키바나 ?
엘라스틱 스택의 관리 , 모니터링 , 솔루션을 총괄하는 메인 UI로 주요기능은 크게 3가지이다(시각화 툴 , 엘라스틱 관리 , 엘라스틱 중앙 허브)
키바나 시각화 기능
디스커버 : 데이터를 도큐먼트 단위로 탐색해 구조와 관계 등 확인
시각화 : 다양한 그래프 타입으로 데이터 시각화
대시보드 : 그래프 , 지도등을 한곳에서 확인
캔버스 : 그래프와 이미지등을 슬라이드처럼 구상
맵스 : 위치 기반 데이터를 지도 위에 표현
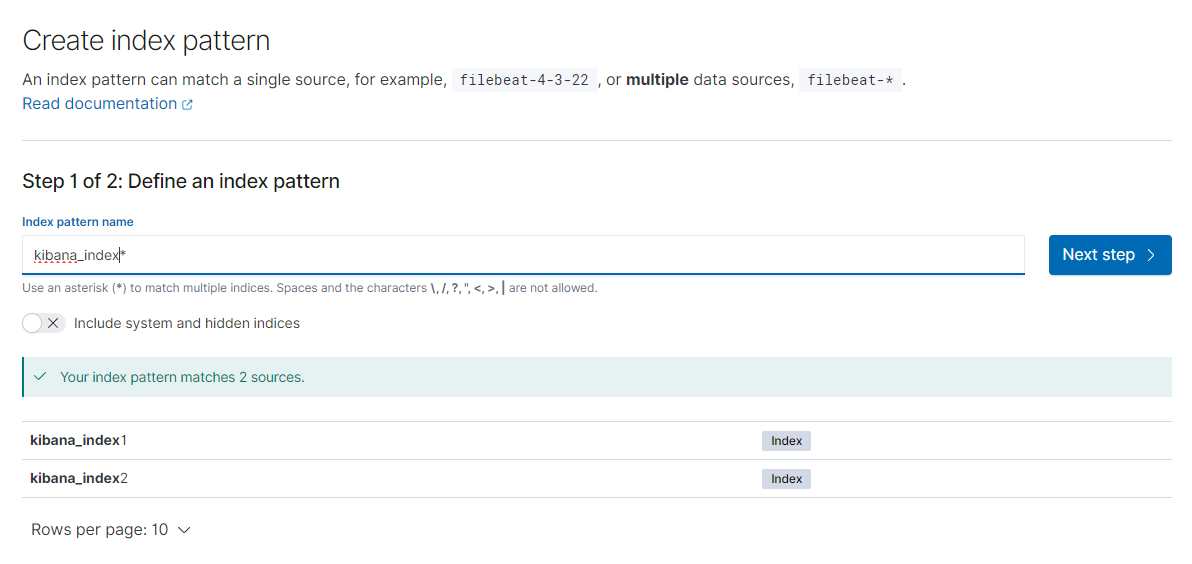
인덱스 패턴
데이터 소스를 엘라스틱서치 인덱스에서 가져오는것 , 인덱스 매핑 정보등을 키바나에 사용하기 적합하게 미리 캐싱해둔 것이다.
만드는 방법은 Management -> stack Management -> Kibana -> Index Patterns -> Create index pattern에서 만들수 있다
디스커버
키비나의 시각화 메뉴로 데이터를 선택하고 쿼리바 , 필터바 , 타임피커등으로 구성되어있다.
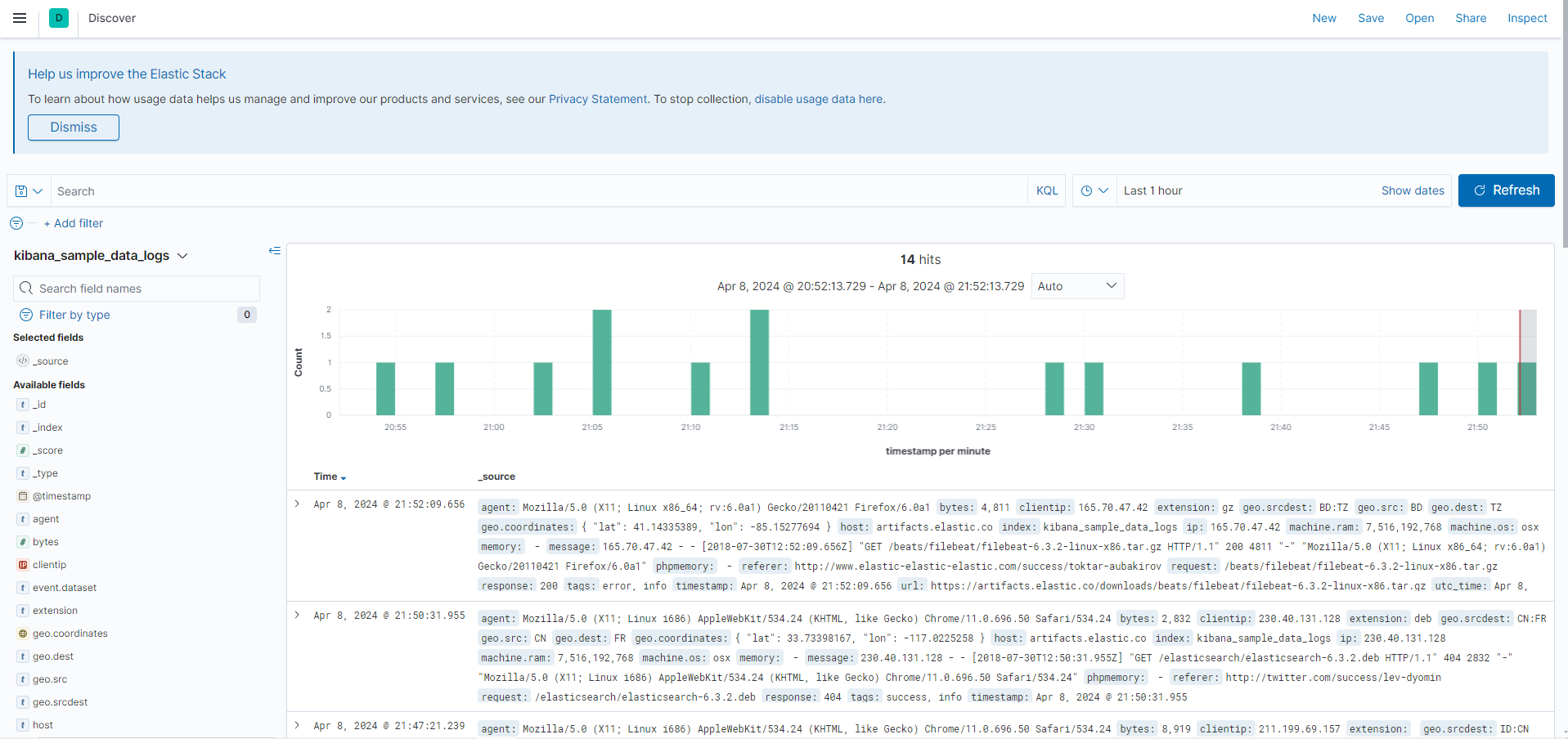
아래처럼 쿼리바에서는 KQL언어를 사용하는데 자동완성 기능을 이용해 손쉽게 쿼리 구현이 가능하다.

타임피커를 통해 기간 , 시간등을 정확하게 지정도 가능하다
다양한 시각화
막대 시각화
Visyalize에 들어가면 시각화를 할 수 있다. 종류와 데이터를 선택하는데 기본적으로 막대 그래프 부터 실습해보겠다. 먼저 Metircs , Buckets을 설정해야하는데 Metrics는 평균값/최솟값/최댓값 같은 통계를 보여주고 그래프상에서 Y축에 속한다 . Buckets은 특정 기준으로 데이터를 나누는 역할을 하며 그래프상에서 X축에 속한다.
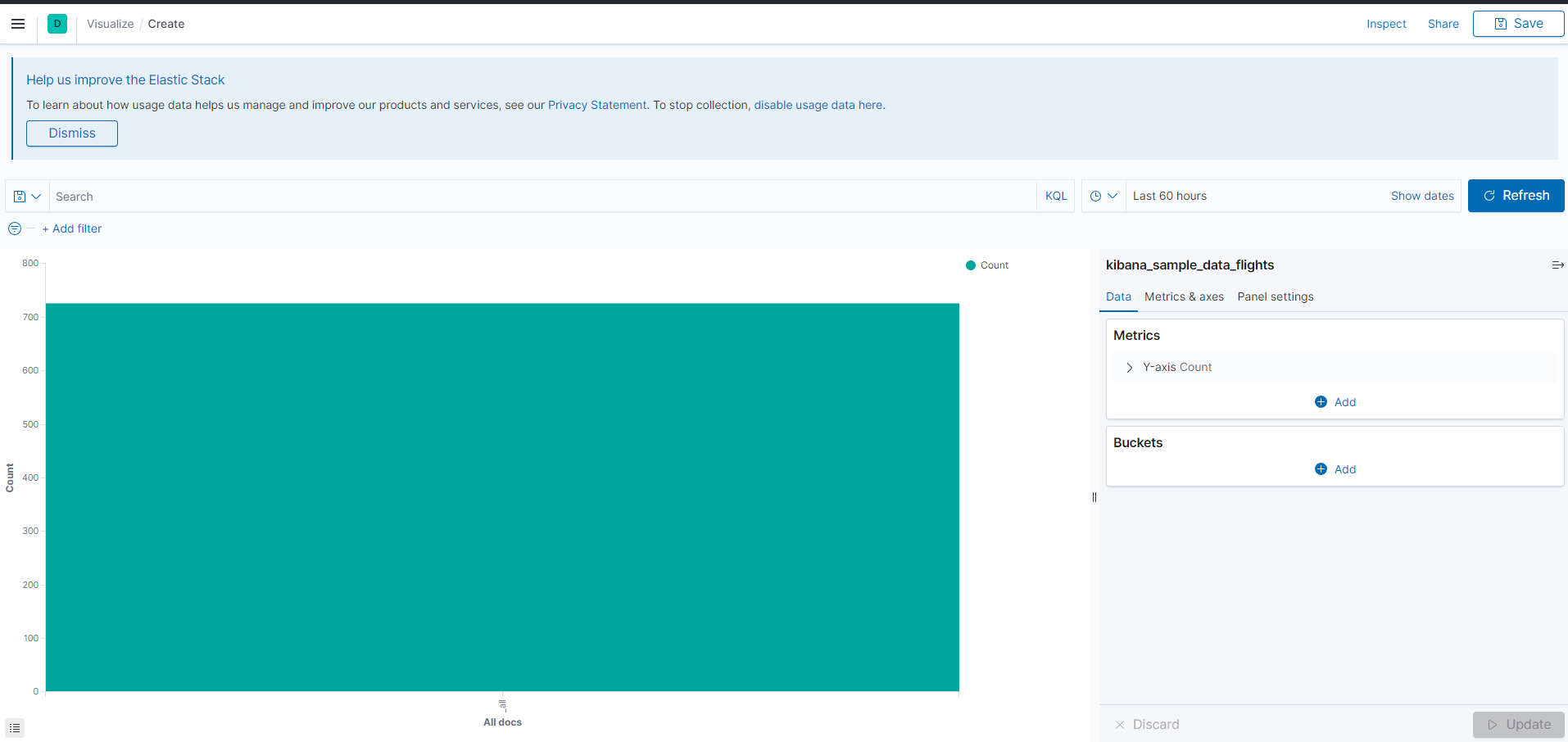
Bukets설정(X축 설정)
아래와 같이 Bucekts에 X_axis을 선택하고 어떤 기준으로 나눠야할지를 선택해야한다. 버킷을 나눌때 집계를 사용하는데 집계 종류를 복습하자면 다음과 같다.
Data Histogram : 날짜/시간 데이터 타입 필드를 일정한 주기를 기준으로 버킷 구분
Data Range : 날짜/시간 데이터 타입 필드를 사용자가 임의 범위를 지정해 버킷 구분
Filters : 필터 적용 가능
Histogram : 일정한 주기를 기준으로 버킷 구분
Ipv4 Range : ip타입을 가진 필드만 사용 가능
Range : 사용자가 임의의 범위를 지정해 버킷을 구분
Significant Terms : 필드의 유니크한 값중 통계적으로 의미 있는 용어를 기준으로 구분
Terms : 필드의 유니크한 값을 기준으로 구분
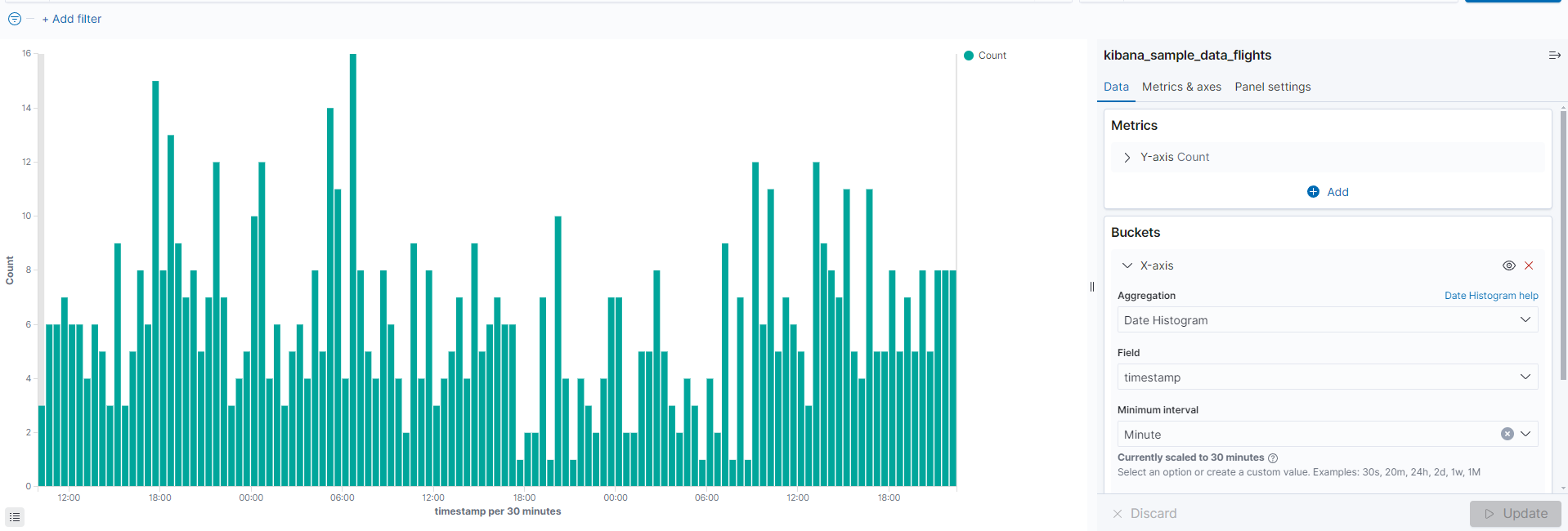
이중 Data Histogram을 적용하면 아래와 같이 데이터가 분할되는것을 볼 수 있다.
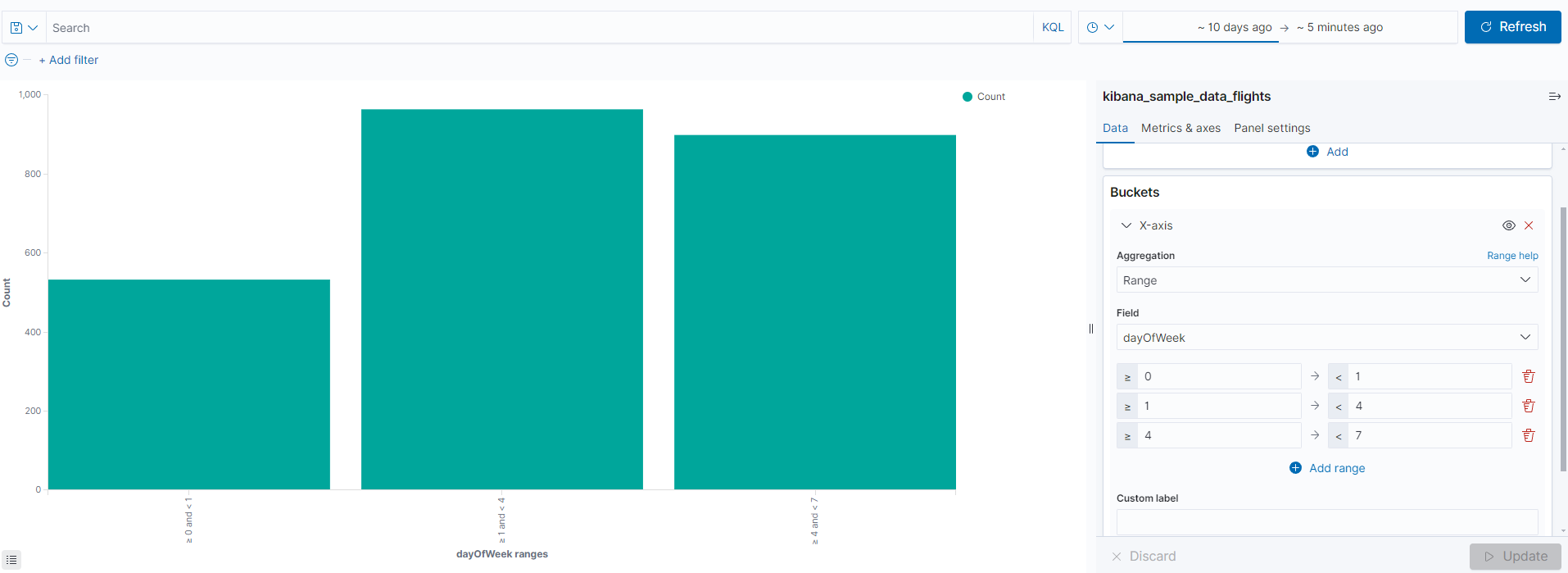
아래처럼 Range를 활용해 dayofWeek필드 범위에 따라 구분도 가능하다
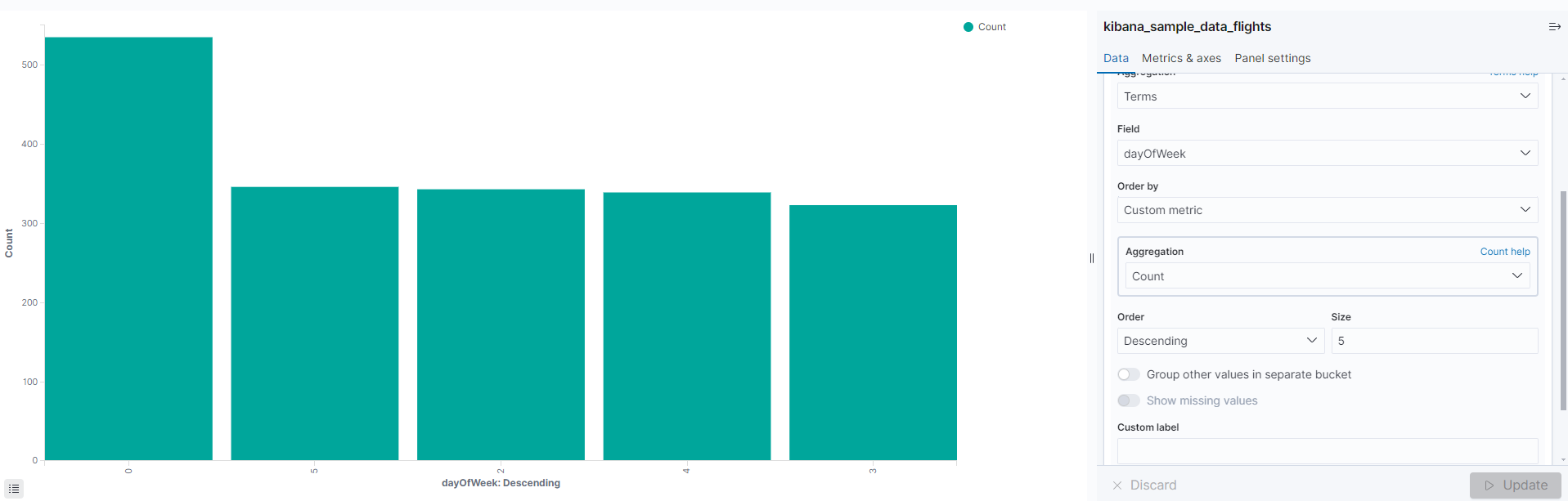
Terms를 선택하고 정렬기준과 size를 설정해 그릴수도 있다
Metrics
y축을 의미하며 아래와 같이 특정 필드의 평규값으로 설정 가능하다.
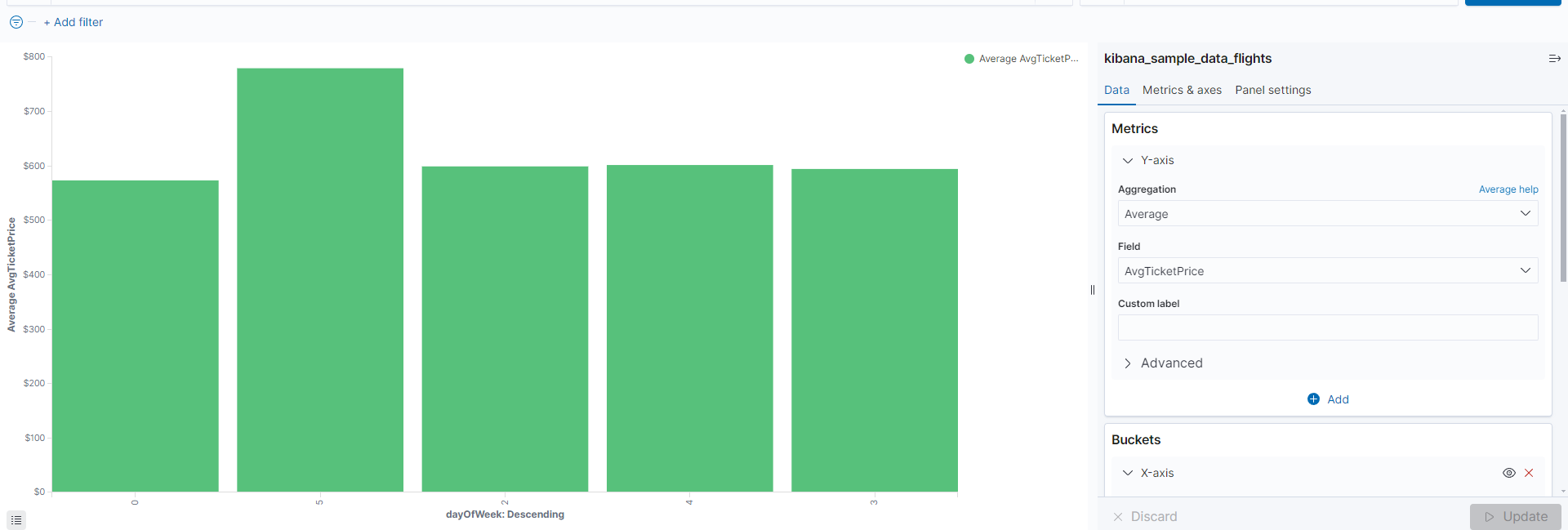
아래처럼 +Add 버튼으로 Y축을 추가해 Derivative(미분) 집계를 추가할 수 있다
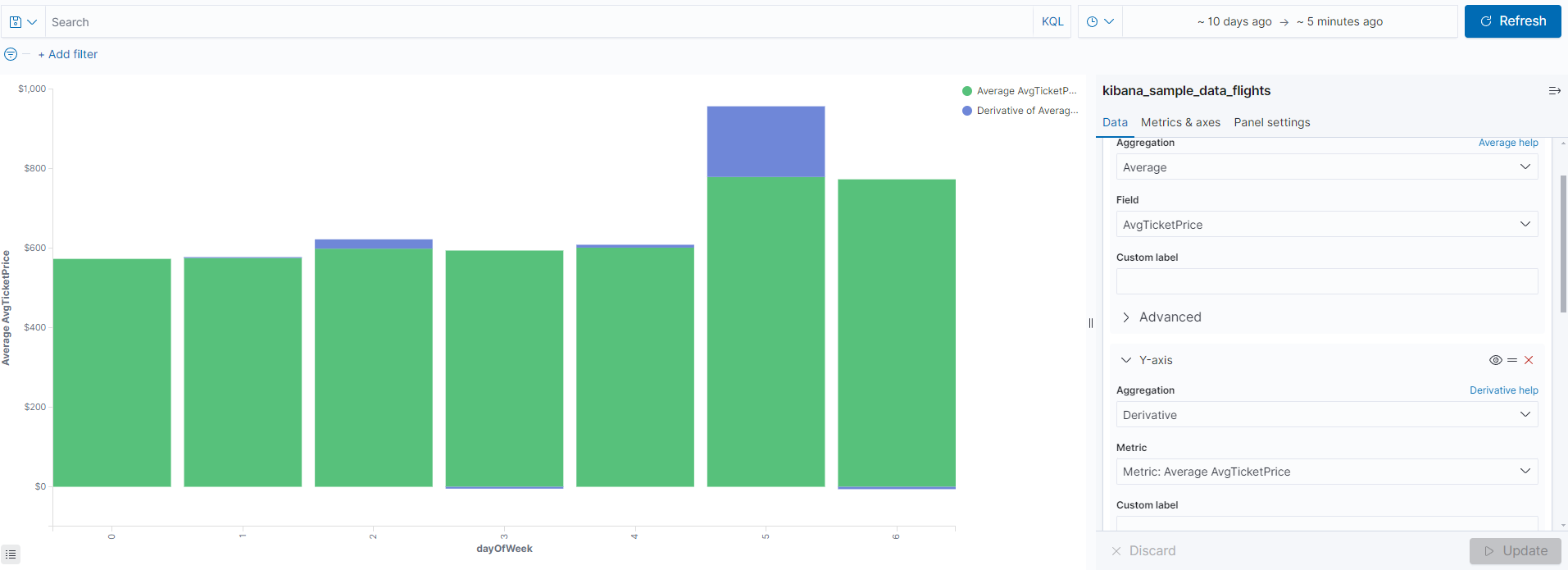
히트맵 시각화
히트맵은 3차원 처리를 위해 X,Y축에 버킷 집계를 하고 Z축에 메트릭 집계를 한다. 아래와 같이 x축은 dayofweek의 Histogram , y축은 도시명(Terms->DestCityName)으로 지정한다.
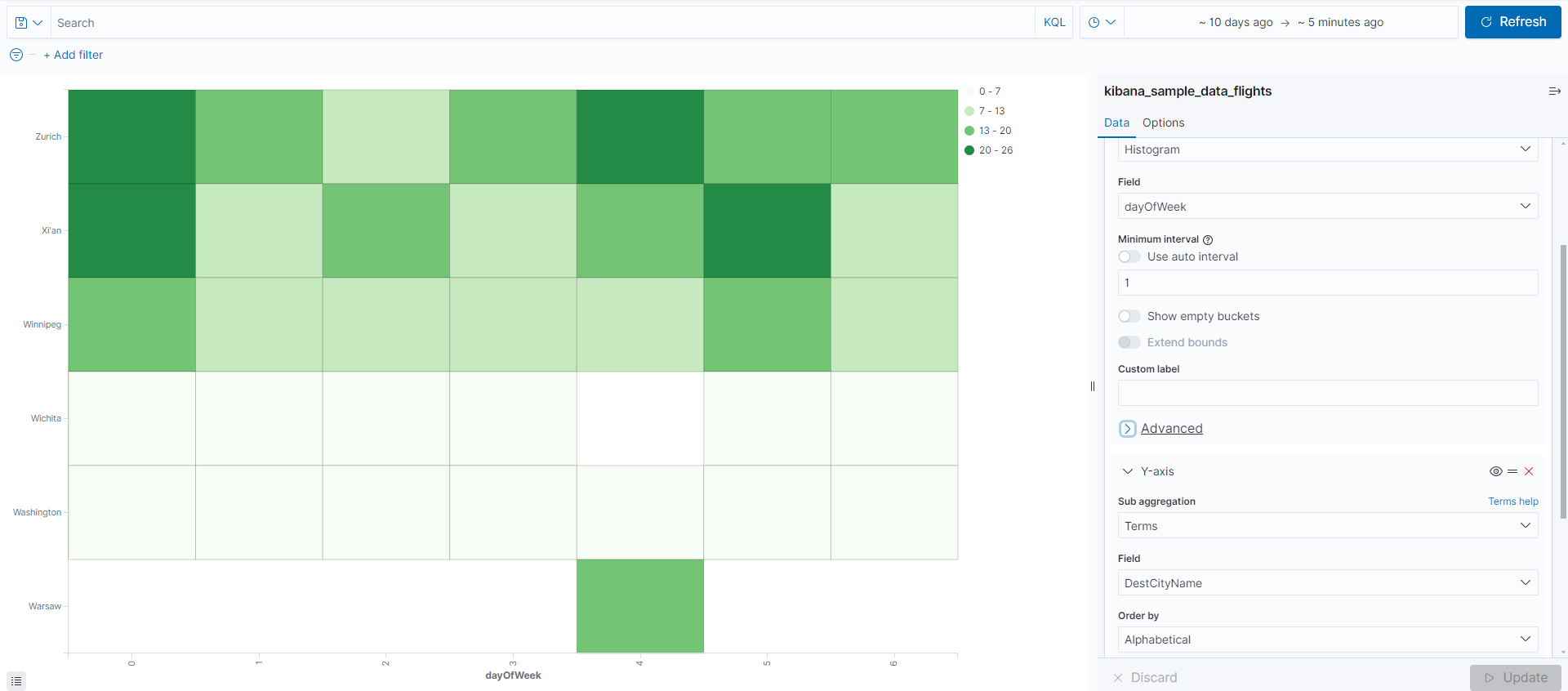
TSVB(Time Series Visual Builder)
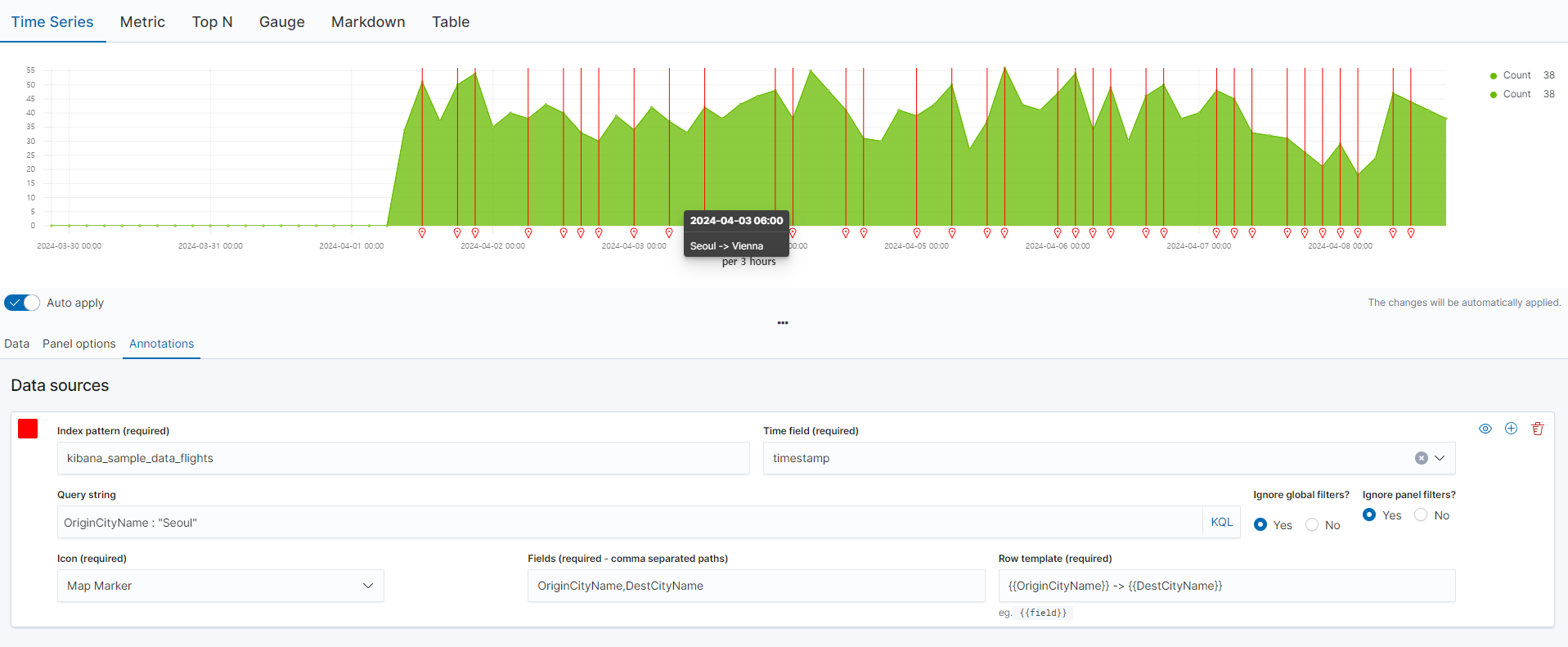
시계열 데이터를 처리하기 위한 메뉴로 로그 모니터링이나 , 시간 범위내 특정 동작을 시각화 하는데 유용하다. Time Series은 시계열 데이터를 히스토그램 형태로 확인하고 , 텍스트 형태로 표현하는 Metrics , 수평 바 형태로 표현하는 Top N , 게이지 형태로 표현하는 Gauge , 마크다운 형태로 표현하는 Markdown , 테이블 형태로 표현하는 Table이 있다. 간단하게 데이터를 추가하면 아래와 같이 나온다
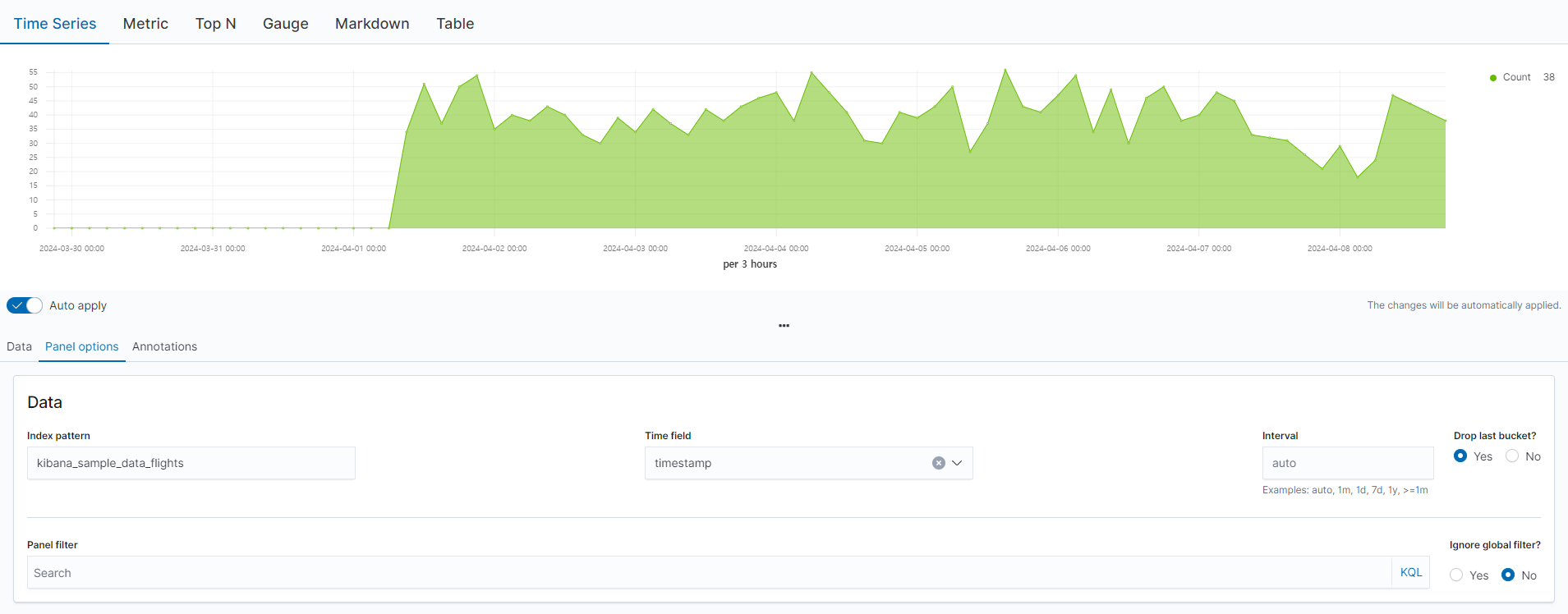
아래와 같이 Annotations에서 데이터를 입력하고 query string으로 서울의 경우만 필터링 한 후 , 마우스를 올렸을때 출발지->도착지로 나오도록 설정했다.
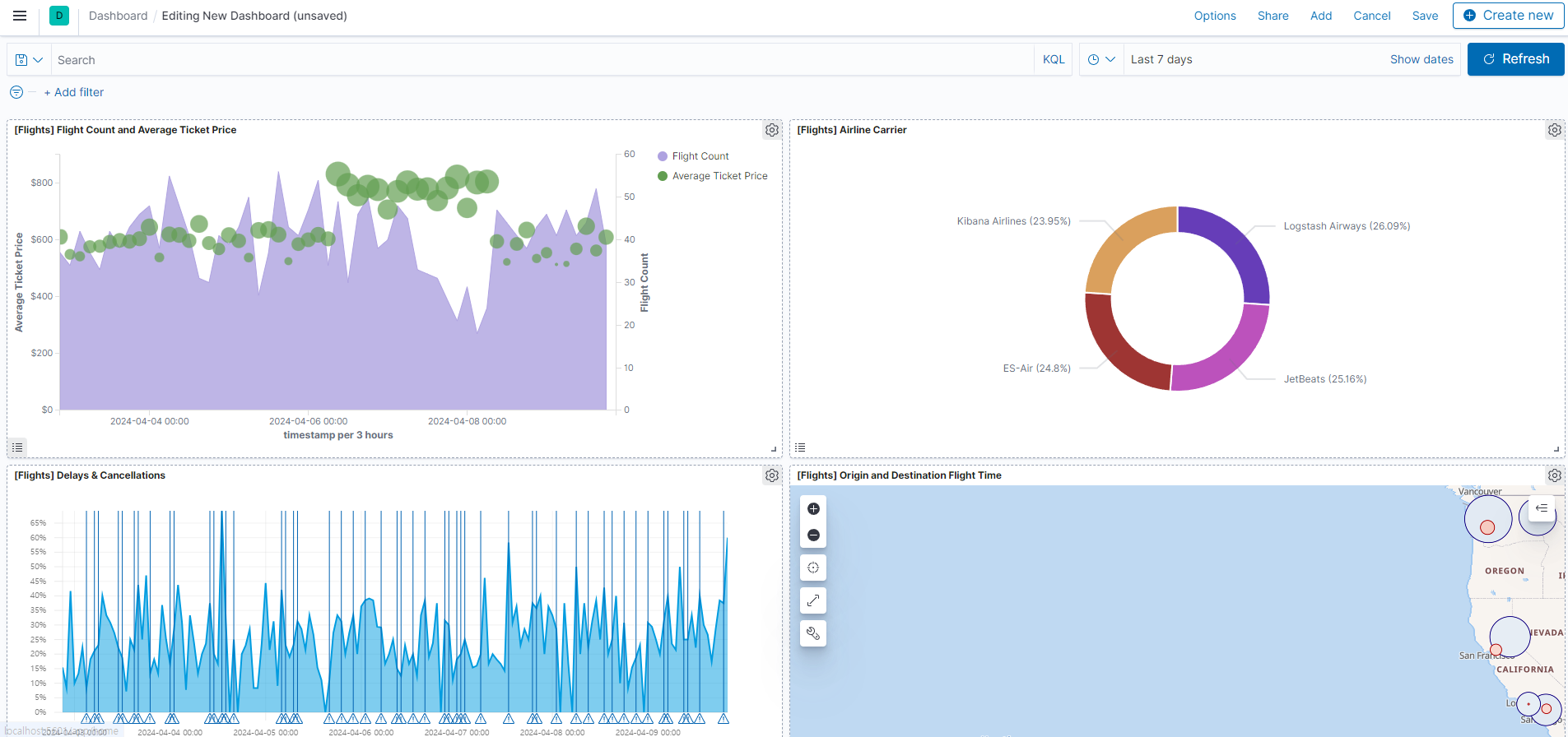
대시보드
대시보드에 들어가서 오른쪽위 add 버튼을 클릭하고 원하는 샘플 대시보드를 추가하면 아래처럼 대시보드를 구성할 수 있다. 패널의 크기 , 범례 , 패널별 시간 범위를 적용할 수 있다.
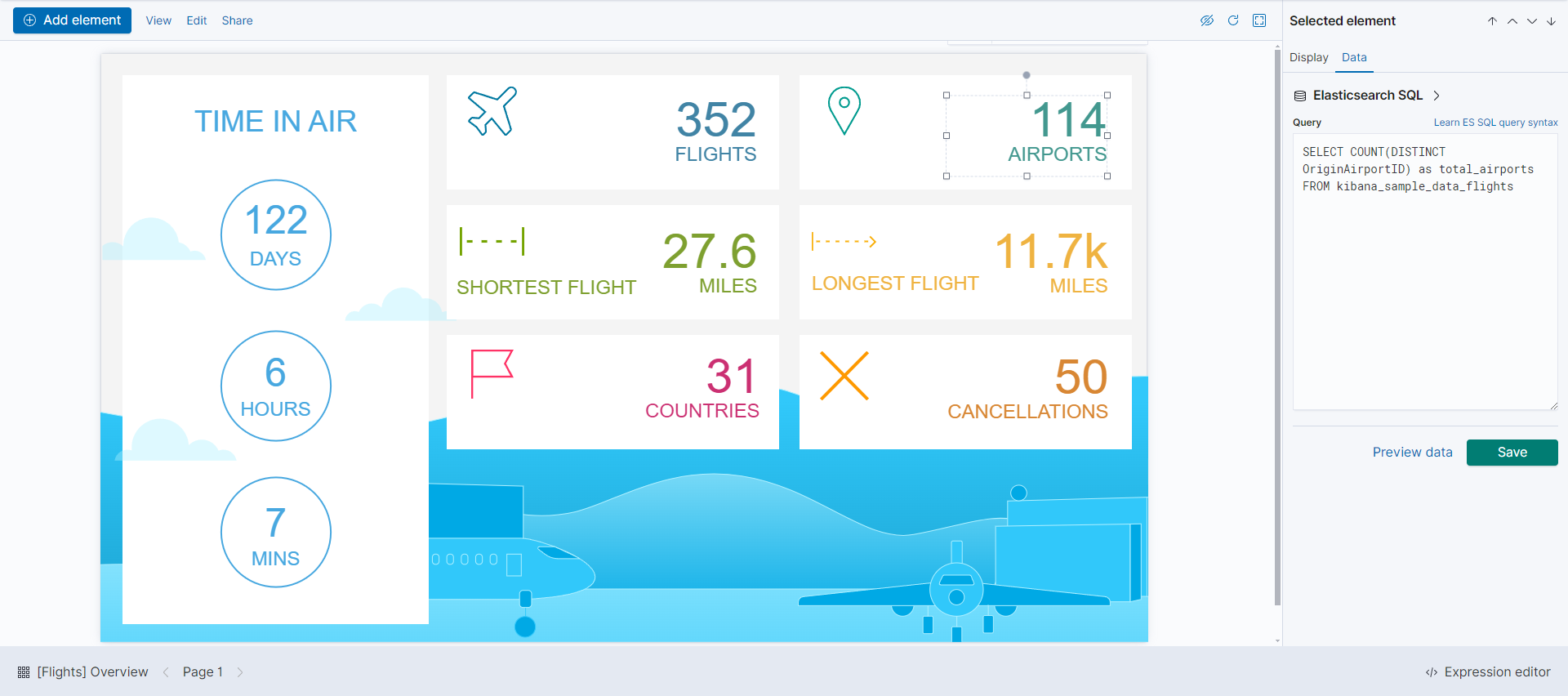
캔버스
캔버스는 인포그래픽 형태로 데이터를 프레젠테이션할 수 있게 해주는 툴이다. 정형화된 대시보드 형식에서 벗어나 나만의 디자인 스타일에 맞춰 동적으로 데이터를 표현할 수 있고 오른쪽 데이터를 선택하는 창에서 소스 종류는 4가지가 있다.
< 데이터 소스 종류>
Timelion : Timelion 문법을 이용해 시계열 데이터를 시각화
Demo Data : 데모로 제공하는 데이터 사용
Elasticsearch SQL : 엘라스틱서치 쿼리 구문을 사용
Elasticsearch raw documents : 엘라스틱서치 데이터를 집계 과정없이 직접 가져옴
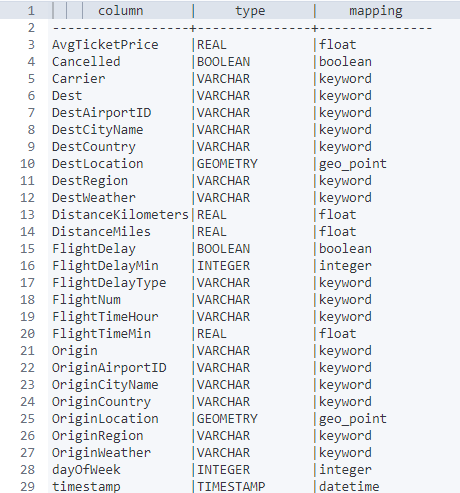
엘라스틱서치 SQL
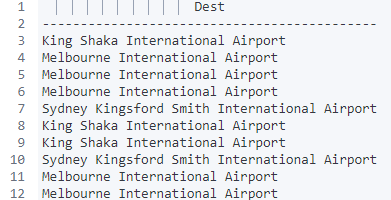
엘라스틱서치는 SQL 문 지원을 위해 _sql이라는 API를 제공한다. 키바나 Dev Tools에 들어가서 아래와 같이 입력하면 엘라스틱서치로 SQL쿼리를 보낼 수 있다.
POST _sql?format=txt
{
"query": "DESCRIBE kibana_sample_data_flights"
}
POST _sql?format=txt
{
"query":
"""
SELECT Dest FROM kibana_sample_data_flights
WHERE OriginCountry='US'
ORDER BY DistanceMiles
DESC LIMIT 10
"""
}
마무리
이번 포스팅에서는 키바나에서 시각화 하는 전반적인 방법들에 대해 다뤄보았다. 사실 이후에 맵을 그려주는 맵스 기능이 추가적으로 있지만 당장은 크게 사용할것 같지는 않아서 포스팅을 하지 않았다. 이번 포스팅을 마지막으로 이제 어느정도 ELK에 기초개념을 알았다. 앞으로는 본격적으로 ELK를 활용해 데이터를 분석하는 방법에 대해 공부하고 포스팅해 보려고 한다.
