시작
엘라스틱서치에서 집계는 데이터를 그룹핑하고 통곗값을 얻는 기능으로 SQL에 group by 기능이랑 유사하다. 키바나의 주 기능인 데이터 시각화 대시보드는 대부분 집계 기능을 기반으로 동작하며 , 따라서 집계를 이해할수록 키바나라는 툴을 더 잘 사용할 수 있다.
집계
- 집계는 크게
메트릭 집계와버킷집계로 나뉘고 엘라스틱서치에서 자주 사용되는 기능 메트릭집계는 수치 작업이나 통계 작업 수행 ,버킷집계는 특정 기준으로 도큐먼트를 그룹핑
집계의 요청
메트릭집계
필드의 최소/최대/합계/평균/중앙값같은 통계결과 보여줌
# 포맷 #
GET <인덱스>/_search
{
"aggs":{
"my_aggs" : {
"agg_type" : {
}
}
}
}->
my_aggs는 지정한 집계 이름 ,agg_type은avg,min등 집계 옵션
->agg_type: avg/min/max/sum/percentiles/stats/cardinality(유니크한값)/geo-centroid
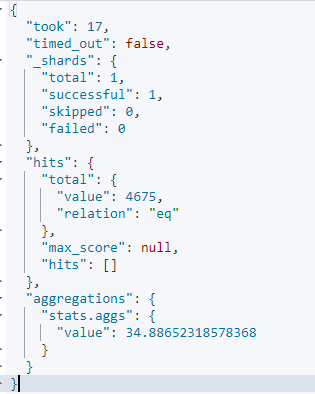
GET kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"stats.aggs":{
"avg":{
"field": "products.base_price"
}
}
}
}
GET kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"stats.aggs":{
"percentiles": {
"field": "products.base_price",
"percents": [
1,
25,
50
]
}
}
}
}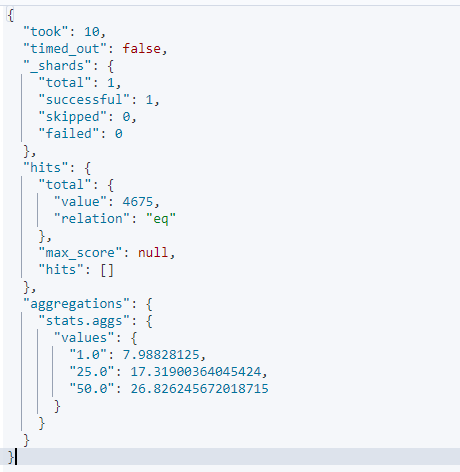
해석 : 백분위 집계로 25% , 50%나
GET kibana_sample_data_ecommerce/_search
{
"size":0,
"aggs":{
"cardi_aggs":{
"terms": {
"field": "day_of_week"
}
}
}
}해석 : day_of_week기준으로 용어 집계
GET kibana_sample_data_ecommerce/_search
{
"size":0,
"query": {
"term": {
"day_of_week":"Monday"
}
},
"aggs": {
"query_aggs": {
"sum": {
"field": "products.base_price"
}
}
}
}해석 : 쿼리를 통해 도큐먼트 범위를 제한하고 용어 수준 쿼리를 이용해 집계
버킷 집계
특정 기준에 맞춰서 도큐먼트를 그룹핑하는 역할
종류
histogram: 숫자 타입 필드 일정 간격 분류
data_histogram : 날짜/시간 타입 필드를 일정 날짜/시간 간격으로 분류
range , date_range , terms , signuficant_terms , filters
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"histogram_aggs": {
"histogram": {
"field": "products.base_price",
"interval": 100
}
}
}
}해석 : products.base_price필드값을 100간격으로 구분후집계
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"range_aggs": {
"range": {
"field": "products.base_price",
"ranges": [
{ "from": 50, "to": 100 },
{ "from": 100, "to": 200 }
]
}
}
}
}해석 : 직접 사용자가 범위 지정 가능
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"term_aggs": {
"terms": {
"field": "day_of_week",
"size": 6
}
}
}
}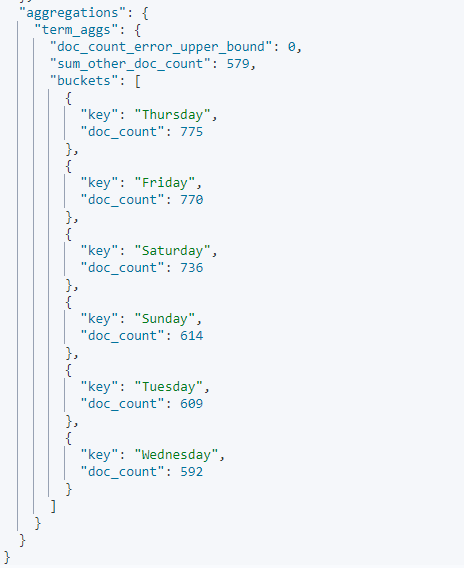
- 도큐먼트 카운트를 하는데 size에 따라 그만큼만 나오게 된다. 7일이 다 나와야하지만 size가6이므로 doc_count가 높은 상위 6개만 나옴
- 용어 집계의 경우 오류가 발생 가능
(분산되어 있는 개별 노드 먼저 집계를 하고 그결과를 다시 취합해 집계를 하기 떄문)
<용어 집계의 정확성 높이기>
- size다음 "show_term_doc_count_error" : true를 넣으면 버킷마다 에러 확인 가능
- 에러가 발생시 size다음 "shard_size"늘려 해결하는 방법이 있음
<집계 조합>
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"term_aggs": {
"terms": {
"field": "day_of_week",
"size": 6
},
"aggs" : {
"avg_aggs" : {
"avg" : {
"field" : "products.base_price"
}
},
"sum_aggs" :{
"sum" : {
"field" : "products.base_price"
}
}
}
}
}
}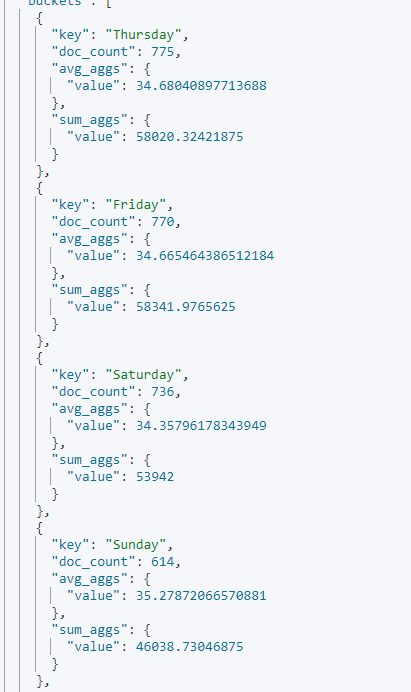
해석 : day_of_week로 먼저 집계를 하고 products.base_price 필드의 평균값 , 총합을 구한다.
파이프라인 집계
- 부모집계와 형제집계라는 두가지 유형이 있음
- 부모집계는 집계 내부에서 작업해야 하는 누적합,분산 계산 같은 작업에 쓰인다.
- 형제집계는 기존 집계 외부에서 전체 버킷의 총합/평균/최소/최대 같은 작업에 쓰인다.
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"histogram_aggs": {
"histogram": {
"field": "products.base_price",
"interval": 100
},
"aggs": {
"sum_aggs": {
"sum": {
"field": "taxful_total_price"
}
},
"cum_sum": {
"cumulative_sum": {
"buckets_path": "sum_aggs"
}
}
}
}
}
}
- 누적합
cumulative_sum을 구하는 부모집계이다- 합계집계
sum_aggs를 입력받아 각 버킷의 누적합을 계산)cum_sum이 개별 버킷 내부에서 보이고 실제로 점점 누적된다sum_aggs가 나오는데 이 값들이 계속cum_sum에 더해지는 현황을 볼 수 있음
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"term_aggs": {
"terms": {
"field": "day_of_week",
"size": 2
},
"aggs": {
"sum_aggs": {
"sum": {
"field": "products.base_price"
}
}
}
},
"sum_total_price": {
"sum_bucket": {
"buckets_path": "term_aggs>sum_aggs"
}
}
}
}

해석 : 형제집계 케이스로 누적집계 값들의 총합이 아래에 나온다
마무리
이번 포스팅에서는 엘라스틱서치 집계기능에 대해 적어보았다. 앞으로 ELK방식으로 원천 로그를 분석하려면필요한 형태로 데이터 가공은 필수이므로 , 집계기능을 자주 사용할것같다. 이번 포스팅을 마지막으로 DSL명령어에 대해서는 끝이났다. 다음 포스팅부터는 로그스태시를 설치하고 다루는 방법을 공부하고 본격적으로 ELK방식에 대해 포스팅해보겠다.
