최근에 많은 generative 모델들이 고해상도의 이미지들을 생성해내고 있으며, 다양한 task에 응용되어오고 있습니다. 그 중에서도 Denoising diffusion 모델들은 generative 모델 중에서도 높은 성능을 보여주고 있습니다. Diffusion 모델이 지금과 같이 사용되기 전에 생성모델 분야를 주름 잡던 GAN 계열 모델들과의 비교에서도 압도하는 모습을 보여주고 있습니다. (https://arxiv.org/abs/2105.05233) 또한 mode coverage와 다양한 샘플 생성을 통해 복잡하고 다양한 데이터도 학습이 가능함을 보여줍니다. Denoising diffusion 모델을 공부하기 위해, 우선적으로 알아야 할 DDPM 논문을 리뷰하겠습니다.
Introduction
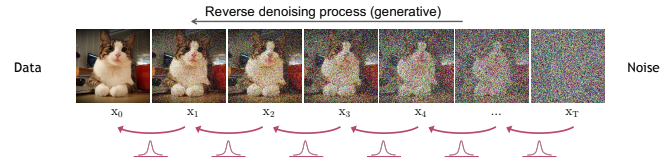
DDPM은 Forward diffusion process와 Reverse denoising process, 총 2개의 과정으로 구성되어 있습니다. Forward diffusion process에서는 각 timestep에서 input data에 noise를 더해갑니다. Reverse denoising process에서는 denoising을 통해 data를 생성하는 방법을 배우게 됩니다.
또한 모델 학습에 사용되는 Loss인 Variational upper bound에 대해서도 자세히 살펴보겠습니다.
Forward diffusion process
앞에서 짧게 언급했던 것처럼, input data에 각 timestep마다 가우시안 노이즈를 더하는 과정입니다. 이때 βt는 noise schedule로 정의되고, 매우 작은 양의 값을 가집니다.
forward 시에 한 번에 여러 번의 step을 적용하는 것이 가능합니다. 즉 여러 step에 걸쳐 이미지에 노이즈를 주지 않고, 한 번에 해당 과정을 수행할 수 있습니다. αt=∏s=1t(1−βs)로 α를 정의하면, q(xt∣x0)를 다음과 같이 표현할 수 있고 이를 diffusion kernel로 정의합니다. noise schedule 역할을 하는 βt를 통해 α가 0이 되게 하여, q(xt∣x0)가 std에 가까워지도록 학습합니다.
q(xt∣x0)=N(xt;αtx0,(1−αt)I)
xt를 샘플링하려면, diffusion kernel 분포에 reparameterization trick을 적용하여 해결할 수 있습니다.
xt=αtx0+(1−αt)ϵ
ϵ∼N(0,I)
이 샘플링이 의미하는 것은, xt를 샘플링할 때 q(xt)에서 직접적으로 하는 것이 아닌 training data dist.에서 샘플링이 가능하다는 점입니다.
Forward process에서 일어나는 과정 파악하기
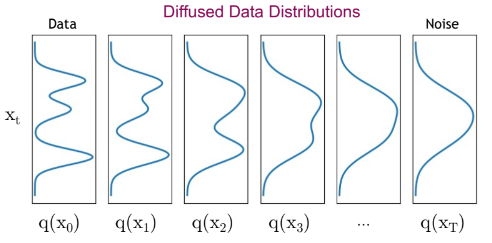
Forward 과정에서 이미지에 diffusion kernel을 적용하여 노이즈 x_t를 만드는 것을 다뤘습니다. 이번에는 Forward 과정이 Data dist.에 어떤 영향을 주는지 알아보겠습니다.
q(xt)=∫q(x0,xt)dx0=∫q(x0)q(xt∣x0)dx0
q(xt): Diffused data dist.
q(x0,xt): Joint dist.
q(x0): Input data dist.
q(xt∣x0): diffusion kernel
Forward 과정을 거쳐서 생성된 diffused data dist. q(xt)는 Input data dist. q(x0)와 diffusion kernel q(xt∣x0) 곱의 적분으로 구해집니다.
또한 input data에 diffusion kernel을 적용하여 만들어지는 분포가 std의 형태를 띄게 되는데, 이는 Forward의 step이 분포를 더 부드럽게 만들어주는 효과를 적용함을 파악할 수 있습니다. 따라서 diffusion kernel을 Gaussian convolution로 바라보는 것도 가능합니다.
Reverse denoising process
diffusion 파라미터들이 q(xt)≃N(xt;0,I)가 되게끔 학습되었습니다. 따라서 denoising을 통해 image generation을 학습하기 위해서 xt를 샘플링한 후에 반복적으로 xt−1를 샘플링해야 합니다. 해당 과정을 통해 diffusion step 이전의 분포를 학습하여 결과적으로 input data 분포를 학습하는 것입니다.
denoising 분포를 구하기 위해 베이즈 이론을 적용하면 q(xt−1∣xt)와 q(xt−1)q(xt∣xt−1)과 비례한다는 사실을 알 수 있습니다. 하지만 q(xt−1)가 적분 불가능하기 때문에 해당 방법으로는 denoising dist.를 구할 수 없게 됩니다.
따라서 q(xt−1∣xt)를 직접적으로 구하지 않고, density network를 통해 근사하는 방법을 이용합니다.
μ~t(xt,x0):=1−αtαt−1βtx0+1−αtαt(1−αt−1)xt: weighted sum
β~t:=1−αt1−αt−1βt
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),σt2I)
Loss 내에서 가장 중요한 denoising process term입니다. 1 < t ≤ T에 대해 두 정규분포인 q(xt−1∣xT,x0)와 pθ(xt−1∣xt) 사이의 KL divergence를 구해야 합니다. 이때 두 분포의 variance인 β~t와 σt2를 같다고 두어도 비슷한 결과를 나타낸다고 합니다. 따라서 KL term을 두 분포의 평균 사이 l2 loss로 표현합니다. (수식 전개 과정은 Appendix에 남겨두었습니다.)
이때 reparameterization(xt=αtx0+(1−αt)ϵ)을 적용하면 μ~t(xt,x0)=1−βt1(xT−1−αtβtϵ)로 나타낼 수 있습니다. (수식 전개 과정은 Appendix에 남겨두었습니다.) 따라서 μθ(xt,t)가 1−βt1(xT−1−αtβtϵ)를 예측하도록 학습됩니다.
최종적으로 구한 Loss 식은 다음과 같습니다! t=1일 때 L0의 역할을 하며, t>1일 때 Lt−1의 역할을 합니다.
Implementation
Algorithm
Training과 Sampling 알고리즘입니다. Training은 x0, t, ϵ을 샘플링 한 후에, gradient step을 밟는 구조로 이루어집니다. Sampling은 xT를 diffused dist.에서 샘플링 하여 denoising model을 통해 reparameterization 과정을 거쳐 x0를 얻어내는 과정입니다.
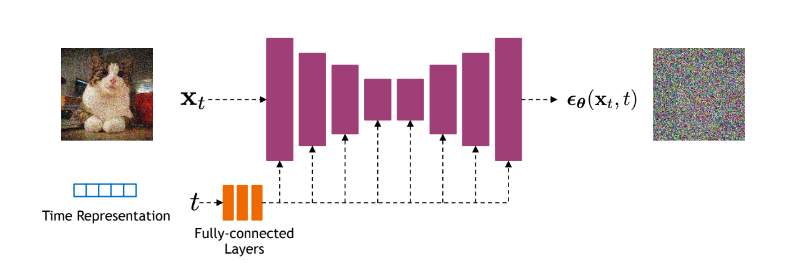
Denoising model
Denoising model로는 U-net을 사용하였으며, Residual block과 self-attention layers를 추가하였습니다. U-net 모델을 통해 noise ϵθ(xt,t)를 예측하였습니다. Time representation으로는 sinusoidal positional embedding 혹은 random Fourier features를 사용하였습니다.
Appendix
Appendix에서는 주로 ddpm의 주요한 식 전개 과정을 올리려고 합니다. 수식 전개에 대해 말로 자세히 설명하는 것보단, 제가 정리한 수식 전개 필기를 올리도록 하겠습니다!
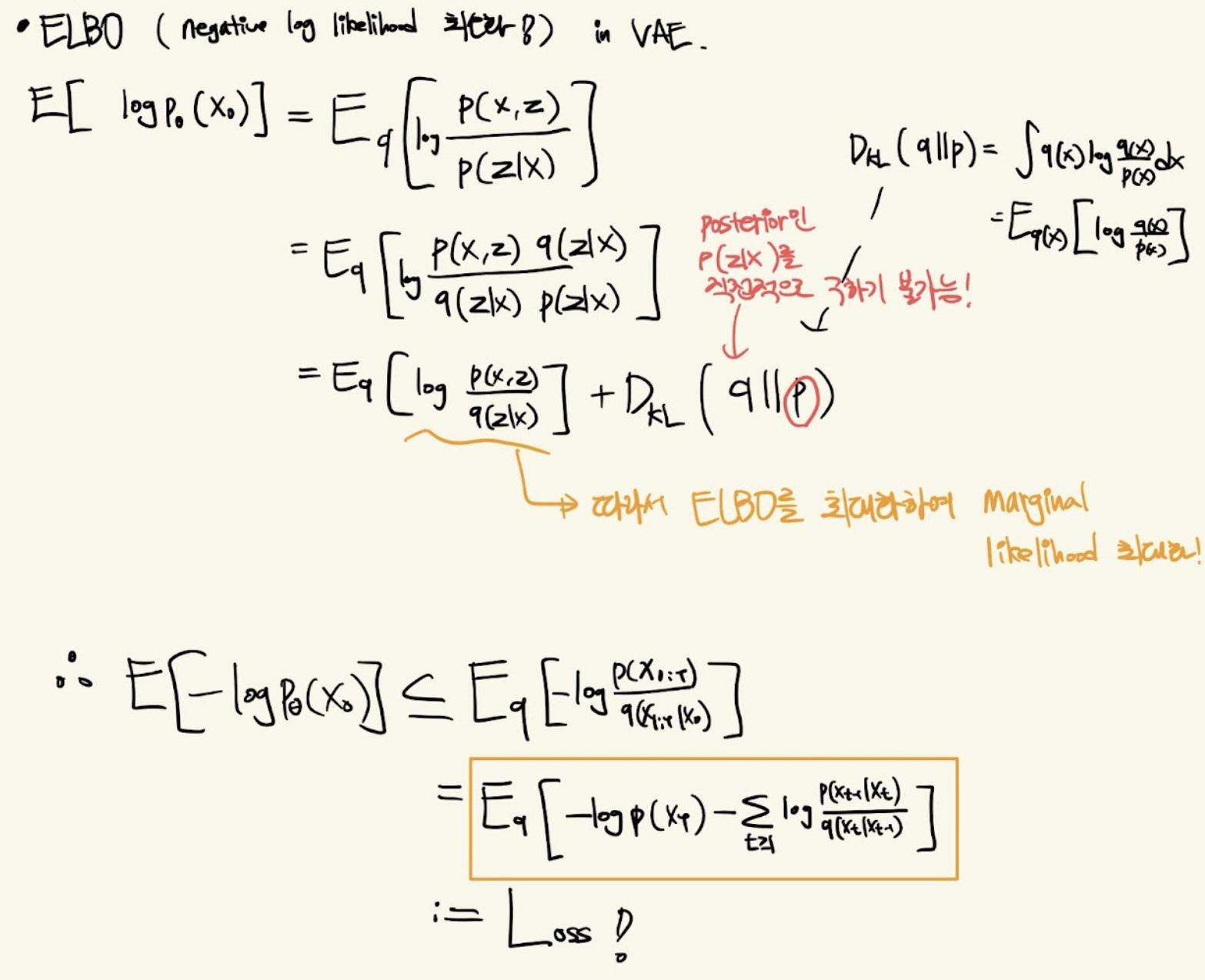
ELBO 표현 유도 과정
VAE에서의 ELBO 유도 과정과 동일합니다. log likelihood를 최대화할 때 직접적으로 z에 대한 적분이 불가능하므로, ELBO를 통해 간접적으로 최대화하는 방법입니다.
Variational upper bound 전개 과정
Variational upper bound를 LT, Lt−1, L0으로 나누는 과정입니다. 베이즈 이론을 통해 Lt−1 term이 유도되는 것이 중요한 점이었던 것 같습니다.
Gaussian KL divergence → l2 loss in Lt−1
Gaussian KL의 증명과 이를 통해 Lt−1 term이 l2 loss로 표현되는 과정을 적어보았습니다.
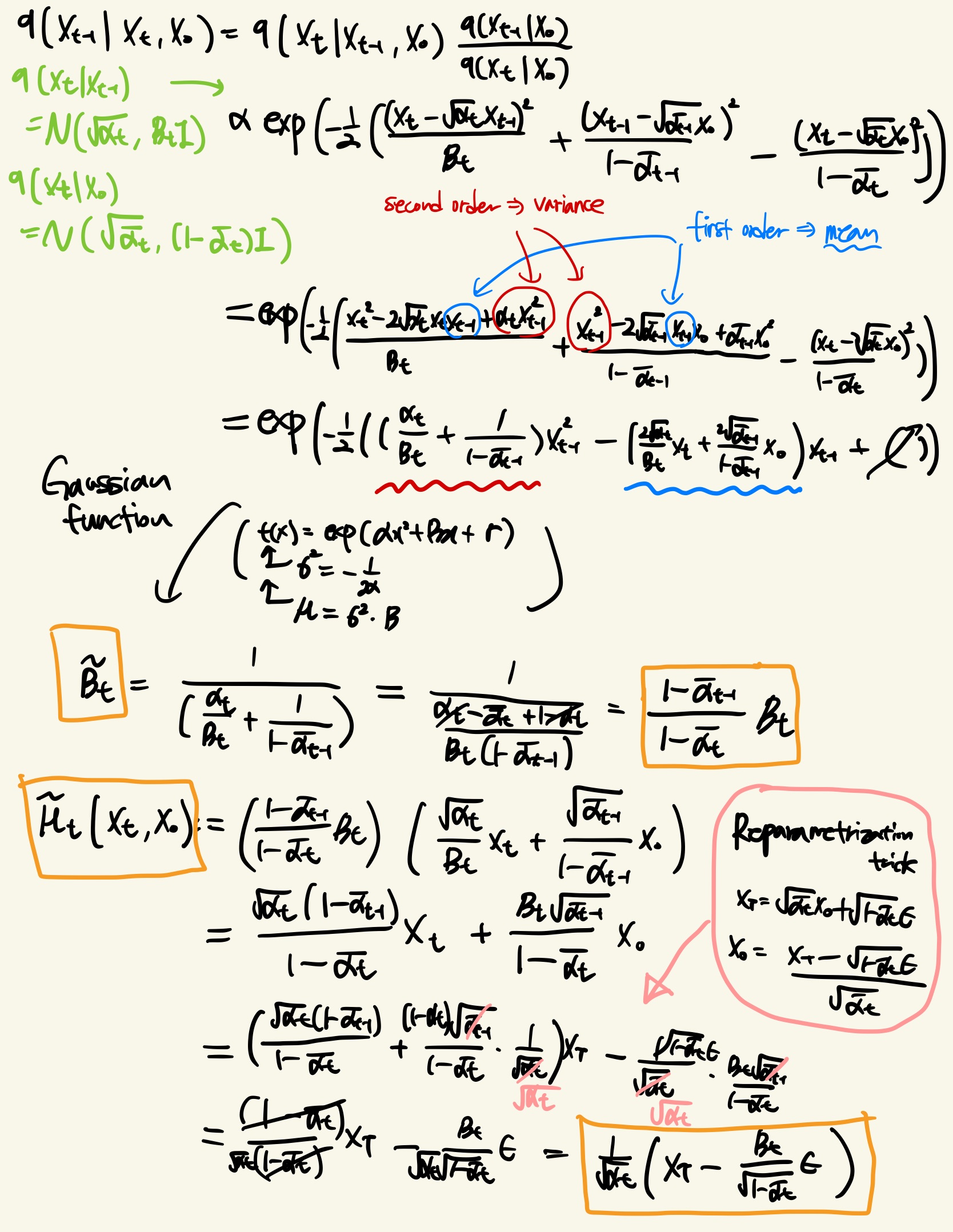
μ~t(xt,x0) with reparameterization
posterior distribution q(xt−1∣xT,x0)의 mean을 구하는 과정입니다. 이 과정에선 Gaussian function의 성질과 reparameterization trick 등이 사용되었습니다.
q(xt−1∣xT,x0)=N(xt−1;μ~t(xt,x0),β~tI)
μ~t(xt,x0):=1−αtαt−1βtx0+1−αtαt(1−αt−1)xt: weighted sum