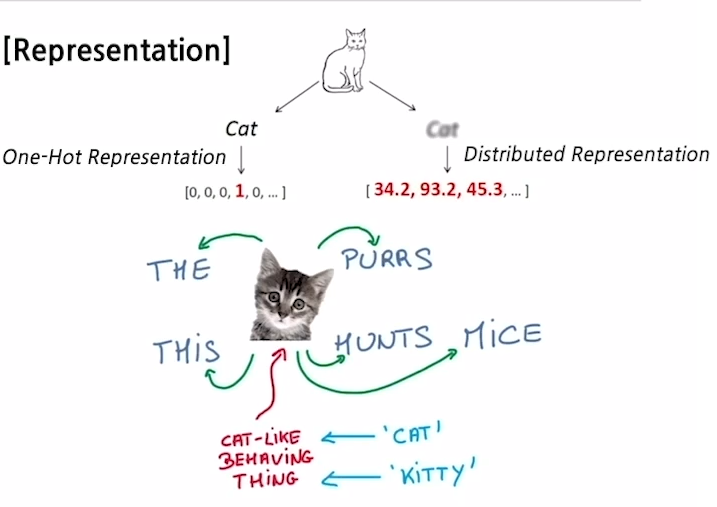
Word Embedding 이란?
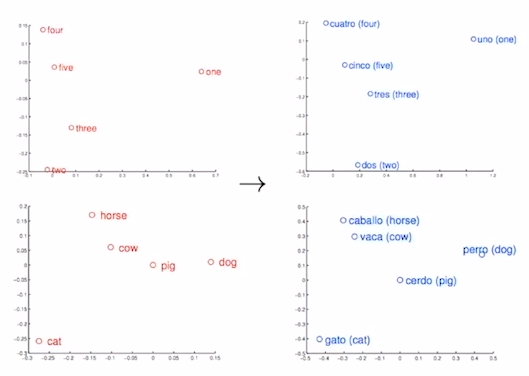
- '워드 임베딩'은 각 단어를 좌표공간에 최적의 벡터로 표현하는(임베딩하는) 기법을 말한다.
- 그렇다면 표현된 벡터값이 '최적'인지를 어떻게 알 수 있을까
- kitty : 아기 고양이
- cat : 고양이
- hamburger : 햄버거
- 위 단어들을 벡터를 통해 좌표공간으로 표현한다면, 'kitty'와 'cat'은 비슷한 위치할 것이다. 그러나 'hamburder'는 꽤 먼 거리에 표현될 것이다. 이와 같이 유사한 단어는 가까이, 유사하지 않은 단어는 멀리 위치하는 것을 '최적의 좌표값'으로 표현할 수 있다.
- 또 다른 예로 감정을 분류를 한다고 했을 때에
- "기쁨", "환희"는 긍정적인 감정을 나타내는 단어들과 함께,
- "분노", "증오"는 부정적인 감정을 나타내는 단어들과 비슷한 위치에 맵핑이 될 것이다.
Word2Vec Idea
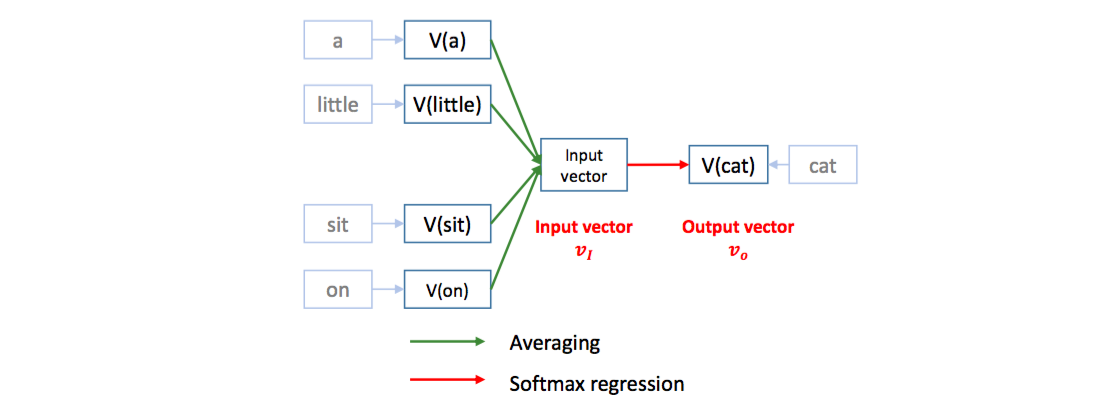
- '워드 투 벡터'의 아이디어는 "문장 내에서 비슷한 위치에 등장하는 단어는 유사한 의미를 가질 것이다" 에서 출발한다. 즉, 주변에 등장하는 단어들을 통해 중심 단어의 의미가 표현될 수 있다는 것으로 추정을 시작한다.

- 이를 위해 우선 워드를 토크나이징(Tokenizing)해준 후, 유니크한 단어만 모아서 사전(Vocabulary)을 만들어주어야 한다. 그 이후 문장에서 중심단어를 위주로 학습 데이터를 구축해준다. ( 중심 단어를 기점으로 앞, 뒤 단어들을 보고 관계를 봄 )
- 예를 들어 “I study math”라는 문장의 중심단어가 study 라고 한다면, (I study), (study I) , (study math) 와 같은 단어쌍을 학습 데이터로 구축한다.
토크나이징(Tokenizing) : 말그대로 문자(Text)를 컴퓨터가 이해할 수 있는 Token이라는 숫자 형태로 바꿔주는 행위
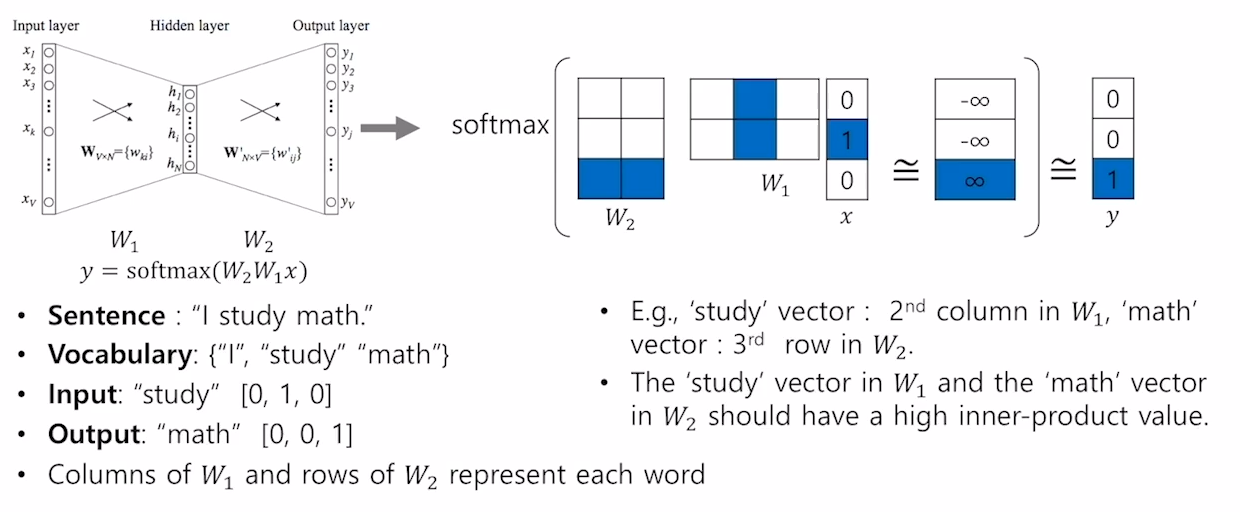
Word2Vec의 계산
- 문장의 단어의 갯수만큼에 Input, Output 벡터 사이즈를 입력/출력해준다. 이 때 연산에 사용되는 히든 레이어(hidden layer,은닉 층)의 차원(dim)은 사용자가 파라미터로 지정할 수 있다.
- 실제로 Tensorflow나 Pytorch와 같은 프레임워크에서는 임베딩 레이어와의 연산은 0이 아닌 1인 부분, 예를 들어 [0,0,1]의 벡터인 경우는 3번째 원소와 곱해지는 부분의 컬럼(column)만 뽑아서 계산해준다.
- 마지막 결과값으로 나온 벡터는 softmax 연산을 통해 가장 큰 값이 1, 나머지는 0으로 출력된다.
- 위의 연산이 반복되면서, 같이 등장하는 단어들 간의 벡터표현이 유사해지는 것을 아래 사이트에서 확인할 수 있다.
- https://ronxin.github.io/wevi/
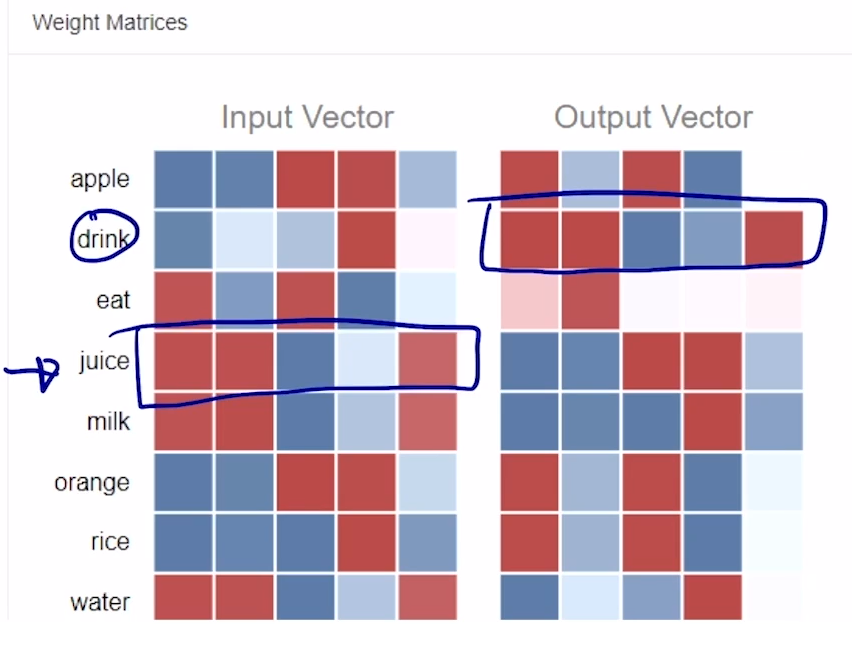
Word2Vec의 특성
- 워드투벡터를 통해 단어를 임베딩하면 queen - king 그리고 woman - man , 마지막으로 aunt - uncle 의 벡터가 비슷한 것을 볼 수 있다. 해당 결과가 의미하는 것은 여성과 남성의 관계성을 잘 학습했다는 것을 의미헌다.
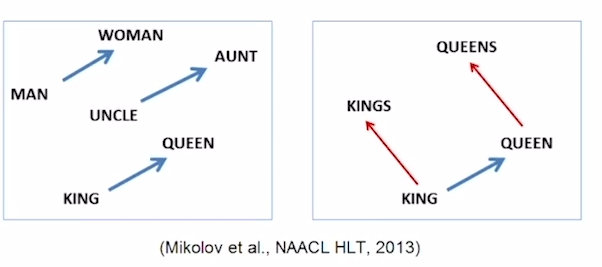
- 연세대 축제 이름인 "아카라카"에서 연세대를 빼고 고려대를 더해주면, 고려대의 축제인 "입실렌티"가 나오는 것도 확인 할 수 있다.
- 워드투벡터 성능 확인하기 : http://w.elnn.kr/search

Application of Word2Vec
- Word2Vec은 그 자체로도 의미가 있지만, 뿐만 아니라 다양한 테스크에서 사용된다.
- Machine translation : 단어 유사도를 학습하여 번역 성능을 더 높여준다.
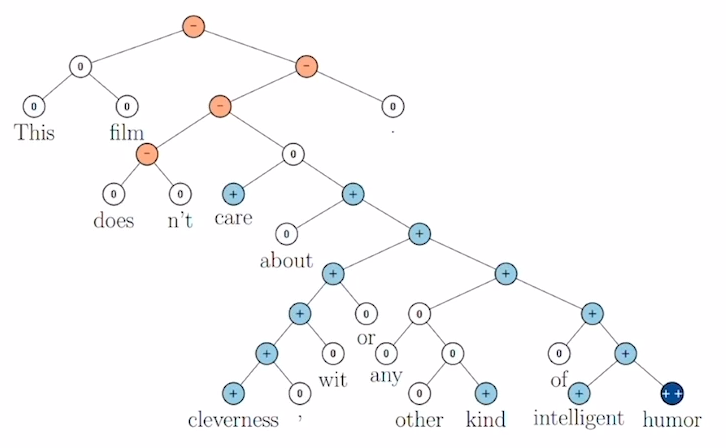
- Sentiment analysis : 감정분석, 긍부정분류를 돕는다.
- Image Captioning : 이미지의 특성을 추출해 문장으로 표현하는 테스크를 돕는다.

Glove : Global Vectors for Word Representation
- Glove는 Word2Vec과 다르게 사전에 미리 각 단어들의 동시 등장 빈도수를 계산하며,단어간의 내적값과 사전에 계산된 값의 차이를 줄여가는 형태로 학습한다.
- Word2Vec는 모든 연산을 반복하지만, Glove는 사전에 계산된 Ground Truth를 사용해 반복계산을 줄일 수 있다.
- 따라서 Word2Vec보다 더 빠르게 동작하며, 더 적은 데이터에서도 잘 동작한다.
사전 학습된 Glove 모델
- 사전에 이미 대규모 데이터로 학습된 모델이 오픈소스로 공개되어 있다. 해당 모델은 위키피디아 데이터를 기반으로 하여 6B token만큼 학습 되었으며, 중복 제거 시에도 단어의 개수가 무려 40만개(400k)에 달한다.
- 학습된 모델을 나타낼 때 뒤에 붙는 "uncased"는 대문자 소문자를 구분하지 않는다는 의미이며, 반대로 "cased"는 대소문자를 구분한다. 예를 들어 Cat과 cat이 uncased에서는 같은 토큰으로 취급되지만, cased에서는 다른 토큰으로 취급된다.
- Glove 깃헙 주소 : https://github.com/stanfordnlp/GloVe (기존에 학습된 워드 임베딩도 다운로드 받아 사용 가능)
Glove의 장점
- Glove는 Word2Vec보다 더 나은 성능을 보여주며, 다양한 NLP 태스크에서 사용된다.
- Glove를 사용하면 높은 차원의 벡터 공간에서 단어 간의 관계를 파악할 수 있으며, 이를 통해 단어들의 유사도를 계산할 수 있다.
- Glove는 사전에 학습된 모델도 공개되어 있어, 해당 모델을 통해 높은 성능의 워드 임베딩을 쉽게 사용할 수 있다.
Notion에 정리된 공부한 글을 옮겨오는 중입니다... (진행중)