계기
CJ올리브네트웍스에서 주관하는 AI 해커톤을 하면서 참여했던 프로젝트이다. 우리팀은 6명으로 구성되었고 3주라는 시간동안 인공지능을 활용한 결과물을 도출했어야 했다. 이에 최근 화두되고 있는 언어모델을 위주로 주제를 선정해보려고 했고 , 자연어처리 프로젝트를 경험해볼 수 있는 좋은 기회라 생각하며 프로젝트에 임했다. 다양한 총10개의 아이디어중에 3차례 투표를 거쳐 낚시성 기사 판별 시스템이 아이디어로 선정되었으며, 해커톤인 만큼 기존 연구와는 다른 방식으로 접근해보려고 노력했다.
협업툴은 회의를 위한 Discord , 문서공유를 위한 notion , 코드 공유를 위한 google drive 총 3가지를 사용했다.


프로젝트 배경 및 목표
배경
- 제목으로 관심을 끌고 정작 내용은 제목과 다른 낚시성기사 존재.
- 사용자는 클릭하기 전까지 낚시성인지 아닌지 판별하기가 어려움
- 기존의 연구방식은 BERT model 기반 낚시성 분류까지만 진행
*BERT : 구글이 공개한 사전 훈련된 모델로 Transformer 기반이며, NLP분야에서 높은 성능을 냄
목표
서비스
- 낚시 기사유무 및 낚시 유형까지 판별하고 기사 요약및 빈출단어까지 제공함으로써 효율적인 정보 취득
- 기사를 보는 비판적인 시각증진
- 언론사에게 '진실성'의무에 대한 경각심 전달 등
연구
- 기존과는 다른 방식인 대규모 언어모델(LLM)로 낚시 기사 판별 및 유형분류 서비스 제공
- 모델의 하이퍼 파라미터 튜닝 및 데이터 변경으로 다양하게 접근
파이프라인 설계
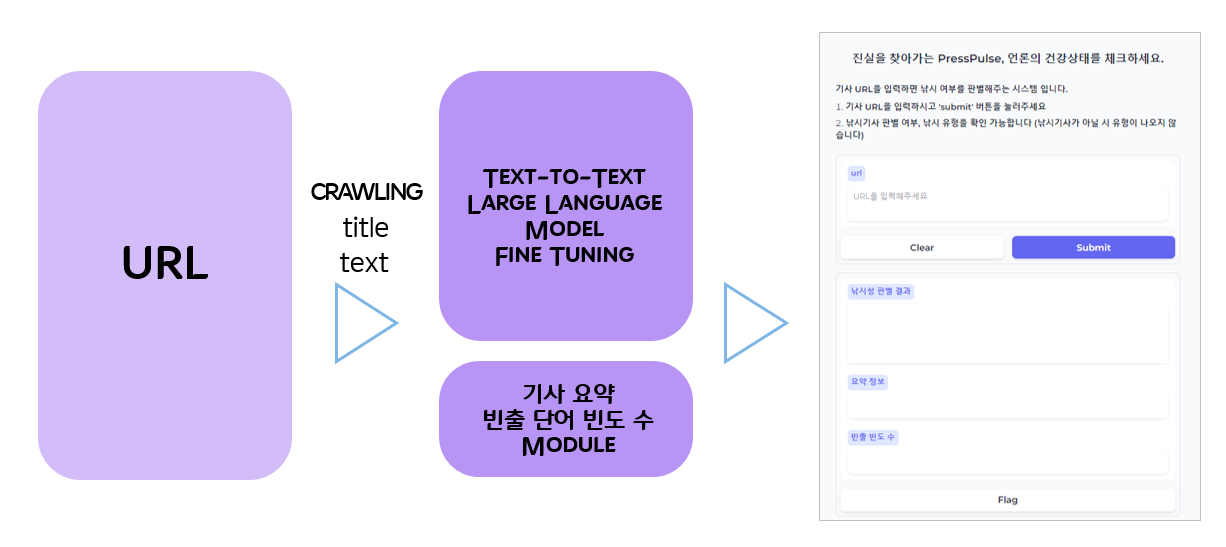
사용자가 URL을 입력하면 크롤링 모듈을 통해 기사제목,본문을 추출하고 Text-to-Text llm model fine Tuning과 , 기사 요약 빈출단어빈도수 module을 통해 최종적으로 낚시유무,낚시유형,기사요약,빈출빈도를 사용자에게 제공한다.
기사요약은 python에 summa 패키지에 summizer모듈을 활용했고 , 빈출 단어 추출은kiwipiepy 패키지의 kiwi를 활용했다.
활용 데이터
https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=data&dataSetSn=71338
데이터는 AI hub에서 제공하는 낚시성 기사 탐지 데이터를 활용했다.
데이터는 640000 rows, 15 columns로 이루어져 있었으며 전에 ai hub에서 메타데이터를 가져와본 경험이 있어 쉽게 csv 형태로 가져올 수 있었다. (csv는 그냥 보기 편하려고 했음)
EDA 및 전처리
전처리는 크게 많이 건들지는 않았다. NULL값이 많은 행을 삭제하거나 , 필요없는 칼럼을 지우는 간단한 작업들만 진행하였고 20만개정도 남았다. 이후 논문을 참고해 낚시 기사의 특징들을 파악해 현재 데이터의 낚시기사와 정상기사가 그 특성에 맞는지 확인작업을 진행했다. 결론적으로 데이터에 문제는 크게 발견되지 않았다.추후에 모델의 loss가 떨어지지 않는 현상으로 인해 데이터에 변화를 줄때 전처리를 추가적으로 진행했다. 학습에 불필요한 특수문자,띄어쓰기 등을 모두 삭제하였고 , 삭제 기준은 팀원들과 상의를 통해 결정했다. 뒤에서도 나오지만 결과적으로 최종 loss를 떨어트리는데 긍정적인 영향을 주었다.
(참고 논문: http://lps3.www.dbpia.co.kr.proxy.jbnu.ac.kr/pdf/pdfView.do?nodeId=NODE07049999 )
모델 선정 및 훈련과정
우선 한국어 기반 llm 리더보드에 다양한 모델이 있지만 , 우리팀이 선정한 모델은 크게 두가지이다.
<Meta AI의 고급 언어 모델인 Llama 2 >

<EleutherAI/polyglot-ko>

둘다 llm 분야에서 우수한 성능을 보여줬지만 ployglot-ko 모델이 한국어 기반으로 학습되어 조금 더 끌렸다. 학습을 하려고 하니 가장큰 문제가 생겼다 . 대규모 모델을 학습하기에 적합한 컴퓨팅 자원이 있는 컴퓨터가 한대뿐이었다.. 어쩔 수 없이 데이터를 최대한 줄이고모델의 성능을 확인한 후 모델을 선정하는 방법으로 접근할 수 밖에 없었다.
1 TRIAL (LLAMA2 7B vs Ployglot 12.8B)
첫번째로 , 우선 학습 조건은 거의 동일한 환경에서 두모델의 성능을 비교해보았다
<학습방식 : autotrain , 데이터 샘플링 : 기존 5%>
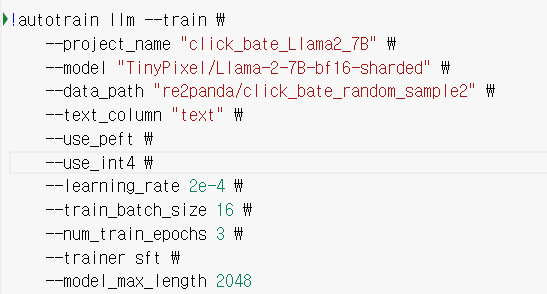
llama2 7B

polyglot -ko 12.8B

비슷한 환경에서 polyglot-ko가 더 원하는 결과에 근접하다는 판단에 polyglot-ko 모델을 채택하기로 했다.
2 TRIAL (유형 다양성 확보를 위한 데이터 샘플링 변경)
최종 결과 낚시 유형이 특정 유형으로만 치우치는 문제가 발생하였다. 이에 데이터 샘플을 각 유형별로 1000개씩 총12000개를 샘플링 하였고 , 학습데이터와 검증 데이터또한 분리시켰다. 결과적으로 낚시 유형의 다양성을 확보할 수 있었다.
3 TRIAL (polyglot ko 12.8B , 5.8B , 1.3B 비교)
polyglot ko 모델을 크기별로 성능을 비교해 보았다. 학습 데이터수가 적어서인지 **polyglot ko 5.8B 모델이 loss가 가장 떨어지는 양상을 보였다.
이후 베포를 위해 학습한 모델을 hugging face에 올리고 올린 모델을 colab또는 local에서 불러와서 베포를 하는것을 선택했는데 , 5.8B모델부터는 용량이 커서 자원이 약한 컴퓨터가 버티지를 못했다. 따라서 polyglot ko 1.3B모델 최적화를 하는 방향을 선택했다.
4 TRIAL (파라미터 수정)
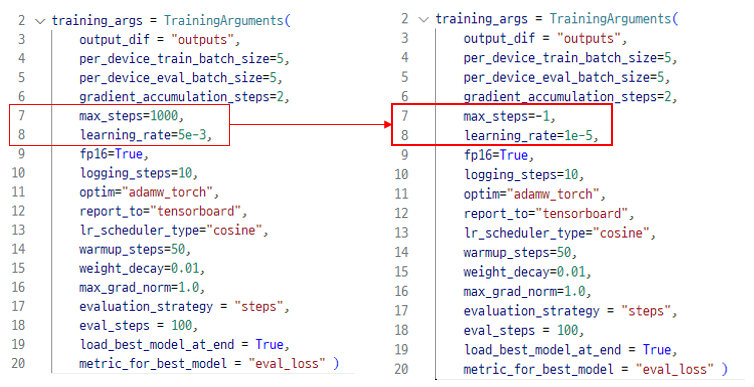
max_steps,learning_rate 위주로 파라미터를 수정했으며 다양한 방식으로 시도했다.
5 TRIAL (프롬프트 수정 , 데이터 전처리)
본문 데이터를 그대로 학습했더니 원하는 결과가 제대로 나오지 않는 상황이 발생해 텍스트를 상의된 기준을 통해 전처리 하였고 , Llama 기반 대규모 언어모델 Alpaca의 학습 방식에서 착안하여 기존과 달리 텍스트 프롬프트에 instruction을 추가해 학습하는 방향으로 접근해보았다.
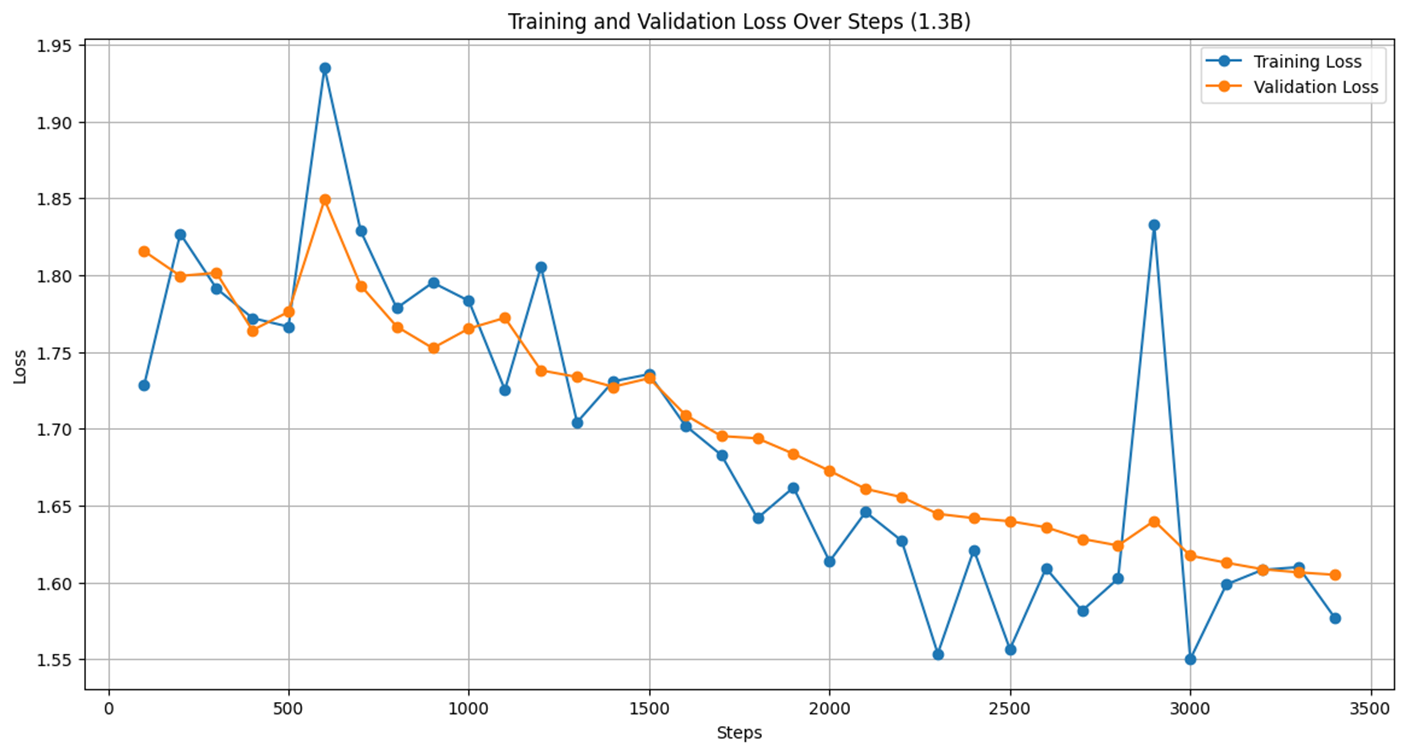
최종적으로 나온 loss이다. 중간에 튀는 부분이 다소 있지만 처음에 비해 떨어진것을 볼 수 있다.
최종선정 모델 : polyglot-ko 1.3B
최종데이터셋 : 유형별 1000개 12000 row
학습 시간 : 6시간
배포


배포는 LangChain과 gradio를 활용하였다 .
Langchain : 언어 모델을 기반으로 한 애플리케이션 개발 작업을 수월하게 진행할 수 있도록 설계된 오픈 소스 프레임워크로 2022년 말쯤에 등장했다.
Gradio: 인공지능 모델을 사용하여 쉽게 웹 인터페이스를 만들 수 있도록 도와주는 오픈 소스 라이브러리이다
gradio만 활용해서 할수도 있었지만 최신 기술을 사용해보고 싶었고 추후 배포 확장성을 고려한다면 langchain까지 활용하면 좋을것같아 둘다 사용했다. 실제로 , hugging face에서 모델을 load하고 LangChain에 연결하는 과정에서 텍스트 생성 prompt를 맞춰줘야 했기에 많은 오류가 발생했지만 결국 해냈다 ..!
model load
 배포만 모델을 Peft를 통해 불러왔고
배포만 모델을 Peft를 통해 불러왔고
langchain 연결
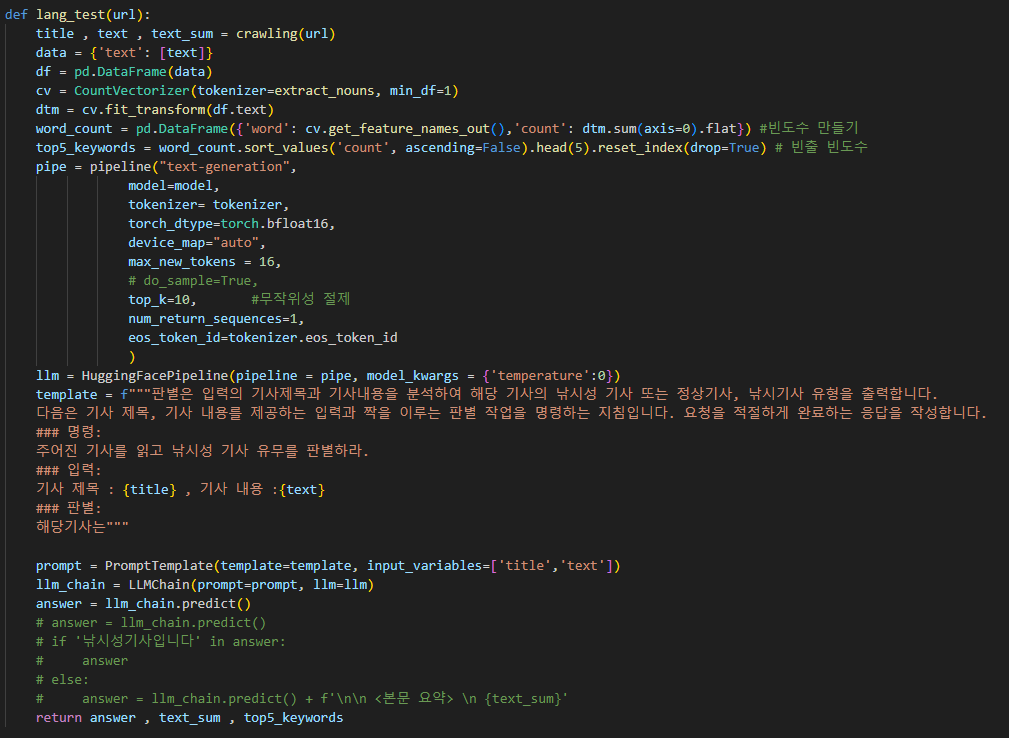 미리 만들어 놓은 크롤링 모듈과 빈도수 추출,요약모듈을 활용하면 url을 넣으면 다음과 같이 모델 예측 결과 , 텍스트요약 , 빈출 빈도수를 추출해 낼 수 있다.
앞서 말했듯이 기사요약은 python에 summa 패키지에 summizer모듈을 활용했고 , 빈출 단어 추출은 kiwipiepy 패키지의 kiwi를 활용했다. 요약은 패키지는 gensim,summa가 대표적으로 있었는데 gensim는 python 3.11에서 버전 이슈가 있어 배제했다.
또한 패키지의 한계로 결과가 텍스트에 따라 불안정한 느낌이 있었지만 시간상의 이유로 어쩔 수 없이 활용했다.
미리 만들어 놓은 크롤링 모듈과 빈도수 추출,요약모듈을 활용하면 url을 넣으면 다음과 같이 모델 예측 결과 , 텍스트요약 , 빈출 빈도수를 추출해 낼 수 있다.
앞서 말했듯이 기사요약은 python에 summa 패키지에 summizer모듈을 활용했고 , 빈출 단어 추출은 kiwipiepy 패키지의 kiwi를 활용했다. 요약은 패키지는 gensim,summa가 대표적으로 있었는데 gensim는 python 3.11에서 버전 이슈가 있어 배제했다.
또한 패키지의 한계로 결과가 텍스트에 따라 불안정한 느낌이 있었지만 시간상의 이유로 어쩔 수 없이 활용했다.
UI
 위 사진은 그라디오 UI에 그리는 코드이다. UI는 간단하게 구성했다.
위 사진은 그라디오 UI에 그리는 코드이다. UI는 간단하게 구성했다.
최종 결과
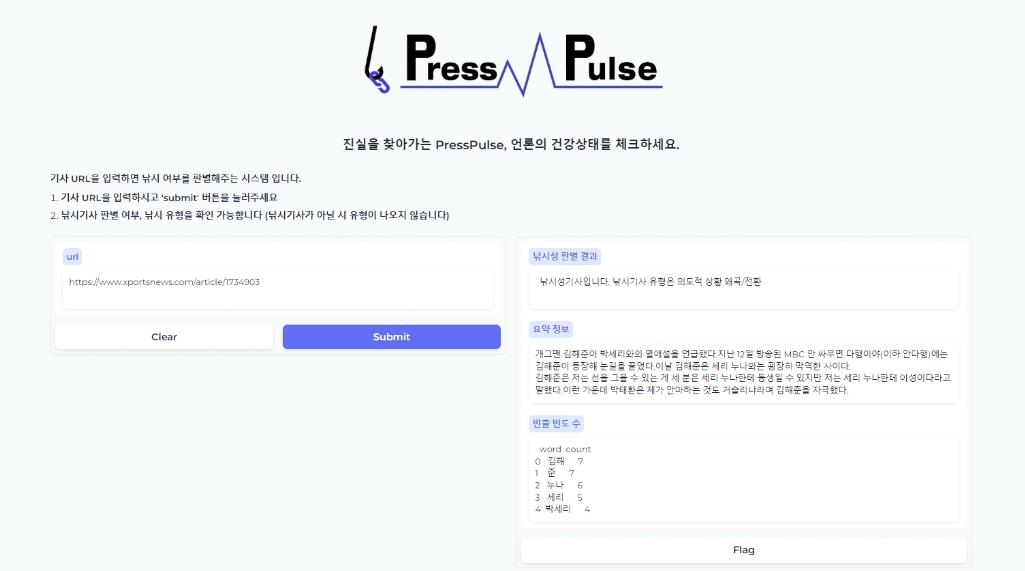
결과는 url을 입력하면 의도한 목표와 같이 낚시성 판별결과 , 유형 , 요약정보 , 빈출빈도수를 한번에 확인 할 수 있다. 시간은 5초정도 걸렸다.
프로젝트 역할
모두가 협업해서 결과물을 만들어 냈지만 크게 나누자면 베포 , 학습으로 역할을 나눴던것 같다 . 높은 컴퓨팅 파워를 보유하고 전에 학습 경험이 있으신 팀원 2분이 모델 학습을 맡아주셨고 나머지 사람들은 그 외 다른것들을 맡아서했다. 물론 학습 결과가 나오면 파라미터 조정 , 학습 방식은 모든 팀원이 매일 회의에 참여하여 상의하면서 결정했다.
나는 전반적인 틀을 만드는 역할을 많이했다. 초반에 데이터를 불러와서 전처리해 가공시키는 파이프라인 및 url을 입력해 크롤링을 하는 파이프라인을 맡았고 , 중반에는 팀원이 llama2를 활용해 성공시킨 langchain틀을 활용해 polyglot-ko에 연결을 성공시켰다. 후반부에는 그라디오 기초 ui를 구성하고 코드를 하나의 실행파일로 합치는 역할을 맡았다.
느낀점
여러가지로 많이 배운 프로젝트였다. 나는 NLP,LLM관련 지식 및 프로젝트 경험이 거의 전무했었지만 프로젝트를 진행하면서 많은 모델에 대한 지식 , LLM의 학습 및 배포방식을 배울 수 있었다. 실제로 hugging face에서 모델을 불러오는것도 한번도 해본적 없는 나에게는 모든게 새로운 지식이었다. 특히 신기술인 langchain을 직접 활용해보면서 배포를 위한 시도했던 과정들이 가장 큰 의미가 있었던것같다.
아쉬운점은 정말 많다. 가장 큰 문제인 컴퓨팅 자원 , 시간이 너무나도 부족했기 때문에 최종적인 결과도 드라마틱한 loss하락을 보여주지 못했다. 또한 같은 이유로 학습량이 부족했기 때문에 일부 기사에서는 제대로 분류하지 못하는 문제점도 생겼다.
텍스트 요약 부분에서도 python 패키지를 활용해서 요약을 해서 어떤 문장들을 중요한 문장을 생략해버리는 문제점도 생겼다. 현재는 많이 불안정하지만 , 충분한 컴퓨팅 자원과 넉넉한 시간이 있었다면 다시 한번 제대로 만들어 보고 싶다는 생각이 든다.
만약 이 서비스를 확장 한다면 다음과 같이 확장할수 있을것이다.
- 단어 빈출 빈도로 감정 분석 후 긍정/부정 기사 분류
- 댓글 / 조회수등 추가 분석으로 고도화된 판별 서비스 제공
- 뉴스 포털 내 낚시성 기사 빈도 수 집계를 통한 언론 지수 제시
- 낚시성 기사 필터링 후 , 양질의 기사를 제공하는 플랫폼 서비스
이외에도 생각하면 확장성은 무궁무진 하다고 생각한다. 아쉬움이 많이 남지만 한달동안 팀원 모두가 정말 집중해주었고 , 나 또한 경험하지 못하면 얻을 수 없는 값진 경험을 할 수 있어서 뿌듯하다.


혹시 원천데이터와 라벨링 데이터 중 어떤 데이터를 csv로 변환하여 사용하신건가요..?