[논문리뷰] UNETR: Transformers for 3D Medical Image Segmentation
의료 영상 분석 분야에 많이 쓰이는 segmentation 모델 논문 리뷰를 하겠습니다.
transformer를 이용한 모델이라 흥미로웠고,
2D input이 아닌 3D input인 부분이 흥미로워서 논문 선정❤️🔥
Vision transformer 공부를 시작하고 나서 2D는 많이 봤지만 3D는 감이 안잡혔던 것 같아요.~😌
이 논문을 읽기 전에 U-net 논문링크과 vision transformer ViT논문 링크
개념이 있어야 좋을 것 같습니다
따로 정리하기
UNETR: Transformers for 3D Medical Image Segmentation

Transformers를 이용한 3D 의료 영상 세분화(UNETR)
기존의 FCNN(Fully Convolutional Neural Networks) 접근 방식의 한계를 극복하기 위해 새로운 아키텍처를 설계!
FCNN은 CNN에서 fully-connected layer (완전연결층, 전결합층)를 제거하여 CNN의 한계를 극복한 신경망
모든 레이어가 합성곱 연산으로 이루어진 신경망
FCN 논문
스킵 연결을 통해 인코더와 디코더 간의 효과적인 정보 전송을 가능하게 하고, 다중 해상도의 정보를 통합하여 세분화 성능을 향상
1. Introduction
fig1. Overview of UNETR
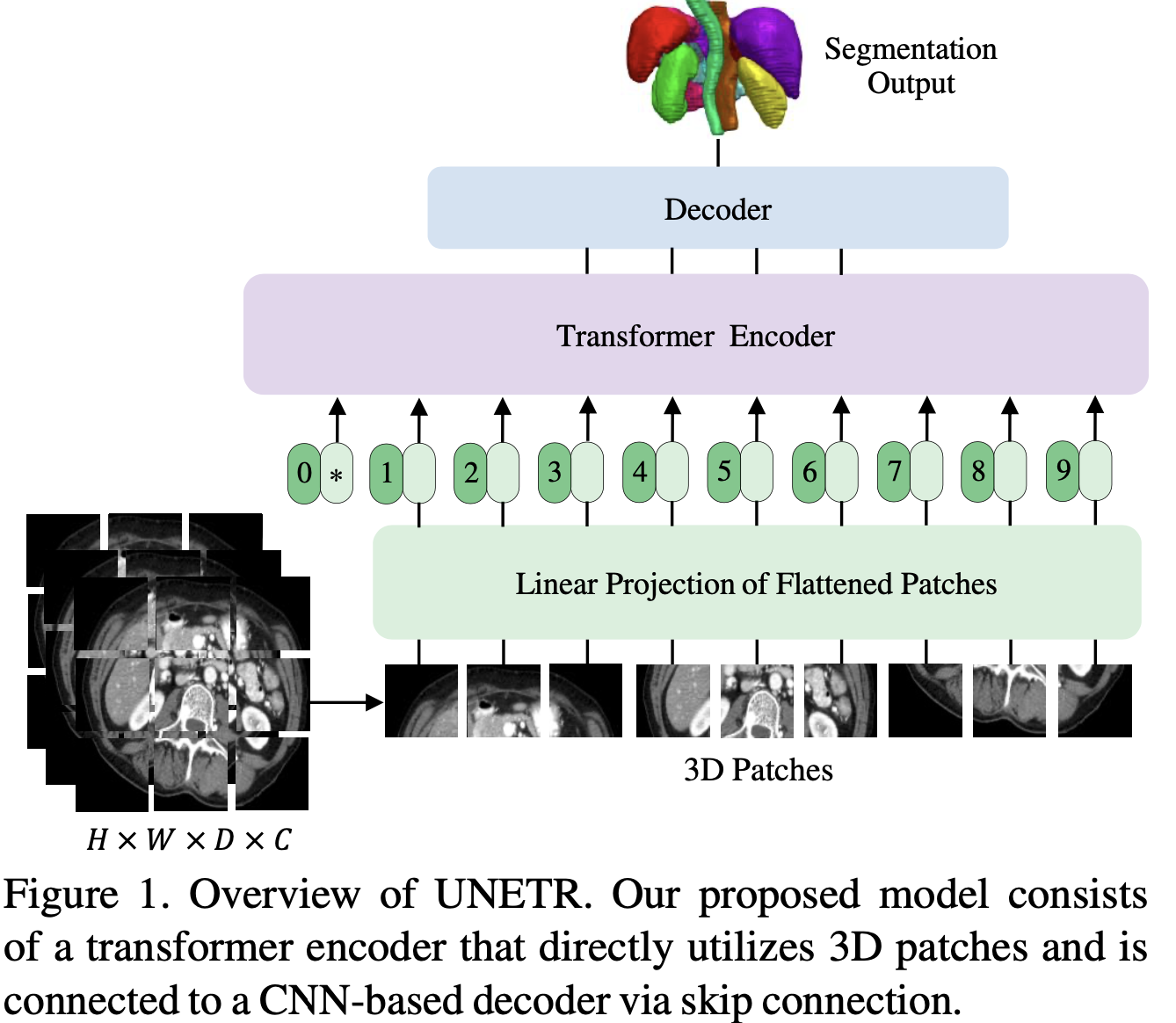
3D 형태의 dataset을 3D patches로 쪼갠 후에 1D로 flatten
- input 3D
- uniform non-overlapping patches
- Multi-Head Self-Attention 입력 데이터의 특성 보존에 집중
위치 정보를 포함하기 위해 learnable positional embedding을 추가 -> 장거리 의존성이 높음
2. Related Work
vision transformers
위치 인코딩 및 계층적 구조를 사용
UNETR은 토큰화된 패치를 직접 활용하여 세그멘테이션 네트워크를 구성하고, CNN 기반 백본에 의존하지 않는 차별점
3. Methodology
3-1. Architecture
UNETR은 인코더로 transformer 스택을 사용하는 contracting-expanding 패턴을 활용하며, 이를 스킵 연결을 통해 디코더와 연결
• H : 높이(Height)
• W : 너비(Width)
• D : 깊이(Depth)
• C : 채널(Channel) 채널 수(RGB의 경우 3) 또는 기타 특성 차원
추출된 패치의 공간 정보를 보존하기 위해서 패치 embedding에 위치 임베딩 추가함
해당 임베딩을 추가한 결과
트랜스포머 기반 모델에서 많이 사용 되는 개념 중 하나인 Patch Embedding
-
입력 이미지 또는 볼륨 데이터를 N개의 패치로 분할한 결과, 각 패치는 고유한 벡터로 표현
- N은 패치 개수
-
: 선형 변환 행렬
-
: 투영된 패치 임베딩 벡터를 순차적으로 연결하여 크기의 시퀀스
-
: 학습 가능한 위치 임베딩
공간적 정보를 보존하기 위해 패치 토큰화와 위치 임베딩을 결합하는 것이 중요한 요소
멀티-헤드 셀프 어텐션(MSA)
다층 퍼셉트론(MLP)
입력데이터 → MSA(상호관계 학습) → MLP(특징 학습)
각 단계에서 norm 진행하여 안정성, 효율성 높음
MSA, MLP 모두 잔차 연결로 기울기 소실 문제 방지
UNETR은 U-Net 아키텍처와 유사하게, 여러 해상도의 인코더로부터 추출된 특징을 디코더와 병합하여 최종 분할을 예측
fig2. Overview of UNETR architecture.
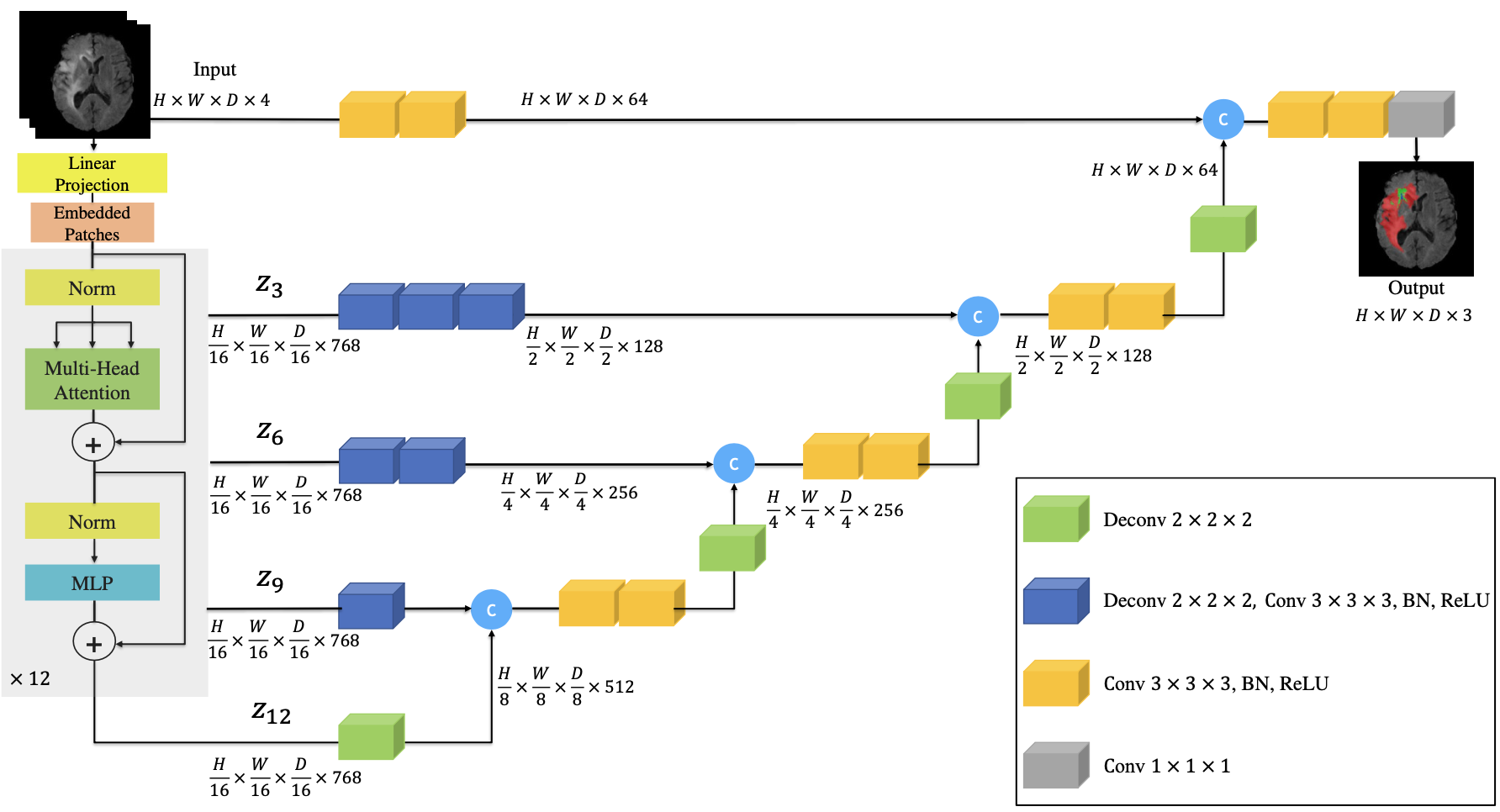
-
입력 (Input)
데이터의 크기 -
패치 분할 (Patch Splitting)
3D 이미지 patch로 나눔 -
패치 임베딩 (Patch Embedding)
선형 변환(Linear Projection) -> 변환된 패치 벡터가 트랜스포머 모델로 전달 -> 위치 임베딩과 더해져서 순서 유지 -
트랜스포머 인코더 (Transformer Encoder)
각 layer들은 MSA, MLP 사용하여 특징 추출
: 서로 다른 레이어에서 추출된 특징 벡터 -
디코더와 스킵 연결 (Decoder with Skip Connections)
고해상도 정보를 유지하면서 점진적으로 해상도를 복원 -
출력(output)
3.2. Loss Function
loss function
-
: Ground Truth.
- -번째 voxel에서 -번째 클래스에 대한 원-핫 인코딩 값 (참값).
-
: 예측 확률값.
- -번째 voxel에서 -번째 클래스에 대한 모델의 출력 확률.
-
: 전체 voxel의 개수.
-
: 클래스의 총 개수.
4. Experiments
4.1. Datasets
BTCV (CT)
30명의 피험자의 복부 CT 스캔
각 CT 스캔은 포털 정맥기(Portal Venous Phase)에서 조영증강(contrast-enhanced) 상태
스캔은 80225개의 슬라이스로 이루어져 있으며, 해상도는 픽셀이고 슬라이스 두께는 16mm
process
각 볼륨은 HU의 강도를 로 정규화
모든 이미지는 등방성(isotropic) voxel 크기 1.0mm로 리샘플링
segmentation
입력 데이터는 1채널 CT 이미지
MSD (MRI/CT)
뇌종양 분할 작업을 위해, 총 484개의 다중 모달(multi-modal) 및 다중 기관(multi-site) MRI 데이터(FLAIR, T1w, T1gd, T2w)와 함께 제공된 교모세포종(gliomas) 분할(괴사/활성 종양 및 부종) 참조 라벨
MRI 영상의 voxel 간격은
voxel 강도는 z-score 정규화를 통해 전처리
segmentation
4채널 입력 이미지(FLAIR, T1w, T1gd, T2w)
4.2. Evaluation Metrics
Dice score와 95% Hausdorff Distance (HD)를 사용
Dice score
Dice 점수는 분할된 영역과 실제 영역의 겹치는 정도를 평가하는 지표
점수 범위는 0에서 1까지이며, 1에 가까울수록 더 정확한 분할
95% Hausdorff Distance (HD)
HD는 두 표면(예: Ground Truth 표면과 예측 표면) 간의 최대 거리를 측정
이를 통해 예측된 경계선과 실제 경계선이 얼마나 일치하는지 확인
이상치(outlier)의 영향을 줄이기 위해 상위 5%의 값은 무시하고 95번째 백분위수 값을 사용
값이 작을수록 좋음
4.3. Implementation Details
fig4. Qualitative comparison of different baselines in BTCV cross-validation
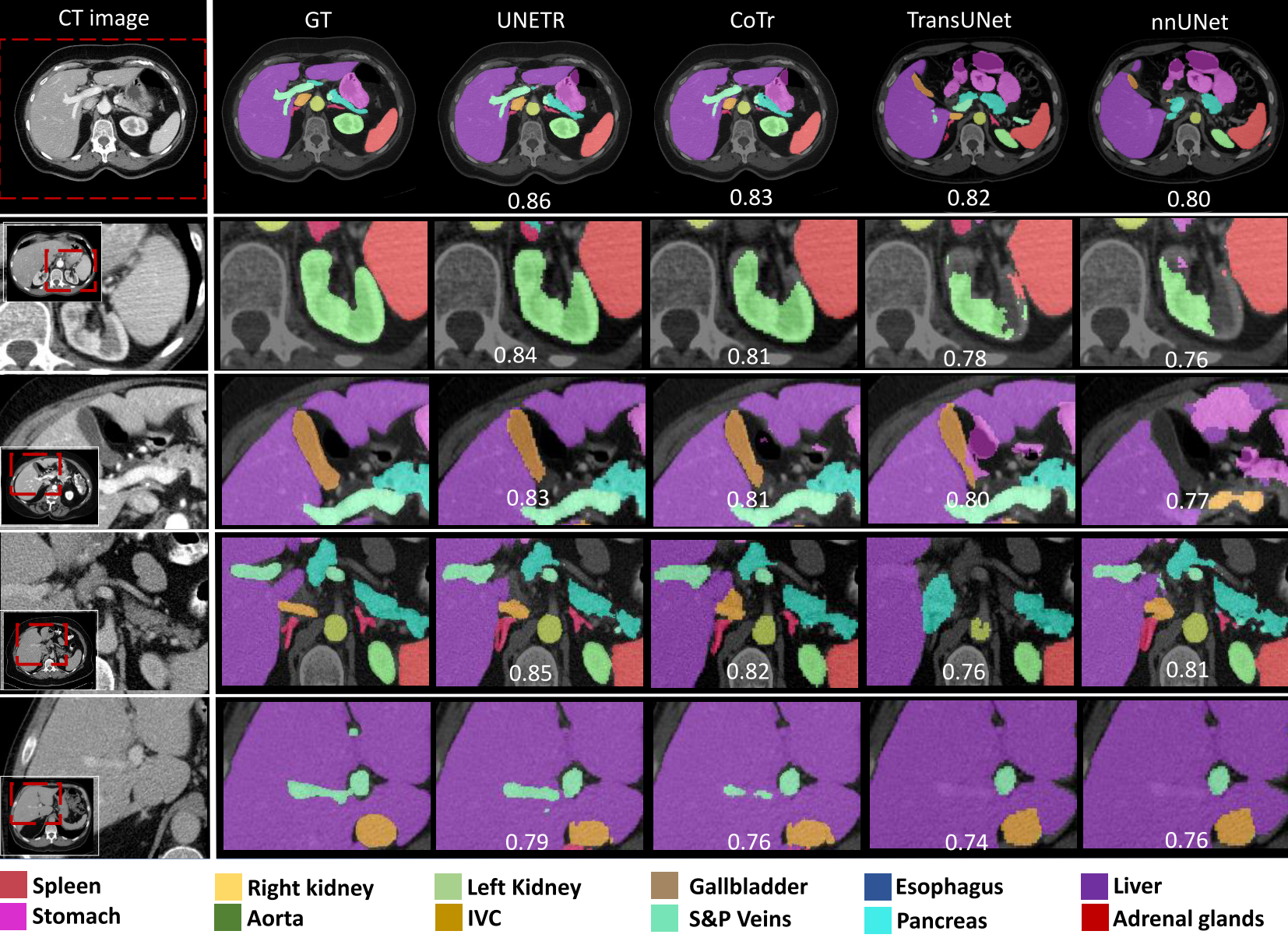
UNETR이 BTCV 데이터셋에서 다른 모델들과 비교
다양한 기관(장기)의 3D 의료 이미지 분할 성능을 시각적으로 차이보임
- 비장과 신장(2row):
UNETR은 경계선이 명확하며, 주변 구조물과 혼동 없이 정확한 분할 - 췌장과 부신(3row):
작은 크기의 장기에서도 UNETR이 기존 모델보다 우수한 경계 - 담낭(4row):
복잡한 장기 형상에서도 UNETR은 예측 영역의 일관성을 유지 - 정맥(5row):
UNETR은 좁고 긴 구조의 정맥에서도 세밀한 분할이 가능
UNETR은 대부분의 장기에서 더 높은 Dice 점수를 기록, 유독 작은 장기에서 높은 점수를 기록
UNETR은 Transformer를 활용한 의료 이미지 segmentation모델로, PyTorch와 MONAI를 사용해 구현
NVIDIA DGX-1 서버에서 AdamW optimizer(lr 0.0001)를 사용해 batch size 6으로 훈련
20,000번epoch에 약 10시간이 소요
4.4. Quantitative Evaluations
UNETR이 BTCV와 MSD 데이터셋에서 정확성(Dice Score)과 경계 품질(Hausdorff Distance) 측면에서 기존의 최신 모델보다 우수함
fig4. UNETR effectively captures the fine-grained details in segmentation outputs.
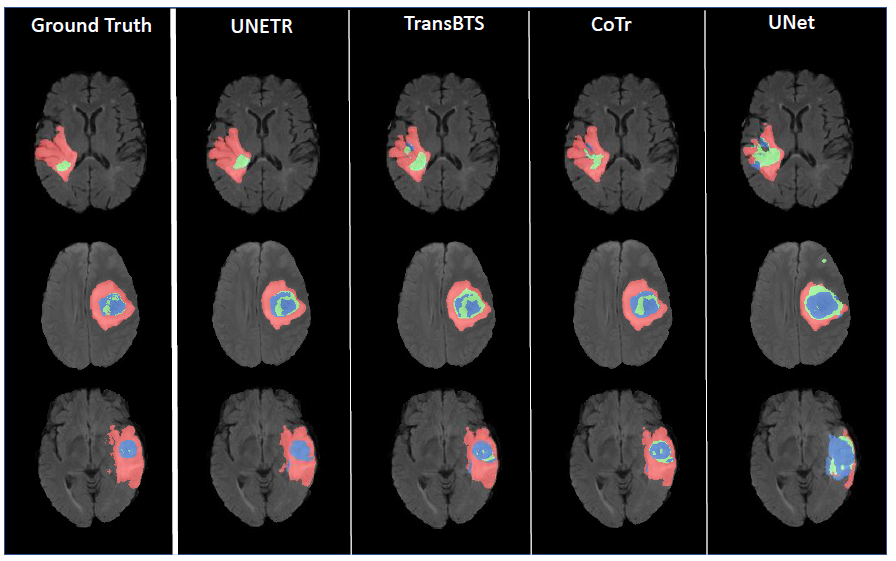
UNETR가 뛰어난 성능을 띄지만, 작은 장기에서는 더 우수
4.5. Qualitative Results
- Transformer 계층 수
적은 계층: 전역 정보를 충분히 학습하지 못함.
많은 계층: 과적합 및 계산 비용 증가.
- 임베딩 크기
작은 임베딩 크기: 정보 표현력 저하.
큰 임베딩 크기: 계산 비용 증가.
-
패치 크기
작은 패치 크기: 계산 비용 증가.
큰 패치 크기: 세부 정보 손실. -
Skip Connections
필수 요소: 없을 경우 성능 크게 저하.
Transformer 인코더의 다중 해상도 특징을 디코더에 전달해 성능 향상. -
Positional Embeddings
중요성: 제거 시 성능(Dice Score) 감소.
공간 정보를 보존해 정확한 분할을 가능하게 함.
5. Discussion
BTCV 및 MSD 데이터셋 실험에서 CNN 및 다른 Transformer 기반 분할 모델보다 우수한 성능
췌장의 꼬리, 담낭, 부신 등 작은 해부학적 구조에서도 높은 분할 정확도
cf) Table 1 및 Figure 3
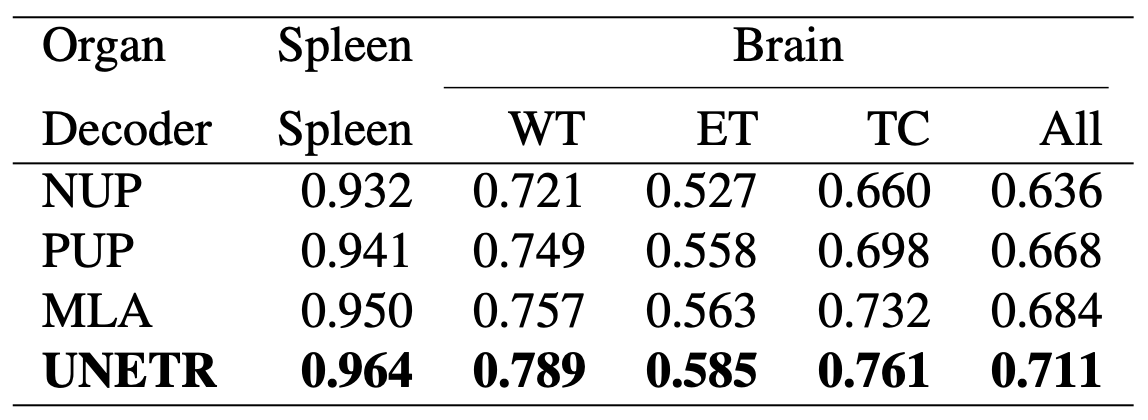
UNETR의 디코더가 가장 높은 Dice Score를 기록하며 최적의 설계
cf) Table3
UNETR은 Transformer의 self-attention 메커니즘을 활용하여 장기 간의 장거리 의존성(long-range dependencies)을 잘 학습.
6. Ablation Studies
Skip Connections 제거 시 성능 저하.
- Transformer 인코더에서 추출한 다양한 해상도의 특징을 디코더로 직접 연결하여 정보 손실을 방지
- Transformer 인코더의 다중 해상도 특징을 디코더에 효과적으로 전달하여 성능 향상.
Positional Embeddings 제거 시 Dice Score 감소.
- 모델이 위치 정보를 기반으로 더 정밀한 분할
- Positional Embeddings를 제외하면 공간 정보가 상실되며, 이는 Dice Score의 하락
7. Conclusion
This paper introduces a novel transformer-based architecture, dubbed as UNETR, for semantic segmentation of volumetric medical images by reformulating this task as a 1D sequence-to-sequence prediction problem.
We validated the effectiveness of UNETR on different volumetric segmentation tasks in CT and MRI modalities.
Transformer와 3D U-Net 결합한 모델이 계속해서 나오고 있다
의료 계열에 많이 쓰일 것 같고 흥미로운 분야인듯!
