시작
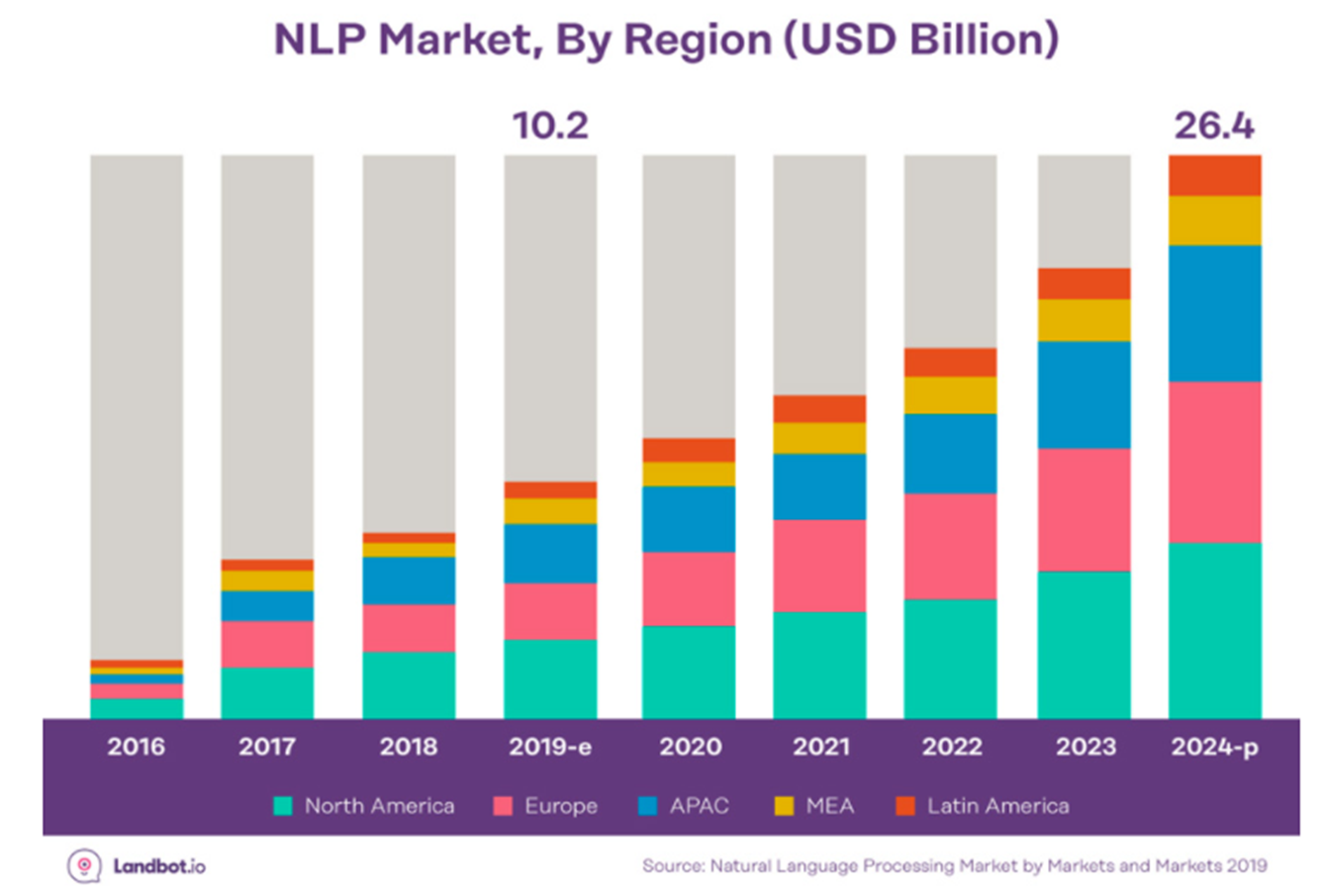
기술이 발전하면서 이제는 비정형 데이터를 다루는 기술이 중요해지고 있고 , 특히 텍스트 데이터를 다루는 '자연어처리' 역량이 많이 중요해진것 같다. 마침 메타코드 사이트에서 제공되는 자연어처리 관련해서 무료강의가 있었고 이번 기회를 통해 공부를 해보려고 한다. 여러가지로 도움을 많이 받는것같다.
자연어처리(nlp)?
일상 생활에서 사용하는 보편적인 언어를 말한다. 따라서 자연어처리는 컴퓨터가 이 자연어를 처리하는것을 의미한다.
기술 예시 1. chat bot
- Sentiment Analysis : 텍스트에 녹아 있는 감성 또는 의견을 파악
- Tokenization : 단어의 최소한의 의미를 파악하는 쪼갬
- Named Entity Recognition : 텍스트로부터 주제 파악
- Normalization : 의도된 오타 파악
- Dependency Parsing : 문장 구성 성분의 분석
기술 예시 2. SIRI
- Feature Analysis : 음성 데이터로부터 특징을 추출
- Language Model : 언어별로 갖고 있는 특성을 반영
- Deep Learning : 이미 학습된 데이터로부터 음성 신호 처리
- HMM: Hidden Markov Model : 앞으로 나올 단어 또는 주제의 예측
- Similarity Analysis : 음성 신호가 어떤 기준에 부합하는가?
기술 예시 3. Translator
- Encoding : 유사도 기반 자연어의 특징 추출
- Time Series Modeling : 문장을 시간에 따른 데이터로 처리
- Attention Mechanism : 번역에 필요한 부분에만 집중
- Self-Attention : 문장 사이의 상관관계를 분석
- Transformer , Attention 구조를 이용한 번역 원리
텍스트 전처리 과정
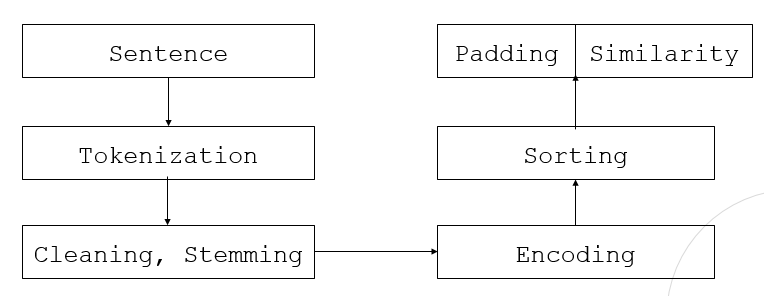
1. 토근화 : 문장을 형태소 단위로 자르는 과정
예)Model-based reinforcement learning don’t need a value function for the policy.


어려운 예)
어제 삼성 라이온즈가 기아 타이거즈를 5:3으로 꺾고 위닝 시리즈를 거두었습니다!
-> 5:3 같은거는 따로 처리를 해줘야함
2. 정제 및 추출 : 데이터 사용 목적에 맞게 노이즈 제거
예 ) 출현 횟수가 적은 단어 제거 , 지시대명사 관사등 제거 , 어간/표제어 추출
어간추출/표제어 추출 대표적 방법(Porter Algorithm)
-
is, are -> be / having -> have
-
표제어 추출은 단어의 품사 정보를 포함하고 있음(여려의미로 쓰는 단어 분류할때 유리) / 어간 추출은 품사 정보를 갖고 있지 않다.
불용어 (Stopword) 제거
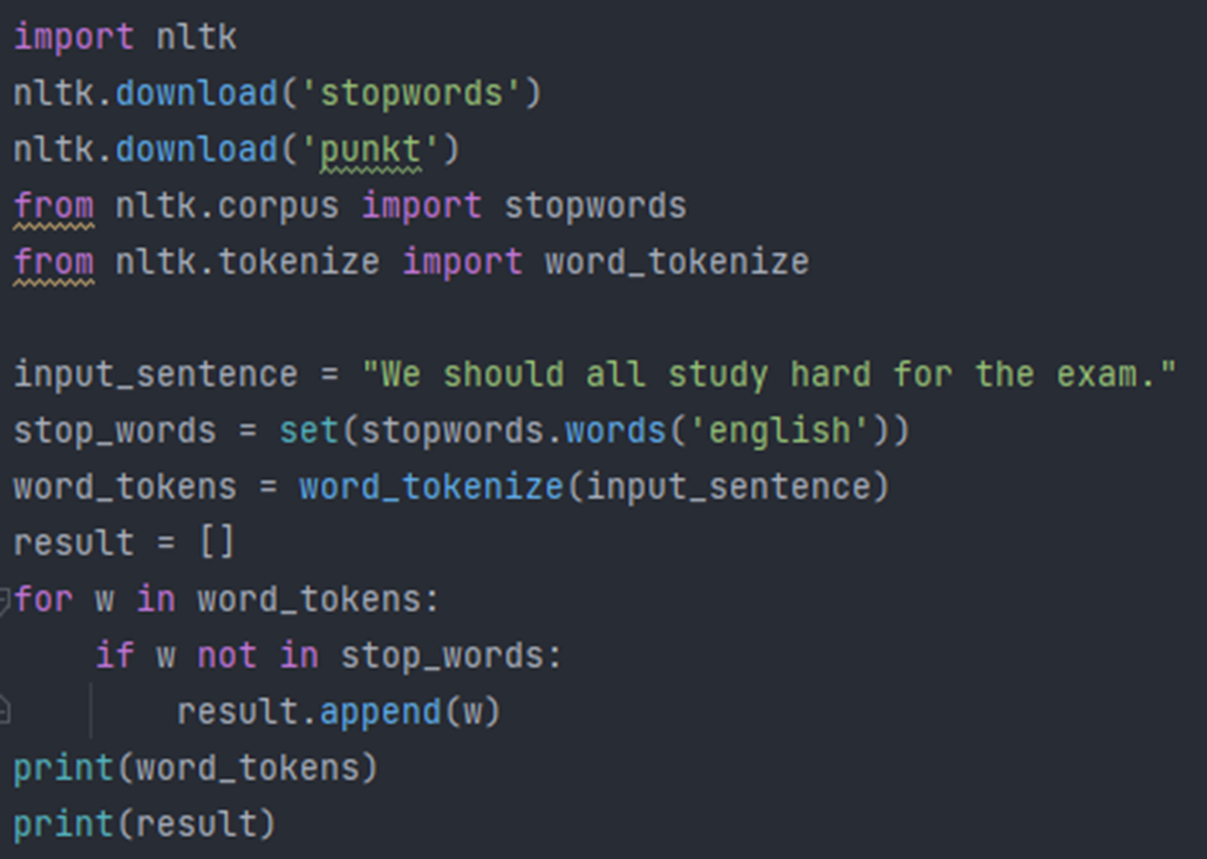
1: 불용어 (stopword) 목록을 받아온다.
2: 정제할 문장을 토큰화 (tokenize)한다.
3: 토큰화된 각 단어마다
-> 단어가 불용어 목록에 없는 경우 → 정제 결과에 추가
-> 단어가 불용어 목록에 있는 경우 → pass
3. 인코딩 : 문장을 컴퓨터가 이해할수 있는 숫자로 변환
정수 인코딩

Word2vec Encoding
- 단어의 유사성을 인코딩에 반영(정수 인코딩의 한계를 극복)
TF-IDF (Term Frequency – Inverse Document Frequency)
- 단어들의 중요한 정도를 가중치로 매기는 방법
4. 정렬 및 유사도 분석
코사인 유사도 방법
예)
1: I love apple.
2: Apple is delicious which I love too.
3: I want a delicious food, but not an apple.
4: Deep learning is difficult.
먼저 각 문장의 단어 빈도수를 계산하고 그를 기반으로 각 문장의 루트값을 구한다. 이후 구하고 싶은 문장끼리의 내적값을 나눠주면 구하고 싶은 문장끼리의 유사도를 파악 할 수 있다.
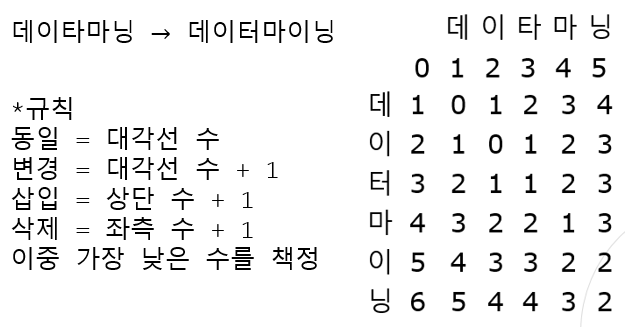
Levenshtein Distance 방법
- 단어 사이의 거리를 나타내는 대표적인 척도(단어 A를 단어 B로 수정하기 위한 최소 횟수)
후기
자연어 처리 관련 첫번째 포스팅이라 가볍게 개념위주로 작성 해보았다. 다음 강의 내용은 텍스트 마이닝 기법들에 대해 자세하게 소개되어 있고 , 다음 포스팅에서는 이 내용들에 대해 작성해보려고 한다.
메타코드 무료 강의 덕분에 모호했던 개념들을 공부하고 정리하는 시간을 가질 수 있게 되어 너무 감사하다.
메타코드 공식 사이트 : https://mcode.co.kr/
강의 유튜브 링크 : https://www.youtube.com/watch?v=Rf7wvs8ZbP4
