[논문 리뷰] Transformers and genome language models
기존에 있던 트랜스포머와 유전체 언어 모델에 대한 연구들을 종합 및 정리 하는 논문입니다.
https://www.nature.com/articles/s42256-025-01007-9
LLM이 발전하면서 유전체 해독에도 LLM이 사용되고 있습니다.
연구자들은 자연어 처리를 위해 개발된 트랜스포머(Transformer) 아키텍처를 유전체 데이터에 적용한 것이 유전체 언어 모델(genomic Language Models, gLMs)'이라 한다.
Abstract
Transformer 기반 LLM이 NLP 혁신을 불러와서 유전체에도 적용하고자 한다.
gLM의 중요성이 대두 되고 있고 그 중에 unsupervised pretraining, zero-/few-shot 학습의 잠재력 강조되고 있다.
An open problem in genomics
단백질을 코딩하는 부분은 겨우 2% → 나머지 98% 비코딩 DNA의 기능을 한다.
아직은 비코딩(non-coding) DNA이 정확하게 무엇을 규명하는지 밝혀지지 않은 상태지만 쓰레기 서열(junk DNA)이 아닌, 유전자 발현(regulatory grammar)에 도움을 주는 배열을 하고 있다.
What data do deep learning models for genomics train on?
- DNA 서열 (Genomic sequences)
A, T, G, C 네 가지 염기로 이루어진 DNA 서열
해당 서열을 딥러닝 모델은 텍스트로 인식 - DNA 인코딩 & 토큰화 방식
One-hot encoding
Tokenization
k-mer / BPE 토큰화 - 멀티모달 데이터 (Sequence + Functional data)
ATAC-seq, DNase-seq, ChIP-seq, RNA-seq, single-cell RNA-seq, Hi-C, CRISPR perturbation 실험
ATAC-seq, DNase-seq → DNA 접근성(accessibility)
ChIP-seq → 단백질-DNA 결합 정보
RNA-seq, single-cell RNA-seq → 전사(transcription) 정보
Hi-C → 3차원 게놈 구조(contact map)
CRISPR perturbation 실험 → 특정 비코딩 DNA를 조작해 발현 변화 관찰
Why transformers and gLMs?
기존 딥러닝 모델의 한계
CNN은 지역적 패턴을 잘 잡지만, 장거리 의존성(long-range dependency) 은 놓치기 쉽다.
RNN은 순차적 구조라 멀리 떨어진 서열 정보를 기억하는 데 약하다.
트랜스포머의 강점
트랜스포머는 Self-Attention 메커니즘이라는 특징으로 서열 전체에서 모든 위치 간 관계를 동시에 학습할 수 있다.
따라서 뉴클레오타이드 간 거리가 멀어도 상호작용을 포착 가능하여 게놈 데이터의 장거리 상관관계를 모델링하기에 적합하다.
gLMs(Genome Language Models)의 필요성
게놈 데이터는 대부분 라벨 없는(unlabeled) 상태
gLMs는 사전학습(pretraining) 을 통해 라벨 없이도 패턴을 학습이 가능하다.
- MLM (Masked Language Modeling): 일부 뉴클레오타이드를 가려두고 맞히기
- ALM (Autoregressive LM): 앞 부분을 보고 다음 뉴클레오타이드 예측하기
fig1. 유전체 언어 모델(gLM) 작동
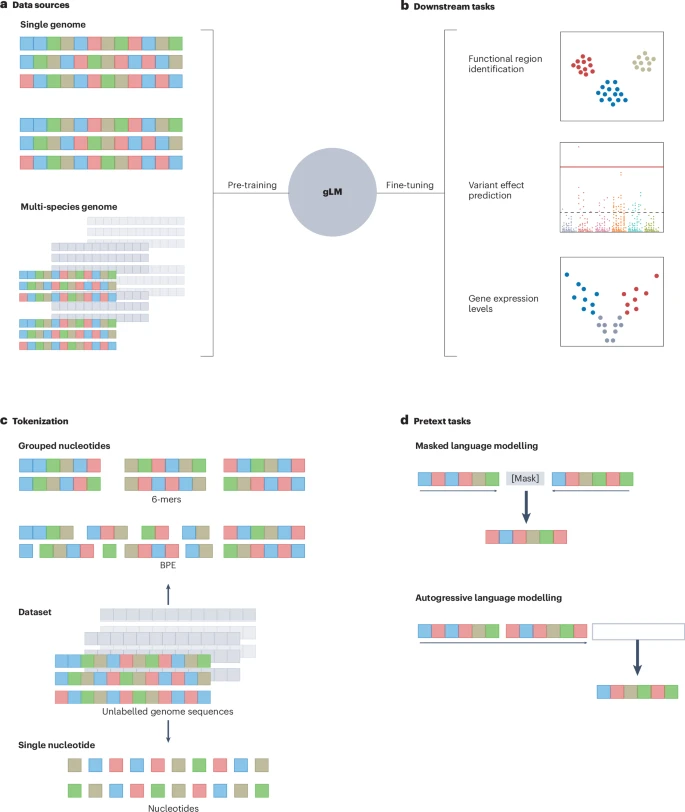
a: 한 종(예: 인간)의 유전체 데이터만 사용할 수도 있고, 더 나아가 여러 종(multi-species)의 유전체 데이터를 함께도 학습이 가능하다.
여러 종의 데이터를 사용하면 진화적으로 보존된 중요한 정보를 학습할 수 있어 더 강력한 모델이다.
c: DNA 서열 토큰화 진행
Single nucleotide: 염기 하나하나를 토큰으로
k-mers: 염기를 'k'개씩 묶어서 하나의 단어(토큰)처럼 취급 (예: 6-mers).
BPE (Byte-Pair Encoding): 데이터에서 자주 함께 등장하는 염기 서열을 하나의 토큰으로 묶음
d: 토큰화된 데이터를 이용해 모델이 '스스로(self-supervised)' 유전체의 문법을 배우게 하는 과정
b: 다운스트림 태스크
실전에 투입하기
기능적 영역 식별 (Functional region identification): 유전자 발현을 조절하는 프로모터, 인핸서 같은 중요한 DNA 영역을 찾아냄
변이 효과 예측 (Variant effect prediction): 특정 유전자 변이(돌연변이)가 질병을 유발할지 아닐지 예측
유전자 발현 수준 예측 (Gene expression levels): 특정 DNA 서열이 얼마나 많은 유전자를 만들어낼지 예측
Fig 2. 딥러닝 모델 5종, DNA 서열을 읽는 각기 다른 방법
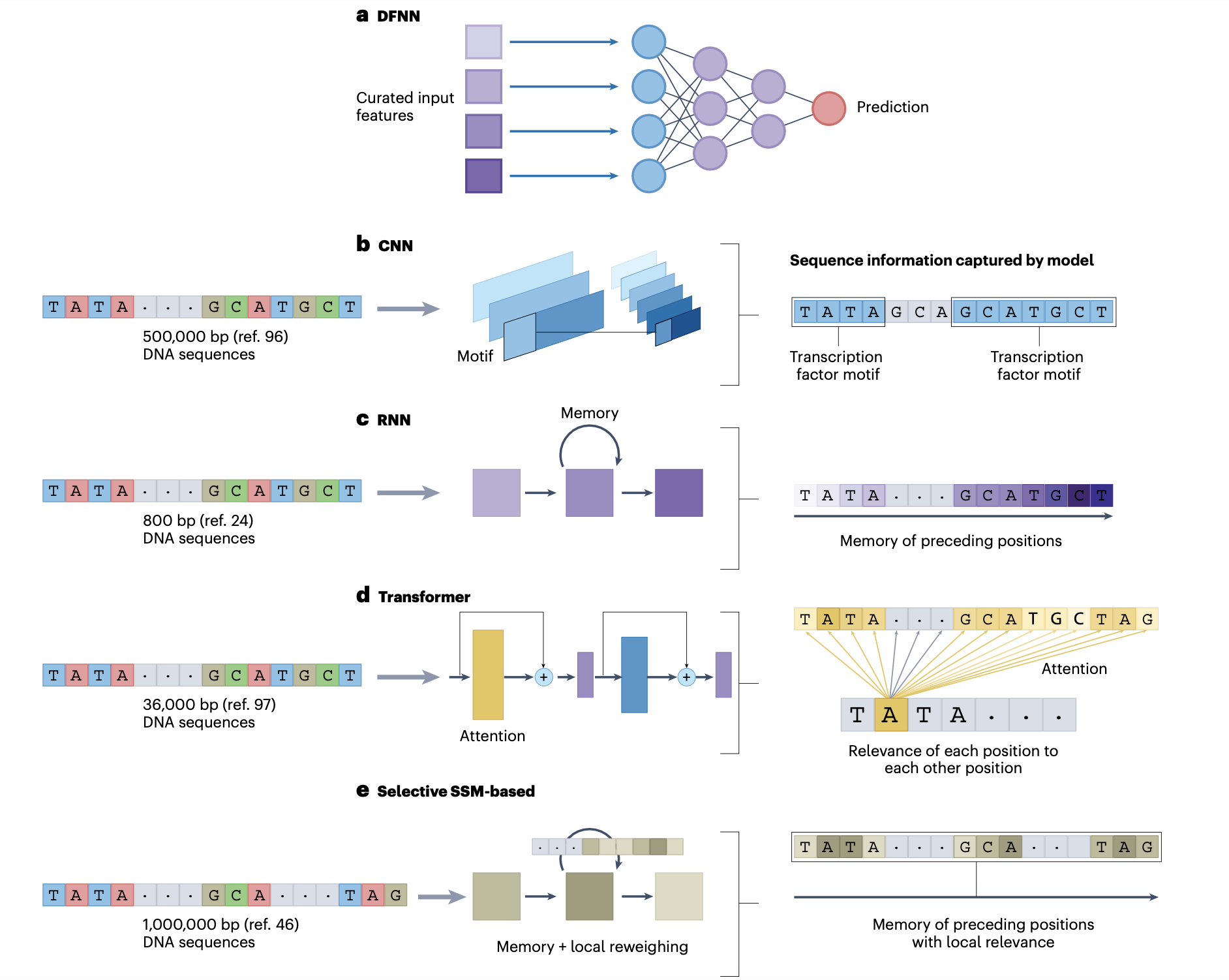
(a) DFNN (Deep Feed-Forward Neural Network)
입력: 사람이 직접 고른 특징(feature set)
단점: DNA 서열 자체를 직접 처리하지 않고, 사전 정의된 특징에 의존
→ 유연성이 낮고, 새로운 패턴을 스스로 발견하기 어려움
(b) CNN (Convolutional Neural Network)
입력: DNA 서열 전체.
동작: 합성곱 필터가 슬라이딩하면서 지역적 패턴(모티프) 을 탐지
예: 프로모터, 전사 인자 결합 서열 등 반복적으로 나타나는 모티프
장점: 지역 패턴 탐지에 강함
한계: 긴 거리(long-range) 상호작용은 포착하기 힘듦
(c) RNN (Recurrent Neural Network)
입력: DNA 서열을 순차적으로 읽음
동작: 앞서 본 서열 정보를 메모리(hidden state) 에 저장하면서 다음 위치를 예측
장점: CNN보다 더 긴 서열 의존성 반영 가능
한계: 긴 서열이 되면 장기 의존성 소실 문제 발생 (정보를 잊어버림)
(d) Transformer
입력: 비교적 짧은 DNA 서열.
동작: Self-Attention 메커니즘으로 서열 내 모든 위치 간 관계를 동시에 학습.
장점:
중간 범위~긴 범위 의존성까지 포착 가능.
글로벌 컨텍스트 모델링 (서열 전체 패턴을 한꺼번에 본다는 의미).
한계: 입력 서열이 길어질수록 계산량이 제곱적으로 증가(quadratic cost) → 긴 DNA를 그대로 처리하기 힘듦.
(e) Selective SSM (State Space Model 계열, 예: HyenaDNA)
RNN처럼 전체 서열을 순차적으로 훑지만,
단순히 “기억”하는 게 아니라, 이전 서열 정보에 따라 새로운 입력을 재맥락화(recontextualize) 함.
장점:
매우 긴 서열(수십만~백만 bp)을 처리 가능.
메모리 효율적, 연산 비용이 트랜스포머보다 훨씬 낮음.
→ “포스트 트랜스포머(post-transformer)” 후보로 주목받고 있음.
Transformers
Architecture
구성 요소: Self-Attention(Multi-Head), Feed-Forward Layers, Layer Normalization, Skip Connections.
형태: Encoder–Decoder 구조가 원형이지만, Encoder-only (BERT 계열), Decoder-only (GPT 계열) 로 변형되어 사용됨
학습 방식:
BERT (Encoder-only) → Masked Language Modelling(MLM). 게놈 서열 “이해(interpretation)”에 강점.
GPT (Decoder-only) → Autoregressive LM(ALM). 앞 서열을 보고 다음 뉴클레오타이드 생성. 게놈 서열 “생성(prediction)”에 강점.
Training
Pretraining (사전학습)
대부분의 게놈 데이터는 라벨이 없는(unlabeled) 상태 → self-supervised pretraining 필요.
대표적 과제(Pretext tasks):
MLM (Masked Language Modelling) → 일부 뉴클레오타이드 마스킹 후 맞히기 (BERT 스타일).
ALM (Autoregressive Language Modelling) → 앞 서열을 보고 다음 뉴클레오타이드 예측 (GPT 스타일).
목적: 대규모 게놈 서열에서 문법/패턴을 먼저 학습.
Fine-tuning (파인튜닝)
Pretraining 후, 소규모 라벨링 데이터셋으로 특정 태스크에 맞게 조정.
경우에 따라 초기 레이어는 고정(freeze), 마지막 레이어만 학습.
예: 전체 게놈으로 pretraining → 프로모터 예측 task로 fine-tuning.
SSMs and beyond
시퀀스 데이터를 입력(xₜ) → 상태(hₜ) → 출력(yₜ) 구조로 표현.
현재 트랜스포머는 강력하지만 긴 DNA 서열을 다룰 때 계산량이 너무 크다(O(n²)).
SSM (State Space Model)
원래 제어이론에서 온 모델.
RNN과 비슷하게 순차적으로 읽고 메모리를 유지.
선택적으로 “기억할 것 / 버릴 것”을 정하는 Selective SSM으로 발전.
의미
트랜스포머가 지금은 주류지만, 긴 서열 처리 효율에서는 SSM 계열 모델들이 더 유망.
Hybrid models and gLMs
The transformer
트랜스포머는 Self-Attention, Feed-Forward Layers, Normalization, Skip Connections으로 구성된 딥러닝 구조
원래는 Encoder–Decoder 형태였지만, BERT(Encoder-only, MLM 학습)와 GPT(Decoder-only, ALM 학습) 같은 변형으로 발전. 장기 의존성이 높아서 유전체 데이터에서도 좋은 모델
Hybrid models: assay prediction
Enformer, Borzoi, C.Origami 같은 하이브리드 모델은 특정 실험 데이터(발현, 조절 요소, 3D 구조)를 예측하는 데 특화
라벨된 데이터로 지도학습을 하기 때문에 특정 과제 성능은 매우 높지만, 데이터가 부족하면 한계
Transformers: gLMs
DNABERT, Nucleotide Transformer, GENA-LM 등은 게놈 언어 모델(gLMs)로 불립니다.
라벨이 없어도 Self-supervised pretraining(MLM, ALM)을 통해 방대한 DNA 데이터를 학습합니다.
이후에는 Zero-shot이나 Few-shot으로 다양한 문제에 적용할 수 있습니다.
범용형 모델이라는 점이 큰 강점입니다.
Beyond the transformer
최근에는 트랜스포머의 계산 비효율을 극복하려는 시도로 SSM 기반 모델들이 등장
- HyenaDNA: 100만 bp 이상의 긴 서열 처리 가능
- Evo: 원핵생물 게놈 학습, 변이·발현 예측에 활용
- GPN: Attention 대신 CNN으로도 사전학습 성능 확보
더 긴 서열을 효율적으로 분석할 수 있게 됐다. “포스트 트랜스포머 시대”의 가능성을 볼 수 있다.
A comparison
Hybrid models: 지도학습(supervised), 실험 데이터(assay prediction)에 최적화 → 특정 태스크에서 높은 성능.
gLMs: 비지도 사전학습(self-supervised) 후 다양한 태스크에 전이 → 범용성은 높지만, 사전학습된 임베딩만으로는 성능이 낮게 나올 수 있음.
성능 격차의 이유
훈련 목표 차이:
Hybrid → 특정 과제 정확도 극대화.
gLMs → 범용 표현 학습.
Pretraining 설계 한계: zero-shot 성능이 제대로 검증되지 않은 경우 많음.
계산 비용: gLMs는 파라미터가 훨씬 크고 학습 데이터도 많이 필요함.
모델 결과
Nucleotide Transformer: 유전자 찾기, 인핸서(annotation)에서 강점.
DNABERT: 염색질 접근성, 히스톤 변형 예측에서 좋은 성능.
두 모델 모두 일부 태스크에서 Enformer, Basset 같은 hybrid 모델 성능에 근접.
Limitations
Long-range interactions
트랜스포머는 계산 비용이 커서 수십만~수백만 bp 규모의 DNA를 다루기 어려움
유전자 발현은 장거리 상호작용에 의해 결정되는데, 이를 완전히 모델링하기에는 부족
Cell type specificity
세포 유형별로 다르게 발현
같은 DNA 서열이라도 신경세포, 근육세포, 면역세포에서 전혀 다른 방식으로 작동
같은 유전체라도 세포마다 다르게 작동한다는 점을 gLMs가 아직 잘 반영하지 못한다.
Data privacy
유전체 데이터는 개인을 고유하게 식별할 수 있는 민감 정보
Interpretability
모델이 예측을 잘하더라도, 어떤 생물학적 규칙을 학습했는지를 이해하기 어려움
해석 가능성이 낮으면 연구자들이 모델을 신뢰하기 어렵고, 실제 의학적 응용(예: 변이 진단)에도 제한
