설명
빅데이터 혁신 사업단에서 진행하는 빅데이터 동계 캠프에 참여했다. 빅데이터 혁신 융합대학은 서울대학교 주최로 총 7개의 대학이 연합을 맺어 만든 사업단이고, 다양한 교육 및 캠프들을 무료로 제공해 준다. 기간은 1월 8일 ~ 1월 12일 총 5일간 진행되었으며 AWS 플랫폼 Deep Racer에 대해 학습하고 실습을 진행했다. 따라서, 사업단에서 배웠던 내용, 경진대회를 위해 준비했던 내용에 대해 포스팅해보려고 한다
커리큘럼
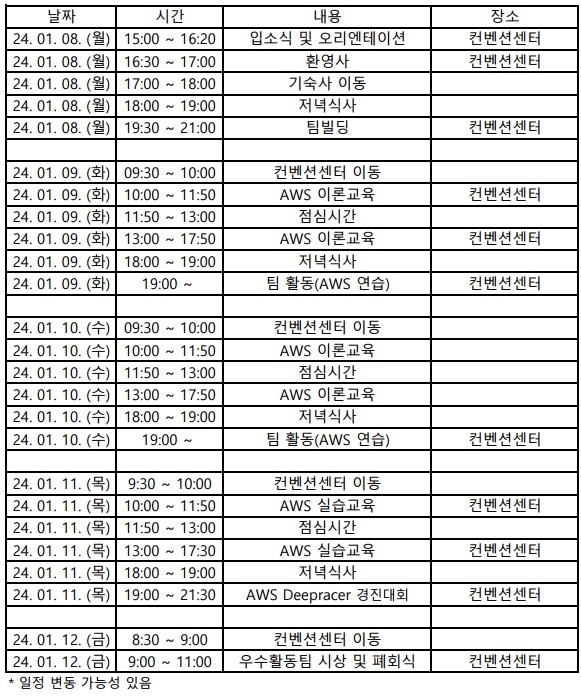
커리큘럼은 다음과 같다. 첫날에는 간단하게 팀 빌딩이 되고, 둘째 날부터 본격적으로 교육 및 실습이 진행되고 , 마지막 날 밤에는 경진대회를 하게 된다. 경진대회 결과에 따라 시상 및 상금까지 주어진다. 팀 빌딩 중 우리 팀은 총 5명으로 구성되었으며 전북대 4명, 숙명여대 1명 구성이었다.
팀원 모두가 AWS 시스템에 처음이었다, 또한 deep racer의 주된 학습 방식인 강화 학습을 경험해 본 사람이 한 명도 없었다. 하지만 모두 열심히 배워서 꼭 수상해 보겠다는 의지가 있었고, 결국에 마지막에 좋은 결과를 도출해 냈다.
학습 과정
AWS ? Deepracer ?
우선 AWS란 클라우드 컴퓨터 분야에서 압도적으로 세계 1위의 점유율을 차지하고 있는 아마존닷컴의 클라우드 컴퓨팅 서비스이다. 뭐 간단하게 말하자면 자원을 빌려서 쓰는 서비스라고 생각하면 된다. 이 자원은 많이 쓰면 쓸수록 비용이 발생하도록 설계가 되어있다.
해당 과정은 AWS에 Deepracer 기능을 주로 활용한 자율주행 관련 과정이었다. AWS DeepRacer는 자율 레이싱에 중점을 둔 강화 학습을 살펴보기 위한 AWS 기계 학습 서비스이며, 간단하게 말하자면 강화 학습으로 시뮬레이션 상으로 자동차를 학습시켜 자율 주행을 하도록 하는 것이다. 모델을 배포하게 되면 학습된 시뮬레이션을 바탕으로 실제 자동차에서는 차량 전면에 장착된 카메라를 통해 추론을 실시하게 된다. 물리적 자동차에 Wi fi를 연결하면 소프트웨어를 다운로드할 수 있다.
우선 이 시스템을 사용하기 위해 AWS 계정을 개인별로 지급받았다. 교육이 끝남과 동시에 계정이 막혀 포스팅 시점에는 들어가 볼 수 없는 게 조금 아쉽다 .. 아무튼 부여받은 계정은 Root 계정이었으며 원하는 자원을 모두 사용이 가능했다. 특히 Deepracer 강화 학습 과정은 10시간 무료로 제공된 이후에는 시간당 3.50 USD 비용이 발생한다. 이러한 자원을 주최 측에서 3일 동안은 자유롭게 사용하도록 해주었기 때문에 많은 시도를 부담 없이 해볼 수 있었다. 아마 3일 동안 얼마나 많은 모델을 테스트해보느냐가 프로젝트 성과에 영향을 미칠 것 같다.
해당 과정에서 paas, laas, Saas 등 클라우드 시스템에 대한 전반적인 개념들도 다뤘다. 덕분에 예전에 잠깐 배웠지만 흩어져있던 개념들을 정리할 수 있었다.
강화학습
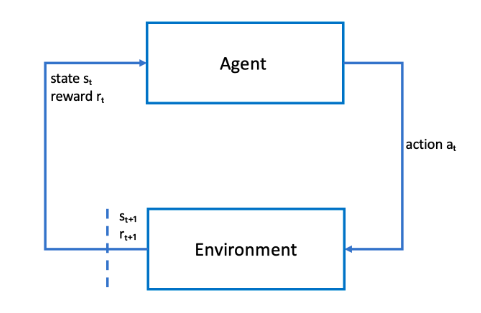
위 사진은 AWS Deepracer 강화 학습 방식이다. 의도한 목표를 달성하기 위한 목표를 가진 물리적 또는 가상 AWS DeepRacer 차량과 같은 에이전트는 환경과 상호 작용하여 에이전트의 총 보상 극대화하게 된다. 차량의 전방 카메라에서 촬영된 이미지는 환경 상태이고, AWS DeepRacer는 1초에 15 프레임의 이미지 전송한다.
사실 나는 강화 학습 개념에 익숙하지 않았다. 주어진 입력 데이터에 대해 정확한 출력을 예측하는 것이 목표인 지도학습, 데이터의 숨겨진 구조나 패턴을 발견하거나 그룹화하는 비지도 학습은 흔하게 접해보았으나 강화 학습이 어떤건지 개념 또한 모호하게 알고 있었다.
강의를 통해 배운 강화 학습의 목표는 최대한의 보상을 받는 행동을 찾는 것이다. 조금 더 부연 설명을 더해보자면 특정 행동에 대한 보상과 벌칙에 의하여 경험을 학습하여 모델을 생성하는 방법이다. 즉, 잘하면 보상을 많이 주고 못하면 벌칙을 주어 Agent 잘할 수 있도록 만드는 것이다. Deep racer에 적용해 보면 Agent는 자동차가 되는 것이고, 벌칙을 주는 것은 내가 하는 코딩이 되는 것이다. 이 부분은 뒤에서 더 자세하게 다루겠다.
강화 학습 특징
1. Tiral and error(시행착오)
- 시행착오를 통해 최적의 행동을 찾아낸다.
2. Reinforecmnet Signal(보상 신호)
- 에이전트는 환경과 상호작용하면서 보상과 패널티를 경험하고, 이러한 결과를 바탕으로 행동을 개선할 수 있다.
- 장기적인 목표를 위해 단기적인 보상을 고려해야한다.
3. Delayed Rewart(보상 지연)
4. Exploration and Exploitation(탐험과 이용)
5. 복잡한 문제를 해결하고 실시간 학습에 적용
예) 로봇 , 신경과학 , 게임 이론 , 신경과학
강화학습 작동 방식
Agent(에이전트) = 자동차
- 의사 결정을 수행하는 주체
- 환경과 상호작용하며 행동을 결정하고 보상을 받는다
Enviortment(환경)
- 에이전트의 해동하는 상태와 보상을 결정
state(상태)
- 환경과 상호작용할때 어떤 상황에 있는지
Action(행동)
- 에이전트가 의사 결정을 통해 환경에 대해 가하기로 선택한 변화
Reward(보상)
- 에이전트가 특정 행동을 취했을 때 받는 신호
- 좋은 행동에 대해 무조건 많은 양의 보상만 주는건 좋은게 아니다 .
policy(정책)
- 앞으로 에이전트가 해야할 행동
문제 푸는 과정
- 순차적 행동 문제 MDP로 전환
- 가치함수(보상을 극대화 하는 방법을 찾는것)를 벨만 방적식으로 반복적 계산
- 최적 가치함수와 최적 정책을 찾는다.
*MDP : agent가 envionmet로 부터 받은 state는 뭐냐 , action은 뭘 해야하냐 , reward는 뭐냐를 결정하는과정
가치 함수
- Agent가 어떤 정책이 더 좋은 정책인지 판단하는 기준
- 현재 상태의 정책을 따라갔을때 얻는 예측 보상의 총합
벨만방정식
- 각각 상태에 대한 가치함수 기대값을 얻고 이것들을 모두 계산하여 최적의 정책을 찾는것
- 현재 상태와 다음 상태의 관계를 나타내는 방정식
- 다이나믹 프로그래밍으로 쪼개서 풀게된다
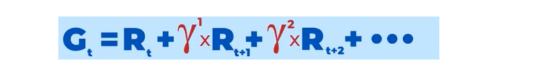
결국 강화학습의 궁긍적인 목표는 모든 보상의 합인 G값을 최대화 하는것이다.
그외 자세한 개념들은 너무 많기 때문에 생략하도록 하고 , 본격적으로 프로젝트를 했던 과정에 대해 포스팅 하겠다.
프로젝트
앞서 강화 학습, Aws Deepracer에 대한 전반적인 개념들을 학습했으니 이제 본격적으로 프로젝트에 적용을 해보았다. 해당 프로젝트에서는 자동차가 자율주행을 빠르고, 안정적으로 할 수 있도록 적절한 보상 함수 코딩과, 하이퍼 파라미터 튜닝으로 최적의 모델을 찾는 것이 목표이다. 즉, 여러 가지 요인들을 파악해 deepracer 시뮬레이션상에서 강화 학습을 통해 최적의 모델을 도출하고, 해당 모델을 실제 자동차에 import 해 실제 Track을 빠르고 정확하게 돌아야 한다. 실제 경진 대회에서는 트랙 밖으로 자동차가 이탈 시, 트랙 가장자리 선에 닿았을 시 감점이 있었기에 정확하고, 빠르게 Track을 돌 수 있는 모델을 만들어내는 것이 필요했다.
우선 알고리즘은 AWS 자체에서 선택이 가능하다. 기본적으로 본 실습 과정은 PPO 알고리즘을 사용하였고, 사실 알고리즘에 대한 자세한 코드를 수정하기는 어려웠다. 따라서 PPO 알고리즘이 고정된 상태에서 Hyperparameters 튜닝과 보상 reward function(보상 함수)를 조정함으로써 빠르게 Track 완주하는 것이 목표였다. 우선 조정 가능한 Hyperparameters와 reward function을 간단하게 적어보자면 다음과 같다.
Hyperparameters
- batch size
- number of epochs
- learning rate
- entropy
- discount factor
- speed/max speed
보상 함수 매개변수
- Position on trace : 트랙에서의 위치 차량에서의 위치 x,y
- Heading : x축에서 시계방향으로 측정된 차량의 방향 각도
- waypoints : x,y좌표로 이정표 좌표
- track_width : 미터단위 너비
- distance_from_center : 트랙 중앙에서 차량의 변위
- is_left_of_center : 중앙선에 왼쪽이 있는
- all_wheels_on_track: 네바퀴가 트랙 경계 안에 있으면 true , 바퀴가 트랙 밖에 있으면 false
- speed : 속도
- streeing_angle : 조향 각도
자세한 보상함수 내용은 https://docs.aws.amazon.com/ko_kr/deepracer/latest/developerguide/deepracer-reward-function-input.html 사이트를 참고하면 된다.
기본적으로 공식 예제로 주어지는 보상함수 코드는 다음과 같다.
def reward_function(params):
Example of rewarding the agent to follow center line
track_width = params['track_width']
distance_from_center = params['distance_from_center']
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
if distance_from_center <= marker_1:
reward = 1
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return rewarddistance_from_center은 차량이 중앙에서의 변위인데 이 변위가 적을수록 보상을 많이 주는 형태이다. 이 예제로 모델을 학습 시키기만 해도 차량은 정상적으로 주행한다. 하지만 조금 더 정밀하고, 빠른 주행을 하기 위해 더 많은 수정이 필요했다. 이 예제 말고도 AWS 자체에서 제공하는 다양한 보상 함수 예제가 있지만 다른 것들은 생략하도록 하겠다.
처음에는 이미 경진대회를 경험한 다양한 사람들의 코드를 참고해 테스트해봤다. 하지만 한 트랙에만 너무나도 과도하게 학습하는 과적 합의 발생하거나, 제대로 학습을 못하는 현상이 발생했다.
그러다 발견한 https://coronasdk.tistory.com/m/1012 이분의 코드를 참고했다. 하이퍼 파라미터는 다양하게 시도하면서 팀에 맞게 바꿨지만 , 보상함수 베이스 코드는 해당 블로그를 따라갔다.
시도 과정 1

Reward function
def reward_function(params):
reward = 1e-3
track_width = params['track_width']
distance_from_center = params['distance_from_center']
steering = params['steering_angle']
speed = params['speed']
all_wheels_on_track = params['all_wheels_on_track']
if distance_from_center >= 0.0 and distance_from_center <= 0.03:
reward = 1.0
if not all_wheels_on_track:
reward = reward - 1
else:
reward = reward + (params['progress'])
if speed < 1.34 :
reward *= 0.80
elif speed >= 1.34 and speed <= 2.665 :
reward += speed
else :
reward = speed*speed+reward
return float(reward)위와 같은 조건을 베이스로 첫 시도를 해보았다. 하이퍼 파라미터는 거의 블로그를 참고해 거의 수정하지 않았으며, 보상 함수는 max speed를 조정함에 따라 같은 비율로 수치를 줄이기만 했다. max speed 줄인 이유는 처음 실행 결과가 속도가 너무 빨라 학습을 제대로 못하고 이탈률이 높았기 때문이다.
코드에 조건을 설명하자면
- 바퀴4개가 이탈했을때 보상 (-)
- 중앙을 유지할때 보상 (+)
- speed를 유지할때 보상(+)** 크게 이렇게 3개의 조건이다.
여기에 우리팀은 추가 조건으로
- steering_angle -> 조향각도에 따른 보상여부
- is_left_of_center & (not) is_offtrack -> inline으로 가면서 빠져나가지 않는 조건으로 보상여부
를 추가시키면서 실험을 진행하였다. 중간에 1시간 학습한 모델로 테스트해 본 결과 무조건 많은 조건을 넣는다고 에이전트가 잘 학습하는 건 아니었다. 따라서 나눠서 모든 경우의 수를 생각하며 학습시켰다. 학습 시간은 6시간을 기준으로 했다.
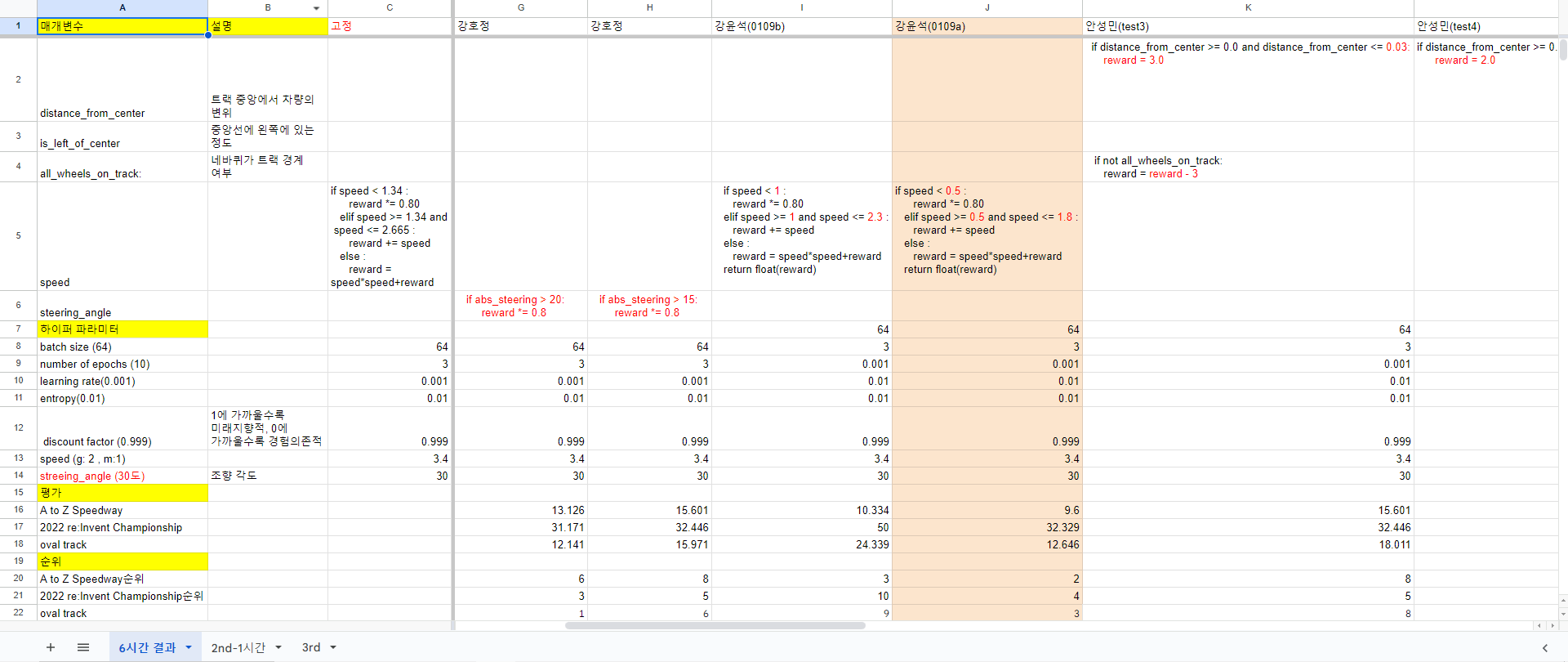
위와 같이 공통적으로 고정하는 하이퍼 파라미터에 조건만 다르게 여러가지 방법으로 실험해보았다. 한 사람당 6시간씩 4개 즉 총 20개의 모델을 뽑을 수 있었고. 모든 모델을 3개의 Track(A to Z Speedway , 2022 re:Invent Championship , oval track)으로 평가해 속도 순위를 부여했다.
상위 순위의 3개의 그래프는 다음과 같다.
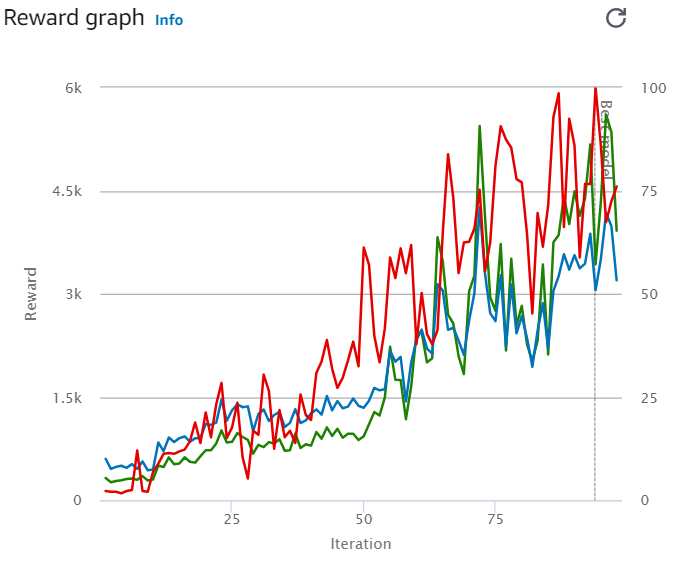

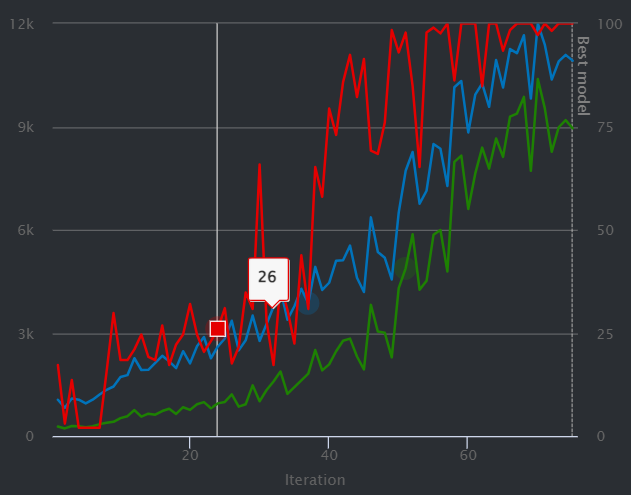
위 그래프에 대해 설명하자면 초록색 그래프는 훈련( Training) 과정 중 각각의 Episode에서 받게 되는 보상의 합을 평균 낸 것이다. 즉, 훈련이 잘 되는 정도이다. 또한, 파란색 그래프는 훈련( Training) 과정 중 각각의 Episode에서 완주율을 평균 낸 것 의미한다
속도만 비교해 봤을 때 위 3개의 그래프를 가지는 보상 함수 조건이 가장 빨랐지만 위와 같이 초록색 그래프가 들쑥날쑥한 것은 결코 좋은 모델은 아니었다. 학습이 불안정하다는 뜻이었기 때문이다. 위 모델을 실제 물리적인 차량에 연결하고 Track에 돌려보니 속도는 빨랐으나 Track 이탈률이 너무 높았다. 경진대회에서 이탈을 하게 되면 결국 아무 의미가 없기 때문에 이탈률을 최대한 줄이자는 방향으로 조정해야 했다.

차량은 위 사진과 같이 생겼고, 앞에 보이는 흰색이 카메라다.
시도 과정 2
이후 다양한 실험을 해보면서 추가적으로 발견한 사실은 "속도를 줄이는 게 안정적이라는 점"과, "학습을 무조건 많이 한다고 해서 좋은 것은 아니라는 점"이다. 학습을 너무 많이 하다 보면 일정 시점에서 학습이 불안정해 초록색 그래프가 하락할 수 있고, 속도가 너무 빠르면 커브 구간에서 속도를 감당하지 못했다.
따라서 학습 시간 조정, 속도 조정, 속도 조정에 따른 보상 함수 구간 조정, steering 보상 변수 추가 여부, inline 보상 변수 추가 여부에 따라 다양한 경우의 수를 생각하여 실험해 보았다. 이번에도 마찬가지로 Track3개로 평가해 가장 잘 나온 모델로 선정하게 되었다. 회색으로 표시한 3개의 모델이 가장 잘 나온 조건이다.

해당 모델들의 그래프를 비교해 보았는데 max speed:2 /speed 기준 구간 : 0.75-1.75 / 학습시간:2h
steering(0) 인 모델이 가장 좋은 그래프 양상을 보였다. 그래프를 첨부하고 싶지만 교육이 끝남과 동시에 AWS 계정을 막아버려서 그래프를 확인할 수 없다.. 나중에 혹시라도 팀원이 가지고 있다면 추가하겠다. 아무튼, 초록색(학습)은 매우 우상향 그래프가 나왔으며 파란색(완주율) 또한 높았다. 해당 모델을 가지고 경진대회에 참여하게 되었고 차량 상태에 따라 차량 기본 세팅 값은 조정했다.

경진대회에서는 다음과 같은 Track에서 진행 하게 되었고 , 우리팀은 한바퀴 기준 9초 기록으로 2등을 하게 되었다. 1등팀은 7초인데 진짜 어마어마했다.. 아무튼 우수상과 상금을 받았다 ! !
느낀점
동계 캠프에 참여하며 가장 먼저 느낀 점은 "빅데이터 산업이 정말 많이 활성화되었다는 점"이다. 전북대학교에서 진행하는 프로그램이었지만 같은 빅데이터 혁신 대학에 속해있는 다른 학생들도 많이 참가해 총 90명의 학생들이 참가했다. 놀란건 생각보다 참여자 중 IT, AI, 빅데이터 분야에 전공자는 적었다. 우리 팀에도 딱 한 명이었다. 하지만 팀원 포함 대부분의 사람들이 해당 과정에 강한 열정이 있었다.
그 이유는 프로그래밍에 접근성 때문이라고 생각한다. 아마, AWS Deepracer 플랫폼에서 기능을 제공하지 않고 강화 학습 모델을 PPO 알고리즘으로 고정하지 않았다면? 학습을 모두 직접 코드로 작성해야 했다면? 수많은 시간이 걸렸을거다. 하지만, AI 기술은 점점 발전하면서 프로그래밍 하는 것이 모든 알고리즘을 다 짜는 것이 아닌 일부 수정으로 만으로도 가능했고, 비 전공자 들고 쉽게 재미를 붙일 수 있게 설계가 되어가는 것 같다.
쉬운 프로그래밍 방식에 더해 각자 다른 도메인 지식을 가진 팀원들의 강점을 최대한 살리고, 다양한 시도를 해보는 열정을 가졌기에 시너지를 냈다. 결과는 좋은 결과로 따라왔다. 이 캠프를 참여하면서 클라우드 기본 개념, 강화 학습 이론, AWS Deepracer 사용법 및 실습, 좋은 동료, 거기에 수상 이력까지 많은 것을 얻어 갔다. 앞으로 기회가 된다면 AWS에 대한 공부 및 강화 학습에 대한 공부는 추가적으로 할 예정이다. 열정적인 사람들을 보며 여러 가지로 나에게 많은 자극이 되었던 의미 있는 과정이었다고 생각한다.
