[논문리뷰] Denoising Diffusion Probabilistic Models
diffusion model에 대해서 기존 모델인 GAN, VAE와 비교하여 설명하는 논문
논문에서 설명하는 이 모델의 특징, 이 모델을 써야하는 이유.
기존 모델들 보다 품질이 좋고 안정적이다.
또한 확률 모델 계산하기에 좋다. DDPM은 명확한 확률 모델로서, 데이터의 log-likelihood를 계산 가능
이는 모델의 성능을 평가하고 비교하는 데 유용
GAN은 log-likelihood 계산이 불가능
DDPM은 이미지를 점진적으로 생성하는 방식을 사용. 이러한 특성으로 중간 단계에서 이미지를 편집하는 것이 용이
Gaussian Noise를 점진적으로 더하거나 제거하는 diffusion model의 특성은 데이터의 고차원 공간에서 효과적인 모델링을 가능 -> 확장성

논문 요약
- 🌧️ 확률적 확산 모델 제시 - 데이터에 점진적으로 노이즈를 추가하여 샘플을 생성하는 마르코프 연쇄 기반 모델.
- 🔍 잡음 제거 점수 매칭과의 연결 - 새로운 파라미터 설정을 통해 잡음 수준을 다양하게 조정하며 훈련 및 샘플링.
- 🔄 진행적 손실 압축 방법론 적용 - 손실 압축 방식으로 데이터를 처리하며, 자기 회귀 디코딩의 일반화로 해석 가능.
1. Introduction
deep generative models이 여러 형태에서 이미지 생성에 성과를 거둠
- generative models의 성장
Generative Adversarial Networks (GANs), autoregressive models, flows, variational autoencoders (VAEs) - Energy-Based Models 및 Score Matching의 발전
Denoising Diffusion Probabilistic Models이 기존 모델과의 차이점
GANs는 적대적 학습을 통해 데이터를 생성
VAEs는 encoder-decoder 구조를 사용하여 잠재 공간을 학습
Autoregressive model은 순차적으로 데이터를 생성
하지만 diffusion은 점진적으로 Gaussian Noise를 추가. 통해 확장성, 안정성
❎ GANs는 불안정한 학습, VAEs는 posterior collapse 문제 발생 가능
❇️ Denoising Diffusion Probabilistic Models은 Variational Inference를 사용하여 학습
따라서 학습 과정이 비교적 안정적
특히, denoising score matching과의 연결 학습 목표

fig2. The directed graphical model considered in this work
Markov Chain (샘플링 과정) 구조 Image Synthesis 과정을 이해하는 데 중요한 역할
-
Forward Process (Diffusion Process)
초기 데이터 에서 시작하여 점진적으로 Gaussian Noise를 더해 최종적으로는 순수한 노이즈 상태로 변환
조건부 확률 로 정의 -
Reverse Process (Generative Process)
Forward Process와 반대로, 순수한 노이즈 에서 시작하여 학습된 전이(transition)를 통해 점진적으로 노이즈를 제거함
실제 데이터와 유사한 생성확률분포를 따름
2. Background
reverse process
P는 의 가우시안 분포를 따르는 확률 분포
평균이 0, 공분산이
결국 노이즈 제거가 우리가 모델에 학습시키고 싶은 부분
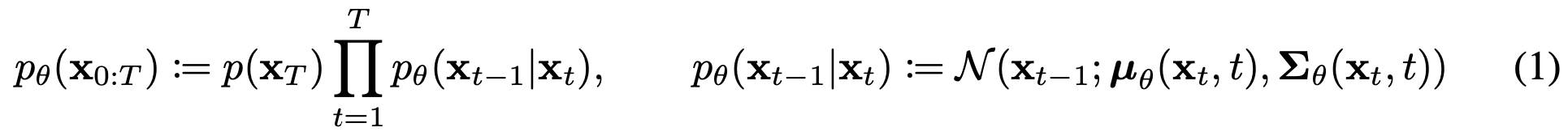
forward process
이 수식은 설계하는 부분
완전한 노이즈 이미지를 생성
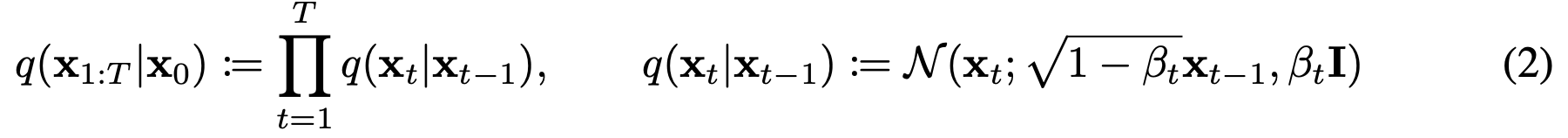
Training
을 우리가 결국엔 잘 학습이 됐는지 궁금한 것
직접 구할 순 없기 때문에 variational inference 변분추론을 활용해서 구함
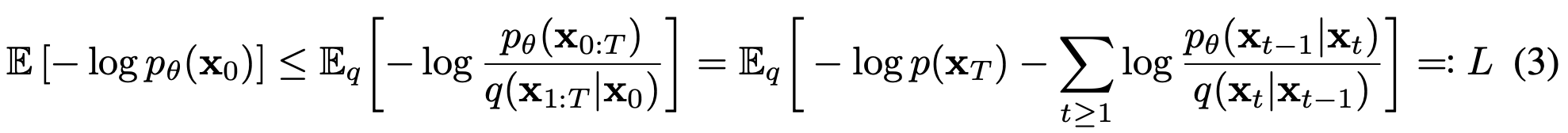
⭐️ 확률 중요
분자: reverse확률
분모: forward 잘 됐는지
따라서, 이 수식이 거꾸로 갈 확률 -> 잘 학습이 됐는지를 보는 분수
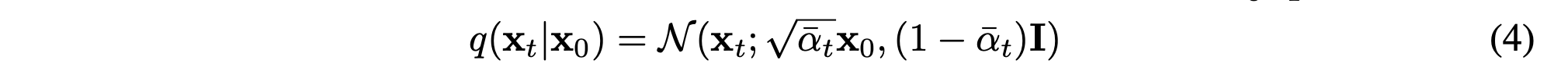
일일이 노이즈를 넣을 필요 없이 한번에 넣을 수 있음
원래 데이터 만 있으면 노이즈 자동으로 들어감
KL Divergence로 분해
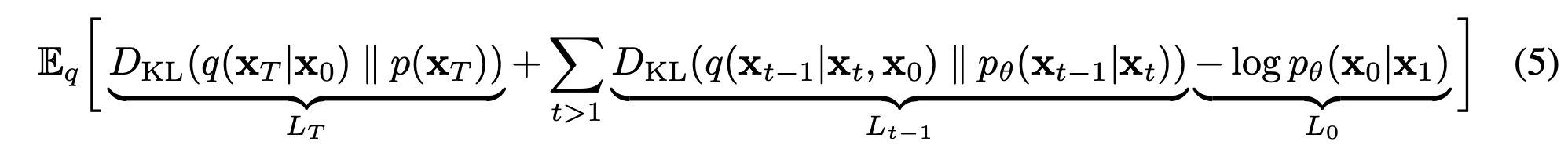
(3)에서 나온 수식을 시간별로 쪼개서 계산할 수 있게 만듦
:맨 마지막 에서의 노이즈 분포와 prior(보통 )사이 차이
: 각 term 마다의 차이
: 최종데이터가 실제 데이터처럼 보이게끔
(6) 은 (4)의 Markov Chain에 대한 와 을 알면 은 구해지는 수식
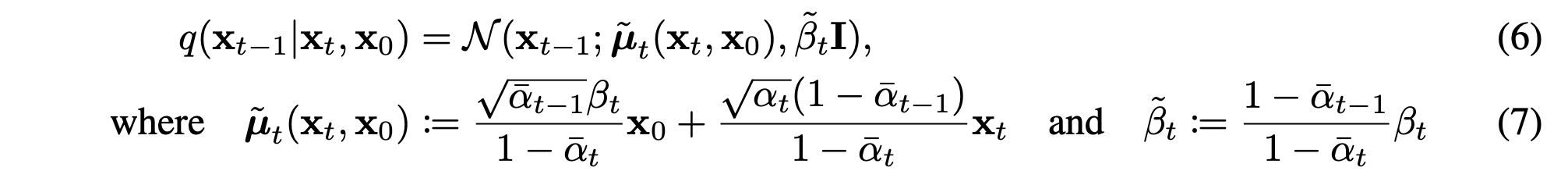
노이즈가 섞인 와 원본 을 알면, 이전 단계 의 분포도 정확하게 계산할 수 있음
(7) 수식
(6)의 평균 와 분산 를 정확하게 계산할 수 있다.
3. Diffusion models and denoising autoencoders
이 과정이 사실 denoising autoencoder랑 비슷
3.1 Forward Process and LT
노이즈의 세기(βₜ)를 그냥 고정된 값으로 사용하면서, forward 과정에서는 이미지를 망가뜨리는 중
따라서, 이 부분은 학습하지 않음. 고정된 값 넣으니까!
⭐️ 3.2 Reverse Process and L₁:T₋₁
우리가 학습하고 싶은 부분
Reverse Process, 이걸 잘 학습해야 좋은 결과
기존 방식은 forward 과정의 평균(μ̃ₜ)을 직접 예측
-> 노이즈 ε를 예측하자
깨진 이미지 = 원래 이미지 + 노이즈
💡 원래 이미지 알고, 깨진 이미지 있으니까 노이즈를 구할 수 있다.
결국엔, denoising score matching이랑 Langevin dynamics임
denoising autoencoder 같은 구조
3.3 Data Scaling and L₀
이미지 데이터를 [−1, 1] 범위로 정규화. 안정적으로 학습
정규화 하지 않으면 노이즈가 너무 적거나, 사이즈가 안 맞는 문제, exploding gradient
ε ∼ N(0, 1)인데 픽셀이 150이면, 노이즈가 거의 티도 안 남
픽셀 단위의 구간 [δ⁻, δ⁺] 사이에 정규분포 확률을 적분
가 정수로 이뤄져 있는 픽셀 값으로 정확한 log-likelihood 계산을 할 수 잇게 함
-> Variational bound를 통해 lossless compression이 가능
Variational bound를 통해 lossless compression 할 수 있는게 왜 좋은데?
- Variational bound
GAN의 출력값을 보면 사람이 잘 만들었다. 라고 판단은 할 수 있겠지만 정량적인 평가를 할 수 없다.
하지만, diffusion 모델은 ELBO (variational bound)를 통해 를 근사할 수 있음 - lossless compression
lossless compression은 이 모델이 데이터를 그 어떤 정보도 버리지 않고 재현할 수 있다는 것을 뜻함 = 정확한 확률 분포를 모델이 학습했다
마지막에서, 확률적인 정수 디코딩을 통해 log-likelihood를 계산
3.4 Simplified Training Objective
원래는 더 복잡한 수식이지만, 더 단순하게
랜덤한 노이즈가 섞인 이미지를 입력 -> 노이즈 ε 예측
단순한 방식이 오히려 더 좋은 예측 결과!
기존 모델과 diffusion model의 차이점
GAN: 샘플 퀄리티는 좋지만 likelihood는 못 씀
VAE: likelihood는 되지만 샘플이 뿌옇고 별로임
근데 diffusion은? 샘플 퀄리티도 좋고, log-likelihood도 계산 가능하고, compression도 된다!
Background 지식
Denoising Autoencoder (DAE)란?
노이즈가 섞인 데이터를 입력으로 주고, 원래 데이터를 복원하는 모델
Diffusion 모델에서 (노이즈 섞인 이미지)-> 를 복원하고 싶잖아?
→ 이게 바로 denoising 문제
해당 모델에서는 reverse 부분에서 노이즈가 섞인것을 복원을 하는 과정이 DAE
Langevin Dynamics란?
데이터 분포의 "모양"을 따라가면서 조금씩 이동하는 방식
: 데이터 분포의 방향으로 이동
: 두 노이즈를 잘 섞이게 해줌
매 단계마다 조금씩 복원 + 약간의 랜덤성 포함
→Langevin Dynamics처럼 동작
