시작
이번 포스팅은 인코딩 방식중에서 one-hot-encoding 과 정수 인코딩의 단점을 보완할 수 있는 새로운 인코딩 방식에 대해 포스팅해보겠다.
word embdding
저번에 포스팅했던 정수 인코딩은 단어 사이의 연관성을 파악하기 어렵다는 단점이 있고 , 원핫 인코딩은 메모리문제/희소 표현(sparse Representation)이 많다는 단점이 있다. 따라서 이 단점을 극복한 방법은 word embdding방식을 주로 사용한다.
word embdding 특징
- 밀집 표현(Dense Representation)
- 차원을 줄이는데 벡터의 차원은 원하는 대로 설정할 수 있음
- 데이터를 이용해서 표현을 학습(nn활용)
word2Vec Methods
1.CBOW (Continuous Bag of Words)
- 주변 단어를 활용해 중간에 있는 단어를 예측해 레이블(데이터)로 활용
- 주변단어를 input으로 넣고 output은 중심단어를 분류후 loss function을 계산하고 back propagation을 시켜 나온 weight matrix들을 학습하는것이 목표
- 주변단어의 개수는 hyper parameter다
2.Skip-Gram
- 중간 단어를 활용해 주변에 있는 단어를 예측(CBOW와 반대)
NNLM(NN-Language Model)
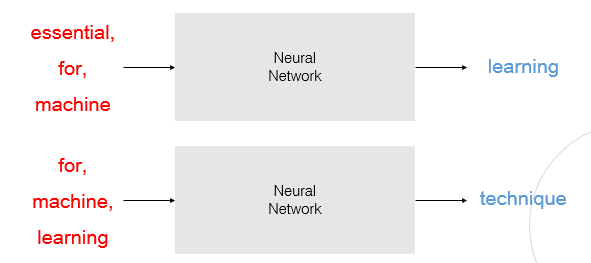
- 예측을 하기 위해 앞에 n개의 단어만 활용하자
- 한계 : 정해진 길이의 과거 정보만을 참조하므로 함축 정보를 파악 불가능
SGNS(SkipGram with Negative Sampling)

- 일반 Skip-Gram , CBOW는 단어가 많아지면 학습 정확도가 떨어지는 한계가 있음
- 선택한 두 단어가 중심인가 ? 주변인가 ? 를 판정해 수치로 레이블링 (문맥 정보 함께 고려)
3.FastText
- 단어 단위에서 더 쪼갠 'subword'의 개념을 도입
예) mouse = <mo+mou+ous+use+se> - OOV(모르는 단어)문제를 어느정도 해결 가능하다 -> 자르면서 해석하므로
- 오타 , 빈도수 적은 단어 전처리에도 좋음
차원을 축소하는 방법 PCA
- word2vec 방법은 임베딩 차원이 고차원이므로 이를 pca를 통해 차원축소하고 시각화 하기 좋다.

Glove
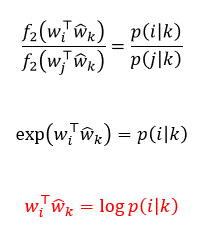
- co-occurrence Matrix을 사용하여 단어 벡터를 학습하는 알고리즘
- 중심단어와 주변단어를 내적을 하면 log(co-occurrence Matrix 확률)이된다
- co-occurrence Matrix
- 붙어있는 단어에게 1을 부여하는 방법
- 행렬이 전치행렬과 같은 구조를 가지는 matrix
loss Function

- 위 식이 교환법칙이 성립하지 않기 때문에 bias를 더해주어야 한다.
- 이 loss를 backpropagation을 통해 nn학습.
- 이 loss function을 구하는것이 핵심 !
장점
- Word2vec 보다 높은정확도
- 편향된 데이터에 강하고 단어의 문맥정보를 어느정도 고려 가능
문제
- logxik 값의 발산 -> 해결방안 : log(1+logxik)
- co-occurrence 행렬 x가 sparse인 경우 -> 해결방안 : weighted prob(python에서는 함수 하나로 가능)
메타코드 공식 사이트 : https://mcode.co.kr/
강의 유튜브 링크 : https://www.youtube.com/watch?v=Rf7wvs8ZbP4

데이터 공부 기록