📌 월요일 회의에서 CNN이 아니라, CNN-LSTM 모델을 빨리 구축하는 것이 좋겠다는 판단이 들어서 진행하고 있던 CNN에서 CNN-LSTM 작업으로 넘어갔다.
✔️input data 를 이미지로 진행할지, 좌표값으로 할지에 대한 많은 고민을 했다. 이미지로 진행한다고 하면 input data가 이미지인 CNN-LSTM 모델을 찾아야하는데, 많은 사람들이 좌표값으로 많이 진행하는 것을 보니 앞이 깜깜하고 이해가 잘 안가는 부분이 많고, 좌표값으로 진행한다고 하면 지금까지 진행해오던 것을 다 갈아엎고 처음부터 시작해야 한다는 리스크와 영상 1개 당 데이터는 1개이니 데이터 셋의 부족의 문제도 컸다. (데이터 증폭이 불가하니까) 둘다 진행하고 비교해볼까도 했지만 시간의 제약이 있어 불가능하다는 생각이 들었다.
✔️이미 우리가 정하고 들어선 길 계속 가보자는 생각이 들어 진행하고 있던 이미지를 그대로 유지하기로 결정했다.
✔️기존에 기획 시 참고했었던 논문들을 지금 다시 읽어보니 이해가 가지 않던 부분도 눈에 들어오고 이해도 더 잘 되는 것같아 학습 부분을 중점으로 읽고 다시 찾아보기로 했다.
논문 정리
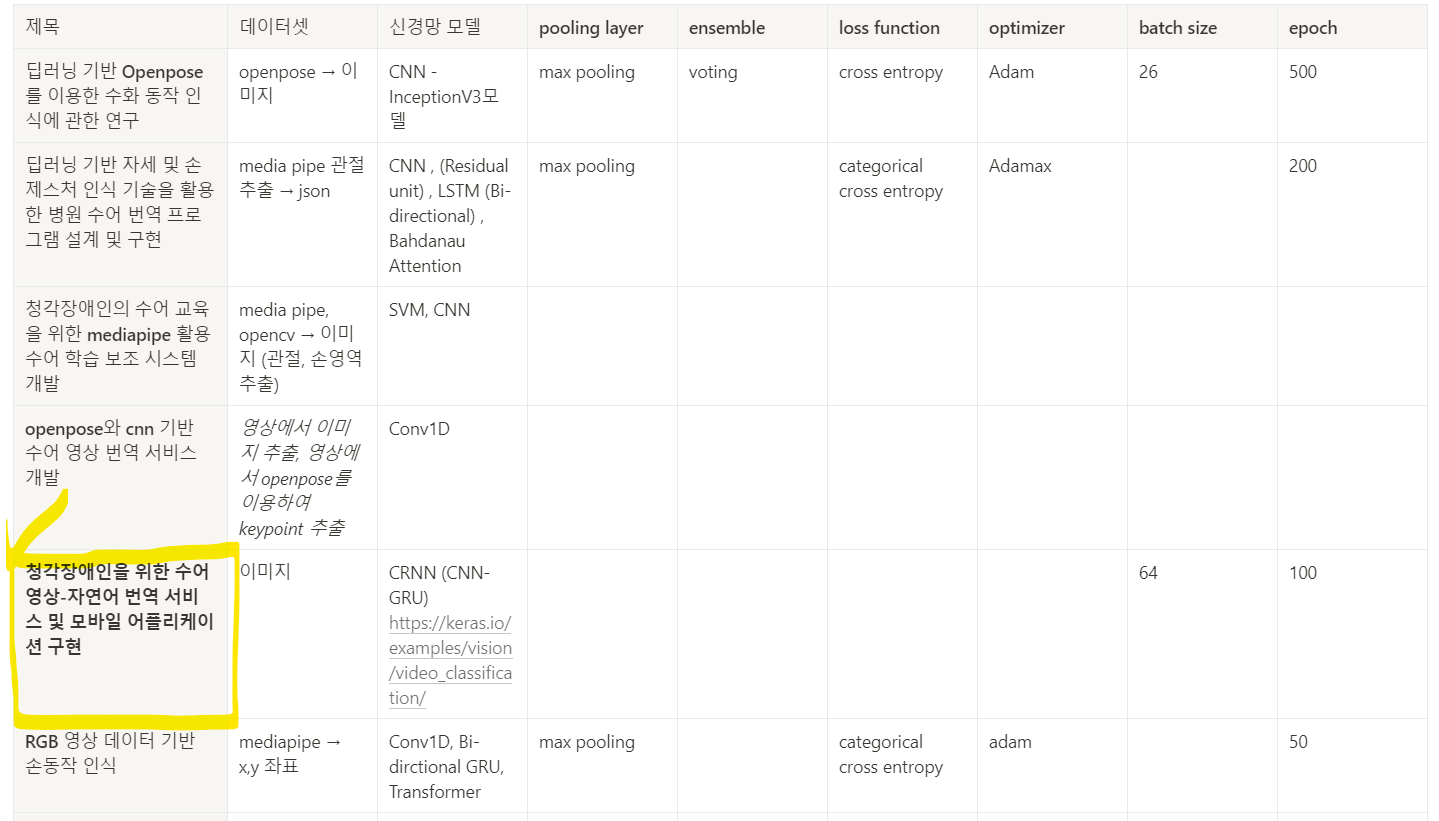
- pooling layer : convolution layer의 출력 데이터를 입력으로 받아 출력 데이터의 크기를 줄이는 용도 or 특정 데이터를 강조하는 용도로 사용
- max pooling, average pooling, min pooling
- ensemble (앙상블) : 여러개의 학습 알고리즘을 사용하고, 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법
- voting, boosting, bagging
- loss function (손실 함수) : 모델의 학습 상태 및 성능이 향상하는지 알기 위해 손실함수를 사용
- cross entropy , MSE
- optimizer : 모델의 예측값과 실제 값의 차이를 계산하는 함수를 만들고 그 값이 최소가 되는 지점을 찾는 작업
- Adam, Momentum, NAG, SGD ..- 노란색으로 표시해놓은 논문이 우리의 프로젝트에 가장 가까운 논문이라고 판단되었다.
- 해당 논문에서 모델을 구축하는 데에 참고한 사이트이다.
- 하지만 실시간 판단이 아닌거같아 실시간으로 동작을 인식하는 모델을 찾아 보았다.
- 그 결과, 실시간으로 pose recognition이 일어나는 건 대부분 input data가 좌표였다.
[실시간으로 동작을 인식하는 예]
✔️'딥러닝을 사용하여 비디오 분류' 라는 타이틀로 검색을 하면 원하는 결과가 더 나올것으로 기대된다.
👊 다음 과제
- input data가 '이미지'이고, 동작을 '실시간'으로 인식하는 '논문' 을 찾아보기
- 영상을 분류하는 cnn-lstm 알아보기
참고

FE Programmer