이번시간에는 스프링 튜토리얼을 진행중에 왜 궁금증이 생겼고 이를 풀어나가는 과정을 말씀드려보겠습니다.
스프링 튜토리얼
상황설명
클라이언트와 JSON 형식으로 데이터를 주고 받는 REST 튜토리얼을 진행 중 궁금한 점이 생겼습니다. 그것은 DTO 필드에 없는 value 에 대해 값을 받고 DB에 저장한다는 내용이었습니다.
저는 처음에 당황스러웠습니다. "DTO의 필드 값으로 데이터가 매핑되는 것이 아닌가 ?" 하는 생각이 첫번째로 들었고, 두번째로는 "우선 이게 저장이 되고 기능이 동작하니 어디선가 동적으로 필드가 생성되고 reflection, Object Mapper 키워드와 관련이 있는걸까? 라는 생각이 들었습니다.
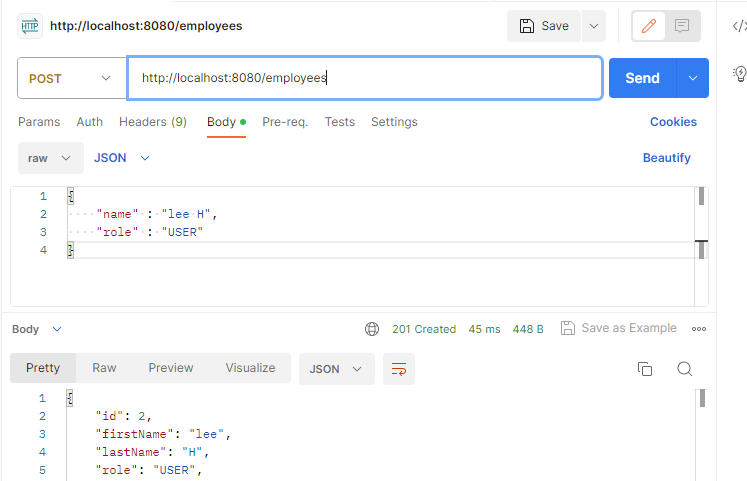
위 튜토리얼에서 Controller 에서 Employee 엔티티를 사용하여 회원을 저장하는 로직이 있었습니다.
회원의 이름에 대한 정보를 받아올때 필드값을 fistName, lastName 으로 받아 해당하는 정보를 저장하고 있었습니다.
{"fistName": "Samwise", "lastName": "Gamgee", "role": "gardener"}하지만 상황이 바뀌어 요구사항 변경이 발생했다고 가정하고 클라이언트에서 요청하는 JSON 객체가
{"name": "Samwise Gamgee", "role": "gardener"}로 변경되었다고 합니다.
그리고 이 요청에 대해 name 을 기존의 데이터베이스의 형식을 유지하기 위해 firstName, lastName 으로 나누어 저장해야한다는 요구사항이 있었습니다.
이 요구사항을 충족하기위한 코드에 Employee 엔티티 클래스에 name 필드는 따로 없었으며 대신 기존에 없던 setName(), getName() 이 아래와 같이 추가되었습니다.
아래는 Employee 엔티티의 일부입니다.
public class Employee {
private String firstName;
private String lastName;
public void setName(String name) {
String[] parts = name.split(" ");
System.out.println("들어오나 ?");
this.firstName = parts[0];
this.lastName = parts[1];
}
public String getName() {
return this.firstName + " " +this.lastName;
}
}아래는 Controller 의 일부입니다.
@PostMapping("/employees")
ResponseEntity<?> newEmployee(@RequestBody Employee newEmployee) {
EntityModel<Employee> entityModel = assembler.toModel(repository.save(newEmployee));
return ResponseEntity
.created(entityModel.getRequiredLink(IanaLinkRelations.SELF).toUri())
.body(entityModel);
}이 상황에서
"어떻게 name 으로 값을 받을 수 있을까? Dto 클래스에는 name이 있는게 아니고 firstName, lastName 필드가 왜 그대로 있는거지 ??"
하는 의문이 들었습니다. 왜냐하면 DTO 역할을 하는 Employee에서는 name 필드가 없었지만 클라이언트에서는 JSON 객체의 key로 name을 주고있었기 때문입니다. 즉 제가 생각하기에는 매핑될 필드가 없었기 때문입니다.
그래서 처음에는 reflection, ObjectMapper 기술이 사용되어 필드를 어떻게 동적으로 생성이 되어 처리가 되는구나 하고 예상해보았었습니다.
각 기술에 대해 짧게 알아보겠습니다.
Reflection이란 ?
- 힙 영역에 로드돼 있는 클래스 타입의 객체를 통해 필드/메소드/생성자를 접근 제어자와 상관없이 사용할 수 있도로 지원하는 API
- 클래스 타입을 모를때 사용하는 방법
- 컴파일 시점이 아닌 런타임 시점에 동적으로 특정 클래스의 정보를 가져는 방법
이렇게 정리를 하였는데 쉽게 말하면 런타임시 클래스 로더를 통해 객체에 대한 정보를 가지고 사용하는 API 이다. 하지만 이번 경우에는 이 기술이 상관이 없었다.
Object Mapper 란?
- JSON 컨텐츠를 Java 객체로 deserialization(역직렬화) 하거나 Java 객체를 JSON으로 serialization 할 때 사용하는 Jackson 라이브러리 클래스이다.
다시 말해 Object Mapper를 사용하면 클라이언트에서 전송한 JSON 객체를 Java 객체로 만들거나 반대로 서버에서 생성한 Java 객체를 다시 JSON으로 만드는 작업을 쉽고 편하게 할 수 있도록 도와주는 라이브러리 이다.
여기서 주의 깊게 봐야할 부분은 Jackson 라이브러리 입니다.
Jackson 라이브러리의 동작 원리를 살펴보겠습니다.
동작 원리
Jackson은 기본적으로 필드의 이름을 기준으로 data를 매핑합니다. 예를 들어 앞서 살펴본 예제와 같이
{"name": "Samwise Gamgee", "role": "gardener"}JSON 형태가 있다면 POJO 객체로 변환할 때 변환할 클래스에 멤버변수인 "name"을 참조하게 됩니다.
이때 중요한 것은 멤버변수를 기준으로 할때 해당 접근자는 public 이어야 합니다. public이 아니라면 Jackson은 접근할 수 없습니다. 하지만 보통 DTO 클래스는 필드를 private을 접근제어자로 설정하며 getter(필요한 경우 setter)를 많이 사용하게 됩니다.
여기서 get 메서드가 있는 경우 이는 public으로 Jackson이 접근하여 해당 객체와 매핑을 지어줄 수 있으며 getXXXX() 메소드는 XXXX key와 연결이 됩니다.
즉, 예를 들어 {"name": "Samwise Gamgee", "role": "gardener"} 데이터를 객체로 바인딩 했을때 POJO의 getName() 메소드에 의해 name 과 매핑이 됩니다.
이 부분이 핵심입니다. 여기서 name은 필드에 존재하지 않지만 getName() 메소드는 this.firstName +" "+this.lastName을 반환하며 이 firstName, lastName은 Employee 클래스 필드에 존재합니다. 따라서 현재 존재하는 필드값인 firstName, lastName 으로 처리되어 Dto 클래스 필드에는 없는 값인 name 으로도 값을 받아 처리할 수 있었던 것 입니다.
또한 값을 저장시에는 setName() 메서드가 있으므로 직렬화시 위와 동일한 원리로 적용되는 것 같습니다.
(setName() 메서드를 주석처리하니 모두 null로 처리가 되었고 값을 받아올 수 없었습니다.)
객체 저장시 이 setName() 이 호출되는 것을 확인하였습니다.

핵심
조금 더 풀어서 설명을 해보자면 저희가 Dto를 사용할때 Getter 를 많이 사용합니다.
하지만 이 데이터를 받아와서 처리가 될때 어떻게 동작하는지를 생각해보면 이는 Jackson 라이브러리 클래스인 Object Mapper 를 사용해서 가능합니다.
여기서 Getter 가 어떤 역할들을 했을까요 ?
이 둘은 JSON 객체의 key 를 POJO 객체의 필드와 이어주는 역할을 하고 있었습니다.
Jackson 은 기본적으로 public 에 열려있는 필드들에 대해 접근을 할 수 있습니다. 하지만 보동 저희들은 private으로 접근제한자를 두죠
ObjectMapper가 Property를 어떻게 찾는지 살펴보면
ObjectMapper 인스턴스를 생성할때 ConfigOverrides() 를 호출하고
이 ConfigOverrides() 에는 Std.defaultInstance() 를 호출하며
Std.defaultInstance() 에는 아래와 같이 VisibilityChecker 가 있습니다.

Json을 객체에 파싱할 때 객체 정보를 알기 위해서는 Getter, Setter, Field 중에서 접근 제한자가 위 조건을 만족하는 것이 꼭 있어야 합니다.
그리고 객체 생성을 위한 기본 생성자도 있어야 하구요.
그러면 이번 경우에는 Getter 메서드가 존재하니 이 메서드를 사용하는 것 입니다.
Getter 메서드를 통해 필드에 접근을 하게 되는데 이때 메서드명을 통해서 필드값을 받아옵니다.
예를 들어 getName() 이라면 name 으로 받아오는 것이죠.
이는 역직렬화로 JSON 을 객체로 변환하는 과정에서 발생하게 됩니다.
반대로 객체를 JSON으로 변환할 경우 Constructor (생성자) 가 사용되는 것 입니다
(이러한 이유로 Object Mapper 사용시 반드시 기본 생성자가 필요한 것 같습니다.)
이러한 과정과 원리를 통해 request response 를 처리할 수 있습니다.
결과적으로 이렇게 결론이 나왔지만 처음 글을 보시고 굳이 ? 왜 ? 라는 생각을 할 수 있습니다. (처음에 저도 하면서 다른 방법은 없을까? 생각을 하였습니다. 이는 바람직하지 않은 구조라고 생각이 됩니다. JSON 객체의 key 값과 서버에서 처리하는 필드명이 다르다면 큰 혼란을 가져올 수 있기때문입니다.)
튜토리얼을 진행하며 제시한 요구사항이 레거시를 유지하기 위한 조건이 있었고 위 코드는 그 조건을 따르기 위해 제시된 방법 중 하나라고 생각합니다.
만약 레거시를 유지해야한다는 요구사항이 있을 경우 다른 방법으로는 DTO를 새로 만들거나, DB 설계를 다시 하는 등등 다양한 방법이 존재한다고 생각합니다.
자바 빈 규약
여기서 자바 빈 규약에 대해서도 알아보겠습니다. 자바 빈 규약 중 직렬화가 되어있어야 한다는 규약이 있어 이에 대해 조금 더 알아보도록 할게요!
자바빈이란 자바빈 규약을 따라는 클래스를 의미합니다.
자바 빈 규약은 아래와 같습니다.
- 자바빈은 기본 패키지 이외의 특정 패키지에 속해있어야 한다.
package com.app.bean
public class MyBean {
}- 기본 생성자가 존재해야 한다.
package com.app.bean
public class MyBean {
public MyBean(){}
}- 멤버 변수의 접근 제어자는 private 로 선언되어야 한다.
package com.app.bean
public class MyBean {
private String beanProperty;
public MyBean(){}
}-
멤버변수에 접근 가능한 getter, setter메서드가 존재해야 하며 각 메서드의 접근제어자는 public으로 선언되어야 한다.
-
직렬화가 되어 있어야 한다 (선택사항)
객체 직렬화는 객체를 입출력시에 사용할 수 있도록 객체의 멤버들을 바이트 형태로 변환하는 것을 의미합니다.
객체를 바이트 스트림으로 변환하는 것을 마샬링(Mashalling) 이라고 하며 바이트 스트림에서 객체로 만드는 것을 언마샬링(UnMashalling) 이라고 합니다.
직렬화는 java.io.Serializable 인터페이스를 상속하여 직렬화할 수 있습니다.
package com.app.bean
public class MyBean implements Serializable {
private static final long serialVersionUID = 1679166037496682065L;
private String beanProperty;
public MyBean(){}
public String getBeanProperty() {
return beanProperty;
}
public void setBeanProperty(String beanProperty) {
this.beanProperty = beanProperty;
}
}직렬화, 역직렬화시 dto 클래스에게 요구하는 것
직렬화란 무엇일까요 ?
데이터는 2개의 타입으로 나눌 수 있습니다.
- 값 타입 (boolean, int, String...)
- 객체 타입(Book, Car ...)
데이터를 입출력시에 사용하기 위해서는 byte단위로 전송, 수신이 가능합니다. 값타입의 경우 byte 단위로 입출력이 가능하지만 객체는 불가합니다. 이때 객체를 byte 형태로 변환하는 것을 "직렬화" 라고 합니다.
Java 시스템 내부에서 사용되는 Objecet나 Data를 외부의 Java 시스템에서도 사용할 수 있도록 byte 형태로 데이터를 변환하는 기술(객체를 전송가능한 byte 형태로 변환하는 것)
반대로 네트워크나 저장소에서 byte 스트림을 가져와 객체로 변환하는 것을 역직렬화(Deserialization)라고 부릅니다.
저희는 위의 자바 빈 규약에서 Serialize 인터페이스를 상속해야한다 라는 규약이 알아보았어요.
자바빈 규약과 직렬화를 함께 생각해볼 수 있을 것 같아요.
Employee 클래스에 serialize를 상속하여 사용한다면 Employee 필드들을 자연스럽게 직렬화, 역직렬화를 할 수 있게 될 것입니다.
@ModelAttribute, @RequestBody 차이
@RequestBody와 @ModelAttribute: 차이점과 사용법
1. @RequestBody와 @ModelAttribute 개요
@RequestBody와 @ModelAttribute는 클라이언트가 보낸 데이터를 Java 객체로 변환하는 데 사용됩니다. 이 두 애너테이션을 올바르게 이해하고 사용하지 않으면 예상치 못한 오류가 발생할 수 있습니다. 이번 포스팅에서는 이 두 애너테이션의 특징과 차이점을 살펴보겠습니다.
- @RequestBody
@RequestBody는 HTTP 요청의 본문을 Java 객체로 변환합니다. 주로 JSON이나 XML 형식의 데이터를 처리합니다.
특징:
데이터 변환: 클라이언트가 보낸 HTTP 본문 데이터를 HttpMessageConverter를 통해 Java 객체로 변환합니다.
필드 바인딩: 기본 생성자와 getter/setter가 필요합니다.
데이터 형식: JSON, XML, Text 등 다양한 형식을 처리합니다.
정리:
직렬화/역직렬화: 기본 생성자 필요.
필드 바인딩: getter/setter 중 하나는 필수.
데이터 형식: JSON, XML, Text 등 다양한 형식을 지원.
3. @ModelAttribute
@ModelAttribute는 HTTP 요청 파라미터를 Java 객체에 바인딩합니다. 주로 Form 데이터나 Query String을 처리합니다.
특징:
데이터 바인딩: HTTP 파라미터 데이터를 Java 객체에 맵핑합니다.
필드 접근: 생성자나 setter 메서드를 통해 필드에 접근합니다.
데이터 형식: Query String 및 Form 형식의 데이터만 처리합니다.
정리:
데이터 바인딩: 생성자나 setter 메서드를 통한 필드 접근 필요.
데이터 형식: Query String 및 Form 형식의 데이터만 처리 가능.
결론
@RequestBody: JSON, XML 등 다양한 형식을 처리하며, 기본 생성자와 getter/setter가 필요합니다.
@ModelAttribute: 주로 Query String과 Form 데이터를 처리하며, 생성자나 setter 메서드가 필요합니다.
참고
