[논문리뷰] Attention Is All You Need
⭐️ transformer가 요즘 비전과 자연어처리 분야에서 많이 보이는 것 같아요
transformer를 처음 제안한 논문인 Attention Is All You Need 논문 리뷰를 해보겠습니다.
Transformer는 자연어 처리 분야에 필수적인 논문으로, 기계 번역에 큰 영향을 미칩니다.
RNN, LSTM, GRU와 같은 이전 연구들을 기반으로 하고 있습니다.
2017년에 발표되어서 현재 인공지능 시장에서 광범위하게 쓰이고 있습니다.
사실 처음에 이름 듣고 정말 잘 지었다고 생각을 했던 논문 중 하나입니다! 획기적인 논문 제목 같다는 생각을 했어요🤩
논문 링크 https://arxiv.org/abs/1706.03762

Transformer의 multi-head attention 기법과 효율성을 강조
1. Introduction
긴 시퀀스를 다룰 때 메모리 제약이 배치 처리에 제한
어텐션 메커니즘은 거리와 상관없이 모델링
Transformer는 RNN, LSTM의 순환성을 배제하고 오로지 어텐션 메커니즘만 사용
따라서 긴 문장에 적합
2. background
seq2seq model
RNN
먼저, RNN
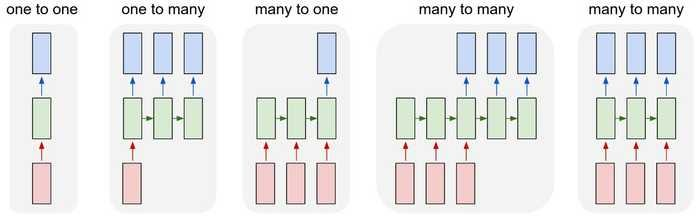
many to many 기법을 사용. 문장을 입력받고 번역된 문장을 출력
초록색 부분에 컴퓨터가 이해할 수 있는 단어로 바꿔서 입력함
이것이 워드임베딩
이 과정에서 각 단어들을 원핫벡터로 표현
후에 각 weight를 곱해서 hidden layer로 만들고 원래의 dimension 으로 돌려놓고 softmax
이후에 실제값과 비교해서 loss가 적은 방향으로 이전 weight를 더해나감
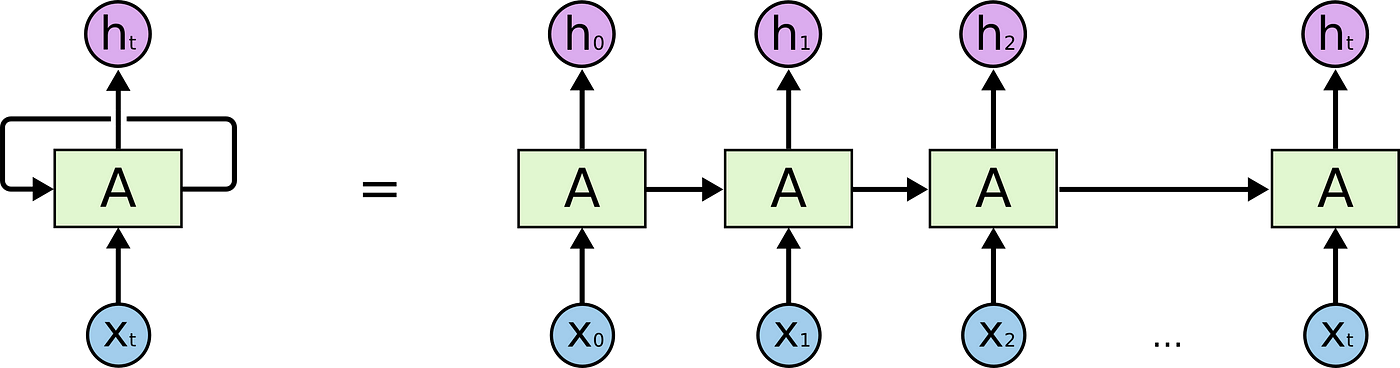
이전 값들을 계속해서 사용하기 때문에
back propagation 과정에서 Vanishing Gradient 문제가 발생
문장이 길면 앞에 부분 맥락을 파악하지 못하는 문제가 발생
이 문제 해결위해 LSTM
LSTM
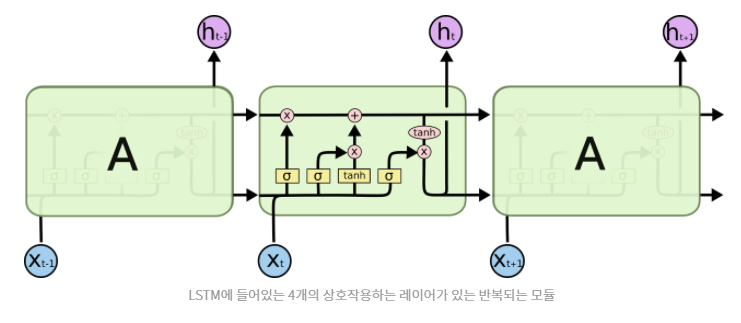
위에서 들어오는 값들이 hidden state(최신) 아래 것들이 과거의 것
즉, 위에서 들어오는 값: short term memory
아래에서 들어오는 값: long term memory
activation function: sigmoid
최근 기억이 0~1 사이이므로, 최근 기억의 중요도에 따라 장기 기억의 중요도 또한 영향을 받음
계속 반복하면 과거의 기억이 최근의 기억에 도움을 받음
단기기억과 현재 정보를 tanh 통과 시키고 sigmoid 거친 최근 기억과 연산해서 다음 hidden state로, 이 값이 output
한개의 layer에 4개의 연산으로 복잡도 높음
따라서 GRU 제안
seq2seq 방식은 결국 한개 백터에 모두 압축해야한다는 단점
를 출력할때 의 영향을 받음
병목현상 발생
3. Model Architecture
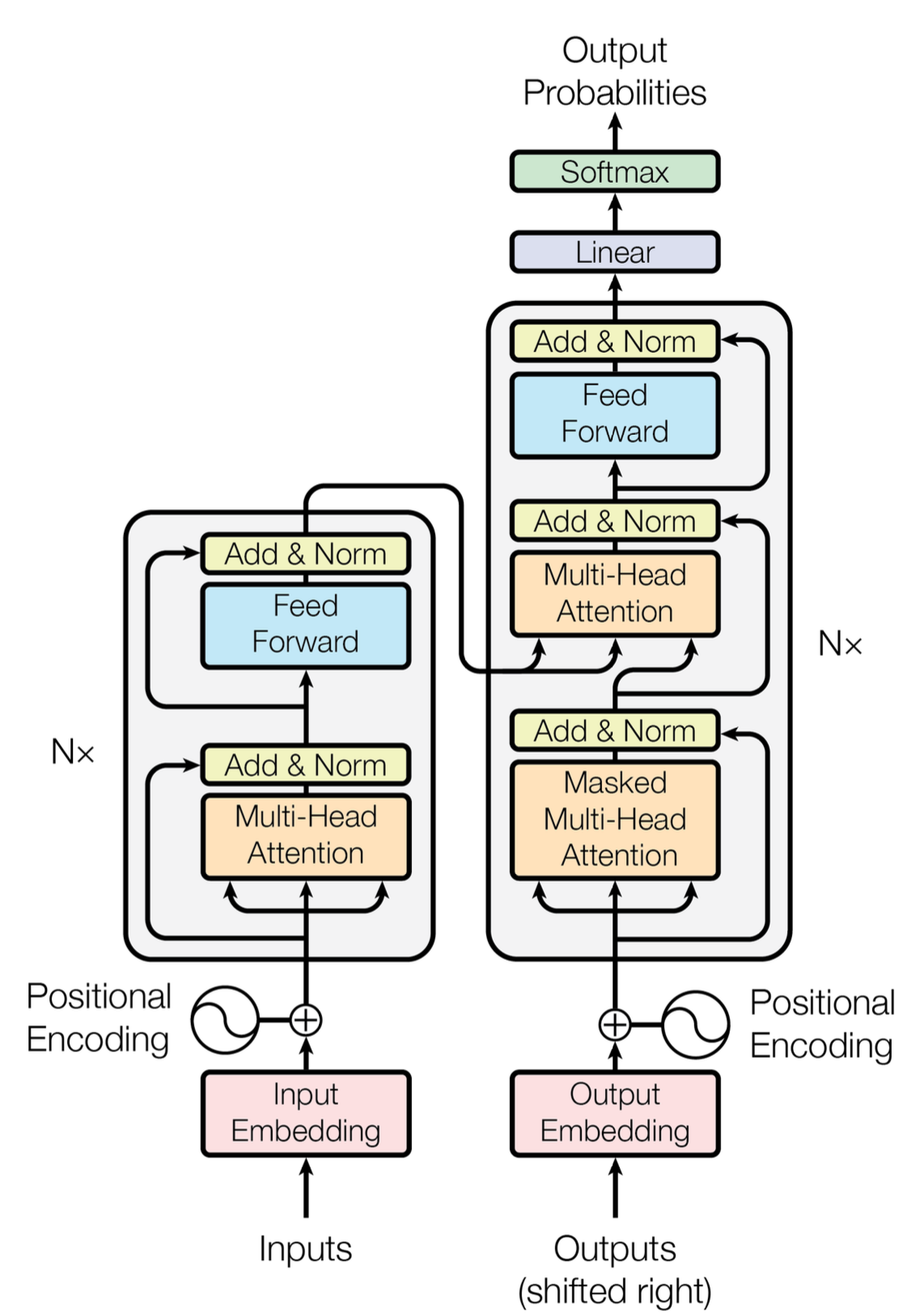
fig1. The Transformer - model architecture.
fully connected layers를 encoder와 decoder 두개 다 갖고 있음
3.1 Encoder and Decoder Stacks
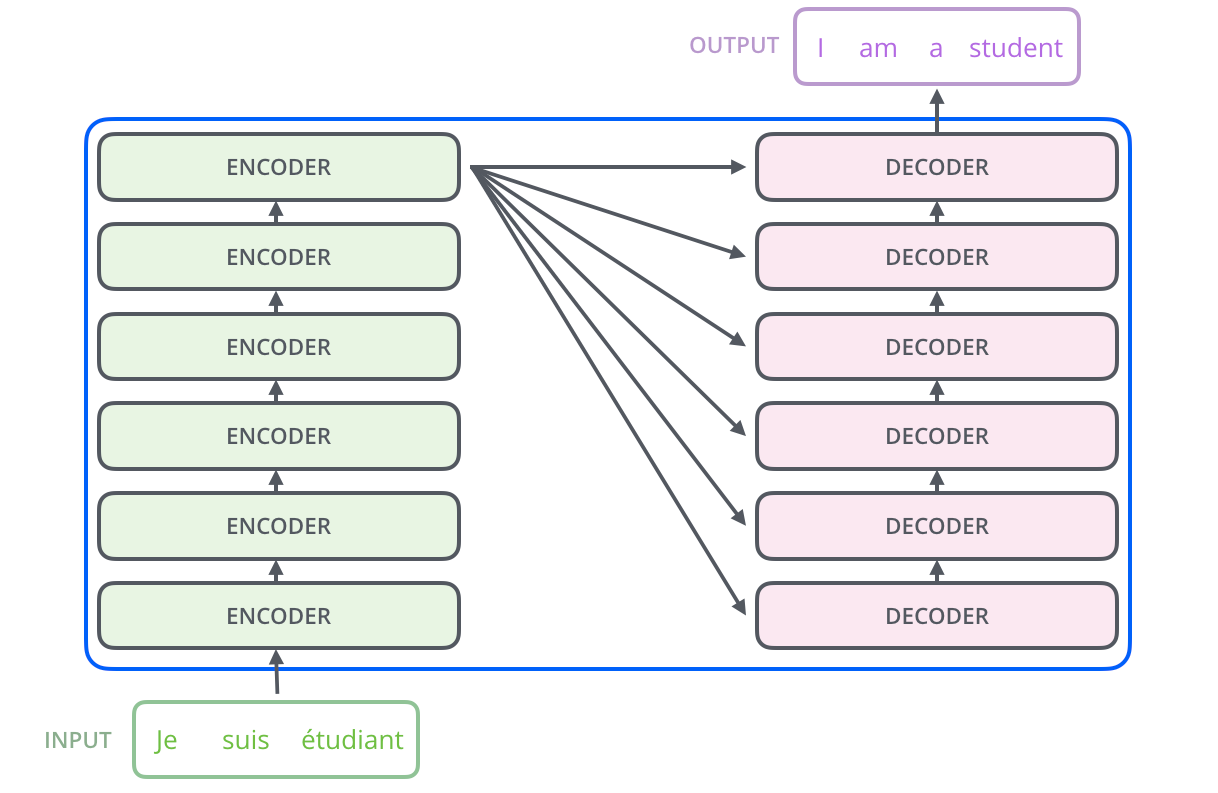
논문에서는 6개의 인코더 디코더 구조로 나와 있음 하지만 6개가 꼭 최적은 아님
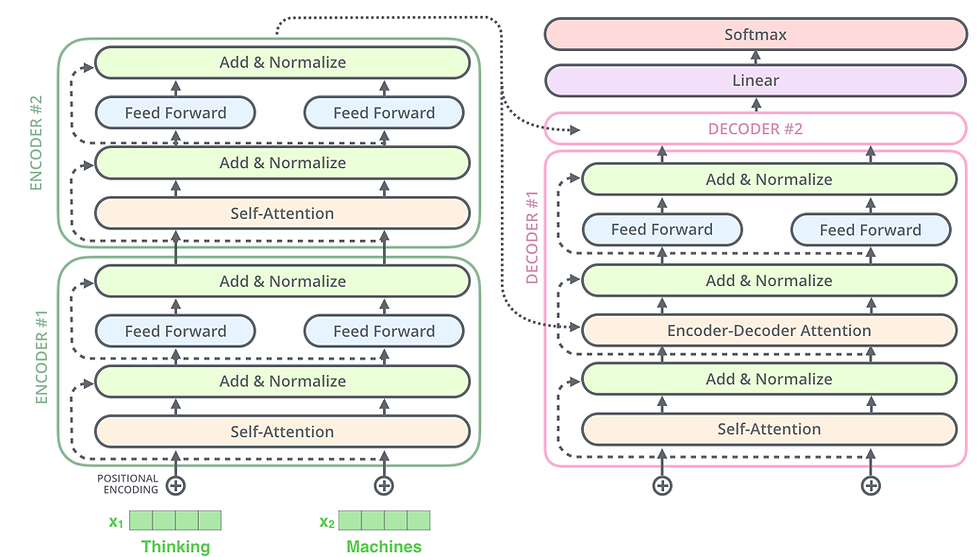
- input으로 Query(Q), Key(K), Value(V) 총 3개
