시작
이번 세번째 포스팅에는 머신러닝 핵심인 앙상블에 대해서 포스팅 해보겠다.
앙상블이란?
앙상블 학습은 여러 개의 모델을 학습시켜, 다양한 예측 결과들을 이용하는 방법론이다. 앙상블은 모든 머신 러닝 모델과 회귀, 분류 문제 모두에 적용 가능하며 크게 Bagging과 Boosting 두가지로 나뉜다. 대표적인 알고리즘으로 Random Forests가 있다.
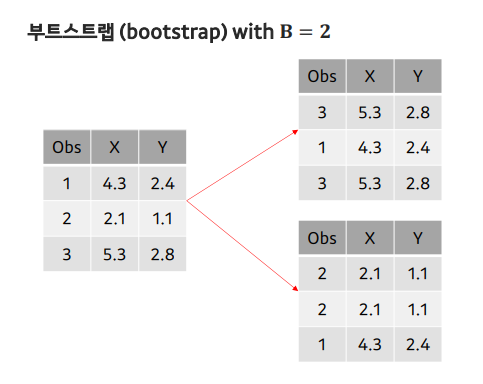
부트스트랩
- 현재 가지고 있는 샘플을 복원 추출(sampling with replacement)하여 여러 개(B개)의 데이터셋을 만드는 방법
배깅
- 병렬적으로 독립적인 모델들을 학습후 각 모델이 만든 예측 결과를 평균화하여 최종 예측(여러 관측을 평균내면 분산을 줄여줌)
- 주로 분류 ,회귀 문제에 적용되며, 모델의 성능 향상과 과적합(Overfitting)의 감소에 효과적이다
- 어떤 피처(variable)가 가장 중요한지 판단이 힘들어 학습 결과에 대한 해석력이 떨어질 수 있음
OOB error
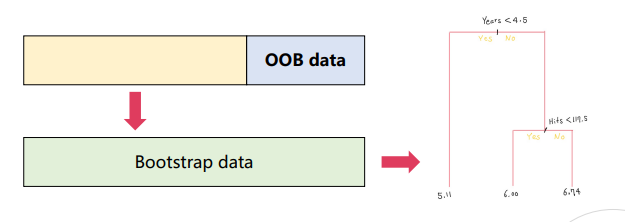
- 하나의 Bagged tree를 학습할 때 사용되지 않은 샘플들을 out-of-bag (OOB)로 부름
- OOB는 각 샘플들의 OOB prediction으로 얻은 오류
- OOB error는 test error에 대한 유효한 추정값이 됨
Random Forests
- Bagged tree 사이의 상관관계를 없애 성능을 향상시킨 알고리즘
- 상관관계가 줄어든 결정 트리를 사용하기 때문에, 분산 감소 효과가 증폭됨
부스팅
- 새로운 모델은 이전 모델이 잘못 분류한 샘플에 가중치를 더 높여 학습
- 부스팅은 이전 스텝의 트리 정보를 활용해순차적으로트리를 만듦
AdaBoost
- 이전 결정 트리가 잘못 예측한 데이터에 큰 가중치(w8)를 부여해, 다음 결정 트리가 더 집중할수 있도록 순차적으로 학습하는 알고리즘

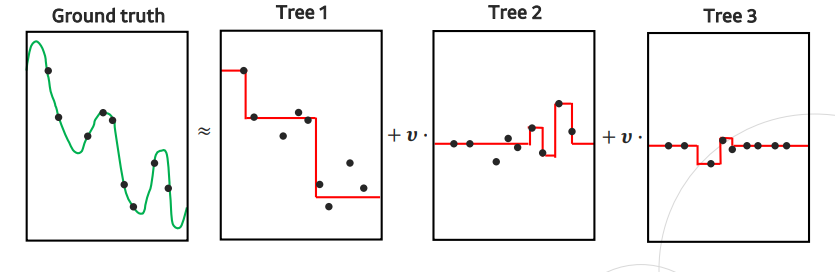
Gradient Boosting (GBM)
- 현재 모델의 오차(residual)를 줄여주는 방향으로 결정 트리를 학습하는 알고리즘
- 손실 함수의 gradient를 기반으로 하는 기법으로, 손실 함수의 gradient를 최소화하는 방향으로 새로운 모델을 구성
XGBoost
- GBM 알고리즘의 성능과 속도 면에서 향상된 알고리즘
- 정규화 항을 손실 함수에 추가 , Split finding 알고리즘을 통해 연산의 효율성을 높임
Light GBM
- GBM기반이며 , 결정 트리 학습에 사용되는 데이터 수를 다음의 방법들로 줄이는 알고리즘
- 작은 gradient 값을 가진 샘플들을 제외하는 방법론 GOSS , 상호 배타적 피처를 묶어, 탐색해야되는 피처 수를 감소시키는 방법론 EFB 사용
후기
이번 포스팅에서는 간단하게 앙상블이란 무엇인지 , 앙상블 방법과 그에 따른 알고리즘들을 정리해 보았다. 나는 이전에 빅분기 실기를 준비했을때 , 캐글에서 titanic데이터로 분류를 수행했을때 앙상블 모델들을 사용한 적이 있다. 사용해보면서 느낀점은 앙상블 알고리즘들이 일반적인 분류 , 회귀 모델들 보다 높은 정확도를 보였으며 XGBOOST , Gradient Boosting , Light GBM , AdaBoost중에서 무엇을 사용할지는 데이터에 따라 다른것 같다.
게임 서버 운영 프로젝트로 DB 데이터를 주로 다루다보니 다소 잊어버렸던 개념들을 이번 공부를 통해 다시 상기시킨것 같다. 앞으로는 추가 개념으로 차원 축소 , 클러스터링 개념등을 더 학습해 포스팅할 예정이며 , 코드로 구현한다면 내용은 추후에 추가하도록 하겠다. 이번에도 역시 교육 전문 플랫폼 메타코드 덕분에 좋은 강의를 무료로 수강 할 수 있어 감사하다.
메타코드 공식 사이트 : https://mcode.co.kr/
강의 유튜브 링크 : https://youtu.be/oyzIT1g1Z3U?feature=shared
#메타코드 #메타코드M #머신러닝 #딥러닝 #앙상블 #기초 #이론
