RNN
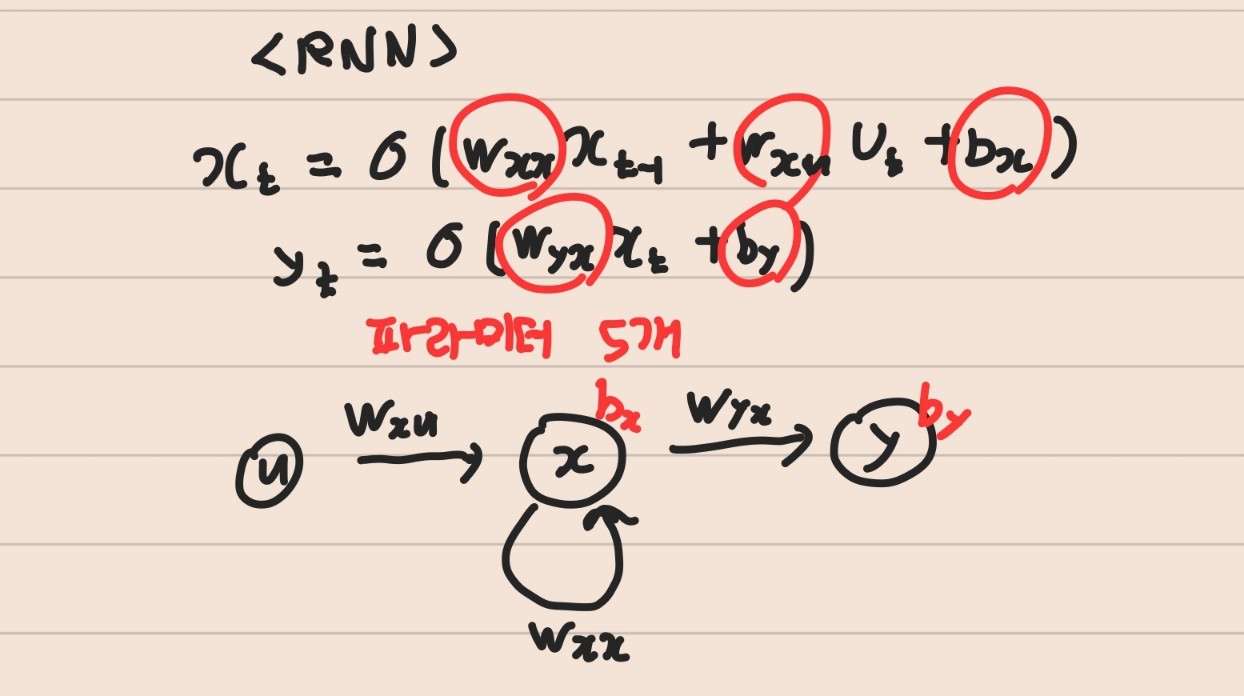
- 시계열 데이터를 처리하기에 좋은 뉴런 네트워크 구조
- RNN은 시간별로 같은 weight를 공유
- 입력(input layer) -> 상태(히든 layer:셀프 피드백) -> 출력(output layer)인데 상태에서 샐프피드백
- ann,cnn처럼 back-propagation(역전파)를 사용 -> BPTT(시간에 따른 역전파)
- 예 ) 음성인식 , 음악 생성기
종류
- many-to-many : input - ouput 둘다 많음 - 번역
- many-to one : input은 많고 output은 한개 - 예측
- one-to-many : input은 한개 output은 여러개 - 생성
문제점
- RNN구조에서 state xt 에는 wxx가 계속 곱해지게 된다
- 곱해지는 값이 1보다 크다면 exploding(발산)
-> 해결책 : gradient clipping(기울기 값을 자르는 것) - 곱해지는 값이 1보다 작다면 vanishing(0수렴)
-> 해결책 LSTM , GRU
LSTM
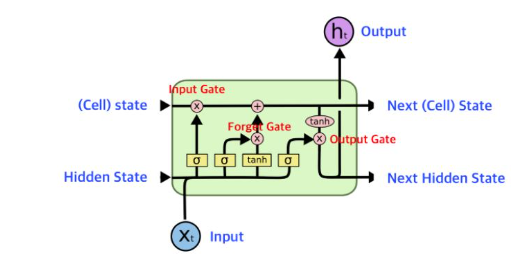
RNN의 문제점을 개선하기 위해 나온 대표적인 모델이 LSTM,GRU이다
- 총 6개 파라미터이고 input gate , forget gate , cell state , output gate 총 4개의 게이트가 있음
- step1 ,2 (forget gate) : 얼마나 잃어버릴 것인가 / (input gate) : 새새로운 정보를 어느 정도 허용할 것인가
- step3 (sell state) : input , forget 에서 나온 정보를 적당히 섞음
- step4 (output gate) : 3개에서 나온 정보를 적절히 합쳐서 output gate로 보냄
- 이러한 게이트들은 입력 데이터와 이전 상태의 조합에 따라 어떤 정보를 전달하고 어떤 정보를 버릴지를 결정하여 정보의 흐름을 조절
GRU
- LSTM 간소화 버전 (sell state없음)
- STM보다 적은 파라미터를 사용하면서도 유사한 성능 , 더 빠르게 학습
Seq2seq model (mamy-to-mamy)
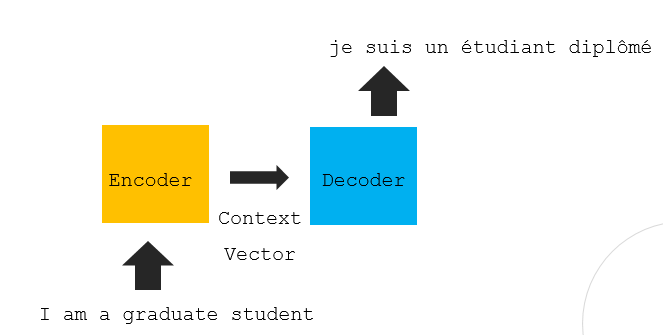
- encoder rnn구조 , decoder rnn구조 가로로 병렬로 쌓음
- 문장이 encoder에 들어가면 context vector(모든정보 함축)로 만들어 decoder 초기상태로 씀
- decoder에서 인풋으로 아웃풋 만들고 아웃풋을 다시 인풋으로 넣고 이 과정 반복하면서 작동(시작과 끝 존재)
장단점
- 장점 : context vector로 받고 단어를 생성할때 이전 문장의 특징을 모두 반영 가능하다
- 단점 : 학습을 제대로 하지 못하면 연쇄적으로 이상한 결과를 만들어낸다 , 입력 시퀀스를 하나의 벡터로 압축하느 ㄴ고자ㅓㅇ에서 입력 시퀀스의 일부 정보가 손실
그외
1D-CNN network structure
-> 자연어처리용 cnn
-> word2vec 결과에 -> 필터 , pooling을 거치고 결과를 모으고 FCL에 넣는구조
bi-lstm
-> lstm 이 두개라고 생각 (wss가 두배)
transformer
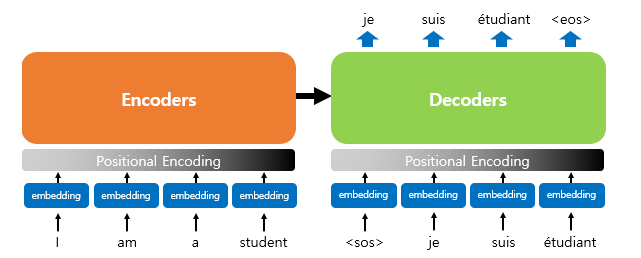
- seq2seq 처럼 encoder-decoder구조로 이루어져 있는데 RNN을 사용하지 않음
- RNN이 없으므로 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있는데 각 단어의 인베딩 벡터의 위치 정보들을 더해 모델의 입력으로 사용 = 포지셔널 인코딩
Attention
- 현재 시점 예측에서 입력의 특정 부분에 보다 집중할 수 있도록 설계
- 어텐션 스코어(Attention Score) 계산
-> encoder 의 hidden state(key)와 decoder의 hidden state(query)를 내적한다 = 유사도 계산 - 어텐션 가중치(Attention Weights) 계산
-> 내적한 값 attension socre에 softmax통과 (합이 1이된다=인코더의 각 hidden state에 대한 가중치로 사용가능=어디에 집중할지) - 가중 평균(Weighted Sum) 계산
-> 어텐션 가중치를 사용하여 인코더의 hidden state를 가중 평균하여 값을 구함
-> 이를 통해 디코더가 현재 예측을 수행할 때 인코더의 다양한 부분에 집중 - 어텐션 값(Attention Value)과 디코더 히든 스테이트 결합
-> 가중 평균값과 디코더의 hidden state를 연결(concatenate)하여 어텐션 값을 구하고 이 값을 디코더의 다음 예측에 사용
Bert -> transformer기반
특징
-
transformer의 encoder부분을 사용
-
대용량 corpus data로 학습시킨후 task에 맞게 전이학습를 하는 모델
-
word2vec,glove,fasttext과 같은 word embedding의 한 방법
-
bert로 구성된 언어 모델에는 lstm , cnn 구조없이 ann만 이어서 task를 수행하여도 성능 good
-
두가지 방식의 pre-training구조
-> masked language model(MLM) = 단어 단위 학습 = 단어를 가린다
-> Next sentence prediction(NSP) = 문장 단위 학습 = 두 문장을 넣어서 이었을때 어색함이 없느냐
1. MLM
- 단어의 15%를 masking하고 가린 단어를 예측하도록 인공신경망에게 요구(지도학습)
1.1 ) 단어의 15% 마스킹
1.2 ) 이중 80%는 그대로 마스킹
1.3 ) 10% 마스킹대신 random word로 치환
1.4 ) 10% 원래 단어를 그대로 둔다.
2. NSP
- 두 문장이 주어졌을때 두문장이 이어지는 문장인가 ?
bert vs gpt
gpt는 transfomer의 decoder부분만 사용
- bert : 양방향성을 지닌 pre-train모델(감성 분석 추출과 관련 task 강점)
- gpt : 순차적으로 계산하는 단방향성 pre-train모델(문장 생성 관련 task강점)
이번포스팅에는 다양한 언어모델들 정의에대해 간단하게 정리해보았다. 다음 포스팅에서 이 모델에 관한 실습을 하려고 했지만 아무래도 모델이 복잡하고 딥러닝 기반이므로 딥러닝을 먼저 선행학습하고 공부 할 예정이다. 현재 pytorch를 따로 책으로 공부중이다. 다음 포스팅부터는 주로 딥러닝관련 포스팅을 진행하겠다.
이번에도 역시 메타코드 덕분에 좋은 강의를 들을 수 있어 감사하다. 나도 도움을 많이 받은만큼 많은 사람들이 메타코드 사이트를 적극 활용해 다양한 강의를 들어 보았으면하는 바램이다.
메타코드 공식 사이트 : https://mcode.co.kr/
강의 유튜브 링크 : https://www.youtube.com/watch?v=Rf7wvs8ZbP4
