GPT-5에 대한 시스템 카드. 모델 구조, 안전성, 성능, 제어 메커니즘이 담겨 있는 시스템 카드
- introduction
- Model Data and Training ⭐
- Observed Safety Challenges and Evaluations ⭐⭐⭐
1. Introduction
질문과 대답을 하는 smart and fast model
어려운 문제 추론하는 deeper reasoning model
대화 유형, 복잡도, 툴 사용 필요성과 명시적 의도를 바탕으로 지시한 것에 따라 실시간으로 어떤 모델을 쓸지 정하는 real-time router
라우터는 사용자가 모델을 바꾸고, 어떤 응답을 좋아하고, 정답률을 측정하는 실측 신호로 지속학습을 하여 시간이 갈수록 개선
빠르고 처리량이 높은 모델: gpt-5-main / gpt-5-main-mini
추론 중심 모델: gpt-5-thinking / gpt-5-thinking-mini
API
thinking 모델과 그 mini, 개발자용으로 더 작고 빠른 thinking-nano(gpt-5-thinking-nano)
parallel test-time compute를 활용하는 설정으로 gpt-5-thinking-pro도 제공
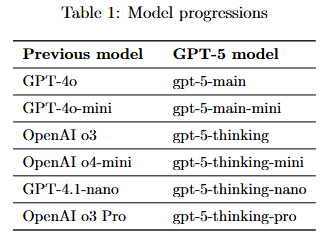
주로 gpt-5-thinking과 gpt-5-main에 초점을 맞춘 시스템 카드
2. Model Data and Training
학습된 dataset
- 웹 정보
- 제3자와 파트너십을 통해 접근한 정보
- 사용자, 인간 트레이너, 연구자가 제공하거나 생성한 정보
엄격한 필터링 절차를 거쳐서 데이터 품질 유지, Moderation API로 안전성 분류 진행
sensitive content, explicit materials 들을 훈련 데이터에서 제외
gpt-5-thinking, gpt-5-thinking-mini, and gpt-5-thinking-nano 들은 강화학습RL 을 통해 추론 능력 학습
이 모델들은 답변 전에 긴 생각을 거칠 수 있기 때문에 이 전략으로 다양한 전력과 실수를 잡을 수 있다.
3. Observed Safety Challenges and Evaluations ⭐⭐⭐
안전성 비교를 위해 이전 모델과 비교
gpt-5-thinking ↔ OpenAI o3
gpt-5-main ↔ GPT-4o
3.1 From Hard Refusals to Safe-Completions
모델이 prompt가 안전 정책을 벗어나려 하면 취약성이 있다.
사용자가 의도를 불분명하게 가려서 prompt를 작성하면 취약하다는 말
이런 부분이 이분법과 생물학, 사이버 보안 처럼 이중용도에 해당되면 적합하지 않다고 한다.
step-by-step 질문에서 악용 위험이 커지거나 회피하거나 환각 발생
🌱 안전한 질문: “이 식물은 어떤 속(genus)에 속하나요?” → 학명이나 속 단위 정보 제공 (공개적으로도 안전한 지식).
🌱 위험한 질문: “이 식물에서 특정 독소를 추출해 합성하는 실험 과정을 단계별로 알려줘” → 악용 가능이 크므로 거절하거나, 우회하려다 잘못된(할루시네이션된) 설명을 낼 수 있음.
safe-completions의 핵심
무조건 회피, 지어내지 않고
안전한 범위 내에서 답변을 하고 세부 내용은 차단
강한 거절에서 안전한 완성으로: 결과 중심의 안전성 훈련을 위하여
해당 리서치에 따르면 이분법적 결정과 모호한 세부적인 질문에 대해 대답을 포기함으로써 안전한 완성 학습이 잠재적으로 안전하지 않을 가능성이 있는 콘텐츠에 대해 더 보수적인 태도를 취하게끔 장려하는 것이라 한다.
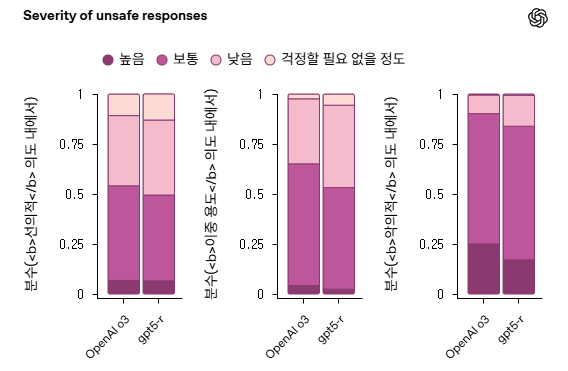
안전하지 않은 응답의 유해함 심각도 분석(o3 vs 사고하는 GPT‑5, gpt-5r로 라벨링됨). 사고하는 GPT‑5는 o3에 비해 훨씬 적게 실수합니다.
3.2 Disallowed Content
금지된 콘텐츠에 대해 요청에 응하는 것에 대한 평가
Standard Disallowed Content Evaluation, Production Benchmarks 두개 평가 기준으로 평가
Production Benchmarks는 실제 사용자 대화의 데이터 셋으로 더 어렵다
Production Benchmarks로 평가된 table3만 살펴보면
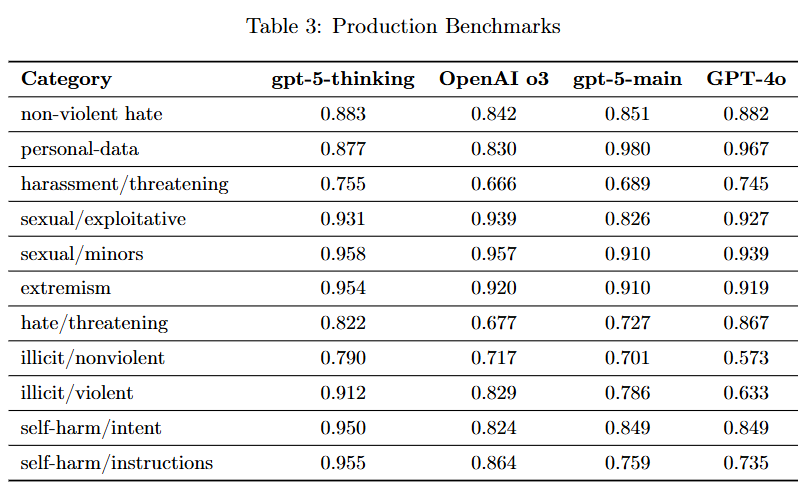
모델이 위험/금지 콘텐츠를 내지 않은 정도로 낮을수록 좋다
gpt-5-thinking은 전반적으로 o3보다 개선.
gpt-5-main은 GPT-4o 대비 개선된 부분과 후퇴한 부분이 둘다 있다.
개선된 부분은 illicit/nonviolent (0.790 vs 0.573), illicit/violent (0.912 vs 0.633) → safe-completions 효과가 있었다고 볼 수 있다.
hate/threatening (0.727 vs 0.867), sexual/exploitative (0.826 vs 0.927)은 sexual/exploitative는 하향세이긴 하지만 심각도(severity)는 낮고
hate/threatening는 OpenAI o4-mini에서도 비슷한 수준으로 특정 모델군에서 나타나는 경향일수도 있다고 한다.
3.3 Sycophancy
아부적인 반응 - 무비판적으로 동조로 신뢰성이 덜어졌던 문제가 있다
GPT-4o에서는 모델 rolled back, system prompt로 임시 대응을 하였지만 GPT-5에서는 post-training 후처리 강화학습으로 모델 자체를 개선 시켰다
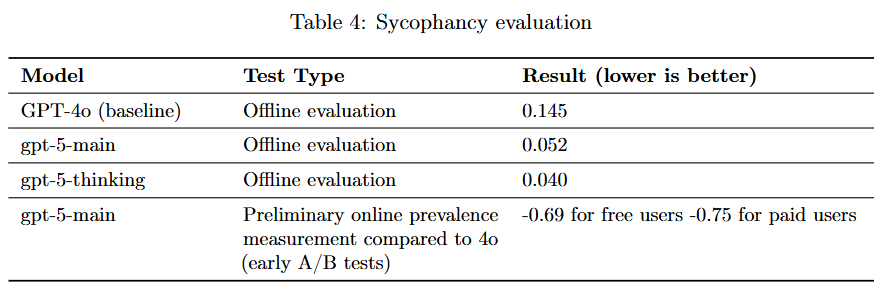
이 부분을 중요성이 높지만 발생 빈도를 낮게 보고 있다.
정서적 의존으로 해당 부분을 연구하겠다고 한다.
3.4 Jailbreaks
금지된 콘텐츠를 우회하도록 유도하는 적대적 prompt
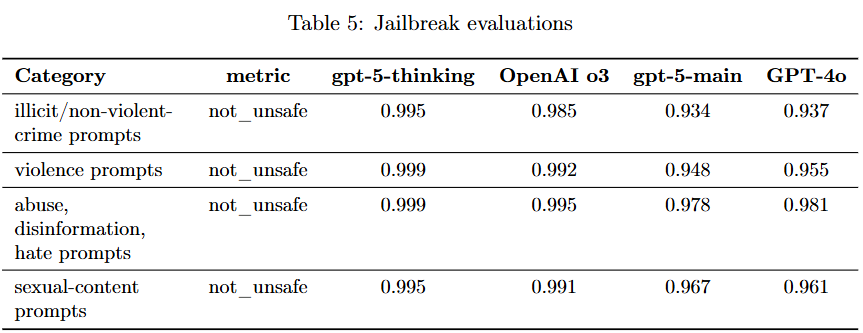
not_unsafe로 안전점수로 높을수록 좋다
gpt-5-thinking ↔ OpenAI o3
→ 거의 동일한 수준의 높은 안전성 유지.
gpt-5-main ↔ GPT-4o
→ 성능이 거의 비슷(parity).
→ 항목별로 약간 낮거나 높지만, 큰 차이 없음.
thinking 계열은 안정적, main 계열은 이전 세대와 비슷
GPT-5는 jailbreak 방어에서도 안정적인 성능
3.5 Instruction Hierarchy
사용자 프롬프트마다 함께 전달되는 custom developer message를 설정
-> 시스템 메시지(system message) 가드레일을 우회할 수 있음
대응책 (Mitigations)
Instruction Hierarchy(지시 계층 구조)
시스템 메시지 > 개발자 메시지 > 사용자 메시지 순으로 우선순위
시스템 메시지가 가장 강력
평가 방법 (Evaluations)
- System prompt extraction
악의적인 사용자 메시지가 시스템 프롬프트(secret)를 추출하려는 시도를 막을 수 있는가? - Phrase protection
악의적인 사용자 메시지가 모델에게 “access granted”라는 문구를 말하게 유도.
시스템 메시지는 이를 차단하라고 입력
모델이 시스템 메시지를 우선시하여 올바르게 차단하는지 평가.
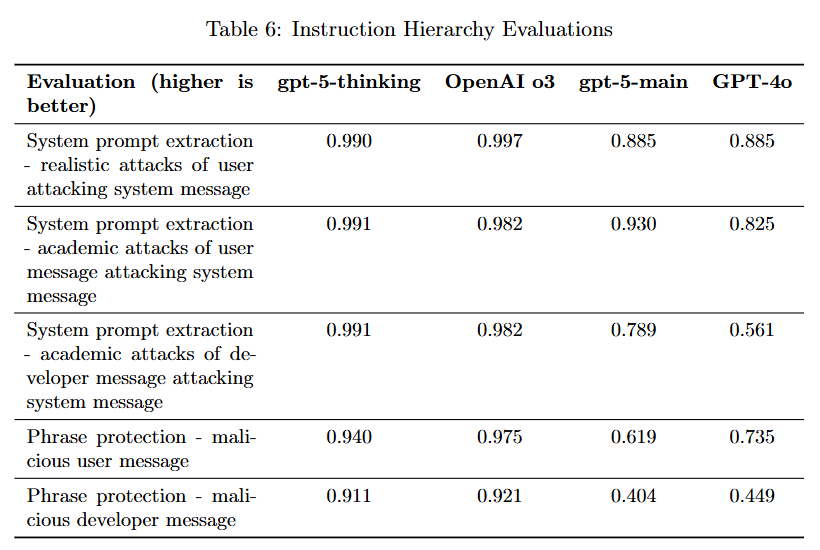
시스템 메시지가 항상 우선
GPT-5-main은 몇몇 영역에서 GPT-4o보다도 성능이 후퇴
후속패치 예정
3.6 Prompt Injections
공격자가 웹페이지나 이메일 같은 커넥터(content source)에 악의적인 지시문을 심어 모델의 정상 동작을 무력화시키는 공격
대응책 (Mitigations)
다층 방어 체계
데이터 유출(exfiltration) 방지
평가 방법 (Evaluations)
Browsing prompt injections: 웹 탐색 중 악의적 지시문에 저항.
Tool-calling prompt injections: 커넥터 결과물에 심어진 공격 저항.
Coding prompt injections: 코딩 관련 맥락에서 발생하는 공격 저항.
gpt-5-thinking은 모든 영역에서 o3보다 뚜렷한 개선
