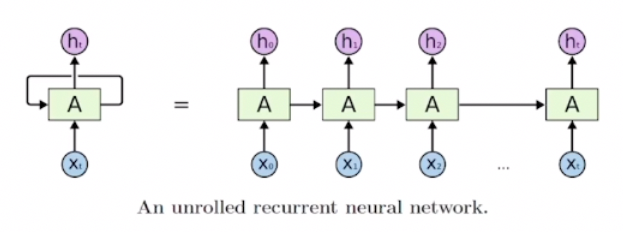
RNN(Recurrent Neural Network)
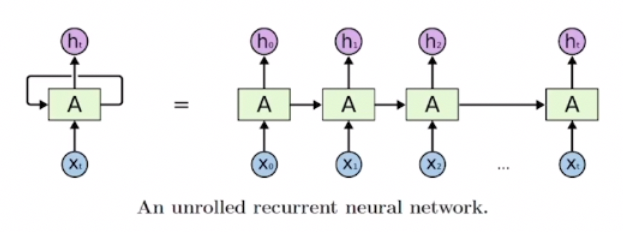
- RNN은 현재 타임스텝에 대해 이전 스텝까지의 정보를 기반으로 예측값을 산출하는 구조의 딥러닝 모델이다.
- 매 타임스텝마다 동일한 파라미터를 가진 모듈을 사용하므로, '재귀적인 호출'의 특성을 보여주어 'Recurrent Neural Network'라는 이름을 가지게 되었다.
RNN 계산 방법

- t : 현재 타임스텝(time step) , w : 웨이트(weight)
- h_t-1h**t−1 : old hidden-state vector (전 단계 rnn 도출 값)
- x_tx**t : input vector at some time step (x input)
- h_th**t : new hidden-state vector ( 현재 도출 값)
- f_wf**w : RNN function with parameters W (파라미터)
- y_ty**t : output vector at time step t (매번 계산하거나, 마지막에만 계산할 수도 있음)
- 위의 변수들에 대하여, h_t = f_w(h_t-1,x_t)h**t=f**w(h**t−1,x**t) 의 함수를 통해 매 타임스텝마다 hidden state를 다시 구해준다.
- 이 때, W와 입력값( x_t, h_t-1x**t,h**t−1 )으로 tan_htan**h 를 곱해서 h_th**t 를 구해준다.
- 구해진 h_t, x_th**t,x**t 를 입력으로 y_ty**t 값을 산출하게 된다.
다양한 타입의 RNN 모델
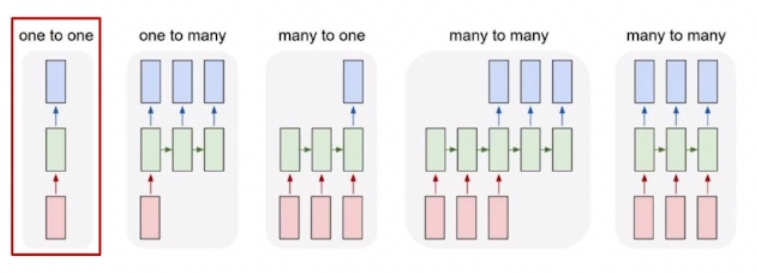
| 1 | one to one | 키, 몸무게, 나이와 같은 정보를 입력값으로 할 때, 이를 통해 저혈압/고혈압인지 분류하는 형태의 태스크 |
|---|---|---|
| 2 | one to many | '이미지 캡셔닝'과 같이 하나의 이미지를 입력값으로 주면 설명글을 생성하는 태스크 |
| 3 | many to one | 감성 분석과 같이 문장을 넣으면 긍/부정 중 하나의 레이블로 분류하는 태스크 |
| 4 | many to many | 기계 번역과 같이 입력값을 끝까지 다 읽은 후, 번역된 문장을 출력해주는 태스크 |
| 5 | many to many | 비디오 분류와 같이 영상의 프레임 레벨에서 예측하는 태스크 (실시간성)혹은 각 단어의 품사에 대해 태깅하는 POS와 같은 태스크 |
Notion에 정리된 공부한 글을 옮겨오는 중입니다... (진행중)