안녕하세요 오늘은 가상 면접 사례로 배우는 대규모 시스템 설계 7장의 내용에 나와있는 다양한 ID 생성기법을 살펴보며 Snow Flake 기법까지 점진적으로 발전시켜나가보겠습니다.
먼저 ID 생성을 할때에는 기본적으로 지켜져야할 것들이 존재합니다.
그것은 유일성, 보안성, 식별 가능성 등이 있습니다.
(ID 특성에 대해 보다 자세한 내용은 토스가 생각하는 좋은 객체 ID 를 참고해주세요)
그리고 책에서 제시하는 요구사항은 아래와 같습니다
- ID는 유일해야 한다
- ID는 숫자로만 구성되어있다
- ID는 날짜에 따라 정렬이 가능해야한다
- 64비트로 표현될 수 있어야 한다
- 초당 10,000 개의 ID를 만들 수 있어야 한다
이를 만족하기 위해 여러개의 제시한들을 설펴보며 요구사항을 충족하는 ID 생성기법을 알아보겠습니다.
다중 마스터 복제
첫번째로 다중 마스터 복제입니다.
이 ID 생성기법은 매우 단순합니다.
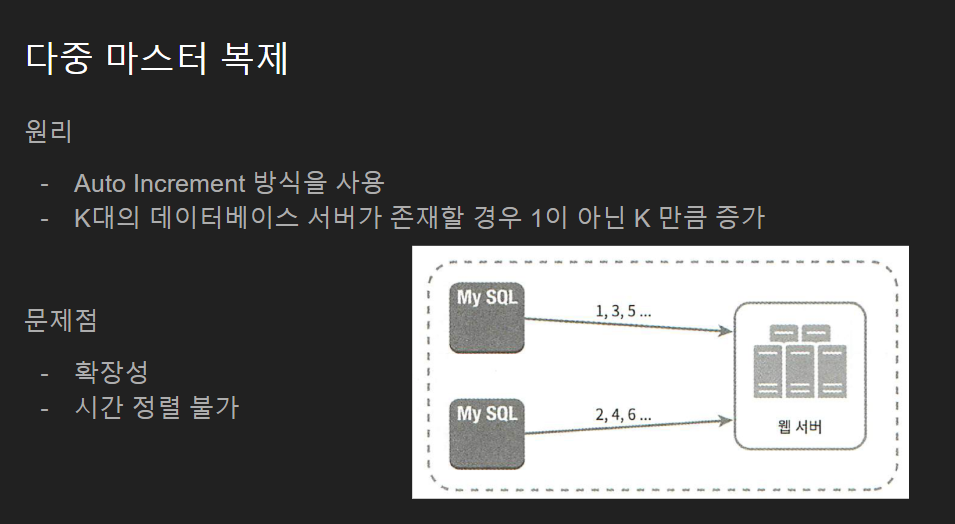
ID를 생성하는 원리는 데이터베이스의 AUto Increment 방식으로 진행하되 데이터베이스의 개수 K 씩 증가시켜주는 것 입니다.
위 그림과 같이 1번 MySQL 서버는 1, 3, 5 / 2번 MySQL 서버는 2, 4, 6 과 같이 증가시켜주는 것입니다.
하지만 문제점은 확장이 불가하다는 것입니다. 처음 정해진 값인 K개의 데이터베이스만 사용해야합니다.
그리고 시간 정렬이 어렵습니다. 객체가 생성된 시간에 따라 정렬이 되어야 하는데, 만약 두번째 데이터베이스에서 객체가 2번 연속으로 생성되었다면 시간정렬조건을 만족시키지 못합니다.
UUID
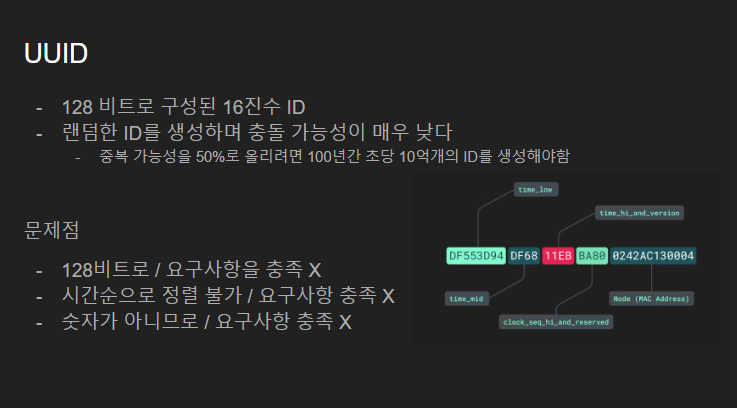
UUID는 랜덤한 String 의 문자열입니다.
UUID의 특징은 매우 명확합니다.
유일성 즉, 중복 가능성이 현저히 낮아 각 서버에서도 독립적으로 생성이 가능하며 다중 마스터 복제처럼 데이터베이스 간 동기화 작업이 따로 필요하지 않다는 것입니다.
하지만 문제점은 ID 가 128 비트로 매우 길며 시간에 대한 정보는 존재하지만 비중이 적어 시간순에 따라 디테일하게 정렬하기가 어렵습니다.
그리고 숫자가 아닌 문자로 되어있어 최초의 요구사항을 충족하지 못합니다.
보통 UUID의 경우 외부와의 통신시 사용하는 경우도 존재합니다.
티켓서버
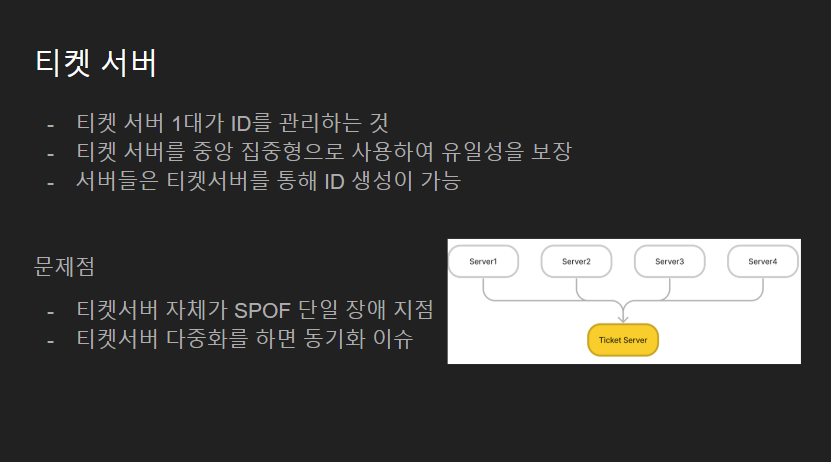
티켓서버는 객체 ID 생성 관리를 티켓서버에서만 하는 것입니다.
이 방식을 사용하면 다른 애플리케이션 서버로 부터 요청을 받아 순차적으로 생성이 가능하여 정렬이 가능하며 숫자로만 구성이 가능하고 유일성도 보장됩니다.
하지만 이렇게 되면 티켓서버 자체가 단일 장애 지점(Single Point Of Faliure)이 될 수 있습니다.
그러니 티켓서버가 만약 장애가 나면 서비스를 이용할 수 없게 됩니다.
이를 해결하기 위해 다중화작업을 하게 되면 이전의 다중 마스터 복제와 같이 동기화 이슈가 발생하게 되며 이를 해결하기란 어렵습니다.
티켓 서버 방식은 중소 규모의 서비스에서는 적합할 수 있습니다.
Twitter Snow Flake
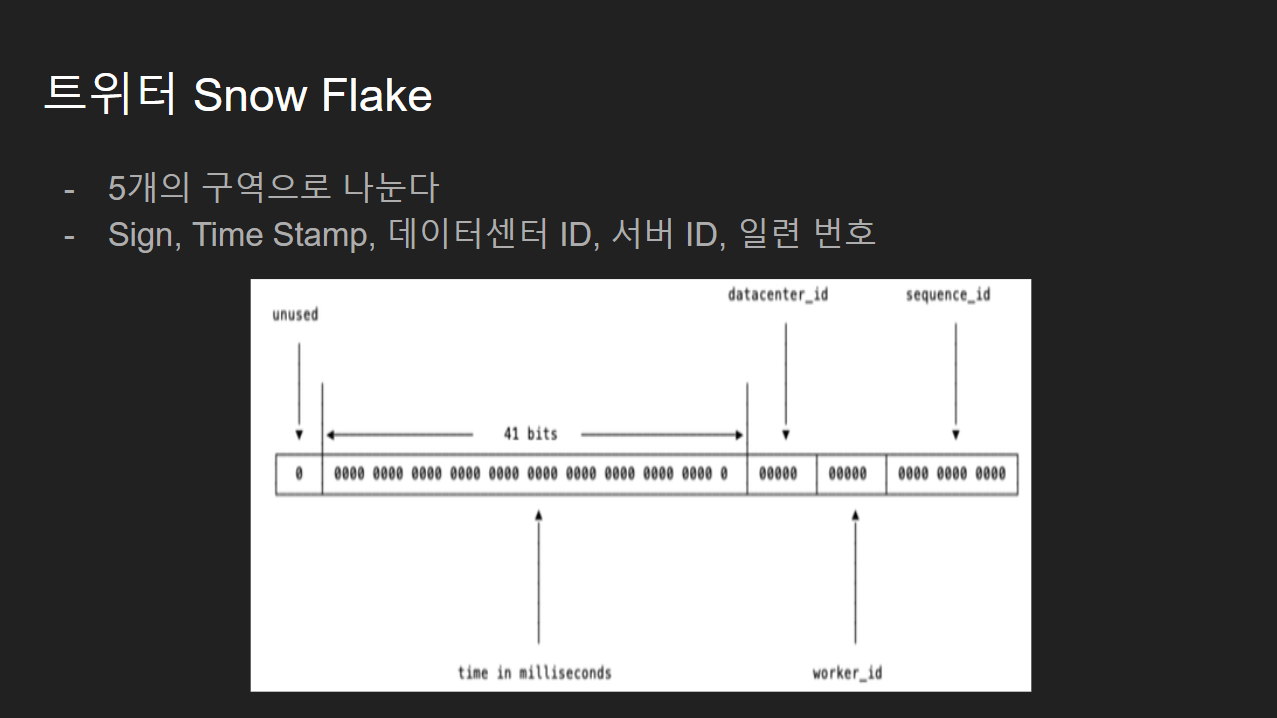
트위터의 스노우 플레이크입니다.
트위터의 스노우 플레이크는 2진수로 이루어져있으며 총 5개의 구역으로 나누어져 있습니다.
각각
- Sign bit
- 생성 시간 정보
- 데이터센터 ID 정보
- 서버 ID 정보
- 객체 일련 번호
구역으로 존재합니다.
각 영역의 역할을 보면
Sign bit
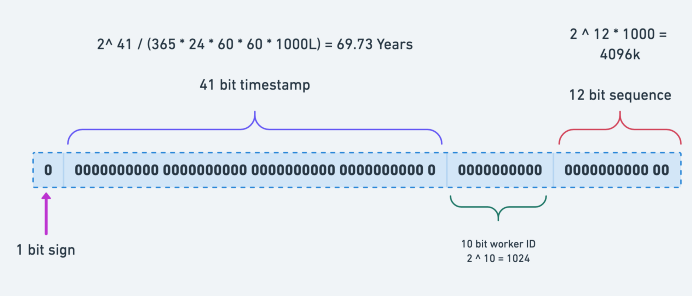
Sign bit는 보통 0으로 세팅되어있고 평소에는 사용하지 않으며 나중에 ID들을 구분할 필요가 있을 경우 미래를 위해 확보해둔 비트 입니다.
Time Stamp
Time Stamp는 총 41비트를 할당합니다. Epoch Time (1970년 1월1일 0시 0분) 이후로 몇 밀리 세컨드가 경과했는지를 나타내며 41비트이므로 최대 69년 시간을 표현할 수 있습니다.
하지만 Epoch TIme을 사용하게 되면 2040년까지만 사용할 수 있게 되어 만약 더 길게 사용하고 싶다면 이 시작시간을 현재로 설정하거나 임의의 시간으로 나타낼 수 있습니다.
데이터 센터 ID, 서버 ID
데이터 센터ID는 5비트로 할당되어 총 32개의 데이터센터를 나타낼 수 있으며 서버 ID도 5비트가 할당되어 32개의 서버를 할당 할 수 있습니다.
일련번호
일련번호로 12비트를 할당하며 (최대 4096) 각 서버에서 ID를 생성할때마다 이 일련 번호를 1씩 증가시킵니다. 이 값은 1ms가 경과할때마다 다시 0으로 초기화가 되어 유일성을 보장합니다.
트위터의 Snow Flake에서는 타임스탬프가 주요한 역할을 합니다. 이에 대해 조금 더 자세히 알아보겠습니다.
Twitter Snow Flake 타임스탬프

(위 사진은 타임스탬프 -> 생성시간으로 변환하는 과정입니다.)
생성 시간으로부터 이 타임스탬프가 만들이지는데에는 여러 동작들이 진행됩니다.
생성시간 -> 타임스탬프
생성 시간 -> 타임스탬프 과정 알아보기 위해 차근차근 알아보겠습니다.
먼저 기원시간으로부터 생성 시간까지 밀리세컨트를 구하고 41비트의 2진수 형태로 나타냅니다.
이 계산은
-
기원일로부터 생성 시간까지의 초를 구합니다. 이는 년도, 월, 일, 시간, 분, 초 순으로 순차적으로 계산됩니다.
-
그렇게 되면 초가 나오게 되고 거기서 1000을 곱합니다.
-
이 밀리세컨드 값은 현재 10진수이므로 이를 다시 41비트의 2진수 형태로 나타내면 타임스탬프가 완성됩니다.
타임스탬프 -> 생성시간
이 타임스탬프의 41비트에서 생성 시간을 알기 위해서는 어떻게 해야할까요 ?
이 타임스탬프가 의미하는 것을 다시 생각해보면 이 타임스탬프가 나타내는 값은 기원시간으로부터 지금까지 얼마나 시간이 지났는지를 밀리세컨드, 2비트로 나타낸것입니다. 이걸 기억하고 다시 생각해보면
- 먼저 41비트의 2진수를 10진수로 변환합니다.
- 기원 시간을 더합니다.
- 그 결과로 얻어진 밀리세컨드를 UTC 시간으로 변환합니다.
이렇게 되면 41비트에서 얻어진 값을 통해 객체 ID가 생성된 시간을 유추할 수 있게 됩니다.
추가 키워드
- 시계 동기화
- 비트 최적화
저희는 현재 모든 서버가 동일한 시간을 사용한다고 가정하고 있습니다.
하지만 실제 기기 local에서는 오차가 있을 수 있으므로 Network Time Protocol을 사용할 수 있습니다.
NTP란 간략하게 설명하면 인터넷을 통해 여러 서버의 시간을 동기화하는 기법입니다.
NTP 서버는 UTC로 나타내는 시간 정보를 전송해주며 NTP는 UDP 기반으로 통신하며 브로드캐스팅 방식으로 서버가 정보를 받아서 시간을 설정하게 됩니다.
비트 최적화는 총 64비트에서 비즈니스에 맞게 각 영역의 길이를 조절하는 것입니다.
