시작
이번에는 크롤링에 대해 공부해보겠다. 데이터를 다루는 사람에게는 어떻게 보면 크롤링을 필수 스킬이다. 이전에 부트캠프에서 잠깐 크롤링을 해본적이 있는데 , 기억이 가물가물해 이번 기회에 공부도 할겸 정리해 보려고 한다.
Web Crawling Process
웹 페이지에서 크롤링을 통해 데이터를 가져오는 과정은 크게 3가지로 나뉜다 . 첫번째는 requests로 HTML 즉 , 웹페이지 구조를 가지고오고 , Beautifulsoup이라는 파이썬 라이브러리를 활용해 우리가 처리하기 쉽도록 HTML문서를 파싱한다. 이후 필요한 정보를 추출하는 다양한 메서드를 사용해 원하는 요소를 선택해 저장한다.
1. requests
python requests 를 사용하면 웹과 쉽게 통신할 수 있다. requests를 통해 웹에게 요청을 하게되면 웹에서 상태코드 , 헤더 정보등 다양한 정보를 응답해주게 된다. 아래와 같이 200상태코드는 요청이 성공적으로 처리되었다는 상태를 나타내고 , 200말고도 201,301,404,403등등 다양한 응답 상태가 있다. 자세한건 아래 사이트에서 확인 할 수 있다. https://developer.mozilla.org/ko/docs/Web/HTTP/Status
import requests
url = 'https://www.google.com'
response = requests.get(url)
print(f"상태 코드: {response.status_code}")
print(f"헤더 정보: {response.headers}")
print(f"HTML 내용: {response.text}")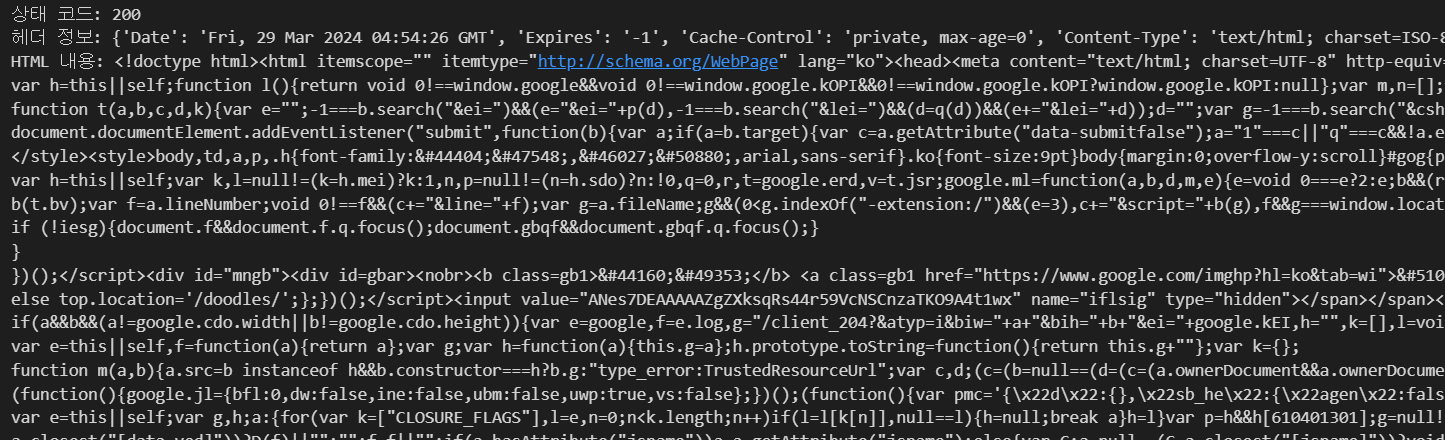
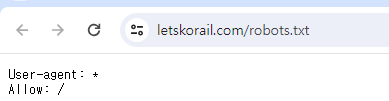
우선 크롤링을 하기전에 '사이트/robots.txt'를 통해 크롤링이 가능한지 먼저 확인해야한다. 예를들면 렛츠 코레일 사이트를 크롤링하고 싶으면 letskorail.com/robots.txt를 입력해 나오는 결과를 보고 크롤링을 해야한다. 아래와 같이 *는 모든 권한을 의미한다. 사이트마다 크롤링을 못하게 한다던가 , 특정 페이지만 크롤링 가능하게 한다던가 각각 다르니 시작전에 확인하고 해야한다.
2.beautiful soap
beautiful soap 라이브러리를 통해 응답받은 html을 파싱하고 여기서 아래와 같이 원하는 요소들을 꺼낼 수 있다.
<예시 html>
html_doc = '''
<html>
<head>
<title>BeautifulSoup Example</title>
</head>
<body>
<h1>Web Crawling Process</h1>
<p>1.requests : 웹 페이지의 HTML을 가져오는 역할</p>
<p>2.Beautifulsoup : HTML 문서 파싱을 도와준다.</p>
<p>3.원하는 요소를 선택한다.</p>
</body>
</html>from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser') # soap선언
title = soup.title
heading1 = soup.h1
paragraph = soup.p
print(title , heading1 , paragraph)
또한 하나의 태그안에 있는 내용을 모두 가져오고 싶을때는 find_add을 사용하면 된다. 여기서 .text를 추가하면 텍스트 내용만 볼 수 있다.
paragraph_all = soup.find_all('p')
print(paragraph_all)
print(paragraph_all[0].text)
위를 활용해 아래와 같이 주소를 입력하고 원하는 태그를 가져와 변수에 저장하고 리스트에 추가해 데이터프레임으로 만드는 간단한 로직이다. 동적이지 않은 정적인 사이트에서는 아래와 같은 로직으로 쉽게 가져올 수 있다.
url_list = []
title_list = []
body_list= []
urls = ['https://news.kbs.co.kr/news/pc/view/view.do?ncd=7898519',
'https://news.kbs.co.kr/news/pc/view/view.do?ncd=7898517'
]
for url in urls:
html_doc = requests.get(url).text
soup = BeautifulSoup(html_doc, 'html.parser')
title = soup.find('h4', class_='headline-title').text
body = soup.find('div', class_='detail-body font-size').text
url_list.append(url)
title_list.append(title)
body_list.append(body)
data = {'뉴스url':url_list, '제목':title_list, '내용':body_list}
df = pd.DataFrame(data)
df.to_csv('news12_kbs_same.csv', index=False)3.Selenium
위에서는 정적인 웹에서 크롤링 하는방법을 알아봤다. 정적 페이지는 서버로부터 한 번 요청하면 변하지 않는 형태의 HTML로 작성된 페이지로 미리 만들어놓은 HTML파일이 변하지 않기 때문에 Requests + Beautifulsoup 으로 충분히 가져올 수 있다.
문제는 동적인 페이지이다. 대부분의 웹은 동적 페이지로 이루어져있으며 동적 페이지는 웹 서버로부터 HTML을 받아온 다음 브라우저가 해석하고 실행하면서 javascript같은 스크립트 언어를 사용한다. 이 경우에는 Selenium이라는 라이브러를 사용해서 가져와야 한다. Selenium은 웹 페이지를 자동으로 제어, 테스트할 수 있는 도구로 직접적으로 웹 브라우저를 제어한다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://news.kbs.co.kr/news/pc/category/category.do?ref=pSiteMap#20240228&1'
html_doc = requests.get(url).text
soup = BeautifulSoup(html_doc, 'html.parser')
box_contents = soup.find_all('a', class_='box-content flex-style')
print(box_contents)
위 코드처럼 동적인 사이트에서 Beautifulsoup만 사용하면 내용을 잘 가져오지 못하고 빈 리스트를 반환하게 된다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
# Selenium으로 웹 드라이버를 실행
service = Service(executable_path=ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# url 전달
url = 'https://news.kbs.co.kr/news/pc/category/category.do?ref=pSiteMap#20240228&1'
driver.get(url)
# 기다려달라는 값을 전달 : 최대 10초 기다리기
wait = WebDriverWait(driver, 10)
# 드라이버 접근 > 페이지 소스 가져오기
html = driver.page_source
# 드라이버 종료
driver.quit()
soup = BeautifulSoup(html, 'html.parser')
box_contents = soup.find_all('a', class_='box-content flex-style')
print(box_contents)위 코드는 직접 크롬 브라우저를 키고 html소스를 잘 가져온다.
원하는 사이트에서 페이지를 넘기면서 넘겨진 페이지에 있는 내용들을 가져와 데이터프레임으로 만들기 위해서는 아래와같이 간단하게 코드를 작성할 수 있다.
url_list=[]
title_list=[]
body_list=[]
date_list=[]
service = Service(executable_path=ChromeDriverManager().install())
for page_num in range(1,14):
driver = webdriver.Chrome(service=service)
url = f'https://news.kbs.co.kr/news/pc/category/category.do?ref=pSiteMap#20240228&{page_num}'
driver.get(url)
wait = WebDriverWait(driver, 10)
# 드라이버 접근 > 페이지 소스 가져오기
html = driver.page_source
# 드라이버 종료
driver.quit()
# Beautifulsoup 사용해서 파싱하고, 태그들을 찾아서 담아줌
soup = BeautifulSoup(html, 'html.parser')
box_contents = soup.find_all('a', class_ = 'box-content flex-style')
# 박스 데이터들을 하나씩 돌면서 리스트에 데이터를 담음
for box_content in box_contents:
url = "http://news.kbs.co.kr" + box_content['href']
title = box_content.find('p', class_='title').text
body = box_content.find('p', class_='news-text').text
date = box_content.find('span', class_='date').text
url_list.append(url)
title_list.append(title)
body_list.append(body)
date_list.append(date)
# 데이터 저장
data = {'뉴스url':url_list, '제목':title_list, '내용':body_list, '날짜':date_list}
df = pd.DataFrame(data)
df.to_csv('news_kbs_pagenation.csv', index=False) 
이번 포스팅에서는 간단하게 웹 크롤링하는 방법에 대해 적어보았다. 메타코드 강의 덕분에 조금 더 쉽게 크롤링을 배울 수 있어 감사하다. 이제 이 기술들을 가지고 원하는 데이터를 가져 오는것을 다음 포스팅에서 다뤄보겠다.
메타코드 공식 사이트 : https://mcode.co.kr/
강의 유튜브 링크 : https://www.youtube.com/watch?v=D5m3Ge-dmws
