Markov 성질
- 미래는 오직 현재에만 기반하고 과거는 영향을 주지 않음
- 회귀 성질을 띈다, T는 T-1 기준, T-1은 T-2 기준 기반
Markov chain
- 오직 현재 state에만 기반하여 next step을 예측하는 확률 모델
Transition
- 다음 state로 넘어가는 것
Transition probability
- transaction이 발생할 확률
Markov Decision Process MDP
- Markov chain 확장판으로 "action"이 추가되어 의사결정을 한다
- 대부분의 강화학습은 MDP로 모델링 됨
- 강화학습의 목적 : 특정 state에서 agent가 해야할 행동 선택 (reward maximize)
MDP 5 요소
-
states
-
actions
-
transaction probability (probability가 정의된 것은 모델링이 잘 되었다는 의미)
- s -> s' 로 state를 움직일때 action을 함으로써 transition 될 확률 -
reward probability
- s -> s' 로 state를 움직일때 s'로 갔다면 받을 수 있는 reward의 확률 -
discount factor
- 의사결정을 할때 현재, 미래 중 어떤 요소가 더 중요한지를 결정
- 0 ~ 1의 값 중 선택, 0에 가까우면 현재가 중요, 1에 가까우면 미래가 중요함을 의미
-
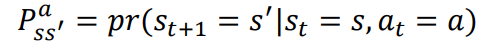
-
반환확률, S t+1 : ~일 확률 , | = 조건
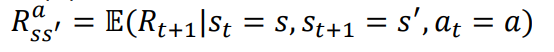
Reward
- 각 time step의 immidiate 보상
Return
- total 보상
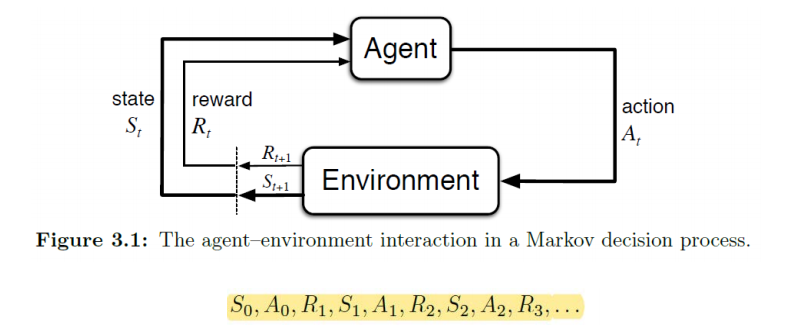
: 0번째 state에서 0 번째 Action을 하면 1번째 Reward가 적립됨
A0 액션을 취할 때 당장 R1을 Maximize하는 것이 목표가 아니고 total reward를 maximize 하는 것이 목표
왜냐하면 하나의 에피소드가 끝났을때 최종적으로 SUCCESS State에 가 있기를 원하므로
ex) 미로 -> goal 에 도착
Episodic and Continuous
- Return을 정의하는데에 있으 서로 차이가 있음
Episodic
- terminal state가 존재 (엔딩이 있음)
- 시작과 끝이 명확
- 각 에피소드는 연관없이 독립적
ex) 미로, goal에 도착하기 위해 계속 episode를 반복하여 각 episode에서 얻은 return을 maximize함
Continuous
- terminal state가 없음
- 계속 학습
ex) 개인비서, 개인에게 최적화 되기 위해 reward를 계속 maximize하며 최종 state가 없음
Discount factor
- 강화학습의 목표는 return을 maximize 하는 것 (total reward)
- episodic에서는 종료 state가 명확, return 계산 가능 (모든 reward를 다 더하면 됨)
- Continuous 는 종료 state가 없으므로 무한대로 더하기는 불가, discount factor를 사용하여 적당한 값을 찾아냄
- γ(discount factor)은 0<γ<1 값을 가지며 보통 0.2 ~ 0.8 의 값을 가짐
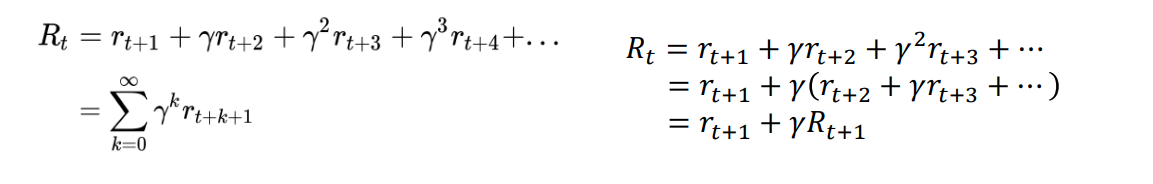
discount factor는 time step t 에 대해 가까운 return과 미래 return 중 어느 것을 더 중요하게 생각하는지를 정의
γ = 0 : 바로 다음 return이 가장 중요, γ = 1이면 미래가 중요
γ은 풀고자 하는 문제에 따라 달라짐
ex) Chess 게임의 경우 바로 다음 return을 중요하게 생각하면 졸병을 잡음 (γ=0)
미래의 king 을 잡는 것을 중요하게 생각하면 (γ=1)
Policy π
- 특정 state에서 어떤 action을 선택할 확률을 의미
- 방정식의 해를 찾는 것이 최적의 policy를 학습하는 것
- Optimal policy(최적 방정식)은 각 state에서 return을 maximize 하는 action을 찾아내는 것
Value function
-
Policy π에 기반해서 특정 state가 agent에 얼만큼 좋은지를 의미
-
time step t 에서 agent가 state S 에 있을때 policy π를 따르면 기대되는 return의 값
-
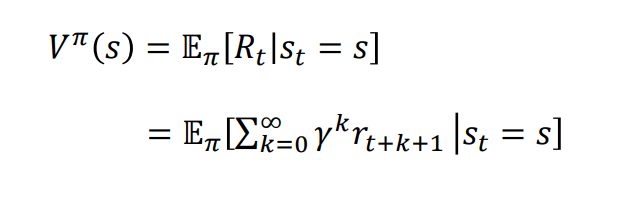
-
Policy π 기반 계산되므로 Policy π가 바뀌면 value도 바뀐다
Value funtion table

State 2에서 value가 더 높으므로 state 2를 선택하게 된다
value란 : 특정 Policy π 에서 해당 state S 에 있는 것이 얼마나 좋은지를 표현, 즉 state로 부터 얻을 것으로 기대되는 return의 값 (높을수록 좋음, maximize 하는것이 목표)
State Action value function
- Action, state 인자 2개를 받음 (action이 추가됨)
- 특정 state에서 어떤 action을 하는 것이 얼마나 좋은지, policy π 기반하여 계산
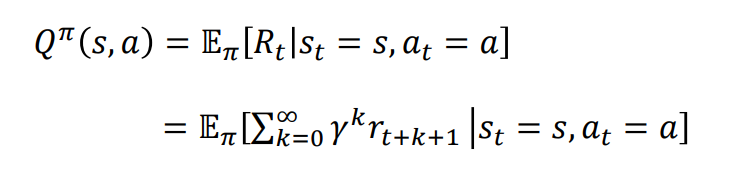
Value function은 해당 state에 있는 것이 얼마나 좋은지
Q function은 해당 state에서 어떤 action을 하는게 얼마나 좋은지

- state1 에서는 action 1을, state 2 에서는 action2를 하는것을 목표로 함
- 강화학습의 최종 목표는 Q 테이블을 찾는 것
- Q 테이블을 찾는다는 의미는 Optimal policy를 찾는다는 의미
value function은 재귀적 특성을 만족한다
