시작
이번 포스팅은 이론으로 포스팅 했던 내용들을 실습 해보겠다. 텍스트 전처리 , word2vec 방법중 cbow 등을 python으로 실습하는 포스팅을 해보겠다.
NLP 전처리
토큰화
텍스트 데이터를 토큰 단위로 나누는것이다.
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
text = "Model-based RL don't need a value function for the policy."
print(tokenizer.tokenize(text))
from nltk.tokenize import word_tokenize
print(word_tokenize(text))
토큰화를 하는 방법은 다양하게 있고 , 기본적으로 nltk에서 제공하는 TreebankWordTokenizer 와 word_tokenize으로 text문장을 토큰화 해보았다. 결과는 아래와 같이 비슷한것을 확인 할 수 있다.

정제 및 추출
from nltk.stem import PorterStemmer, LancasterStemmer # 표제어 추출
stem1 = PorterStemmer()
stem2 = LancasterStemmer()
words = ["eat", "ate", "eaten", "eating"]
print("Porter Stemmer :", [stem1.stem(w) for w in words])
print("Lancaster Stemmer:", [stem2.stem(w) for w in words])
from nltk import WordNetLemmatizer # 시제를 동사 원형으로 바꿔줌(품사테깅 할때 좋다)
lemm = WordNetLemmatizer()
words = ["eat", "ate", "eaten", "eating"]
print("WordNet Lemmatizer:",[lemm.lemmatize(w, pos="v") for w in words])
불용어 제거
text = "Model-based RL don't need a value function for the policy."
nltk.download('punkt')
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(text)
result = []
for w in word_tokens:
if w not in stop_words:
result.append(w)
print('token화만 했을때 ' ,word_tokens)
print('불용어까지 했을때',result)자주 쓰이지 않는 필요없는 단어들을 제거하는 과정을 불용어 제거라고 하며 , 결과는 아래와 같이 for,a,the등이 지워진것을 볼 수 있다.

정수 인코딩
# 딕셔너리가 주어진 상태에서는 간단함 #
vocab = {'apple': 2, 'July': 6, 'piano': 4, 'cup': 8, 'orange': 1}
vocab_sort = sorted(vocab.items(), key = lambda x:x[1], reverse = True) # 빈도수 순위로 리스트
print(vocab_sort)
word2inx = {word[0] : index + 1 for index, word in enumerate(vocab_sort)} # 단어별 인덱스
print(word2inx)

# 문장이 주어졌을때 정수 인코딩을 하는 방법 #
from nltk.tokenize import TreebankWordTokenizer
tokenizer = TreebankWordTokenizer()
text = "Model-based RL don't need a value function for the policy, " \
"but some of Model-based RL algorithms do have a value function."
token_text = tokenizer.tokenize(text)
word_counts = {} # 단어별 빈도수 딕셔너리
for word in token_text:
if word in word_counts:
word_counts[word] += 1
else:
word_counts[word] = 1
sorted_word_counts = sorted(word_counts.items(), key=lambda x: x[1], reverse=True) # 빈도수 기준으로 단어 정렬해 직접만들기
print('직접 만들기 :',dict(sorted_word_counts))# 기존에 알던 패키지(Counter)를 사용하는 방법 #
from collections import Counter
text = "Model-based RL don't need a value function for the policy, " \
"but some of Model-based RL algorithms do have a value function."
token_text = ' '.join(tokenizer.tokenize(text))
word_counter = Counter(token_text.split(' ')) # 단어별 빈도수 딕셔너리 생성
print('counter사용 :',word_counter)딕셔너리가 아닌 문장으로 주어졌을때 문장의 빈도수를 세는 방법이랑 , 기존에 알던 방식인 Counter방식을 활용했을때 차이를 비교해보았다. 두 방법 같은 결과가 나온것을 확인 할 수 있다.

유사도(Similarity)
## 코싸인 유사도 ##
import numpy as np
def cos_sim(A, B):
return np.dot(A, B) / (np.linalg.norm(A)*np.linalg.norm(B)) # 내적/절댓값곱
a = [1,0,0,1]
b = [0,1,1,0]
c = [1,1,1,1]
print(cos_sim(a,b), cos_sim(b,c), cos_sim(c,a))
## 레벤슈타인 거리 ##
def leven(text1, text2):
len1 = len(text1) + 1
len2 = len(text2) + 1
sim_array = np.zeros((len1, len2))
sim_array[:,0] = np.linspace(0, len1-1, len1)
sim_array[0,:] = np.linspace(0, len2-1, len2)
for i in range(1,len1):
for j in range(1,len2):
add_char = sim_array[i-1,j] + 1
sub_char = sim_array[i,j-1] + 1
if text1[i-1] == text2[j-1]:
mod_char = sim_array[i-1,j-1]
else:
mod_char = sim_array[i-1,j-1] + 1
sim_array[i,j] = min([add_char, sub_char, mod_char])
max_dist = max(len1, len2)
return 1 - sim_array[-1,-1] / max_dist
# 예시
print(leven('데이터마이닝', '데이타마닝'))
두 방법 모두 유사도를 계산하는 방법이며 , 결과는 아래와같다.

Word2vec - cbow

위와 같이 이루어진 데이터셋으로 활용해서 앞서 포스팅한 cbow를 진행해보자 . cbow는 word2vec방법중하나로 주변단어로 중심 단어를 예측하는 방법이다.
# 데이터 불러오기
data = pd.read_csv('transcripts.csv')
merge_data = ''.join(str(data.iloc[i,0]) for i in range(30))
print('Total word count: ', len(merge_data)) # str데이터 내용 join으로 합치기(전처리를 위해)
## 토크나이저
tokenizer = RegexpTokenizer("[\w]+")
token_text = tokenizer.tokenize(merge_data)
#불용어 제거
stop_words = set(stopwords.words('english'))
token_stop_text = []
for w in token_text:
if w not in stop_words:
token_stop_text.append(w)
print('After cleaning :', len(token_stop_text))
print(token_stop_text[:10])
# cbow를 활용 #
token_stop_text = np.reshape(np.array(token_stop_text),[-1,1]) # 모델에 넣기 위해서 reshape
print(token_stop_text)
from gensim.models import Word2Vec
#양옆에5개보고 , 2개이하는 버리자 , 100차원 , cbow는 sg=0
model = Word2Vec(vector_size = 100, window = 5, min_count = 2, sg = 0)
model.build_vocab(token_stop_text)
model.train(token_stop_text, total_examples = model.corpus_count, epochs = 30, report_delay = 1)
vocabs = model.wv.key_to_index.keys()
word_vec_list = [model.wv[i] for i in vocabs]
print('100차원으로 embedding:',word_vec_list[:10]) # 각 단어마다 100차원으로 ebedding
# pca를 통한 차원 축소 시각화 (100차원 -> 2차원) # 고차원 축소
from sklearn.decomposition import PCA
pca = PCA(n_components = 2)
pcafit = pca.fit_transform(word_vec_list)
x = pcafit[0:50,0]
y = pcafit[0:50,1]
import matplotlib.pyplot as plt
plt.scatter(x, y, marker = 'o')
for i, v in enumerate(vocabs):
if i <= 49:
plt.annotate(v, xy = (x[i], y[i]))
plt.show()아래 그림처럼 2차원상에 나타내서 단어들을 보면 근처에 있을수록 비슷한 의미의 단어들인데 , model이 그렇게 정확하지는 않은것들 확인 할 수있었다.
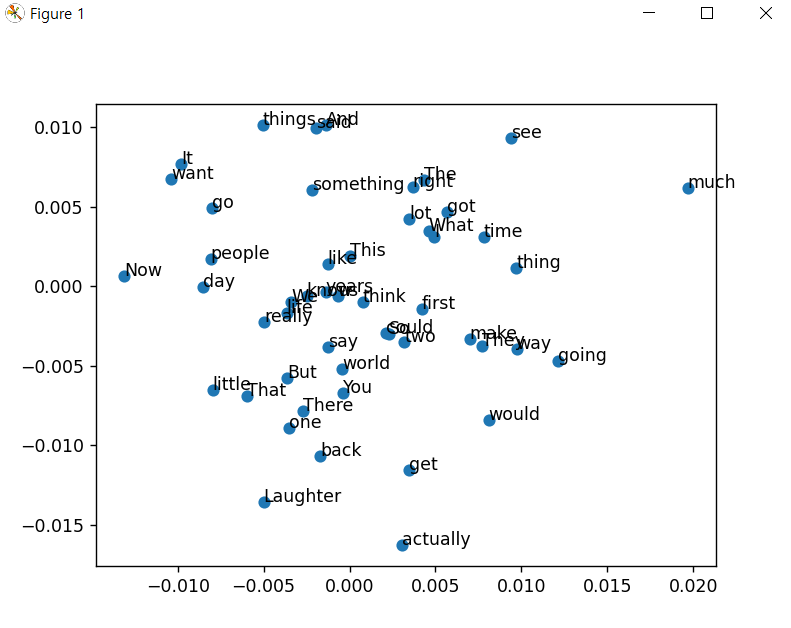
많이 안해봤거나 생소한 개념들을 다뤄보면서 다소 어렵기도 했지만 점점 적응해가면서 익숙해지고있다 . 저번에 포스팅했던 SGNS에 대한 모델구현 코드도 있었지만 pytorch와 딥러닝 구조에 익숙하지 않아 공부후에 다시 다뤄보겠다. 해야할게 너무 많은 공부 ... 파이팅 !
메타코드 공식 사이트 : https://mcode.co.kr/
강의 유튜브 링크 : https://www.youtube.com/watch?v=Rf7wvs8ZbP4
