시작
이번 포스팅은 ELK중 L에 해당하는 로그스태시에 대해 포스팅해보겠다. 로그스태시를 활용해 본격적으로 로그를 원하는 형태로 가공하고 엘라스틱서치나 키바나에서 모니터링하는 과정들에 대해 다뤄보겠다.
로그 스태시란 ?
로그스태시는 플러그인 기반의 오픈소시 데이터 처리 파이프라인 도구이며 , 다소 복잡하고 귀찮은 데이터 전처리 과정을 별도의 애플리케이션 작성 없이 비교적 간단한 설정만으로 수행할 수 있다. 주요 특징은 다음과 같다.
- 플러그인 기반 : 플러그인을 구성하는 각 요소들은 전부 플러그인 형태
- 모든 형태의 데이터 처리가 가능하며 특히 이벤트 데이터 처리 최적화
- 자체적으로 내장되어 있는 메모리와 파일 기반 큐를 사용하므로 처리 속도와 안정성 높음
- 장애 상황에서도 도큐먼트 유실을 최소화 할 수 있어 안정성
설치 및 실행
먼저 JDK를 설치하고 위 사이트에서 로그스태시를 다운받아 설치한다.
파이프라인
로그스태시를 실행하기 위해서는 반드시 파이프라인 설정 필요하다 . 기본적으로 파이프라인은 입력(input) , 필터(filter) , 출력(output)이라는 세가지 구성요소로 이루어지며 아래와 같이 -e옵션을 주어 콘솔에서도 만들 수 있다. 하지만 나중에 yml파일에서 파이프라인을 한번에 관리하는것이 일반적이다.
\bin\logstash.bat -e "input { stdin { } } output { stdout { } }" --log.level error
-> 위 코드 파이프라인을 실행시키면 입력받은 내용을 그대로 출력시켜 hello world를 입력하면 그대로 담아서 출력한다. 로그스태시는 위와같이 json형태로 출력을 하며
입력 플러그인
로그스태시는 다양한 형태의 데이터를 인식할 수 있고 이를 쉽게 처리하기 위해 다양한 입력 플러그인들이 존재하는데 대표적으로 자주 사용하는 플러그인은 아래와 같다.
file: 파일을 스트리밍하며 이벤트를 읽어 들임
syslog: 네트워크를 통해 전달되는 시스로그를 수신
kafka: 카프카 토픽에서 데이터를 읽어 들임
jdbc: JDBC 드라이버로 일정마다 쿼리를 실행해 결과를 읽어들임
input 플러그인
테스트를 위해 logstash-test.conf파일을 만들고 아래 내용을 넣는다. 앞으로 실험은 logstash-test.conf를 실행시켜 해볼것이다.
# logstash-test.conf
input {
file {
path => "C:/elasticsearch-7.10.1/logs/elasticsearch.log"
start_position => "beginning"
sincedb_path => "nul"
}
}
output {
stdout {}
}
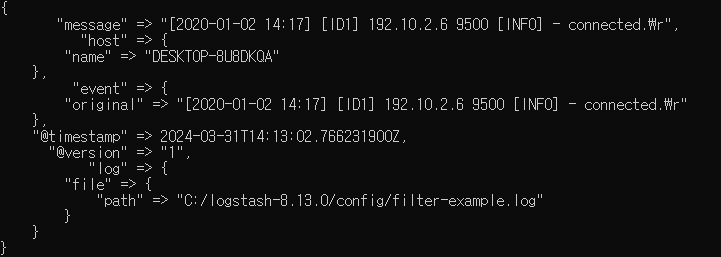
-> 만든 logstash-test.conf를 콘솔에서 실행시키면 위와같이 경로에 적힌 elasticsearch.log파일이 업데이트 될때마다출력 플러그인의 stdout에 의해 로그들이 모니터에 보인다.
필터 플러그인
입력 플러그인이 받은 데이터를 의미있는 데이터로 구조화하는 역할을 하며 자주 사용되는 필터 플러그인은 다음과 같다.
grok: 메세지를 구조화된 형태로 분석=정규표현식과 유사
dissect: 간단한 패턴을 사용해 메시지를 구조화된 형태로 분석
mutate: 필드명을 변경하거나 문자열 처리등 일반적인 가공함수 제공
date: 문자열을 지정한 패턴의 날짜형으로 분석
앞으로의 실험 예제를 위해 filter-example.log를 만들고 아래와 같은 임의의 로그를 넣는다
# filter-example.log
[2020-01-02 14:17] [ID1] 192.10.2.6 9500 [INFO] - connected.
[2020/01/02 14:19:25] [ID2] 218.25.32.70 1070 [warn] - busy server.
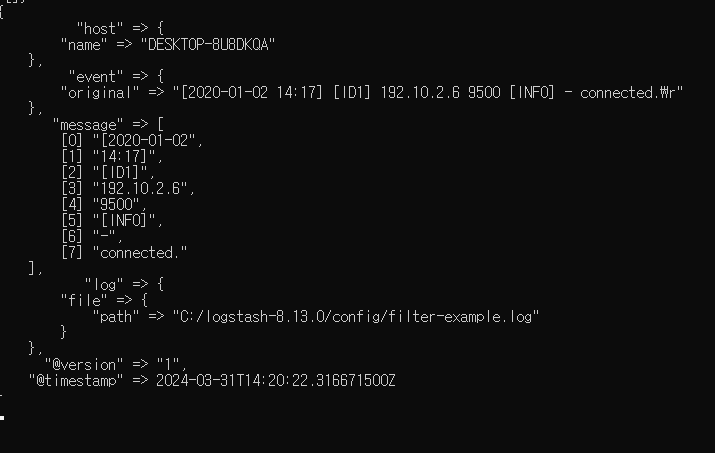
문자열 자르기(mutate - split)
아래와 같이 filter 부분에 mutate 플러그인중 split을 활용해 filter-example.log의 log를 공백 기준으로 자를 수 있다.
input {
file {
path => "C:/logstash-8.13.0/config/filter-example.log"
start_position => "beginning"
sincedb_path => "nul"
}
}
filter {
mutate {
split => { "message" => " " }
}
}
output {
stdout {}
}
<필터 다른 옵션>
split: 구분 문자를 기준으로 문자열을 배열로 나눈다.
rename: 필드 이름을 바꾼다.
replace: 해당 필드 값을 특정 값으로 바꾼다.
uppercase: 문자를 대문자로 바꾼다.
lowercase: 문자를 소문자로 바꾼다.
join: 배열을 구분 문자로 연결해 하나의 문자열로 합친다.
gsub: 정규식이 일치하는 항목을 다른 문자열로 대체한다.
merge: 특정 필드를 다른 필드에 포함시킨다.
coerce: null인 필드값에 기본값을 넣어준다.
strip: 필드 값의 좌우 공백을 제거한다.
우선 순위: coerce > rename > update > replace > convert > gsub > uppercase > capitzlize > lowercase > strip > remove > split > join > merge > copy
filter {
mutate {
split => { "message" => " " }
add_field => { "id" => "%{[message][2]}" }
remove_field => "message"
}
}-> 위처럼 id필드를 생성하고 분리되어 있는 message필드중에서 message[2]데이터를 넣고 message필드는 삭제할 수도 있다 .
< add_filed 외 다른 옵션>
add_field: 새로운 필드를 추가할 수 있다.
add_tag: 성공한 이벤트에 태그를 추가할 수 있다.
enable_metric: 메트릭 로깅을 활성화하거나 비활성화 할 수 있다. (필터 성능 분석할때 사용)
id: 플러그인의 아이디를 설정한다. 모니터링 시 아이디를 이용해 특정 플러그인을 쉽게 찾을 수 있다.
remove_field: 필드를 삭제할 수 있다.
remove_tag: 성공한 이벤트에 붙은 태그를 제거할 수 있다.
dissect
dissect플러그인을 사용하면 매핑을 정의 줘야한다. 변하지 않는 로그를 처리할떄는 dissect플러그인이 유용하다
filter {
dissect {
mapping => {"message" => "[%{timestamp}]%{?->}[%{?id}] %{?ip} %{?port} [%{?level}] - %{?msg}."}
}-> %{필드명->}은 공백이 몇칸이든 하나의 공백으로 인식, %{?필드명}은 필드명 결과에 포함x , %{+필드명}은 여러개의 필드명 하나의 필드로 합쳐서 표현
grok
정규 표현식을 이용해 문자열을 파싱할 수 있고 , 기본적으로 %{패턴명:변수명} 형태이다.
<다양한 패턴>
NUMBER : 십진수 인식
SPACE : 공백 인식
URL/IP : url,ip인식
SYSLOGBASE : 메시지외의 헤더 부분 인식)
TIMESTAMP_SIO8601 : TIMESTAMP인식
DATA : 직전 패턴부터 다음 패턴 사이 모두 인식
filter {
grok {
match => { "message" => "\[%{TIMESTAMP_ISO8601:timestamp}\] [ ]*\[%{DATA:id}\] %{IP:ip} %{NUMBER:port:int} \[%{LOGLEVEL:level}\] \- %{DATA:msg}\."}
}
}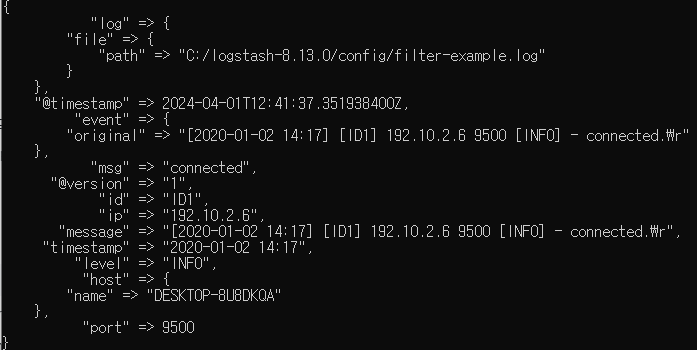
-> []*은 모든 공백 허용 , \를 붙이면 기호로 인정 , {형태:변수명}형태 즉 각 필드별로 어떤 패턴을 적용할지 설정해준다.
filter {
grok {
pattern_definitions => { "MY_TIMESTAMP" => "%{YEAR}[/-]%{MONTHNUM}[/-]%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}?" }
match => { "message" => "\[%{MY_TIMESTAMP:timestamp}\] * \[%{DATA:id}\] %{IP:ip} %{NUMBER:port:int} \[%{LOGLEVEL:level}\] \- %{DATA:msg}\."}
}
}-> 연/월/일 형태도 지원하도록 추가
대소문자 변경
filter {
dissect {
mapping => {"message" => "[%{?timestamp}]%{?->}[%{?id}] %{?ip} %{?port} [%{level}] - %{?msg}."}
}
mutate {
uppercase => ["level"]
}
}-> discent플러그인을 이용해 패턴에 맞춰 문자열을 자르고 level필드를 제외하고 나머지는 ?를 사용해 모두 무시한다. 결과적으로는 level필드만 대문자로 바뀐다.
날짜 / 시간 문자열 분석
input {
file {
path => "C:/logstash-7.10.1/config/filter-example.log"
start_position => "beginning"
sincedb_path => "nul"
}
}
filter {
dissect {
mapping => {"message" => "[%{timestamp}]%{?->}[%{?id}] %{?ip} %{?port} [%{?level}] - %{?msg}."}
}
mutate {
strip => "timestamp"
}
date {
match => [ "timestamp", "YYYY-MM-dd HH:mm", "yyyy/MM/dd HH:mm:ss" ]
target => "new_timestamp"
timezone => "UTC"
}
}
output {
stdout { }
}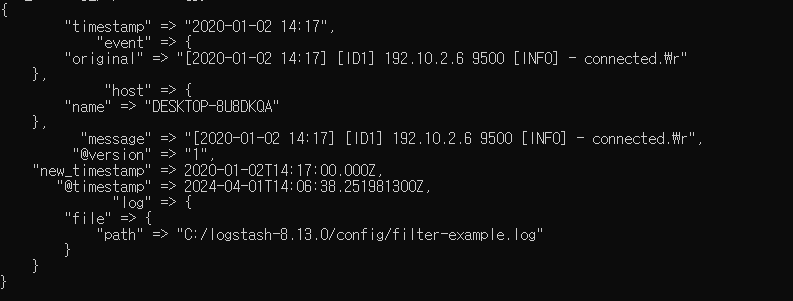
-> dissect로 문자열을 자르고 , mutate strip으로 양쪽공백을 제거 한다
-> date플러그인을 통해 YYYY-MM-dd HH:mm or yyyy/MM/dd HH:mm:ss형식이면 매칭되는데 new_timestamp라는 필드 만들어서 거기에 매칭시킴
조건문
filter {
dissect {
mapping => {"message" => "[%{timestamp}]%{?->}[%{id}] %{ip} %{port} [%{level}] - %{msg}."}
}
if [level] == "INFO" {
drop { }
}
else if [level] == "warn" {
mutate {
remove_field => [ "ip", "port", "timestamp", "level" ]
}
}
}-> dissect플러그인을 통해 timestamp , id , ip , port , level , msg필드를 생성
-> if 조건문을 통해 필드명이 특정 조건과 일치하는지를 확인하고 if조건문에 걸려 level이 INFO인 첫번째 로그는 출력되지 않음
-> level이 warn인 두번째 로그는 ip,port,timestamp,level필드가 삭제되어서 나온다
output 플러그인
입력과 필터를 거쳐 가공된 데이터를 지정한 대상으로 내보내는 단계이다.
<자주 사용하는 플러그인>
elasticsearch : bulk api를 사용해 엘라스틱서치에 인덱싱 수행
file : 지정한 파일의 새로운 줄에 데이터 기록
kafka : 카프카 토픽에 데이터 기록
input {
file {
path => "C:/logstash-7.10.1/config/filter-example.log"
start_position => "beginning"
sincedb_path => "nul"
}
}
output {
file {
path => "C:/logstash-7.10.1/config/output.json"
}
elasticsearch {
index => "output"
}
}-> 엘라스틱서치에 파일 형태로 전송하는데 인덱스명을 output으로 지정
(여기에서 host나 document_id 지정등 다양한 옵션 가능)

-> curl과 GET을 활용해 엘라스틱 서치에 조회하면 위와같이 전송이 잘 되었는지 확인 할수있다.
필자는 여기서 데이터 전송 다양한 오류를 겪었는데 결국 버전 문제인것을 깨달았다. 엘라스틱서치 , 키바나 , 로그스태시 버전이 맞아야한다 ..
코덱
입력과 출력 단계에서 데이터의 인코딩/디코딩을 담당(예를들면 json형태로 바꾸기 등) 하며 특히 여러줄로 되어있는 로그를 하나로 통합해줄때 매우 꼭 필요하다.
<자주사용하는 플러그인>
json : json변환
plain : 단순문자열로 읽어드림,출력시는 포맷지정가능
rubydebug : 파이프라인 설정오류 디버깅시 사용
input {
file {
path => "C:/logstash-7.10.1/config/filter-example.log"
start_position => "beginning"
sincedb_path => "nul"
}
}
output {
stdout{
# codec => "line"
# codec => "json"
# codec => "rubydebug"
}
}-> 위와 같이 out위치에 codec을 넣거나 input위치에 넣어 출력 형식을 지정할 수 있음
다중 파이프라인
예를들어 두개의 서버에서 하나는 beats로 , 하나는 kafka에서 온 데이터를 logstash로 가공한다고 할때 조건문으로 하면 복잡해진다. 따라서 이때 사용할 수 있는 방법이 다중 파이프라인을 구성하는것이다. 일반적으로 pipelines.yml 파일을 수정해서 파이프라인을 만든다.
파이프라인 설정
- pipeline.id : 고유한 아이디
- path.config : 파이프라인 설정 파일의 위치
- pipeline.workers : 워커수로 호스트의 cpu코어수와 동일하게 설정
- pipeline.batchsize : 워커당 최대 몇개 이벤트 동시에 처리할지
- queue.type : 파이프라인에서 사용할 큐의 종류를 정함
먼저 pipelines.yml파일에서 아래와 같이 파이프 라인을 참조를 만들고

각각 적용하고 싶은 파이프 라인 파일을 만들어 원하는 파이프라인 코드를 넣는다

이후 .\bin\logstash.bat을 실행하면 원하는 파이프라인이 동시에 실행된다.
모니터링
<API를 활용하는 방법>
curl -XGET 'localhost:9600/_node?pretty' : 노드의 기본 정보 제공(OS,JVM등)
curl -XGET 'localhost:9600/_node/plugins?pretty' : 사용하는 플러그인 정보 제공
curl -XGET 'localhost:9600/_node/stats?pretty' : 파이프라인,이벤트,프로세스등 정보 제공
curl -XGET 'localhost:9600/_node/hot_threads?pretty' : CPU 사용량이 많은 스레드를 높은 순으로 보여줌
<노드 통계 API>
jvm : 스레드,메모리 사용량 , 자바가상머신 사용통계등
process : 열어둔 파일 수와 메모리 , CPU사용량등프로세스의 사용통계
events : 로그스태시에 인입된,필터링된,출련된 총 이벤트의 수와 이를 처리하기 위해 소요된 시간등의 통계
pipelines : 파이프라인과 그 하위에 구성된 플러그인별 이벤트 통계
reloads : 로그스태시에서 자동/수동으로 설정을 리로드했을떄 성공,실패수통계
os : 도커와 같은 컨테이너에서 실행될때 cgroup에 대한 통계
모니터링 기능 활성화
logstash.yml파일에서 모니터링 기능을 다음과 같이 수정한다

이후 키바나에 접속해서 Turn on monitoring 버튼을 클릭하면 아래와 같이 모니터링 대시보드를 볼 수 있다.
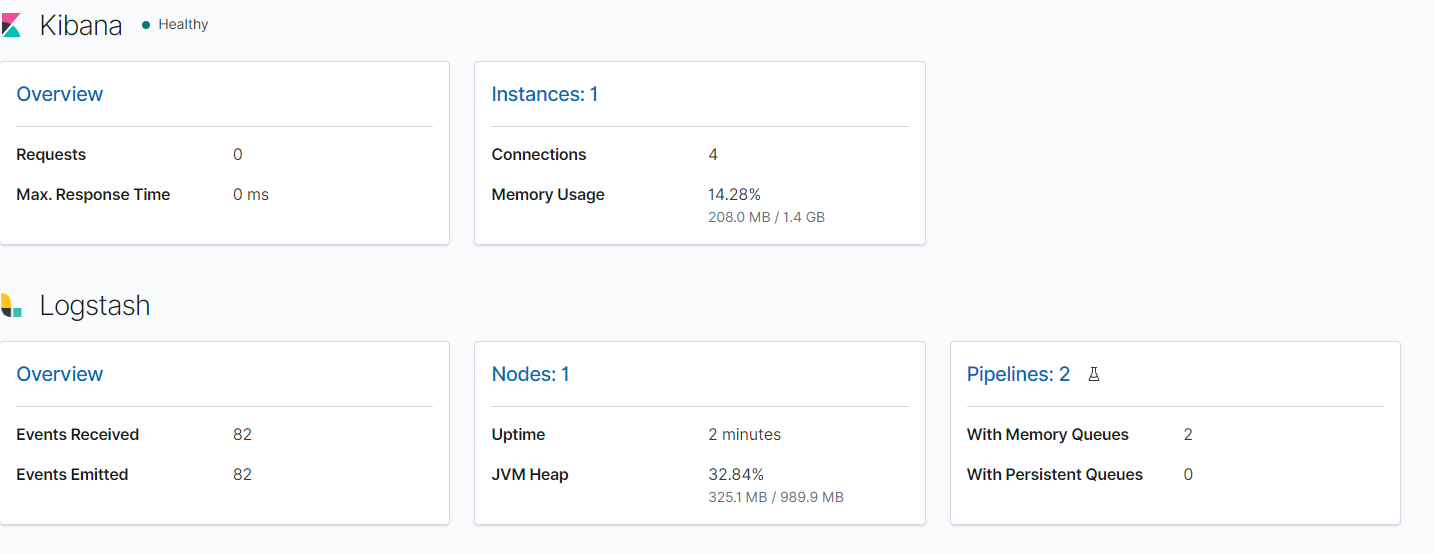
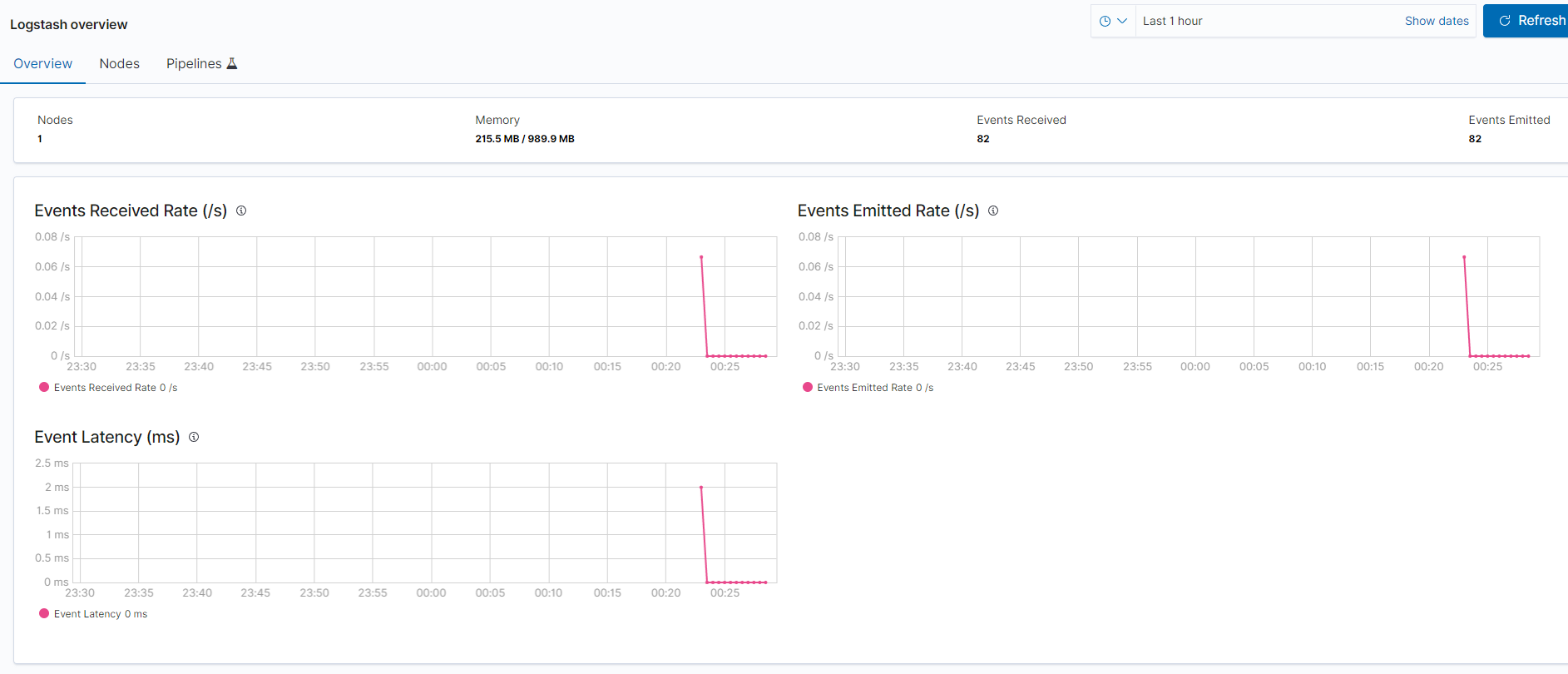
마무리
이번 포스팅에서는 logstash에 전반적인 사용법을 적어보았다. 아무래도 처음 사용하는거라 모든게 익숙하지 않았지만 그래도 친절한 책 설명 덕분에 무리없이 따라갈 수 있었다. 기본을 다 배웠으니 나중에 빠르게 내 프로젝트에 적용시키면서 익숙해지고싶다.
