계기
플레이데이터에서 주관하는 부트캠프 6개월 과정 중 final project로 진행한 프로젝트이다. 우리 팀은 4명으로 구성되었고 기간은 7주 동안 진행했다. 나는 부트캠프에서 배운 내용을 토대로 비정형 데이터를 다루는 프로젝트에 참가하고 싶었고, 따라서 가장 적은 인원이었지만 이미지를 다루는 딥러닝 프로젝트에 도전했다. 주제는 경구약제 여러 개를 이미지를 인식해 어떤 약인지 알려주는 '뭔약이유?' 서비스를 구상했다. 적은 시간에 대규모 이미지를 처리, 학습, 서비스 연결하기에는 분명 도전적인 과제였지만 팀원 모두 최적화와 효율성에 중점을 두고 높은 정확도를 도출해내려고 노력했다.
협업 툴은 소통으로 slack, issue관리 및 code 공유를 위한 github를 활용했다.
git주소 : https://github.com/BrianPark314/final_project
프로젝트 배경 및 목표
배경
- 국민 6명중 1명이 약물 오남용 경험 , 65세 이상 44%가 매일 5개 이상 약 복용
- 약품 처방이 매우 쉽고 많은 수가 전문의약품과 일반의약품을 혼용함
- 여러 약을 혼용했다 부작용을 겪는 사례들이 발생
- 의약품 혼용 금지 조합 및 부작용에 대한 정보 접근성이 떨어짐
목표
핵심적으로 생각한 가치는 정확성과 간편성이다.
의약품에 대한 정보를 제공하는 서비스이므로 약품 인식 및 정보제공이 정확해야 하며 , 어떤 사용자층도 사용할수 있도록 최소한의 동작만으로 정보를 얻을 수 있게 설계하는것이 목표이다.
따라서 사진 촬영 한번으로 혼용 금지 조합과 부작용 정보를 한눈에 정확하게 알려주는 웹 서비스를 구상했다.
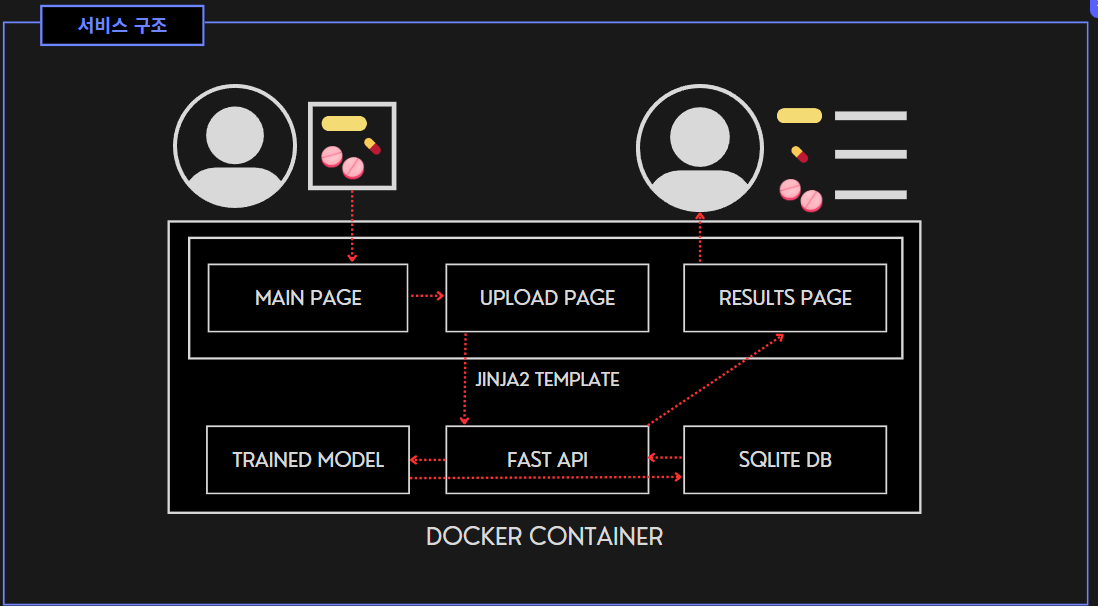
서비스 구조

'뭔약이유?' 서비스 웹은 도커 컨테이너 위에서 FastAPI 기반으로 동작한다. 사용자가 함께 복용하고 싶은 알약을 모아 사진을 찍고 업로드하면 서버가 미리 훈련된 모델에 전달한다. 이후, 모델이 결과를 반환하면 이를 DB에 가지고 있는 정보와 대조하게 되고 결과 페이지를 통해 알약 성분, 주의사항, 부작용 등을 알려주게 된다. 또한 혼용 금지 조합이 있을 경우 경고 문구를 출력하게 된다. 자세한 건 뒤에서 설명하겠다.
활용 데이터
https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=data&dataSetSn=576
메인 데이터는 AI hub에서 제공되는 '경구약제 이미지 데이터'를 활용했다. 5000종의 종류의 경구약제와 250만개 이미지로 이루어져 있으며 총 용량은 4.4TB이다. 여기에 더해 혼용 금지를 알려주기 위한 '혼용 금지 데이터' 약의 성분을 알려주기 위한 'e약은요' 데이터를 추가로 활용했다.
개발 환경 및 파이프라인
처음 설계(GCS사용)

한정된 시간에 좋은 서비스를 만들기 위해 효율적인 개발환경 구축이 필요했다. 컴퓨팅 자원 문제는 google colab pro+를 사용해 학습 , 이와 연동되는 GCS에 이미지를 적재함으로서 해결했다. 이 두 서비스는 컴퓨팅과 I/O에 비례해 비용이 발생하므로 이를 최소한으로 줄이고자 기타 전처리는 모두 local pc에서 실행했다.
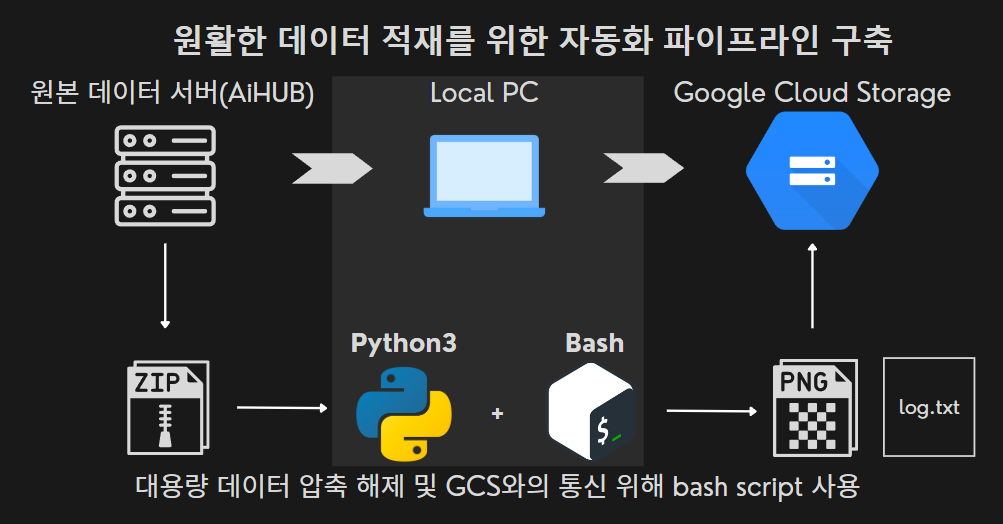
원본 데이터는 100GB로 압축된 80개의 파일로 구성되어 있다. 하지만 GCS는 내부에서 파일을 압축 해제하는 기능을 제공하지 않았으며, 원본 데이터 서버에서 서드 파티 프로그램을 이용하여 파일을 전송하기 때문에 직접적인 적재가 불가능했다. 따라서 서버에서 로컬 PC를 거쳐 GCS에 파일을 적재하는 자동화된 파이프라인을 설계해야 했다.
이 과정에서 우분투 환경에서 파이썬에 비해 압축 해제 속도와 신뢰성이 더 높은 Bash script를 사용했다. 또한 GCS 파일 전송은 무결성이 보장되지 않기 때문에 따로 로그를 기록하여 처리된 파일을 표시했으며, 이를 통해 데이터 무결성을 검증함과 동시에 중복 처리를 없애 자원 낭비를 줄일 수 있었다. 덕분에 효율적으로 시간과 비용을 사용할 수 있었다.
설계 변경(Colab VM사용)
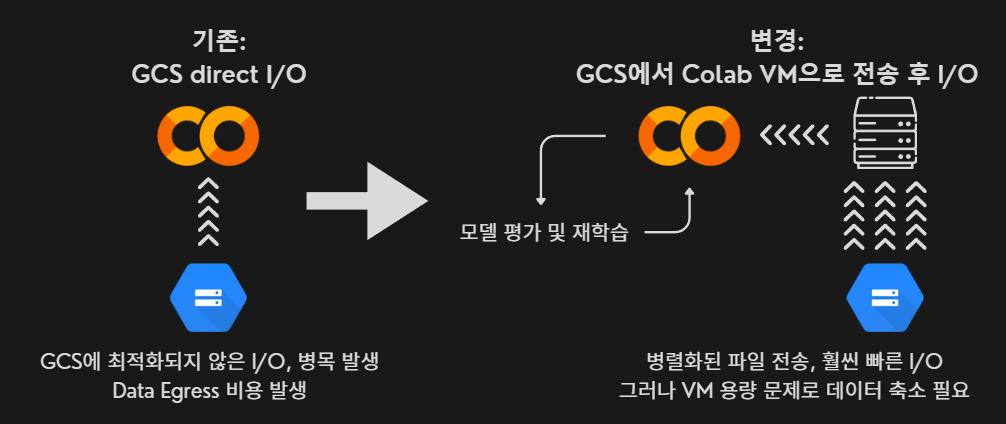
기존 GCS를 테스트하다가 문제가 발생했다. 파일 전송 속도가 너무 느리고, GCS에서 데이터를 egress할 때 비용이 많이 발생했다. 따라서 Colab이 작동하는 리눅스 가상머신에 병렬화된 처리로 파일을 보내고, 그 이후에 모델 학습을 진행하는 방식으로 변경했다. 이에 데이터를 100GB 용량의 가상머신 저장소에 모두 탑재해야 하기 때문에 이미지 용량 축소가 필요했다.
EDA 및 전처리
메인 데이터
이미지 모델에 가장 핵심은 객체 인식이다. 모델이 객체를 정확하게 인식하고 학습해야 정확도가 높은 결과를 도출해 낼 수 있다. 특히 알약의 경우 미세한 차이로 종류나 성분이 바뀌기 때문에 객체 인식을 정확하게 하기 위해 다양한 전처리와 객체 인식 범위인 bounding box를 정교하게 추출해야 했다.
처음에는 직접 bounding box를 추출하려고 시도했다. OpenCV를 활용해 Gaussian blur 등을 통해 필터를 적용해 배경 노이즈를 먼저 제거하고 Otsu 최적화와 윤곽 추출을 통해 자동으로 bounding box를 추출하게끔 시도했다. 하지만 배경을 충분히 제거되지 않아서인지 정확한 윤곽을 추출하지 못했다. 따라서 메타데이터에 포함된 bounding box 정보를 그대로 활용하기로 결정했다.
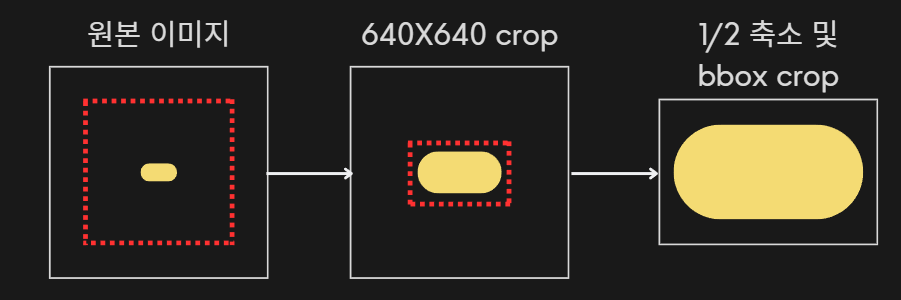
다음으로 컴퓨팅 자원의 한계로 대용량 데이터를 학습을 위해 이미지 데이터 크기를 줄여야 했다. 처음에는 640*640픽셀 크기의 정사각형으로 일괄적인 크롭을 했으나 용량을 충분히 줄이지 못했고 알약별로 이미지에서 차지하는 비중이 달라 알약이 잘리는 문제가 생겼다. 따라서 최종적으로는 가장 오른쪽과 같은 방법을 선택했다. 이미지를 1/2 resize하고, bounding box를 기준으로 약간의 padding을 둬서 크롭하는 방식이다.
이 방법은 이미지의 배경이 거의 제거되므로 모델이 객체와 배경을 구분하지 못하는 문제가 생길 수도 있지만 테스트 결과 걱정과는 다르게 성능을 유지하면서 용량과 소요시간이 20배 줄어드는 효과를 얻었다.
서브 데이터
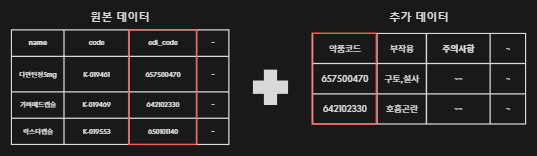
이미지(알약)에 대한 알약 코드, EDI 코드 등 기본 정보는 메타데이터인 JSON 파일에 담겨있다. 하지만 사용자에게 서비스를 제공하기 위한 부작용, 주의사항, 혼용 금지 정보 등 추가적인 정보는 부족하기 때문에 외부 데이터를 불러와 합쳐주었다.
결측치 처리, 데이터 정규화 등 기본적인 전처리를 진행하고 성분 검색에 사용되는 EDI code를 기준으로 추가 정보를 합쳤다. 결과적으로 2000종류 정도 합칠 수 있었다.
이후, 혼용 주의 조합을 약품 코드로 매칭해 DB에 적재하고 모델로 인식한 알약들의 성분 조합을 쿼리로 전달하면 혼용 주의사항을 return 할 수 있게끔 설계했다.
모델 선정 및 훈련과정
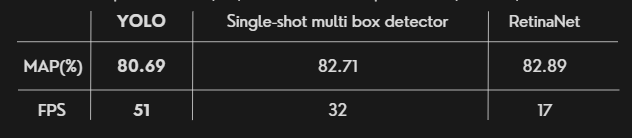
모델은 SSD,RetinaNET,YOLO 3가지 모델의 성능을 비교해 보았다. 위 사진과 같이 분류성능에는 크게 차이가 없었고 , 속도가 빠르고 기술적 접근성등 YOLO가 가장 뛰어나다고 판단해 YOLO를 선택하게 되었다.
결과적으로 최종 모델은 2000종류의 이미지 43만장을 40시간 이상 학습했고 평가결과 precision 93% , map@95 96.2% , map@95 96%를 달성했다.
웹
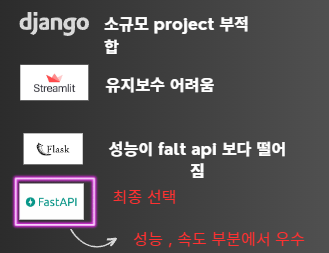
웹 기본 구성은 HTML 템플릿을 받아와서 수정했다. 이후 backend 웹 서버를 구현하기 위해 Streamlit, Flask, FastAPI 모두 시도해 보았다. 결국 성능과 속도 부분에서 FastAPI가 가장 좋다고 판단해 FastAPI를 활용했다. 이후 Jinja templates를 활용해 템플릿에 렌더링했다. 자세한 코드는 제일 상단 GitHub 주소에 보면 확인할 수 있다.
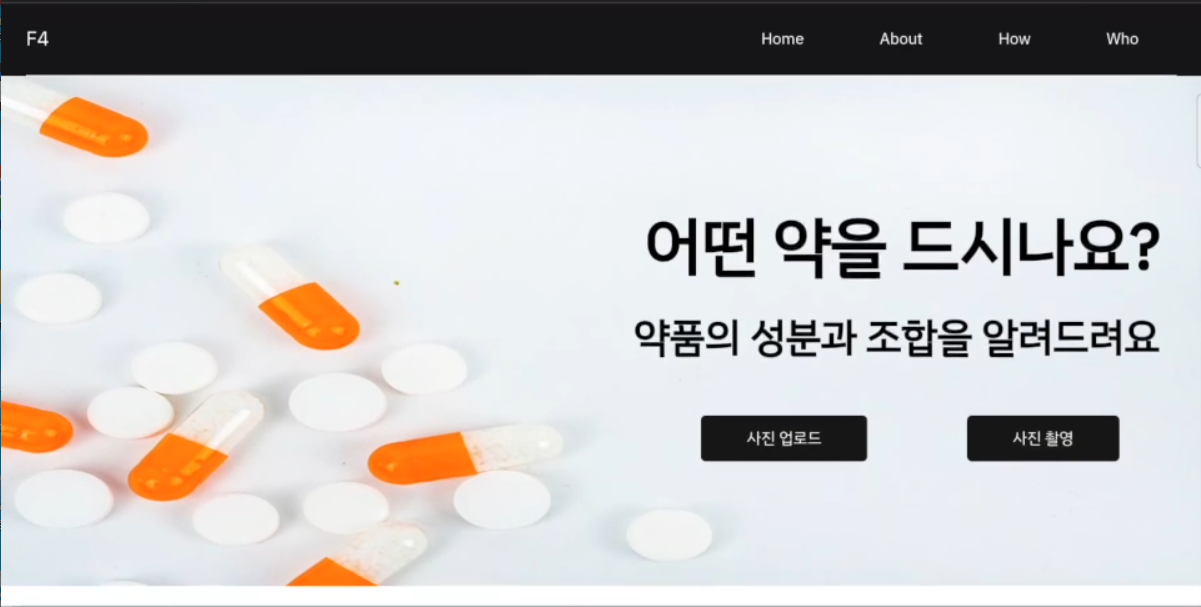
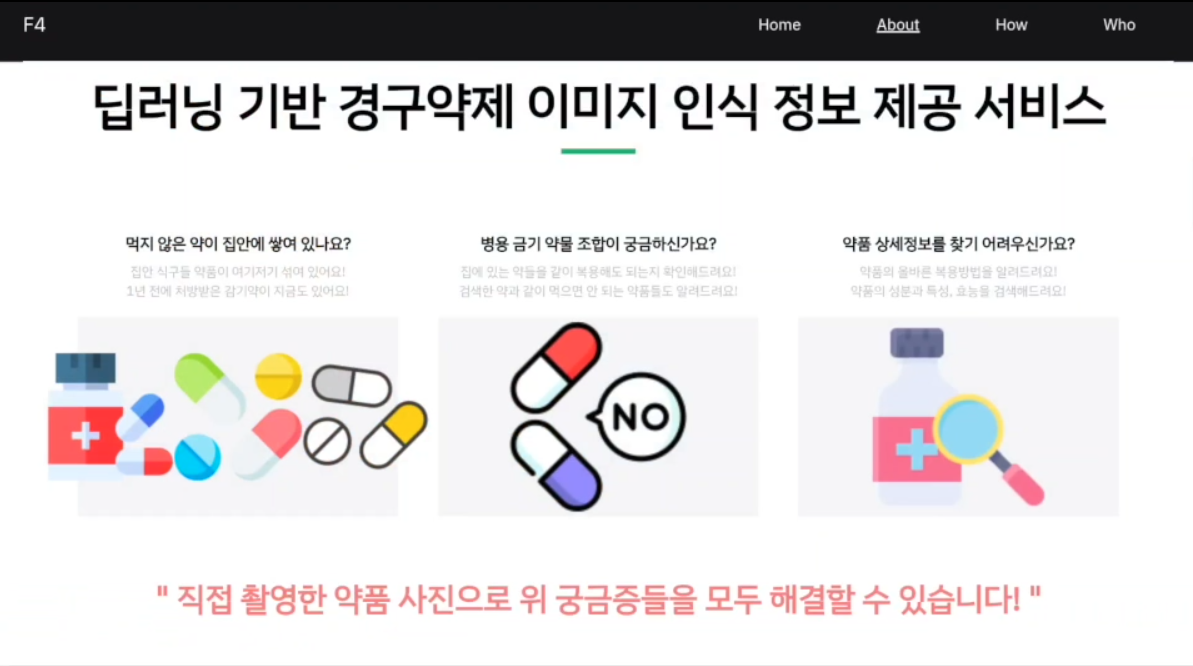
위 사진은 기본적으로 만든 웹 메인 페이지이다.
최종 결과
사용자가 함께 복용하고 싶은 알약을 모아 사진을 찍고 업로드하면 알약성분,주의사항,부작용,혼용 금지 조합을 알려주게 된다.
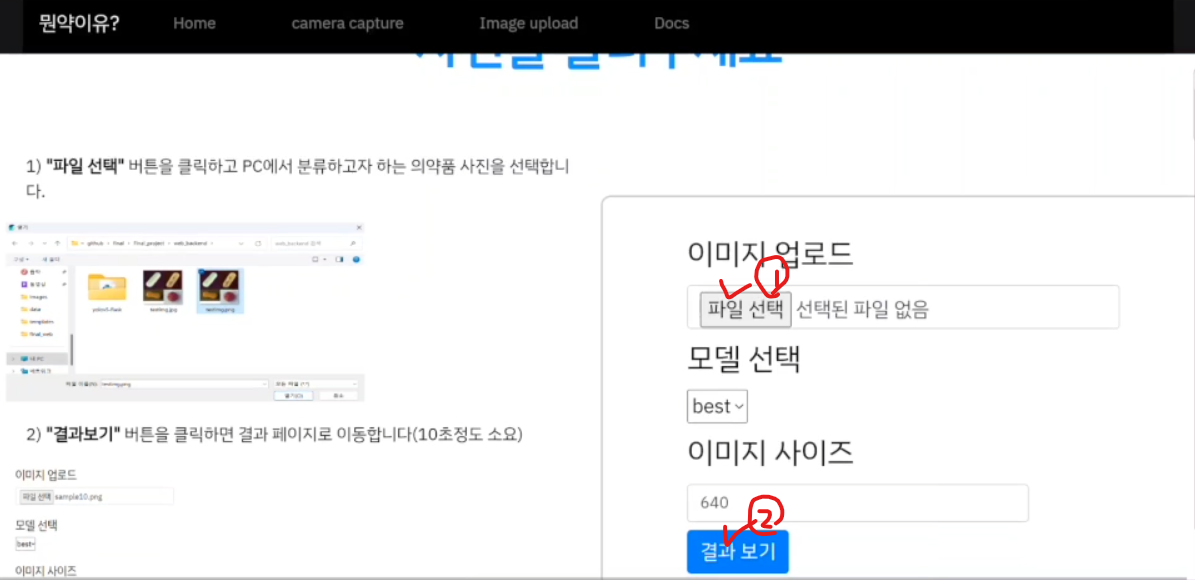
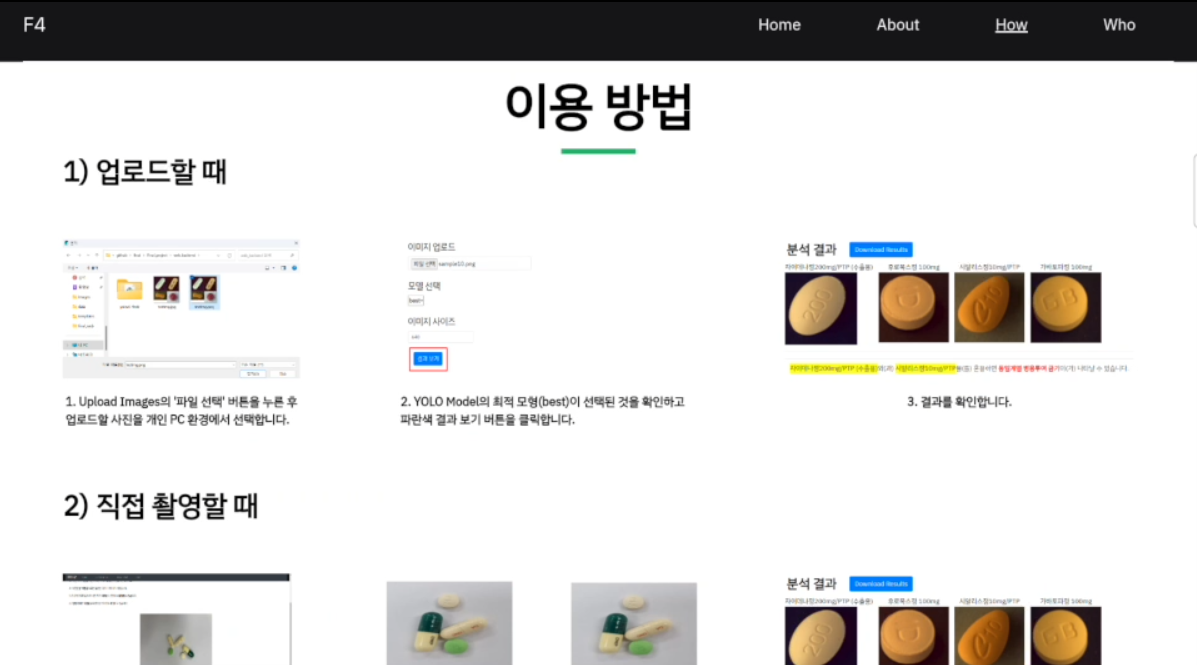
왼쪽에는 간단한 사용설명이 나와있고 오른쪽은 실질적인 기능이 포함되어 있다. 사용자는 파일 선택 버튼을 누르고 사진을 업로드한뒤 결과보기를 누르게 된다.
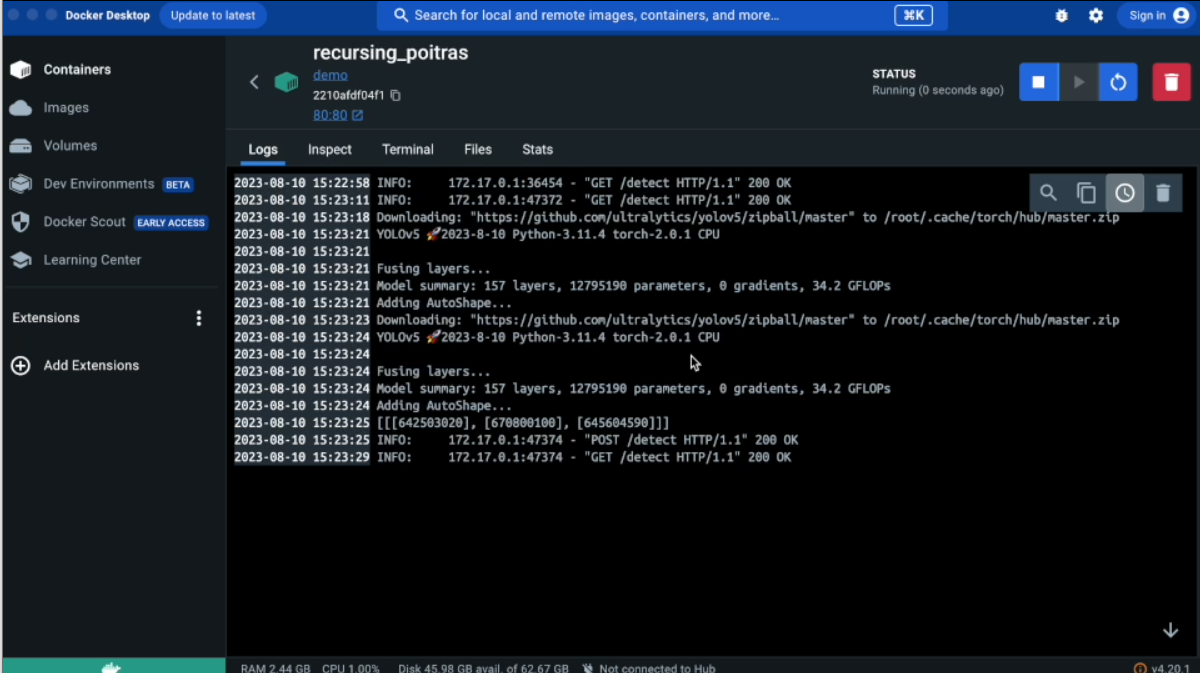
위와같이 도커 컨테이너에서 다음과 같이 잘 작동하는 것을 확인 할 수 있다.
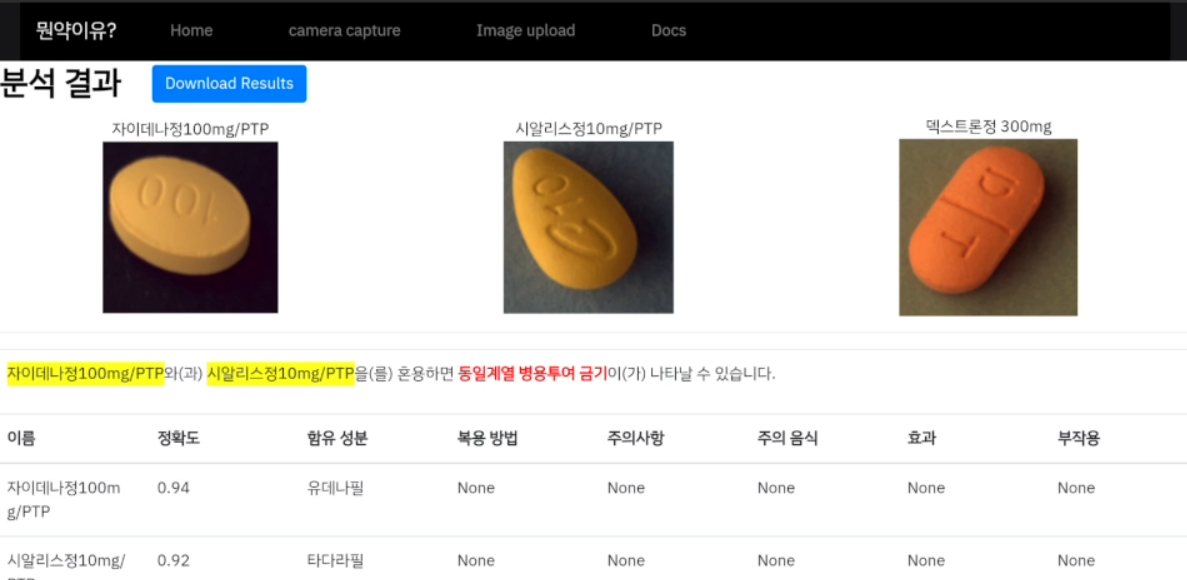
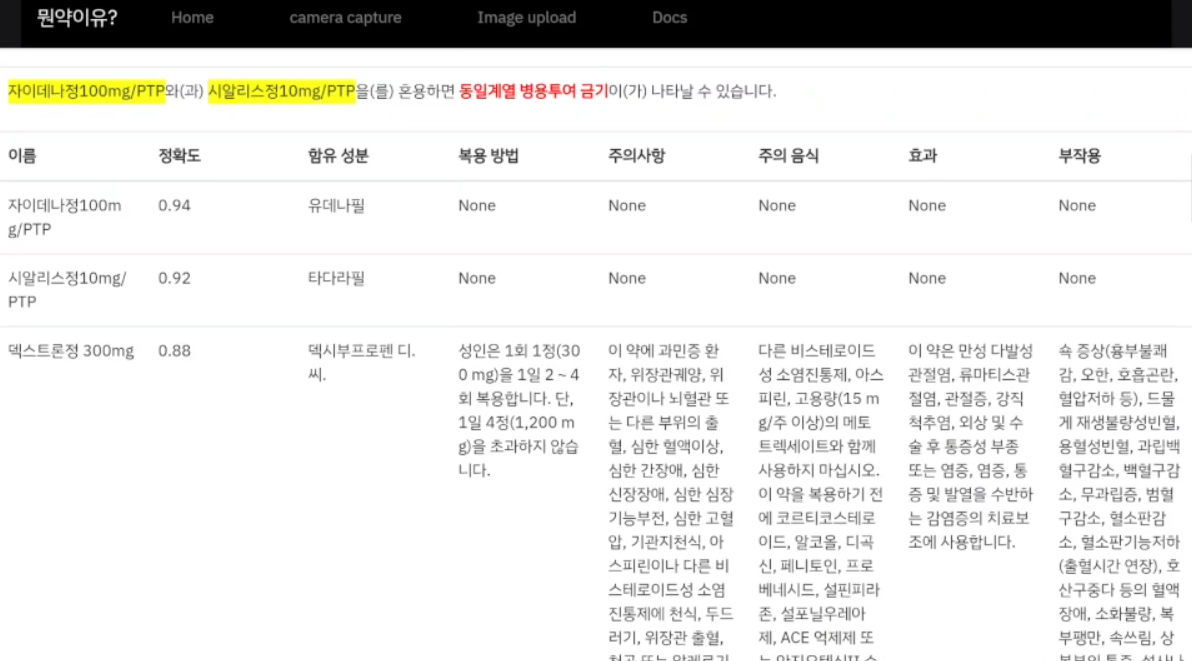
최종 결과는 다음과 같이 혼용 조합일시 주의 멘트 , 각 약품별로 다양한 특성을 알 수 있다.
프로젝트 역할
역할을 크게 model파트 1명, 클라우드 엔지니어링 파트 1명, 전처리 & web파트 2명으로 나눴다. 나는 이중에서 전처리 & web 파트를 맡았다. 초반에는 이미지 전처리 , 외부 데이터 전처리 및 연결을 맡았고 , 중반에는 웹서버 구현을 위해 flask,streamlit등 다양하게 시도해보았다. 마지막에는 fast api 활용 backend을 메인으로 , css,javascripts를 활용한 frontend 기능 수정등을 맡았다.
한계점 및 느낀점
한계점
가장 큰 한계점은 컴퓨팅 자원 대비 시간이었다. 이미지의 양이 어마어마하게 많았기 때문에 학습만 해도 많은 시간이 걸렸고, 압축해제, 전처리, 적재, DB와 대조 등 모두 해야했기에 시간이 많이 부족했다. 또한, 약의 종류는 너무나도 많기 때문에 메인 데이터에 대한 의약품에 대한 추가 정보 데이터가 없는 것들이 많았다.
충분한 시간과 컴퓨팅 자원 , 데이터가 있다면 충분히 의미있는 서비스로 확장 가능 할것이라고 생각한다.
느낀점
이 프로젝트는 여러모로 나에게 의미가 많은 프로젝트이다. 기존에는 단순하게 데이터 분석만 진행하는 프로젝트를 했다면 이 프로젝트를 통해 처음으로 데이터, 인공지능 기술을 결합해 서비스단까지 만들어 보는 경험을 했다. 또한, 정형화된 데이터가 아닌 이미지(비정형) 데이터를 주로 다뤄보는 프로젝트였다는 점에서도 의미가 있다.
가장 실력이 좋은 팀장의 주도하에 모두가 목표를 향해 바쁘게 달려갔지만 지금 생각해보면 아쉬움이 남는 프로젝트이다. 특히, 웹 서버를 구축하고 웹 서비스와 인공지능 모델을 연결하는 과정이 나에게 모두 처음이었기 때문에 많이 돌아갔다. 하지만, 단순한 데이터로부터 서비스까지 구현되는 전 과정을 경험하면서 많이 배운 것 같다. 이미지를 다양하게 전처리하는 방법을 익히는 것에 더해 하나의 AI 서비스가 어떻게 구현되는지 흐름을 파악 할 수 있었으며, 직접 웹 Backend Frontend를 만들면서 웹 서비스 구축 기술도 익힐 수 있었다.
이 프로젝트를 계기로 이후, 서비스단까지 구축하는 프로젝트에 과감하게 도전할 수 있었다. 데이터 분석가로 갈길을 아직 멀지만 매 프로젝트마다 새로운 기술을 익혀가며 앞으로도 지속적인 성장을 할 것이다.

안녕하세요 글잘 보았습니다. 코랩 서버 비용은 총 얼마나 들었는지요?