비지도 : input 만 주어짐, hidden 패턴 학습
강화 학습 : 피드백을 받음, 보상(reward)을 극대화 하며 모델을 학습함
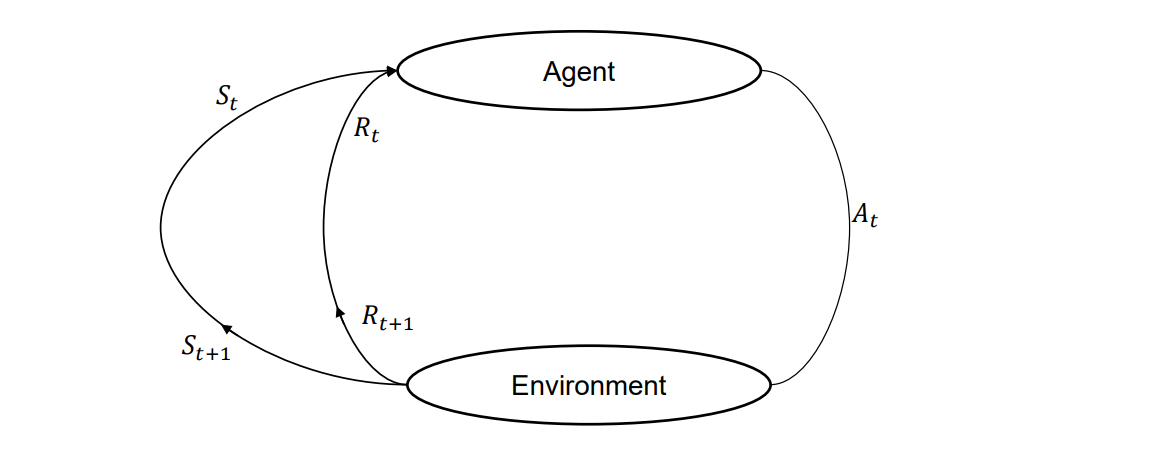
강화학습의 요소
Agent
- 환경과 상호작용하며 행동을 취하고 보상을 얻음
Policy
- 환경에서 agent 행동을 정의
- agent는 policy에 따라 수행할 작업을 결정
- 정책은 π(파이)로 표시됨
Value function
- agent 가 특정 상황에서 얼마나 적합한지 나타냄
- policy 마다 다른 value function을 가짐
- 총 기대 보상과 동일함, agent가 policy에 따라 행동
- Optimal value function은 모든 state에 대해서 가장 좋은 값을 가지는 함수
- Optimal policy 는 최적 value function을 가지는 정책
Model
- agent의 환경
- 2가지 타입
- model based learning(학습된 루트)- Model free learning(모든 루트)
Model(based vs free)을 구별하는 방식은 ?
- agent가 환경에 대한 표현을 가지고 있는지 여부에 따라서
(가지면 based, 없으면 free)
ex 예시)
미로에서 공은 정지되지 않는 방향으로 극대화 된다
계속 positive reward를 찾는 방식
목표 : 목적지에 도달
agent : 공 / 환경 : 미로 / 상태(status) : 공의 위치 / reward(보상) : 공이 멈추지 않을 때
강화학습 환경
결정적 환경 : 현재 상태 기반으로 작업 결과를 아는 경우 - 체스
확률적 환경 : 현재 상태 기반으로 결과를 모를 때 - 주사위
완전한 관찰 : agent 상태를 항상 파악 가능 - 체스
부분적 관찰 : agent 상태를 항상 파악 불가 - 포커
개별 환경 : agent 상태 변경이 제한적 - 체스
지속 환경 : agent 상태 변경이 무한 - 자율주행
에피소드 환경 : 하나씩 진행, 종료 시점이 있음 (1~10km 가속시 1초, 1일 등)
비 에피소드 환경 : 미래에 영향을 끼침, 가상 비서 채팅
Docker란 ?
- 가상 시스템의 일종
- 하드웨어를 가상화 시킴
- 컴퓨터 사용, OS와 관계없이 프로그램을 동일한 환경으로 실행 가능
- 이미지가 실행 될때는 컨테이너 안에서만 실행 됨
컨테이너란 ?
- 응용프로그램, 종속성을 실행할 수 있는 운영체제 가상화
컨테이너의 장점
- 환경 일관성
- 운영 효율성
- 개발 생산성
- 버전 관리
