Abstract
의료 분야에서 질병 진단 관련하여 후향적인 연구를 진행하였을때 데이터 수집간 적은 데이터을 자주 목격하게 되었다. 그렇기 때문에 '적은 데이터셋으로 모델을 학습시켜 질병 분류를 할 수 있을까?' 에 대한 고민을 하게 되었고. 이와 관련하여 Few-shot Learning 기법에 대해 알게되었다.
Few-shot Learning 이 부족했던 데이터의 분류 문제에서 해결책이 될 수 있겠다 싶어서 찾아봤다.
1. Few-shot Learning (FSL)
- (few 한 데이터로 학습을 한다는 의미인줄 알았으나....) 적은 데이터 셋으로도 잘 분류할 수 있다는 것임
2. Few-Shot variations
FSL 의 다양한 변형으로 일반적으로 연구자들은 네 가지 유형으로 나눔
- N-Shot Learning (NSL)
- Few-Shot Learning
- One-Shot Learning (OSL)
- Less than one or Zero-Shot Learning (ZSL)
FSL 에 대해 이야기할 때 일반적으로 N-way-K-Shot-classification을 의미함.
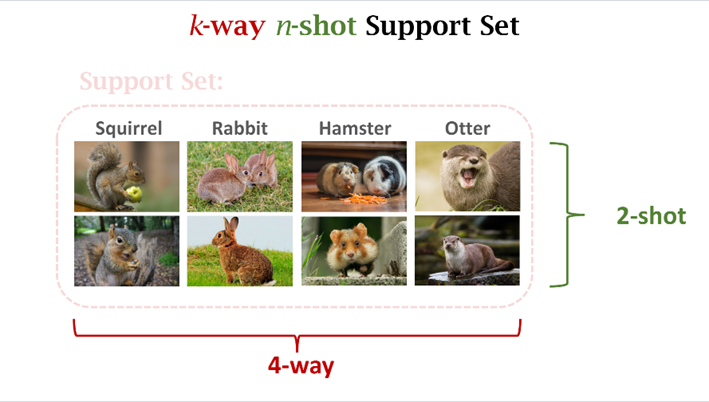
N은 클래스 수를 나타내고 K는 훈련할 각 클래스의 샘플 수를 나타냄.
N-Shot Learning은 다른 모든 것보다 더 광범위한 개념으로 간주되고, 즉, Few-Shot , One-Shot , Zero-Shot Learning 은 NSL 의 하위 분야임.
Zero-Shot Learning
Zero-Shot Learning 의 목표는 학습 데이터 셋의 예제 없이 보이지 않는 클래스를 분류하는 것
Question : 사물을 보지 않고도 분류할 수는 있을까?
Answer : 개체, 모양, 속성 및 기능에 대한 일반적인 개념이 있다면 문제가 되지 않음
이것이 ZSL을 할 때 사용하는 접근 방식이며 현재 추세로는 Zero-Shot Learning이 곧 효과적일 것이라는 전망
One-Shot and Few-Shot Learning
One-Shot Learning(OSL) 에서는 각 클래스의 단일 샘플만 있는 것, Few-Shot은 각 클래스당 2~5개의 class을 가지고 있어 보다 유연한 OSL 버전임
주의! : 전반적인 개념에 대해 이야기할 때 Few-Shot Learning 용어를 사용하기 때문에 혼동될 수 있음.
3. Human vs AI : Recognition

사람에게 Support Set 을 보여주고, Query 가 어느쪽에 해당하는지 물어보면, Pangolin 이라고 잘 대답할 것임
하지만 기존의 딥러닝이라면 아마도 두 클래스에 대한 수많은 사진을 준비하고 모델학습이 필요함
그렇다면 사람은 어떻게 Query 가 바로 Pangolin 클래스에 속한다는 것을 알 수 있을까?
바로 우리는 "구분하는 방법"을 배웠기 때문! 가령 고양이와 강아지가 다르다는 것을 배우는 것과 같이 다른 수많은 데이터에서 겪은 경험과 시행착오를 기반으로 가능한 것임
이렇게 "구분하는 방법을 배우는 것"을 Meta Learning 이라 하며, "Learn to Learn" 이라고도 표현함
Few-shot 은 바로 위와 같은 사례에서 착안한 Meta Learning 임
따라서, "구분하는 방법"을 배우고자 하는 방법론이고, 즉 이를 위해 수많은 데이터가 필요한 것은 마찬가지 하지만 기존의 딥러닝과 다른 점은 "구분하고자 하는 대상"이 반드시 학습 데이터셋에 없어도 된다는 점
4. Few-shot Learning Process
Few-shot Learning 을 위해서는 아래 속성이 필요함
1) Training Set
2) Support Set
3) Query image
Training Set 을 이용하여 "구분하는 방법"을 배움
Query image 가 들어왔을 때, Query image 가 Support Set 중 어떤 것과 같은 종류인지를 맞춤
결과적으로 "어떤 클래스에 속하는가"를 맞추는 것이 아닌 "특정 클래스와 같은 클래스인가"를 푸는 문제라고 생각하면 됨
앞서 말한것 처럼 k-way 는 Support Set 이 k 개의 클래스로 이루어졌다는 것을 의미, 즉 k 값이 클수록 모델의 정확도는 낮아짐
K의 값에 따른 정확도
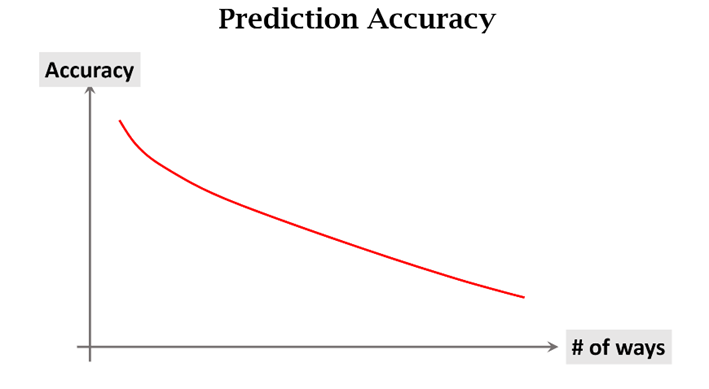
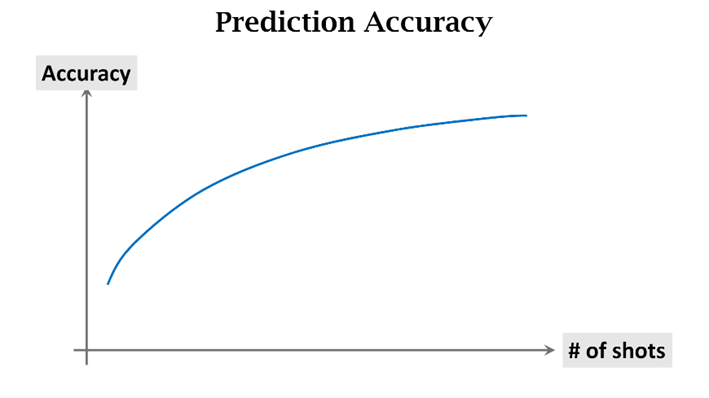
n-shot 은 각 클래스가 가진 sample 수로, 비교해볼 사진이 많을수록 어떤 클래스에 속하는지 구분이 쉽기 때문에 n 이 클수록 모델의 정확도는 높아짐
n=1 일 경우 one-hot learning 이라 함
N의 값에 따른 정확도
5. Few-shot Learning Method
Few-shot Learning 의 기본 학습 방법은 유사성을 학습하는 것
즉, Query image 가 주어졌을 때, Support Set 의 사진들과 잘 비교하여 (각 이미지들의 특징을 잘 추출하고 파악하여) 어떤 클래스에 속하는지를 알아내는 것이 중요
즉, Training Set 에서 각 사진별로 중요한 특징들을 잘 추출해서 "같은지 다른지를 구분하는 방법"을 잘 학습해야 함

Few-shot Learning dataset
아래와 같이 Positive Set, Negative Set 으로 구성하여 학습 진행

Few-shot Learning Network
이때, Feature extraction 을 잘 수행할 수 있도록 모델의 아키텍처를 구성해야 하는데, 일반적인 Conv-ReLU-Pooling layer 도 충분히 적합함
기초 Few-shot Learning 에서는 Siamese Network (샴 네트워크) 를 사용하는데, 이는 같은 CNN 모델을 이용하여 hidden representation 을 각각 구한 뒤, 이 차이를 이용하는 방식을 의미함
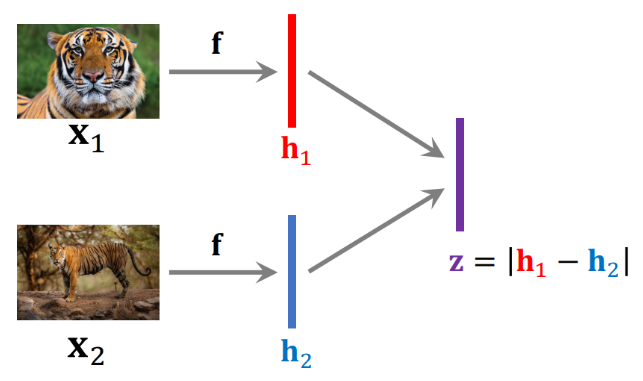
이후, Positive pair 에 대해 한 번, Negative pair 에 대해 한 번, 이렇게 번갈아가며 학습을 진행함
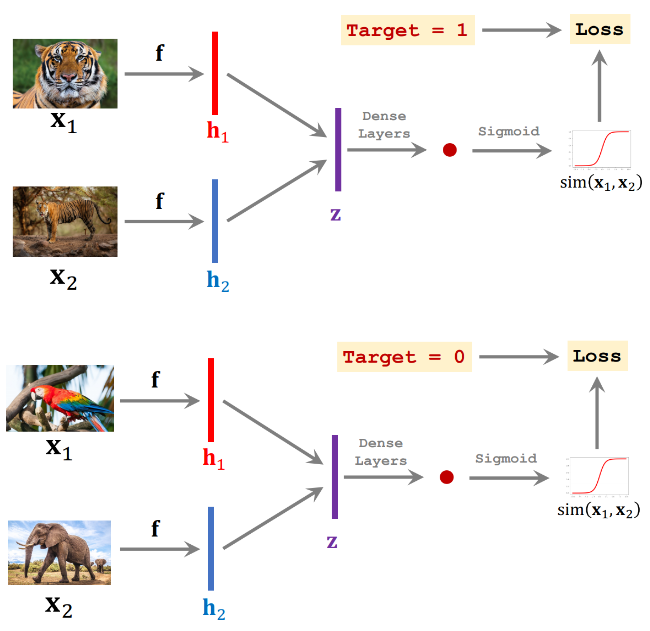
Prediction 에서는 위 방식과 같이 Support set 의 이미지의 representation 과 Query 이미지의 representation 간의 차이를 Siamese Network 를 이용하여 계산하고 그 유사성을 구함
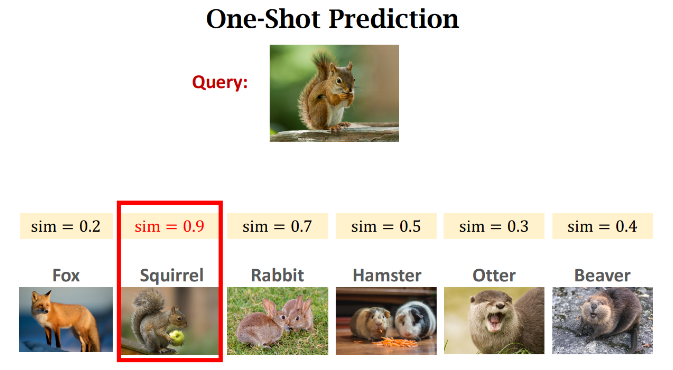
6. Summary
- 정리하면, Few-shot Learning 은 "구분하는 방법"을 배운다는 것임
- 학습데이터를 통해 학습하는 방법 자체를 배우고 이 방법을 통해 적은 양의 데이터로도 충분히 예측을 수행
References
