점은 _ 로 구분된다는 점, 그리고 test 라는 단어와 ck를 통해 test용인 clientKey 클라이언트 키 값과 관련이 있겠구나라고 사람이 쉽게 인식 할 수 있는 점이에요. 이렇게 해서 뒤에 랜덤한 문자열만 떨렁 있는 것 보다 훨씬 가독성이 좋아져요.
이렇게하면 장점이 무엇이 있을까요 ?
- 특정 카테고리에 속한 객체를 식별하고 이해하기 쉬워짐
- 객체 ID 충돌 방지
- 가독성
- 객체간 연관 예측 가능성
이렇게 4가지로 추려볼 수 있어요.
앞의 3가지는 알겠는데 객체간 연관 예측 가능성? 이 뭘까요 ?
만약 아래와 같이 Order 와 Customer가 있다고 가정해볼게요.
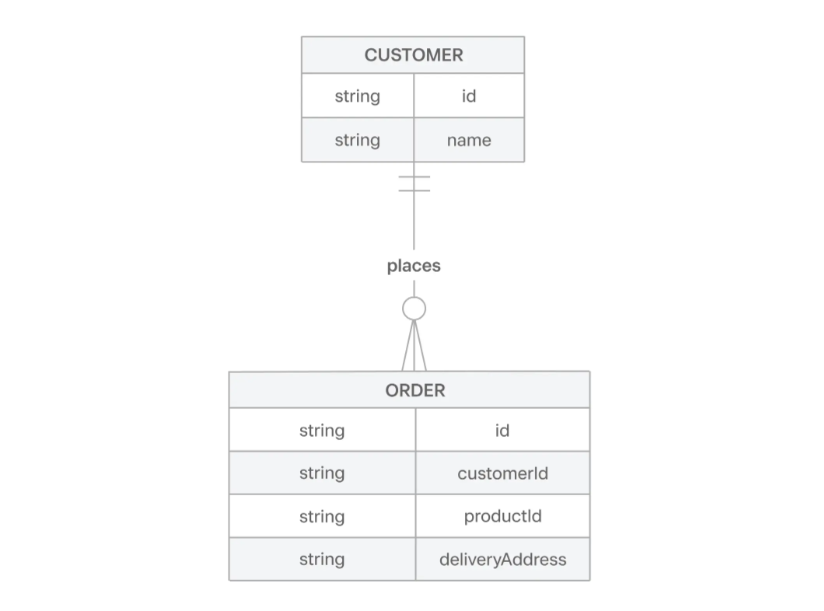
Order에는 어떤 고객이 주문하였는지를 식별하기 위해 고객에 대한 정보를 저장해야해요. 그래서 customerId를 저장하고 있어요. 이때 해당 고객에 의 다른 주문 목록을 보고자 할때 이 ID를 사용하게 될 거에요. 이때
customer_ck_D5GePWvyJnrK0W0k6q8gLzN97Eoq vs D5GePWvyJnrK0W0k6q8gLzN97Eoq
중 어떤 ID가 고객 ID라는 것을 더 쉽게 예측이 가능한가요 ?
데이터를 다룰때에는 한 가지가 아닌 다양하고 복잡한 여러 데이터를 다루게 될거에요. 그런 상황에서는 정보 하나하나가 중요하고 명확해야해요. 위 2가지의 예시중에서 더 적합한 ID는 왼쪽에 있는 ID일 거에요.
개념 정리
앞서 설명한 내용들을 다시 정리해볼게요.
Q : 객체 ID가 뭐야 ?
A : 객체 ID란 객체를 구분하는 식별자에요.Q : 그럼 ID를 만들때 그냥 만들 수 없잖아. 어떤 부분을 고려해야해 ?
A : 고유성, 식별가능성, 보안성을 고려해서 만들어야 해요.Q : 고유성이 뭐고 식별가능성이 뭐야 ?
A : 고유성은 객체 ID가 시스템 내에 단 1개만 존재해야하는 것이고 식별 가능성은 ID에 사용자가 예측할 수 있도록 접두사를 사용하는 방식이에요.
ID 만들어보기
그럼 객체 식별자 ID에 대해 이해해보았으니 직접 만들어보겠습니다.
물론 좋은 라이브러리들(UUID4, UUID-Random 등)이 많아 쉽게 사용할 수 있지만
그 원리를 잘 알고 활용하기 위해서 함수를 만들어볼게요.
