https://velog.io/@rkdghwjd1999/ELK공부-엘라스틱-스택-개발부터-운영까지-1
https://velog.io/@rkdghwjd1999/ELK공부-엘라스틱-스택-개발부터-운영까지-2
https://velog.io/@rkdghwjd1999/ELK공부-엘라스틱-스택-개발부터-운영까지-3
https://velog.io/@rkdghwjd1999/ELK공부-엘라스틱-스택-개발부터-운영까지-4
https://velog.io/@rkdghwjd1999/ELK공부-엘라스틱-스택-개발부터-운영까지-5
https://velog.io/@rkdghwjd1999/ELK공부-엘라스틱-스택-개발부터-운영까지6
https://velog.io/@rkdghwjd1999/ELK공부-엘라스틱-스택-개발부터-운영까지7
시작
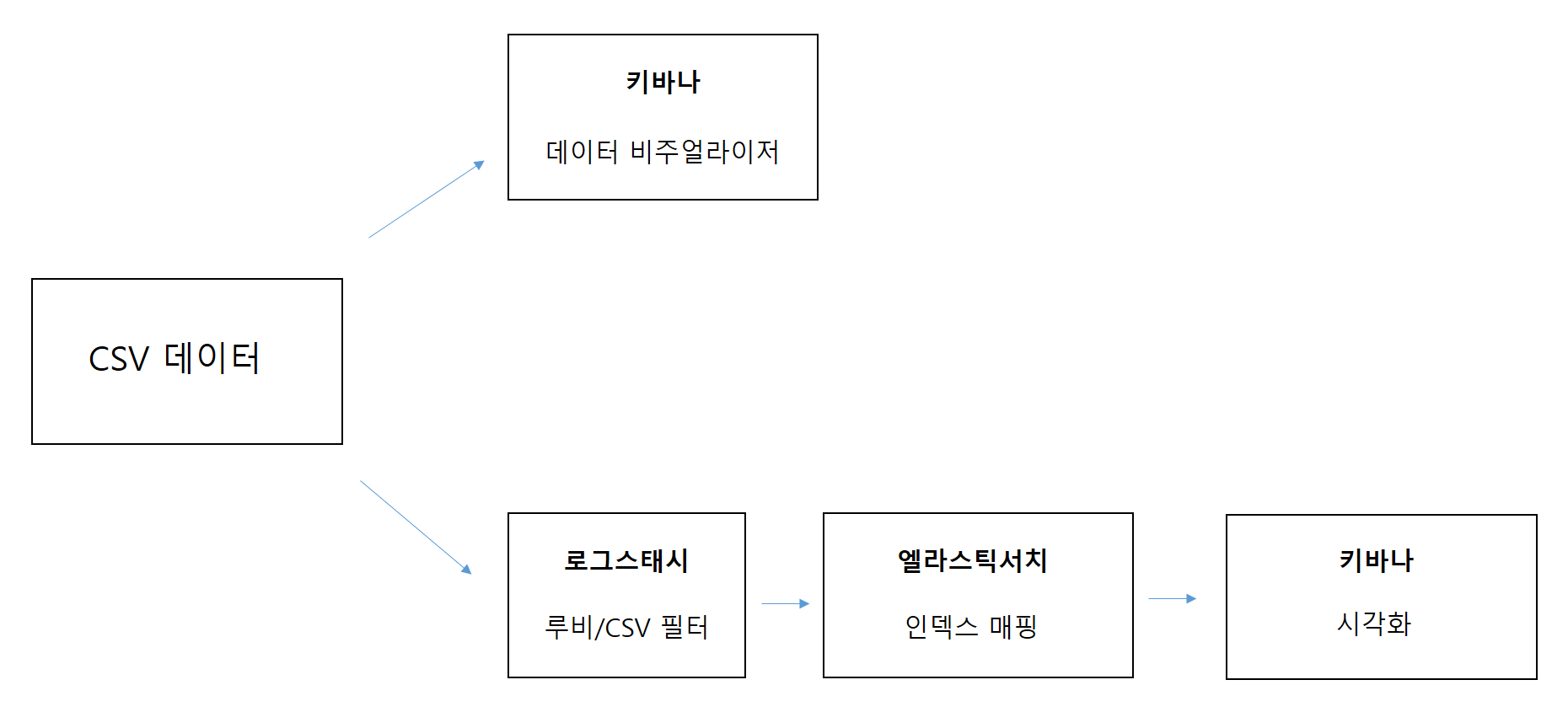
이번 포스팅은 본격적으로 실제 csv파일 데이터를 가져와서 엘라스틱서치를 활용해 분석을 해보겠다. 지금까지 배웠던 내용들을 잘 써먹어보자 ..!
학습 한눈에 보기
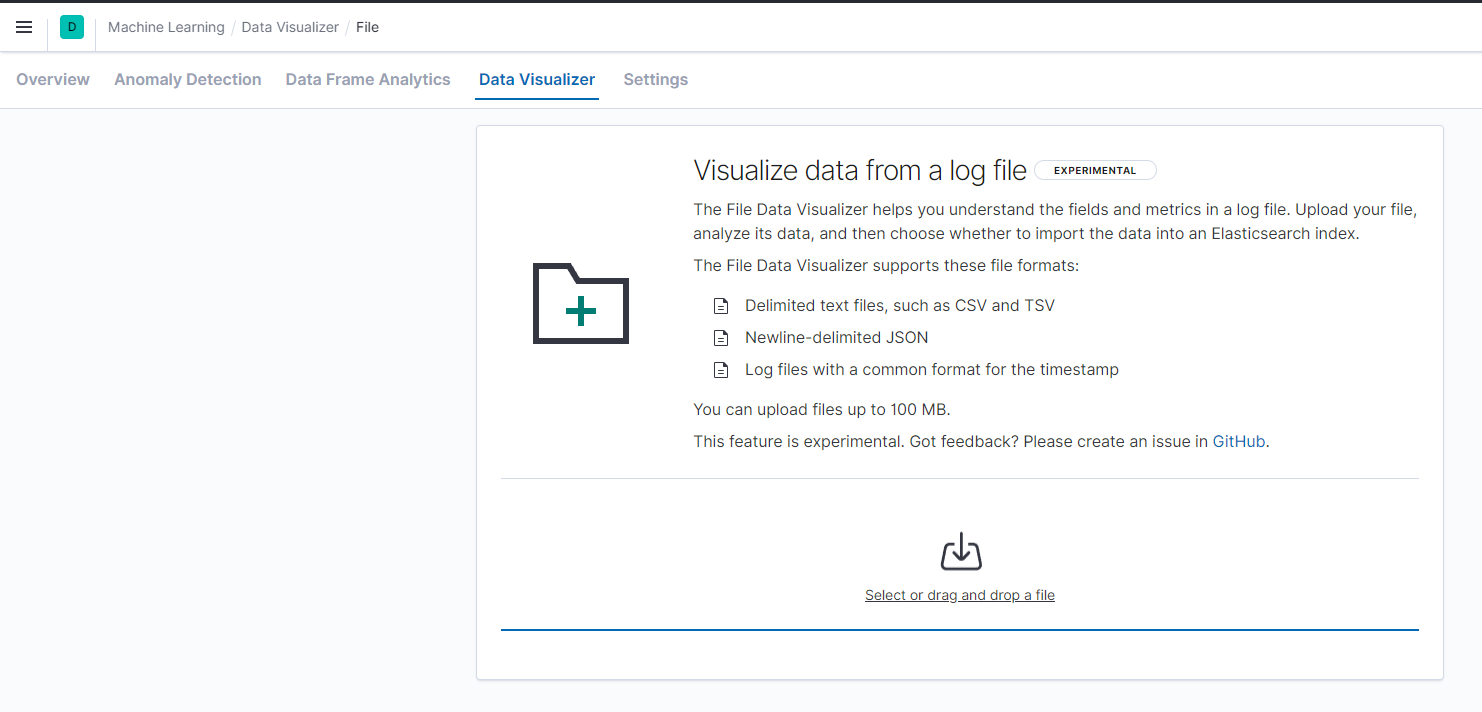
1.파일 가져오기(키바나 활용)
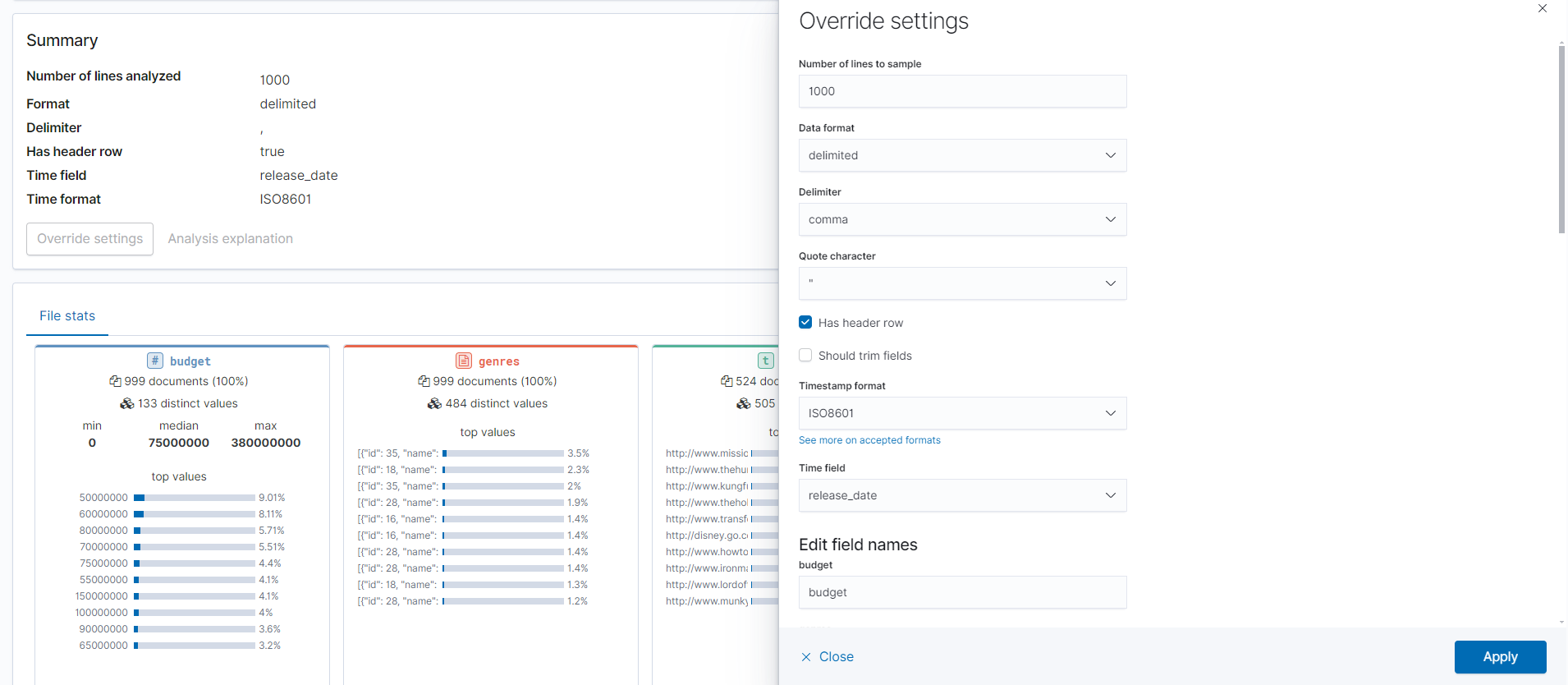
아래처럼 데이터를 넣으면 간단한 통계 정보를 요약해준다. 또힌 overrried settings버튼을 누르면 사진 오른쪽 처럼 컬럼명,타입설정,시간/날짜 컬럼 설정등이 가능하다.
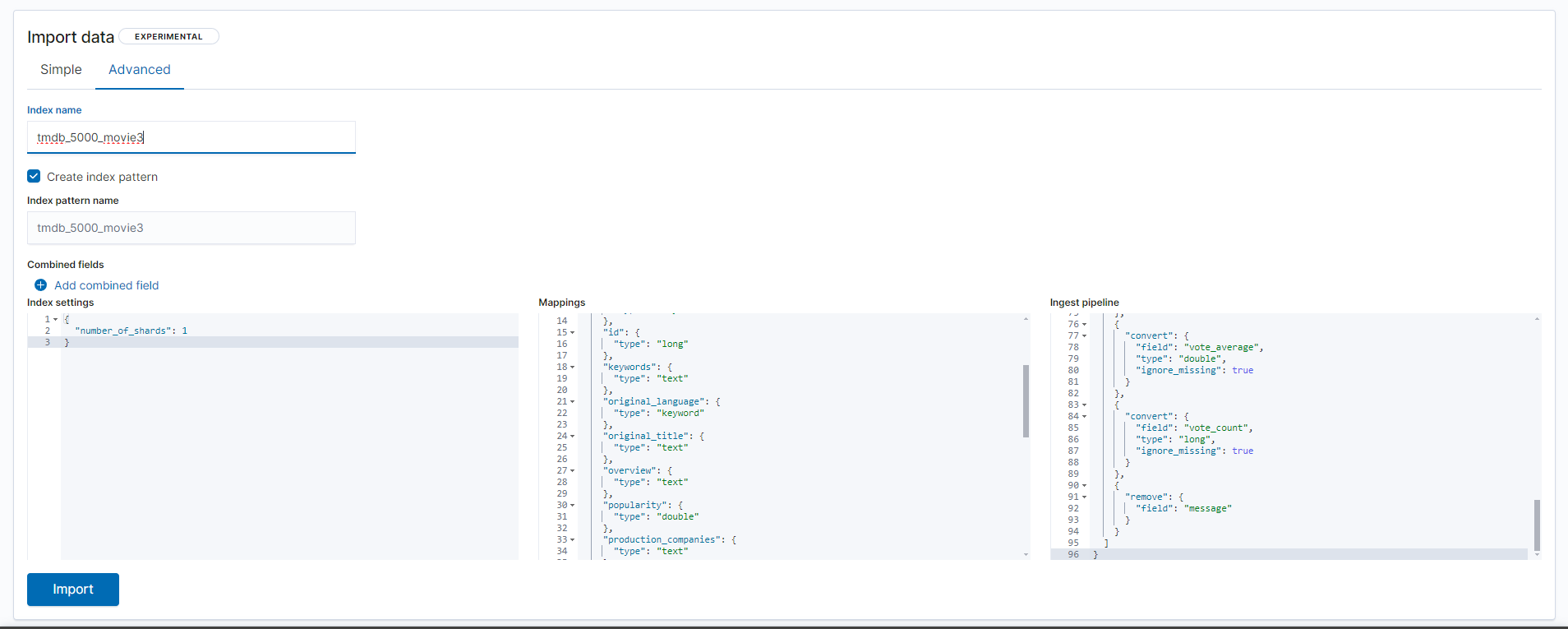
인덱스 패턴 만들기
아래 사진 하단 import 버튼을 클릭하면 simple , advanced 총 2가지 방식으로 인덱스인덱스 생성이 가능하다.

범위 설정
선택했는데 시각화 화면에 아무것도 나오지 않는다 ? 이유가 무엇일까?

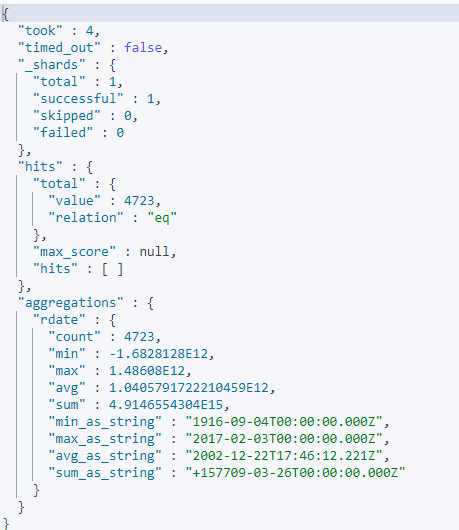
만든 인덱스에 아래처럼 release_date의 통계값을 보았더니 release_date컬럼의 범위가 2017년까지 인것을 알수있다. 하지만 위에서 필터링으로 선택한 날짜는 1년 전이므로 범위 날짜와 맞지않아 나오지 않는것이다. 날짜/시간 범위 설정에 항상 주의하자!
GET tmdb_5000_movie1/_search
{
"size":0,
"aggs": {
"rdate": {
"stats": {
"field": "release_date"
}
}
}
}
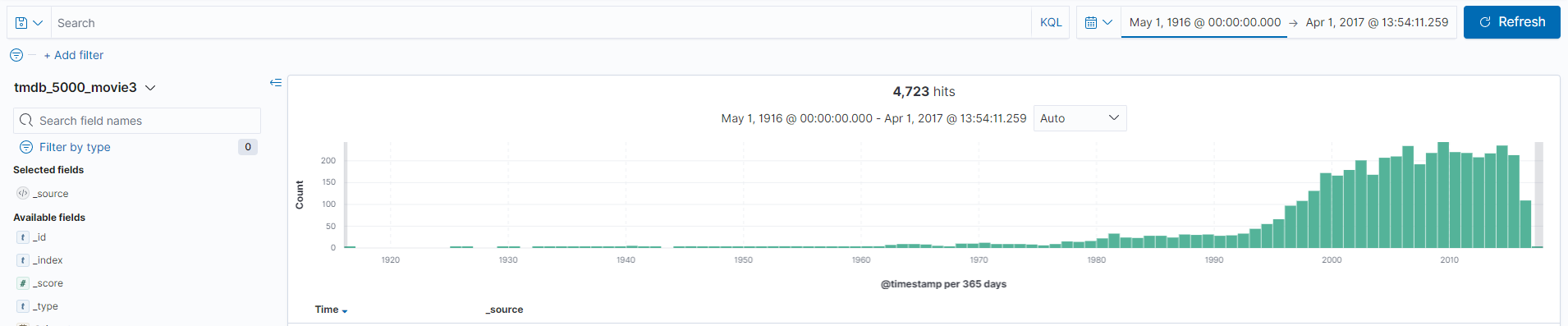
아래와 같이 범위를 release_date에 맞춰서 설정했더니 시각화가 잘 보인다!
2.CSV 파일 가공
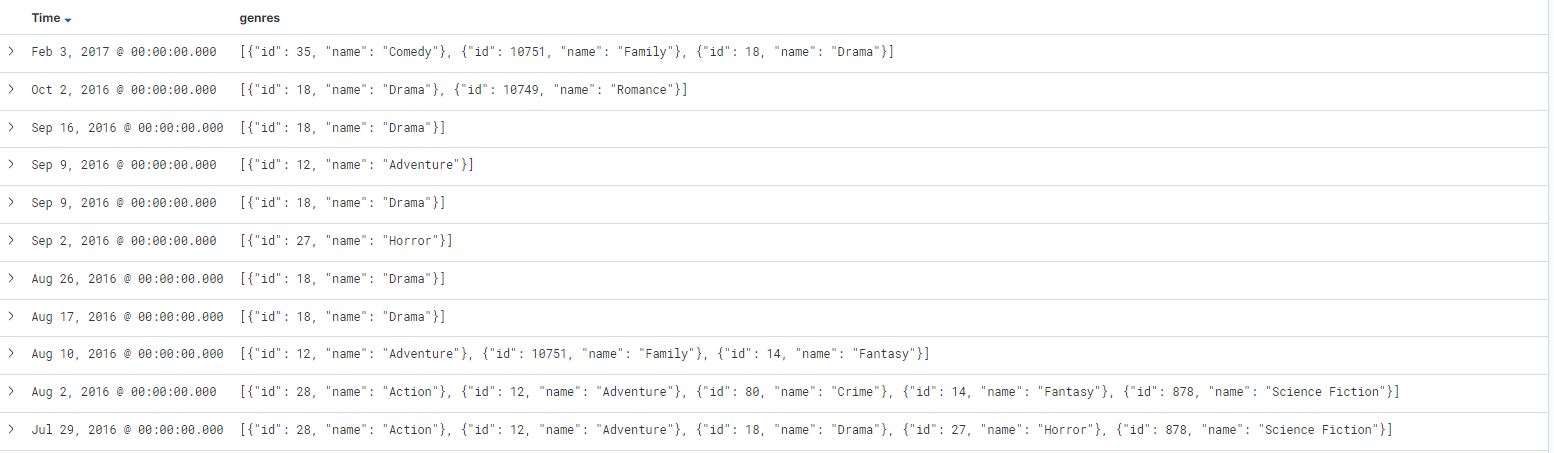
데이터를 살펴보면 아래와 같이 특정 필드가 json형태 텍스트로 저장이 되어있다. 실제 분석을 하기 위해서는 객체 배열 형태로 저장이 되어야하고 이를 위해 로그스태시에서 원하는 형태로 변환해야한다.
우선 more 명령어로 csv내용을 확인한다. 아래와 같이 csv는 헤더부분에 칼럼들이 나오는데 이부분을 삭제하고 분석하기 쉬운 형태로 가공해야한다.
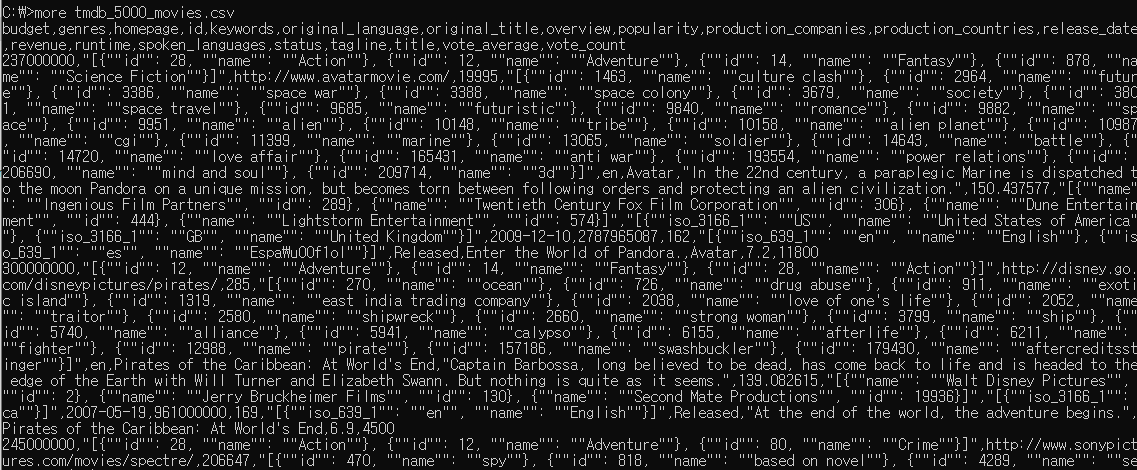
csv 플러그인을 적극 활용해 ',' 구분자로 분리하고 필요한 필드들을 정의하고 , 필요없는 필드들은 remove_field로 지워준다.
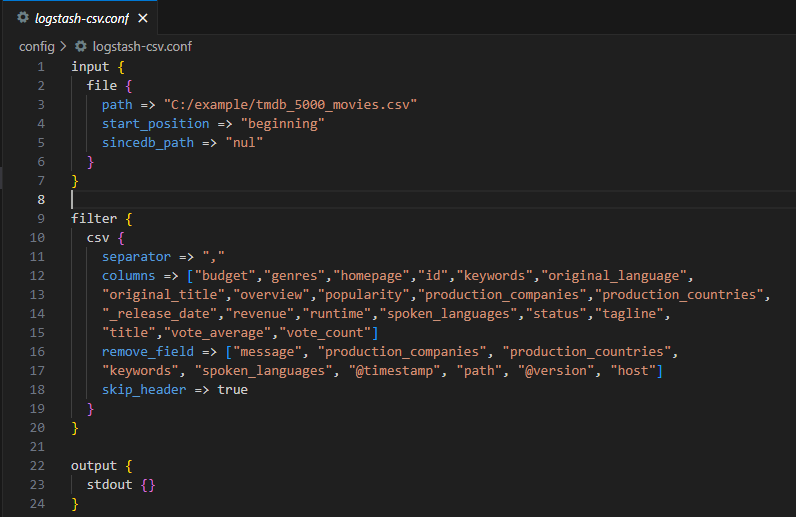
이후 .\bin\logstash.bat -f .\config\logstash-tmdb.conf를 실행시켜줬더니 아래와 같이 원하는 형태로 잘 가공된것을 cmd에서 확인 할 수 있다.
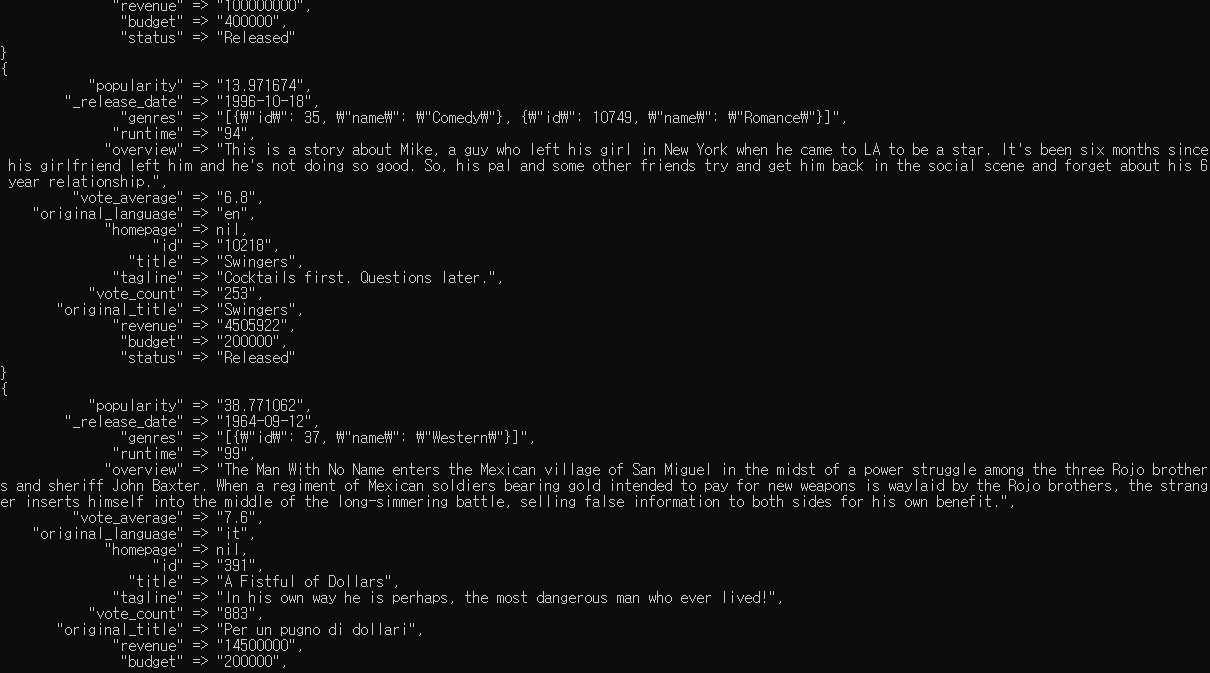
하지만 두가지 문제가 더 있다. 날짜/시간 필드인 _release_date가 텍스트 타입이라는점 , genres가 객체가 아닌 긴 텍스트 형태라는점이 문제이다. 이 두가지를 처리해주자
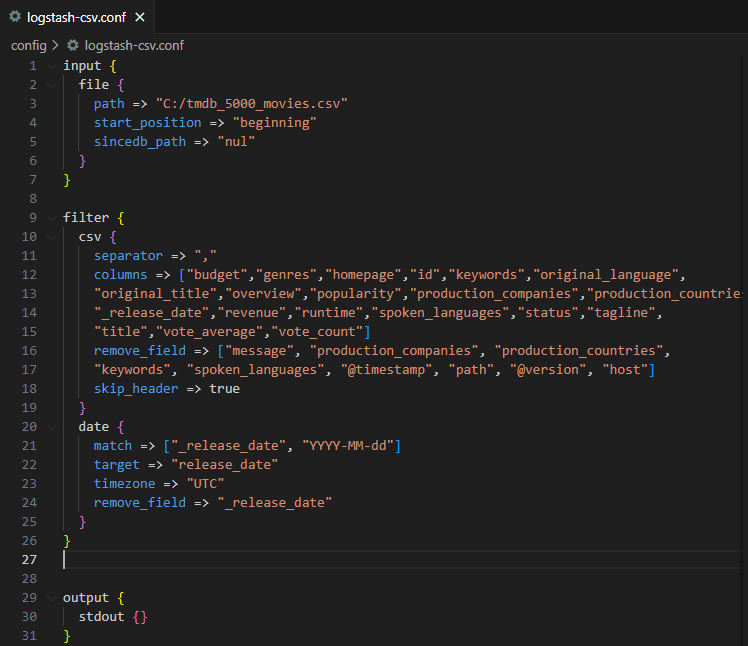
_release_date 타입 변환
타입 변환은 간단하다. date필터 플러그인을 활용하는 부분을 conf파일에 추가해주면 바로 변환이 가능하다.
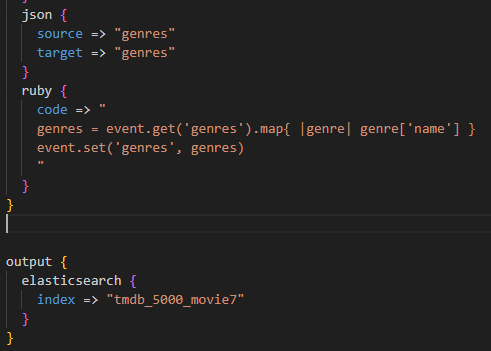
genres 루비 필터를 이용한 파싱
방법1
genres 를 원래 의도했던 형태로 만들기 위해서는 ruby필터를 활용해 파싱해야한다.
같은 .conf 파일에 date 아래 부분에 ruby필터를 추가한다. 루비 필터에는 code포함 아래와 같이 3가지 옵션이 있다.
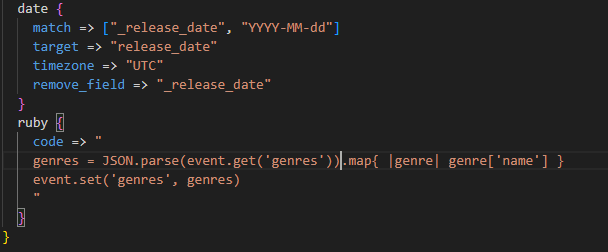
<ruby 필터 3가지 옵션>
code : 각 이벤트 필터링을 위한 루비 코드 작성
init : 로그스태시가 초기화되는 시점에서 수행할 코드 , 모든 이벤트에 대해 공통으로 사용될 함수나 상수 정의할때 사용
path : 코드 설정대산 별도의 파일로 작성하고 해당 파일을 가리킬 수 있게 하는 방법
이벤트 API는 로그스태시 내부에서 각 이벤트를 처리할 떄 사용되는 API로 get,set 함수를 제공한다
event.get('필드이름') : 이벤트 객체에서 얻어오고자 하는 필드 경로를 입력하는데 , 이때 하위 객체 필드는 [상위필드명][하위 필드명]같이 대괄호로 표현
enent.set('필드이름','변경할 값') : set API , get API와 동일하게 값을 변경하고자 하는 필드 경로를 입력하고 , 변경할 값을 입력한다
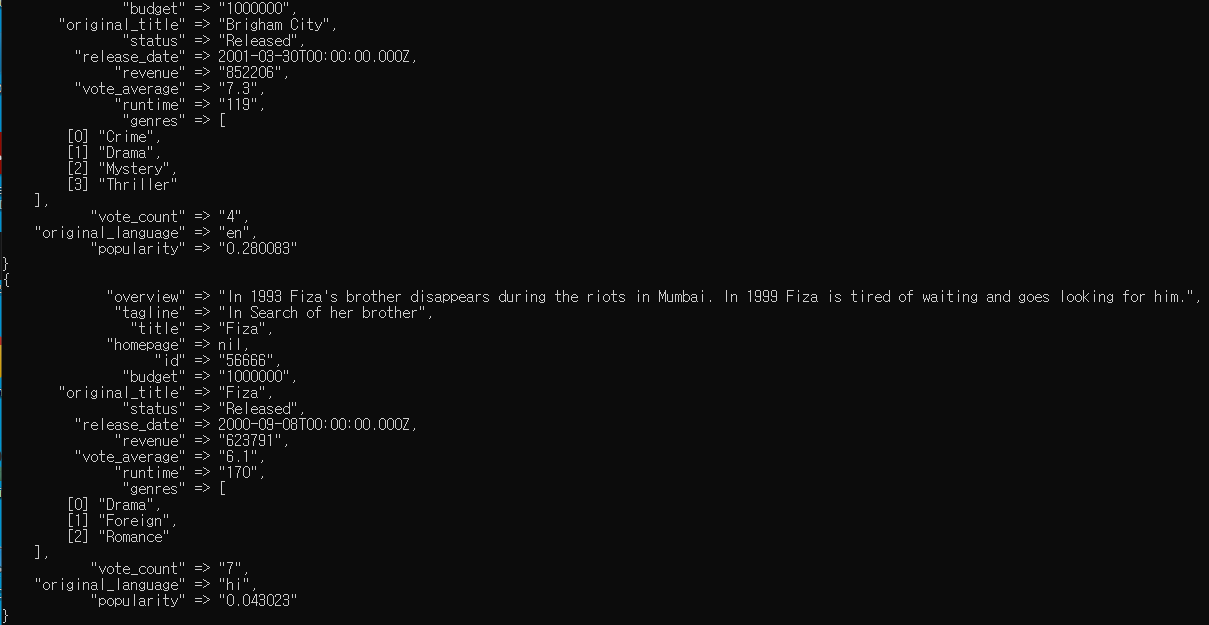
JSON.parse()는 JSON을 파싱하는 함수이다 . 따라서 추가된 위 코드는 envet.get으로 특정 컬럼의 문자열(genre)을 가져오고 event.set으로 특정 컬럼에 문자열을 쓴다. 이후 루비 map함수로 열거형 데이터 값을 가져오도록 한다. 결과는 아래와 같다.
방법2
검증된 json 필터 플러그인을 활용하는 방법이다. 코드는 거의 달라지지 않고 , json 함수대신 json 필터 플러그인을 추가한다. 결과는 위와 같으므로 생략하겠다.
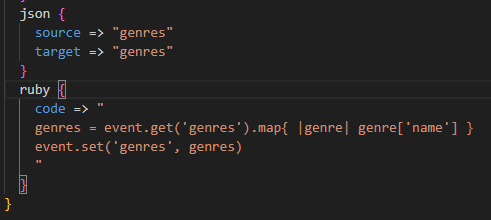
<json 필터 플러그인 옵션>
source : 파싱되지 않는 JSON 문자열이 들어있는 필드
target : 파싱된 객체를 담을 대상 필드
skip_on_invalid_json : 잘못된 형식의 JSON 문자열이 입력되었을때 별도의 경고없이 이를 무시
tag_on_failure : JSON 문자열 파싱에 실패했을떄 tags필드에 추가할 태그를 의미
3.인덱스 매핑
로그스태시에서 파싱된 데이터들이 엘라스틱서치로 인덱싱되기 위해서는 엘라스틱서치 매핑작업이 필요하다. 다이나믹 매핑 방법을 사용해서 매핑을 해도 되지만 , 필드타입을 모두 알고있기 때문에 명시적 매핑을 진행한다. 키바나 콘솔을 활용해 아래처럼 'tmdb_5000_movie7' index를 생성하면서 명시적 매핑을 진행한다.

이후 아래처럼 output을 elasticsearch로 향하게 하도록 conf파일을 수정한 후 실행한다.
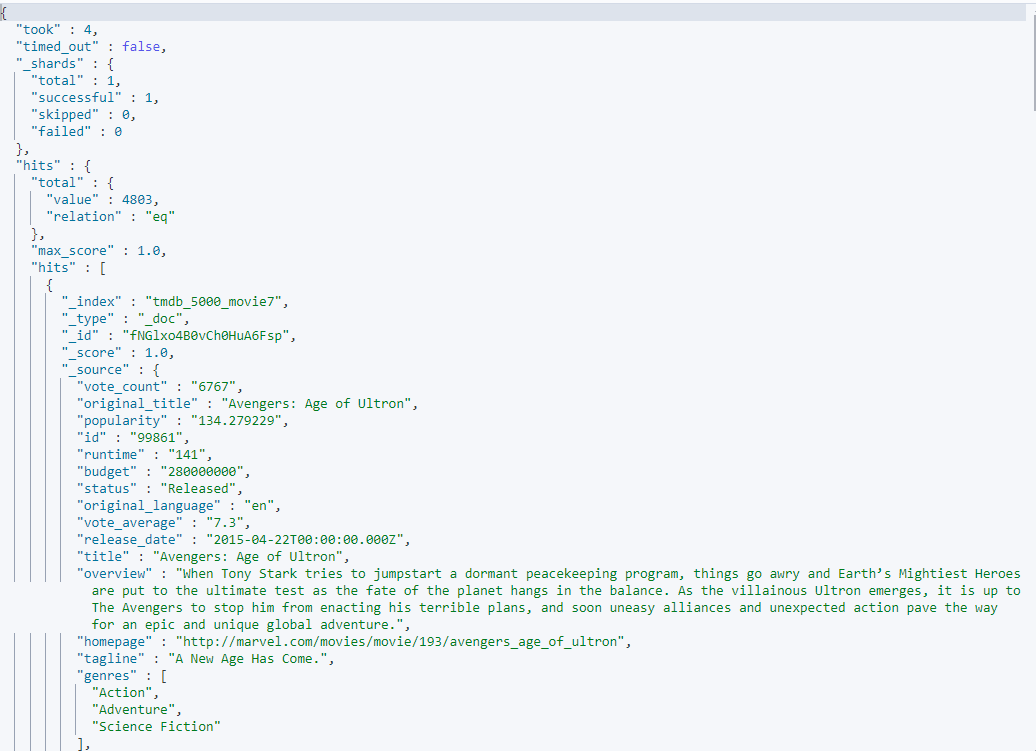
키바나 콘솔에서 GET tmdb_5000_movie7/_search 을 실행해 정상적으로 elasticsearch레 GET tmdb_5000_movie7 인덱스가 생성되고 원하는 대로 바뀌었는지 확인한다. genres부분을 보면 의도한대로 잘 바뀌었고 , release_date도 날짜 형식으로 잘 바뀐것을 볼 수 있다.
4.키바나 분석
키바나에서 사용하기 위해서는 만든 index를 키바나 인덱스 패턴을 지정해야한다. 아래와 같이 만들어 놓은 'tmdb_5000_movie7'를 정의하고 Next step을 클릭한 후 날짜/시간 필드로 release_date를 선택한다. 필자는 캡처를 하기전 위 과정을 진행했기에 이미 정의 되었다고 나온다.
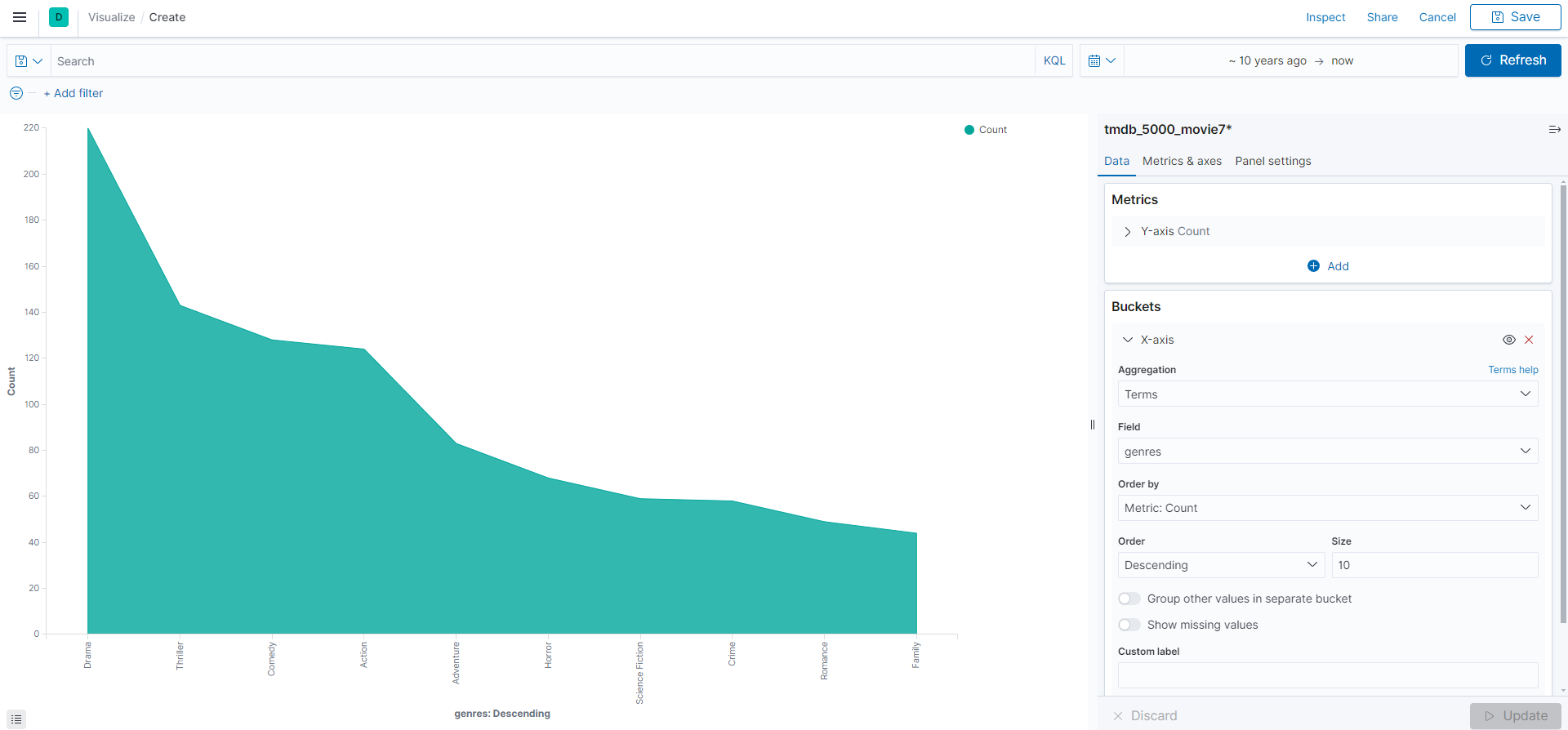
10년 영화 장르 분석
area 대시보드를 선택하고 정의한 index 'tmdb_5000_movie7' 선택한다. 이후 아래와 같이 날짜를 10년으로 조정 , 버킷 집계어서 X-zxis를 선택해 그림과 같이 설정하면 10년동안 유행하 장르를 확인 할 수 있다.
평점 , 수익 분석
평점이 높으면 좋은 영화라고 가정하고 좋은 영화이면 수익이 났는지를 분석해보려고 한다. 먼저 x축과 y축을 아래와 같이 설정해준다.
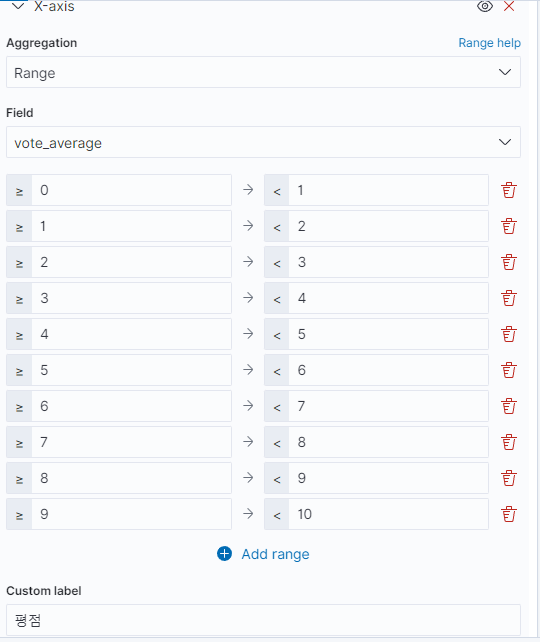
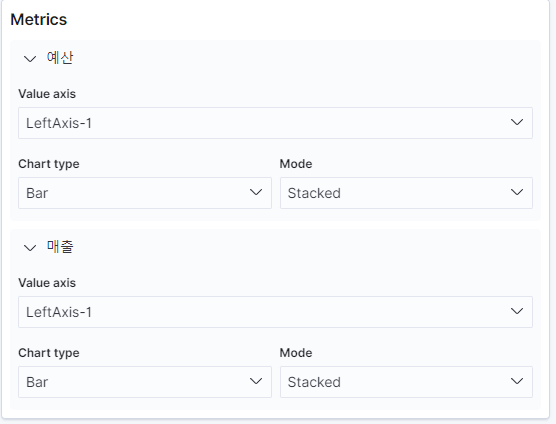
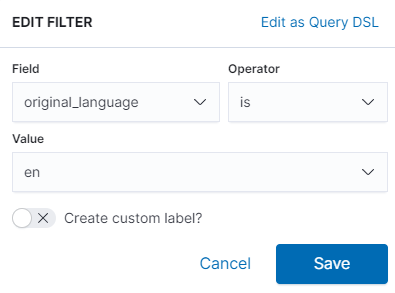
이후 왼쪽 위 필터링 기능을 활용해 할리우드 영화만 필터링 한다.
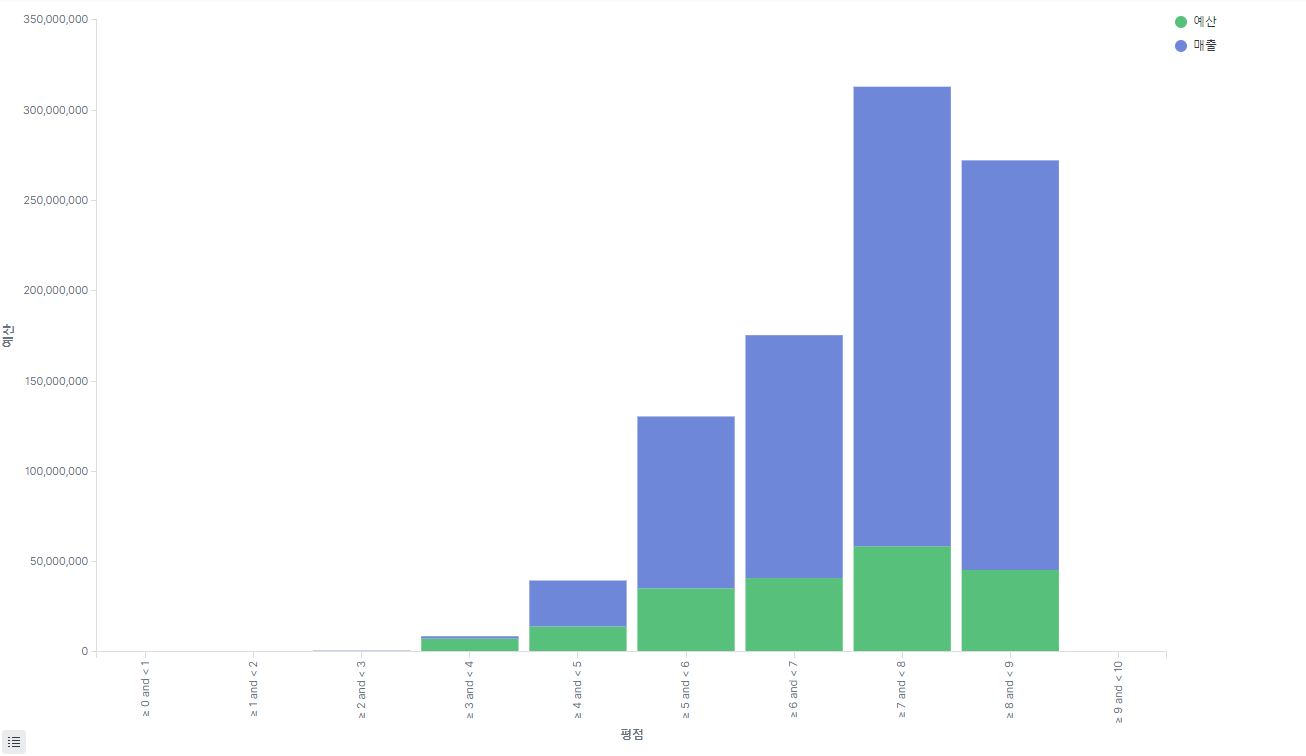
아래와 같이 그래프가 잘 그려지는것을 확인 할수 있다. 평점과 매출은 어느정도 상관관계가 있지만 오히려 8점이 넘어가는 평점은 매출이 그렇게 높지는 않은것을 확인 가능하다.
마무리
이번 포스팅은 본격적으로 캐글 데이터를 가져와서 logstash로 가공하고 elasticsearch로 적재한 후 키바나를 통해 시각화를 하는 과정을 다뤄보았다. 이제는 데이터를 가져와서 키바나 모니터링까지 어떻게 이루어지는지 전반적인 과정을 익힐 수 있었고 , 다음 포스팅에는 다른 데이터를 다뤄보면서 공부해볼 예정이다.
