시작
저번 마무리 정리 포스팅에 이어 이번에는 서버를 닫고 진행했던 로그분석 과정 , 앞으로 방향 , 고찰순서로 포스팅을 하겠다.
로그분석
메인 서버에서 메일 게임내에 있는 다양한 로그(채팅기록,상점이용기록,접속정보,에러등)들을 압축파일로 만들어주는데 게임을 운영한 2주동안 유저들이 만들어준 로그를 합쳐보니 총 4만개 정도 쌓였다.
지난번 4번째 포스팅에서 로그분석을 ELK또는 EFK방식으로 시도해 보는 과정을 작성했었다. 이어서 계속 진행했지만 각기 다른 방식으로 쌓이는 로그를 정제해서 elasticsearch로 올리는 과정이 어려웠고 , 결국 익숙하게 할 수 있는 python으로 로그분석을 해보자는 결론에 도달했다.
이미 서버 운영을 닫은 시점에서 분석을 하기에 분석한 결과가 게임 운영에 반영되지 않는다는점이 아쉽지만 , 그래도 실제 데이터가 있으니 해당 데이터를 정제하는 모듈을 구축하는것도 데이터를 다루는 사람으로써 의미있는 작업이라고 생각해 시작하게 되었다.
이번 포스팅에서는 간단하게만 진행한 로그분석에 대해 정리해보겠다. 로그 데이터가 너무나도 다양하게 쌓였기 때문에 인공지능을 활용한다면 더 많은 분석이 가능할 거 같고 앞으로 해당 데이터를 가지고 꾸준하게 분석해볼 예정이다. 새로운 분석을 적용하면 해당 포스팅을 업데이트 시키겠다.
분석 방향
크게 3가지 방향(유저 분석 , 채팅 분석 , 구매/판매 분석)으로 나누어서 분석 프로세스를 구축했으며 , 총 모듈은 6개를 만들었다. 코드 전문은 github에 업로드 했다. github주소 : https://github.com/KangHoJ/minacraft
모듈별 설명
load.py (데이터 로드)
def load_main_data():
# 옵션 설정
plt.rcParams['font.family'] = 'NanumGothic'
pd.set_option('display.max.colwidth', 1000)
pattern = r"\[(.*?)\] \[(.*?)\]: (.*)"
file_list = glob.glob('log/*.gz')
data = []
for file in file_list:
with gzip.open(file, 'rb') as f:
log_data = f.read().decode('utf-8')
groups = re.findall(pattern, log_data)
for group in groups:
data.append(group)
df = pd.DataFrame(data, columns=['Timestamp', 'Level', 'Message'])
df = df[~df['Message'].str.contains('청소')] # 청소 관련 처리
return df
우선 내 local pc에 있는 알집파일들을 모두 불러와서 합치고 '아이템이 청소됩니다'와 같이 주기적으로 등장하지만 필요 없는 데이터는 미리 처리를 해주었다.
# DB 데이터 로드
def load_db_data():
import mysql.connector
import pandas as pd
db = # db정보 입력
cursor = db.cursor()
query = 'SELECT * FROM player_info_view'
cursor.execute(query)
rows = cursor.fetchall()
user_df = pd.DataFrame(rows, columns=['아이디', '이름', '계좌돈', '은행레벨', '유저돈', '플레이어여부', '등록날짜',
'마지막로그인', '전체게임수(컨텐츠)', '승리횟수(컨텐츠)',
'작은승리횟수(컨텐츠)', '패배횟수(컨텐츠)'])
lst = list(user_df['이름'].values) # 다른 데이터와 비교를 위해
return lst, user_dfDB에 있는 데이터를 따로 load하는 이유는 db에 있는 유저id에 따른 정보를 통한 비교들을 다른 모듈을 에서 수행하게된다. 따라서 mysql db서버와 연동하고 user이름 list , 유저정보 데이터프레임을 반환해 주는 함수를 만들었다. user_df는 아래와 같다.

uesr.py(유저 접속 분석)
def convert_to_seconds(timestamp):
import datetime
time_obj = datetime.datetime.strptime(timestamp, '%H:%M:%S')
seconds = time_obj.hour * 3600 + time_obj.minute * 60 + time_obj.second
# 새벽 시간 (00:00:00 ~ 06:00:00) 처리
if time_obj.hour < 6:
seconds += 86400
return seconds
def time_df_func():
global time
time =[]
for li in lst:
plus = []
minus = []
for idx, message in enumerate(login_df['Message']):
if (li in message) and ('[+]' in message):
plus.append(login_df.iloc[idx]['Seconds'])
elif (li in message) and ('[-]' in message):
minus.append(login_df.iloc[idx]['Seconds'])
# [+] 개수와 [-] 개수가 같은지 확인
if len(plus) == len(minus):
total_plus_time = sum(plus)
total_minus_time = sum(minus)
result = total_minus_time - total_plus_time
time.append(result/3600)
else:
print(f"사용자 '{li}'의 [+] 개수와 [-] 개수가 일치하지 않습니다. plus 개수 : {len(plus)} , minus 개수 : {len(minus)}")
return time
def login_df_func():
global login_df
login_df = df[(df['Message'].str.contains('\[\+\].*')) | (df['Message'].str.contains('\[\-\].*'))] # 입,출입만
login_df = login_df[~login_df['Message'].str.contains('님이')].reset_index().drop(['index'],axis=1) # 전처리
login_df = login_df.drop([0, 2, 610]) # 이상 데이터 전처리
login_df['Seconds'] = login_df['Timestamp'].apply(convert_to_seconds) # 시간변환
return login_df
먼저 많은 log데이터 중에서 유저들의 접속을 분석하기 위해 유저들의 접속,퇴장을 나타내는 +,- 을 먼저 추출해야했다. 정규표현식을 사용해 내용을 추출하고 이상데이터를 처리했고 , 중간에 + , - 숫자가 안맞는 즉 , 유저가 들어왔는데 나간 기록이 없는 현상이 발생했다. 이에 +,-개수를 비교하는 logit을 추가해 어떤 데이터인지 확인하고 후처리했다.
해당 문제의 원인은 중간에 로그 시스템 기록 현상이 한번 바뀔때 접속 또는 퇴장해 기록이 제대로 안되었던거였다 . 또한 새벽시간 (예를들자면 01:00)가 정렬을 했을때 23:00시보다 작은 값으로 분류되었기 때문에 따로 time처리 함수를짜서 처리해주었다. 결과는 아래와 같다. seconds칼럼은 추후 다양한 시간을 계산할때 사용된다.
def user_info():
top_users = login_df['Message'].str.extract(r'\[\w+\] ?(\w+)')[0].value_counts().head(5) # 지표1. 유저 로그인 순위 series
time_df = pd.DataFrame({'User': lst , '누적 시간': time}).sort_values(by='누적 시간',ascending=False).reset_index().drop('index',axis=1).head(10) # 지표 2. 유저별 누적시간 순위 데이터
return top_users , time_df
위와 같이 로그인 데이터에서 유저 이름만 뽑아 유저별 로그인 빈도수를 계산해 로그인 빈도수 순위를 계산하였고 , 유저별 누적시간 순위도 구할 수 있었다.
chat.py(채팅 분석)
먼저 log 데이터 level칼럼중 'Async Chat Thread'문구가 붙은 내용들이 있었다. 채팅 유형을 분류하는것 같은데 각 숫자 유형마다 어떠한 관계가 있는지 알 수 없었다. 따라서 채팅분석은 간단하게 어떤 유저가 많이 채팅을 했는지 , 또 게임상에서 부여된 뉴비라는 칭호를 가진 유저중 어떤 유저가 가장 많은 채팅을 했는지 확인해 보았고 , 이 순위를 활용해 나중에 최종 유저 랭킹이 계산되게 된다.
기본적으로 채팅은 위와같이 이루어져있다.
def chat_info_fuc():
global chat_df
global chat_df_new
chat_df = df[df['Level'].str.contains('Async Chat Thread')]
extract_user_info(chat_df,lst) # message에서 유저 생성
chat_df_new = chat_df[chat_df['Message'].str.contains('[뉴비]')]
return chat_df,chat_df_new
def chat_info():
top_chat = chat_df['user'].value_counts().head(5)
top_chat_new = chat_df_new['user'].value_counts().head(5)
return top_chat,top_chat_new
유저 분석과 비슷한 방식으로 정규표현식으로 유저를 추출하고 유저에 count순위를 부여했다. 유저별 접속 횟수와 채팅횟수를 시각화해본 결과는 아래와 같다.
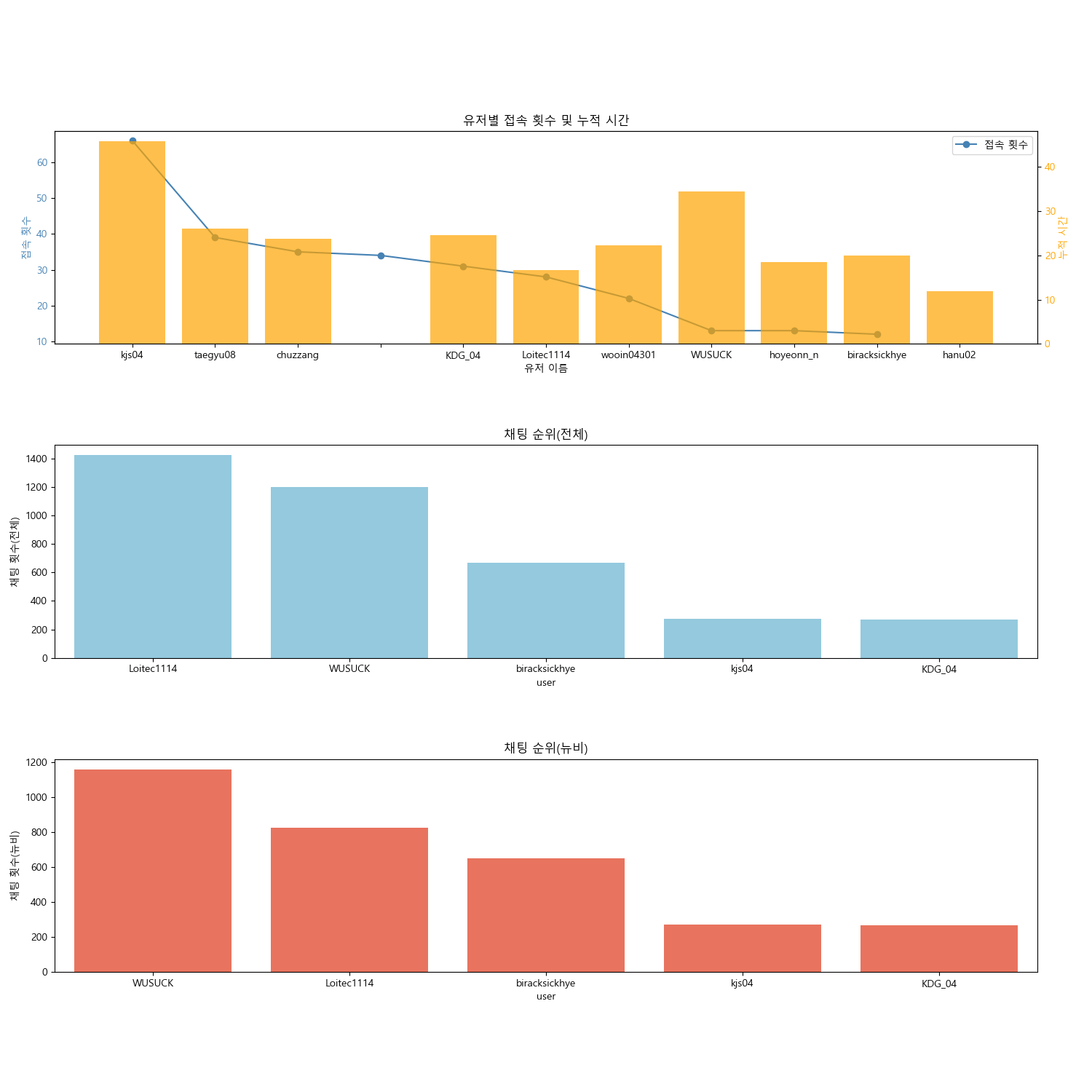
kjs04유저가 압도적으로 많은 접속과 접속시간을 보유했고 , 반면에 채팅은 Loitec114 , WUSUCK 등의 유저가 많이 해주신것을 확인할 수 있었다. 유저 접속 횟수와 누적 접속시간은 어느정도 비례했지만 일부 유저들은 접속 횟수가 적음에도 많은 시간을 투자해주신것을 확인할 수 있었다.
채팅 분석(알고리즘)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
df_chat['talk'] = df_chat['Message'].str.extract(r'>>\s*(.+)')
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(df_chat['talk']) # tf-idf적용
num_clusters = 7
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
kmeans.fit(tfidf_matrix)
df_chat['Cluster'] = kmeans.labels_
order_centroids = kmeans.cluster_centers_.argsort()[:, ::-1]
terms = tfidf_vectorizer.get_feature_names_out()
for cluster_label in range(num_clusters):
print(f"< 클러스터 {cluster_label} 주요 단어 > ")
for ind in order_centroids[cluster_label, :3]: # 상위 5개 단어 출력
print(f" {terms[ind]}")
print("\n")
cluster_messages = df_chat[df_chat['Cluster'] == cluster_label]['talk'].head(5) # 클러스터별 상위 5개 메시지
print(cluster_messages)
print("\n")
print(f'{cluster_label} 군집 level value_counts')
print("\n")
print(df_chat[df_chat['Cluster'] == cluster_label]['Level'].value_counts())
print("\n")채팅분석을 다양한 방법으로 시도해보기 위해 TfidfVectorizer로 벡터화 시키고 비지도학습 알고리즘중 Kmeans를 활용해 단어를 분류해보았다.

그 후 위와같이 클러스터별 워드 클라우드를 그려보았는데 클러스터마다 명확한 특징을 찾지는 못했다.

또한 30분안에 이탈한 유저들의 채팅의 특성을 분석하기 위해 토큰화를 하고 모두 합쳐 빈도수를 워드클라우드를 해보았는데 큰 특징을 찾지는 못했다.
구매 , 판매 분석
게임 이용자가 상점에서 물건을 구매하거나 , 물건을 파는 기록이 모두 로그에 남는다. 어떤 상품을 많이 사고 ,파는지 / 또 유저별로 어떠한 상품이 많이 구매,판매되는지 분석해보았다. 실제로 서버 오픈 중간에 로그를 한번 local에 다운받아 분석해 사용자가 비정상적으로 판매를 통해 돈을 버는것들을 확인할 수 잇었고 , 게임 내부 가격조정을 하는데도 잠깐 사용되었다.
구매 분석
# db에서 불러온 lst에 해당하는 이름만 lst에 담도록 구현 #
def extract_user_info(df, lst):
extracted = []
for message in df['Message']:
for ltem in lst:
if ltem in message:
extracted.append(ltem)
break
else:
extracted.append(' ')
df['user'] = extracted
return df
def buy_df_func():
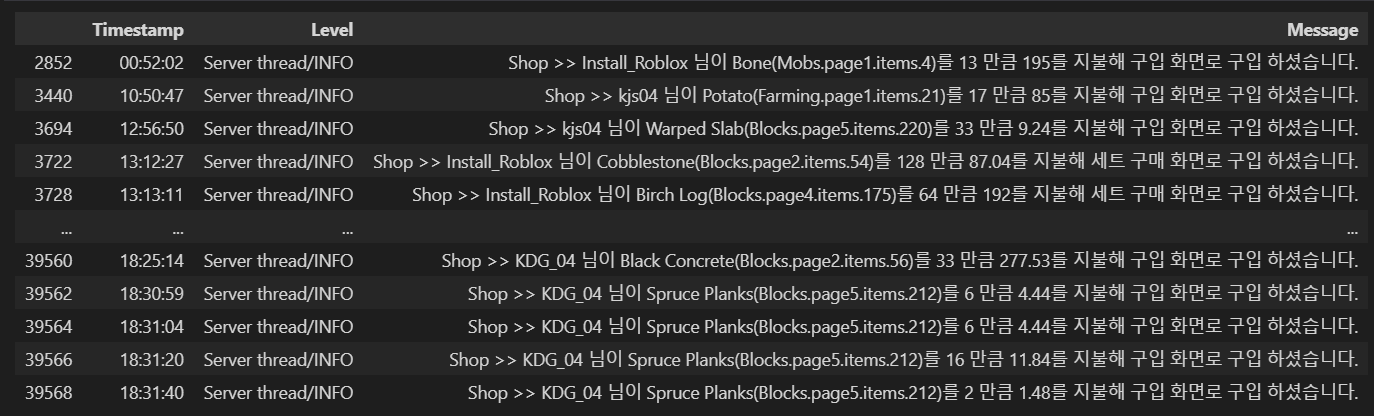
buy_df = df[df['Message'].str.contains('구입')].copy()
buy_df['Item'] = buy_df['Message'].str.extract(r'님이 ([^(]+)') # 님이 이후에 괄호를 뺀 모든 문자열 (아이템명)
buy_df['Count'] = buy_df['Message'].str.extract(r'(\d+) 만큼') # 만큼 전 숫자 (몇개 샀는지)
buy_df['cost'] = buy_df['Message'].str.extract(r'(\d+)를') # 를 전 숫자 (총 얼마인지)
buy_df["category"] = buy_df["Message"].str.findall(r"\((.+?)\.") # 몇개 샀는지
buy_df["category"] = buy_df["category"].apply(lambda x: ', '.join(x))
buy_df = buy_df.astype({'Count': int, 'cost': int})
buy_df = buy_df.reset_index().drop('index',axis=1)
extract_user_info(buy_df,lst) # 유저 만 추출
return buy_df
이 과정은 대부분 정규표현식으로 진행했다. 먼저 '구입'이라는 단어가 들어간 log만 추출하고 정규표현식을 통해 아이템 , 구매 개수 , 구매 금액만 추출해 각각 칼럼으로 만들었다. 또한 이전 load에서 가져온 db정보에서 유저들의 이름만 lst로 반환시켜 그 정보에 해당하는 부분만 추출하는 로직을 통해 '유저 칼럼'으로 만들어 유저 이름도 추출할 수 있었다.
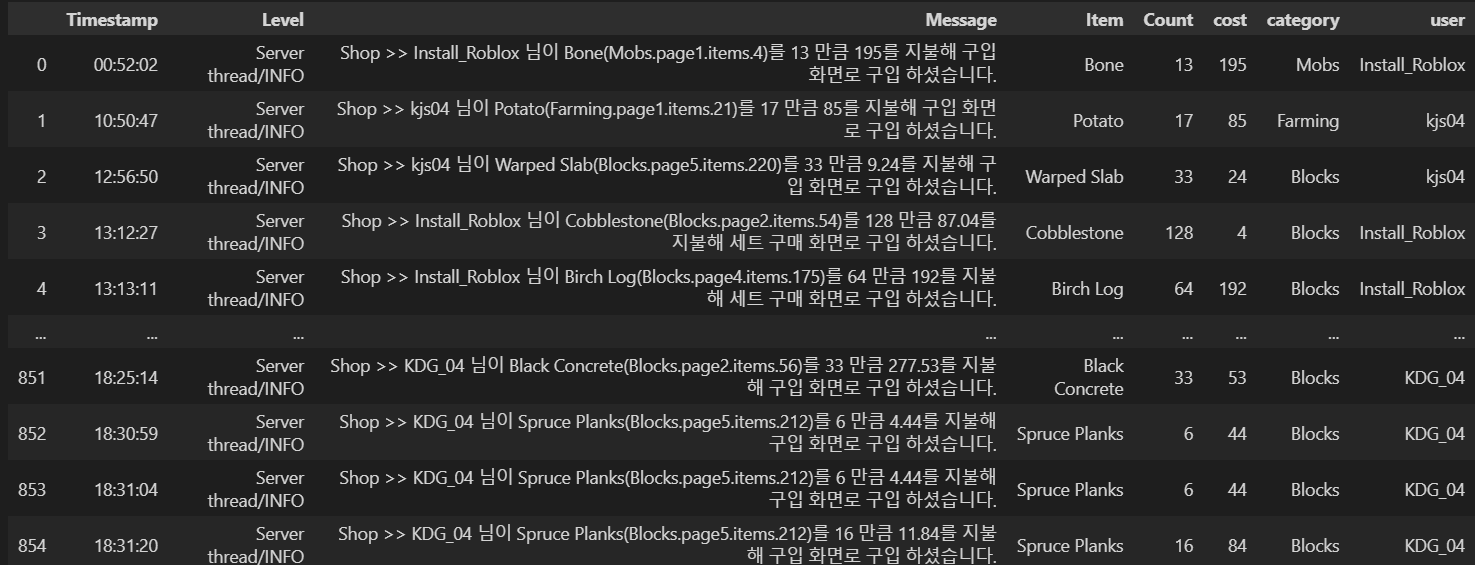
위와같이 잘 추출된 데이터를 통해 가장 많이 산 아이템 , 많이 산 카테고리 , 가장 많이 산 카테고리 , 유저 구매량 , 유저별 많이 산 카테고리 , 유저별 많이 산 아이템 등을 확인 할 수 있었다. 보는것은 막대그래프가 가장 편하므로 막대그래프로 시각화 했다.
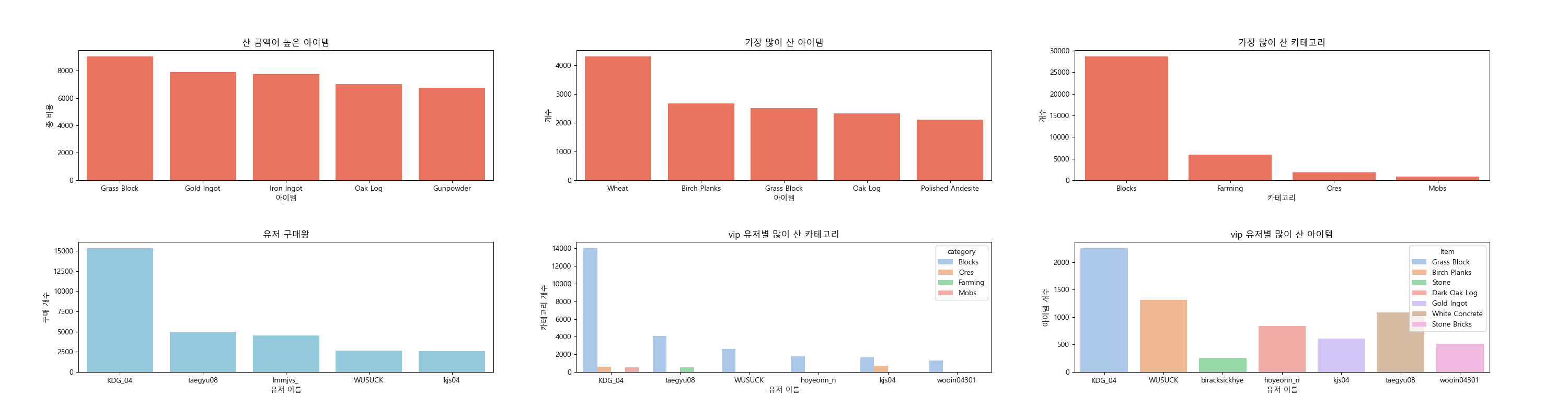
유저별 많이 산 카테고리,아이템를 통해 유저의 플레이스타일을 확인 할 수 있었고 , 유저별 구매 빈도를 통해 구매시스템을 많이 이용해 준 유저들을 확인할 수 있었다. 위에서 접속을 가장 많이 해주신 KDG_04 유저가 가장 많은 구매를 해주셨다
또한, 누적시간 상위 10명의 유저를 vip로 지정하고 이 유저들의 구매를 보았다. 대부분 block에 돈을 많이 사용했지만 block안에서 세부 아이템을 보면 유저별로 구매 스타일이 많이 다른것으로 보아 각자 추구하는 컨텐츠가 다르다고 추측할 수 있었다. 서비스 중간에 이 데이터를 분석했다면 유저들을 관리하는데 좋은 지표가 될 수 있었을텐데 조금 아쉽다..
판매 분석
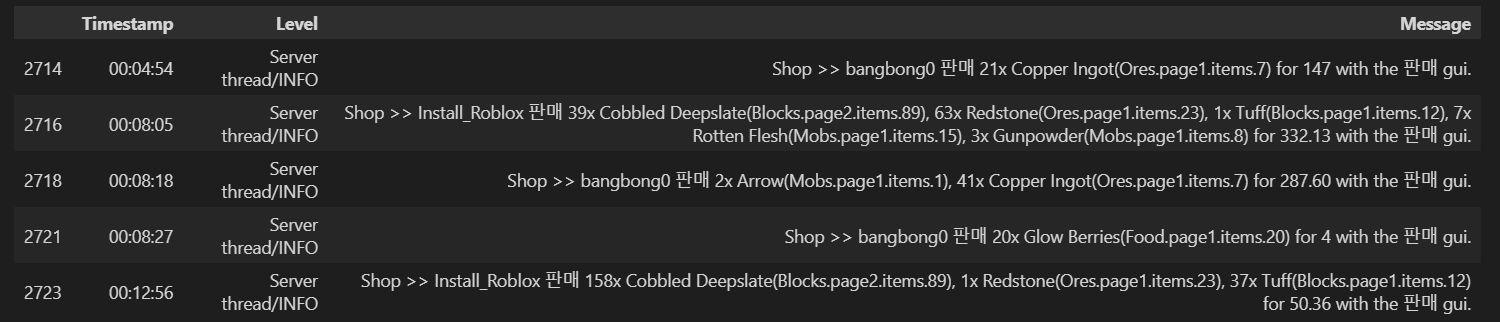

판매분석은 조금 까다로웠다. 구매와는 달리 유저가 판매를 하는 방법에는 상점gui를 통한 판매 , npc를 통한 직접판매 총 두가지가 있었고 , gui로 판매시 한번에 판매가 가능했기에 , 두 판매방식에 로그가 다르게 쌓였다. 따라서 따로 전처리를 진행했어야 했다.
def sell_df_multi_func(): # 한번에 여러상품 판경우
sell_df_multi = df[df['Message'].str.contains('판매 gui')]
sell_df_multi = sell_df_multi[~sell_df_multi['Message'].str.contains('챗')] # 이상치 제거
sell_df_multi['item'] =
sell_df_multi['Message'].str.extractall(r'(\d+x\s([\w\s]+)\(.*?\))')[1].groupby(level=0).apply(list) # 여러개일수도 있으므로(아이템명)
sell_df_multi['item'] = sell_df_multi['item'].apply(lambda x: ', '.join(x) if isinstance(x, list) else x)
sell_df_multi['cost'] = sell_df_multi['Message'].str.extract(r'for (\d{1,3}(?:,\d{3})*(?:\.\d+)?)') # 총 비용
sell_df_multi['cost'] = sell_df_multi['cost'].str.replace(',', '').astype(float)
sell_df_multi["category"] = sell_df_multi["Message"].str.findall(r"\((.+?)\.") # 카테고리
sell_df_multi["category"] = sell_df_multi["category"].apply(lambda x: ', '.join(x)) # 여러개일수도 있으므로
sell_df_multi = sell_df_multi.reset_index().drop('index',axis=1)
return sell_df_multi
def sell_df_one_func(): # 한번에 한종류 상품 판경우
sell_df_one = df[df['Message'].str.contains('판매 하셨습니다')].copy()
sell_df_one['item'] = sell_df_one['Message'].str.extract(r'님이 ([^(]+)') # 아이템명
sell_df_one['cost'] = sell_df_one['Message'].str.extract(r'(\d+)를') # 총 얼마인지
sell_df_one['cost'] = sell_df_one['cost'].astype(float)
sell_df_one["category"] = sell_df_one["Message"].str.findall(r"\((.+?)\.") # 카테고리
sell_df_one["category"] = sell_df_one["category"].apply(lambda x: ', '.join(x)) # 여러개일수도 있으므로
sell_df_one = sell_df_one.reset_index().drop('index',axis=1)
return sell_df_one먼저 동시판매와 단일판매를 나누었다. 이후 , 두 판매모두 정규표현식을 통해 item , cost , category를 추출해냈고 , 동시판매의 경우 item에 여러 item이 들어간것을 확인할 수 있다. 동시판매 logit에서 여러 아이템들만 추출하는 부분이 힘들었는데 이 부분은 gpt에 도움을 받았다.
def shop_all_func():
global buy_df
global sell_df_multi
global sell_df_one
global sell_df
buy_df = buy_df_func()
sell_df_multi = sell_df_multi_func()
sell_df_one = sell_df_one_func()
sell_df = pd.concat([sell_df_multi,sell_df_one])
sell_df['item'] = sell_df['item'].str.replace(',\s*', ',', regex=True) # 공백제거
sell_df['category'] = sell_df['category'].str.replace(',\s*', ',', regex=True) #공백제거
extract_user_info(sell_df_one,lst)
extract_user_info(sell_df_multi,lst)
extract_user_info(sell_df,lst)
return buy_df , sell_df_multi , sell_df_one , sell_df이후 판매데이터를 하나로 합치고 구매와 같이 user이름을 추출한 후 가장 많이 판매한 아이템,카테고리 / 유저별 판매현황등을 구매와 비슷하게 시각화 했다. 여기서 구매와 다르게 count칼럼을 따로 만들지 않은 이유는 분리된 판매데이터를 합치고 Counter함수로 세는것이 더 효율적이라 판단했다. 따라서 유저별 판매개수 현황을 구할때 Counter함수를 통해 구하는 logit을 따로 해주었다.
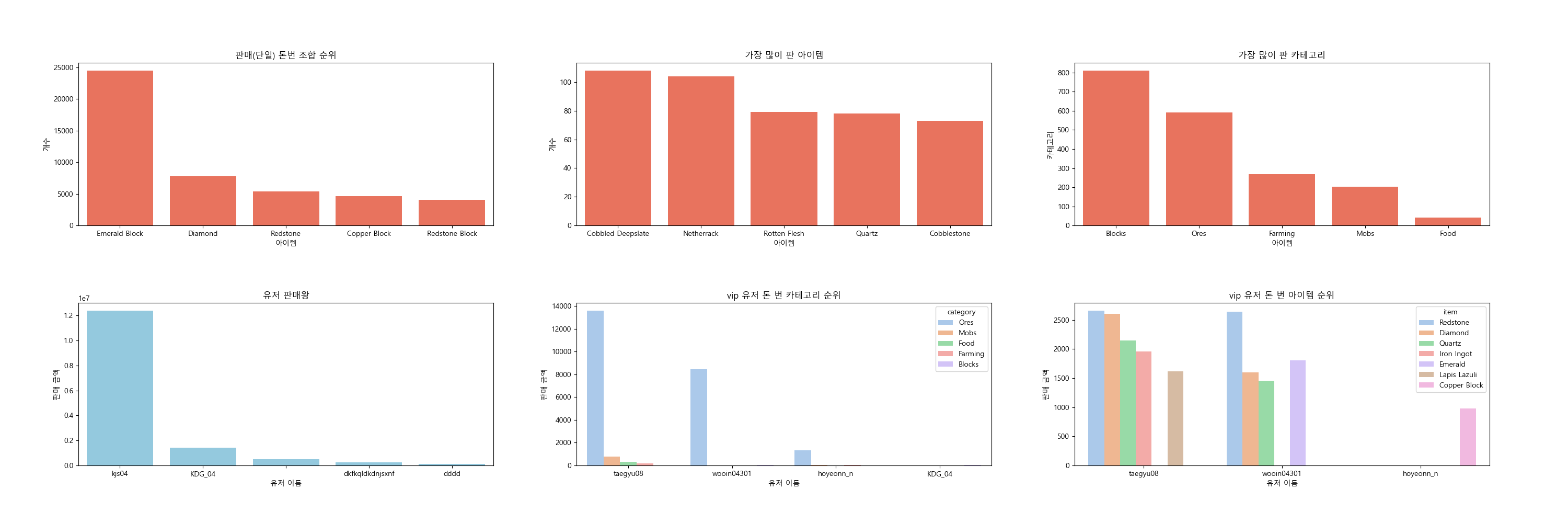
유저들은 보통 Blocks 중 Emerald Block , ores중에 diamonds를 통해 큰 재화를 획득했으며 반면에 많이 판 아이템은 cobbled deepslate , Netherack등이었다. 이 결과로 cobbled deepslate , Netherack같은 item들은 획득하기가 쉽고 / diamonds,Emerald Block들은 획득대비 큰돈을 벌 수 있다는 점을 유추해 볼 수 있다. 역시 가장 많은 플레이를 해주신 kjs04유저분이 압도적으로 많은 판매량을 보였다. 감사합니다 ..!
또한 가장 많이 판매된 카테고리는 Blocks지만 vip유저들은 주로 Ores를 팔아 재화를 획득한것을 알 수 있다
랭킹
앞서 산출한 유저 채팅 , 유저 누적 시ㅏ간 , 유저 상점 이용률의 순위를 유저별로 산출해 점수화시켜 최종 점수 순위를 뽑아냈다.
def rank_all():
max_rank=200
buy_grouped = buy_df.groupby('user')['cost'].sum().reset_index(name='누적 구매 금액')
sell_grouped = sell_df.groupby('user')['cost'].sum().reset_index(name='누적 판매 금액')
# 순위 매기기
buy_grouped['buy_rank'] = buy_grouped['누적 구매 금액'].rank(ascending=False)
sell_grouped['sell_rank'] = sell_grouped['누적 판매 금액'].rank(ascending=False)
buy_grouped['buy_score'] = max_rank - buy_grouped['buy_rank']
sell_grouped['sell_score'] = max_rank - sell_grouped['sell_rank']
# shop 순위까지 계산
merged_df = pd.merge(buy_grouped, sell_grouped, on='user', how='outer').fillna(0)
merged_df['shop_rank'] = merged_df['buy_rank'] + merged_df['sell_rank']
merged_df['shop_score'] = max_rank - merged_df['shop_rank']
# time 순위까지 계산
m_df = pd.merge(time_df, merged_df, on='user', how='left').fillna(0)
# chat 순위까지 계산
chatt_df = chat_df[['user','chat']]
chat_rank_df = pd.DataFrame(chatt_df['user'].value_counts().rank(method='min', ascending=False)).reset_index()
final_rank_df = pd.merge(m_df, chat_rank_df, on='user', how='left')
final_rank_df = final_rank_df.rename(columns={'count': 'chat_rank'}).fillna(200)
final_rank_df['chat_score'] = max_rank - final_rank_df['chat_rank']
final_rank_df['final_score'] = final_rank_df['shop_score'] + final_rank_df['chat_score'] + final_rank_df['time_score']
final_rank_df['final_rank'] = final_rank_df['final_score'].rank(ascending=False, method='min')
return final_rank_df
if __name__ == "__main__":
rank_all()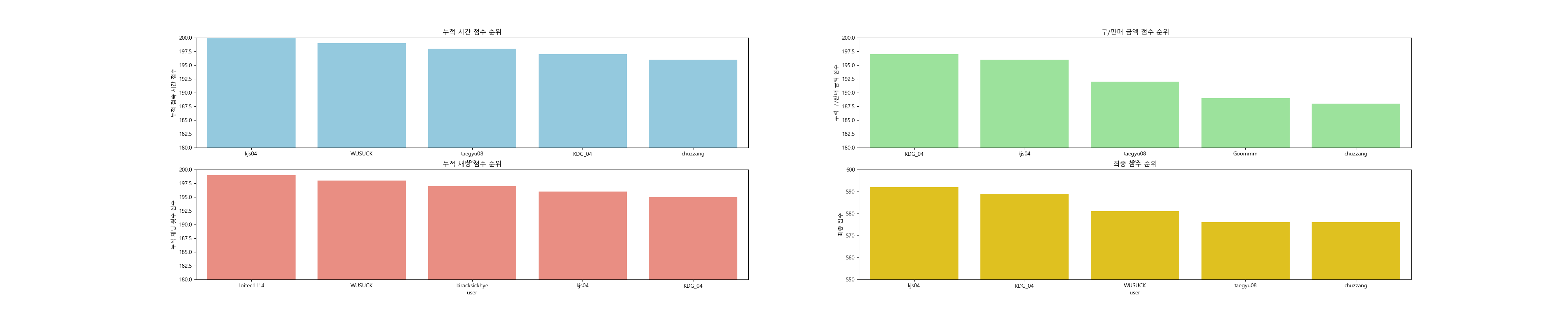
위와같이 kjs04 , KDG_04분들 순서로 우리 서버에 공을 많이 들여주었다.
고찰
3개월동안 열심히 달려왔던 프로젝트가 마무리 되었다.
서로의 실력도 제대로 모르고 3명다 개발을 전문적으로 하는 인력이 아닌 학생이었기에 , 서버를 준비하는 과정속에 정말 많은 시행착오가 있었다.
많이 미숙하지만 다행히 원하는 목표인 서버 오픈을 잘 할 수 있었고 , 너무나도 고맙게도 200명에 유저들이 우리 서버를 방문해주었다. 운영을 하면서 너무 재밌다고 하는 유저들의 채팅 , 다양한 고마운 피드백들을 보면서 기존 개발과는 다른 뿌듯함을 느낄 수 있었다.
프로젝트를 돌아보면서 느꼈던 점은 다음과 같다.
느낀점
단순한 서비스라도 복잡하다
지금까지 프로젝트는 단순하게 데이터와 인공지능 기술을 활용한 아이디어를 local환경에서 데모버전까지 구현한 프로젝트가 많았다. 하지만 안정정있게 서비스 운영까지 해야하는 프로젝트를 하면서 하나의 서비스가 만들어지기 위해 많은 과정이 필요하다는점을 느꼈고 , 다양한 인프라환경 세팅을 경험 할 수 있었다.
운영은 힘들다..
많은 시간을 투자해 개발하고 테스트를 해보았기에 운영에 큰 시간을 쓰지 않을줄 알았다. 하지만 , 생각과는 달리 유저들이 끊임없이 들어오면서 생기는 다양한 돌발 상황이 있었고 , 3명에서 즉각적으로 빠르게 대처를 하기 위해서는 실시간 모니터링과 새로운 개발은 필수였다. 이 과정을 직접 경험해보면서 기획의 중요성과 , 서비스 운영을 위해서는 많은 노력이 필요하다는것을 느꼈다.
기본에 충실하자
이번 프로젝트를 진행하면 내 기본기가 많이 부족하다는것을 느꼈다. db테이블 데이터를 다루기 위한 쿼리,python전처리등 충분히 많이 해봤다고 생각했는데 생각보다 코드를 짜는게 쉽지않았다. 또한 , 로그 데이터가 주어졌을때 어떠한 분석 방법론과 인공지능 기술을 활용해야할지 바로 떠오르지않았다. 이 부분은 많은 연습과 , 경험이 더 필요한것 같다.
마무리
이제 4만개의 실제 데이터가 있으니 이 데이터를 가지고 지금까지 배웠던 다양한 시도들을 해 볼 예정이다. 좋은 경험을 만들기위해 고생한 팀원들과 , 서버에서 게임을 재밌게 즐겨준 유저들 너무 감사합니다.
