분산(Variance)
-
데이터가 얼마나 '퍼져있는지'를 표현하는 통계량이다. 분산이 클 수록 데이터 서로 간의 퍼짐이 크고, 작을 수록 데이터 퍼짐 정도가 작다. 평균에서 데이터 각각의 값을 배고(편차를 구하고) 제곱하여 그 값을 모두 더한 뒤, 전체 데이터 개수에서 하나의 데이터를 뺀 값(N-1)로 나누어 분산을 구한다. 데이터 간 거리(편차)를 구한 값이 음수인 경우 양수로 바꾸어 데이터간 거리를 설명한다.
-
왜 평균에서 데이터의 값을 뺀 후 제곱을 해주냐면, 데이터의 퍼짐 정도를 알기 위해 평균과 데이터들의 떨어짐 정도를 구해줬는데, 중앙(평균)값을 기준으로 왼쪽의 데이터의 값을 빼게 되면 음수가 되어버리기 때문에 제곱을 해주어 양수로 만들어 주기 위함이다.
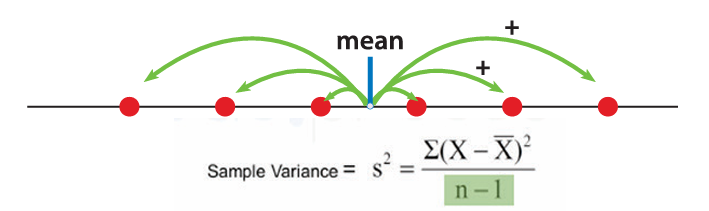
데이터의 변동성, 흩어짐 정도를 표현 : 편차제곱합 / 자료의 개수
분산은 데이터의 움직임을 설명할 수 있는 통계량이다. 분산은 데이터 간 거리를 표현한 것이고, 이때 데이터 간 거리는 '변동성'을 설명한다. 분산을 다른 말로 '변량'으로 부르는 이유이다.
표준 편차(Standard Deviation)
- 분산에 양의 제곱근하여 구한다. 평균과 개별 데이터 간 차이(=편차)의 표준값이라 생각하면 된다. 표본의 표준편차는 보통 (S또는 시그마 σ)로 칭한다. 각 개별 데이터와 평균값 간 차이들의 표준값이다. 따라서 표준편차는 데이터 분포의 간격을 설명할 수 있는 대푯값의 기능을 갖는다.
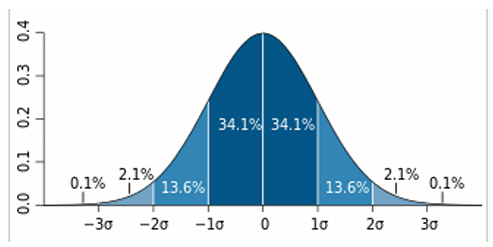
표준편차와 분산의 특징
-
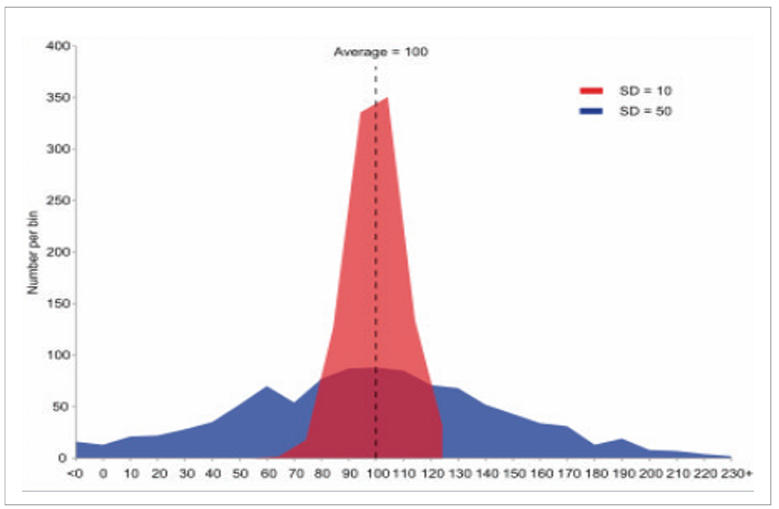
분산은 평균의 한계를 보완할 수 있는 통계량이다. 아래의 그림처럼 붉은색 영역이나 파란색 영역 모두 평균값은 동일하게 나온다. 하지만 데이터 간 분포의 차이는 뚜렷함에도 불구하고 평균만으로 그 차이를 설명할 수 없다.
-
붉은색 영역에 비해 파란색 부분의 데이터 분포는 표준편차가 상대적으로 크고 분산값도 훨씬 크다. 붉은색 영역의 표준편차는 10인데 반면 파란색 영역의 표준편차는 50으로 분산으로 보면 전자는 100, 후자는 2500이 된다. 표준편차와 분산은 그 값이 클수록 데이터의 변화 정도가 크다고 할 수 있다.
사분위수
- 데이터를 4등분하는 위치의 수를 사분위수라 칭한다. 전체 데이터를 순위별로 4등분 하는데, 이때 등분 지점이 되는 위치의 수를 Q1, Q2, Q3라 한다.
- 제1사분위수(Q1) : 누적 백분율이 25%에 해당하는 값
- 제2사분위수(Q2) : 누적 백분율이 50%에 해당하는 값, 중앙값
- 제3사분위수(Q3) : 누적 백분율이 75%에 해당하는 값