현재 구성중인것은 s3버킷에 음성파일을 올린뒤 lambda 서비스를 이용해서 해당 버킷의 음성파일의 endpoint를 aws transcribe 서비스로 전달한뒤 음성파일을 텍스트파일로 변환뒤 다시 받아오는것이다.
그뒤 텍스트 파일로 aws bedrock 서비스를 사용해서, 텍스트파일을 요약하고 이런 전체적인 서비스를 step fuction 서비스의 파이프라인을 통해 자동화해볼것이다.
- s3버킷에 준비해둔 음성파일을 올린다.
나머지는 기본값으로 세팅한뒤 버킷을 생성한다.
그뒤 해당 버킷을 들어간뒤 준비해둔 음성파일을 올린다.

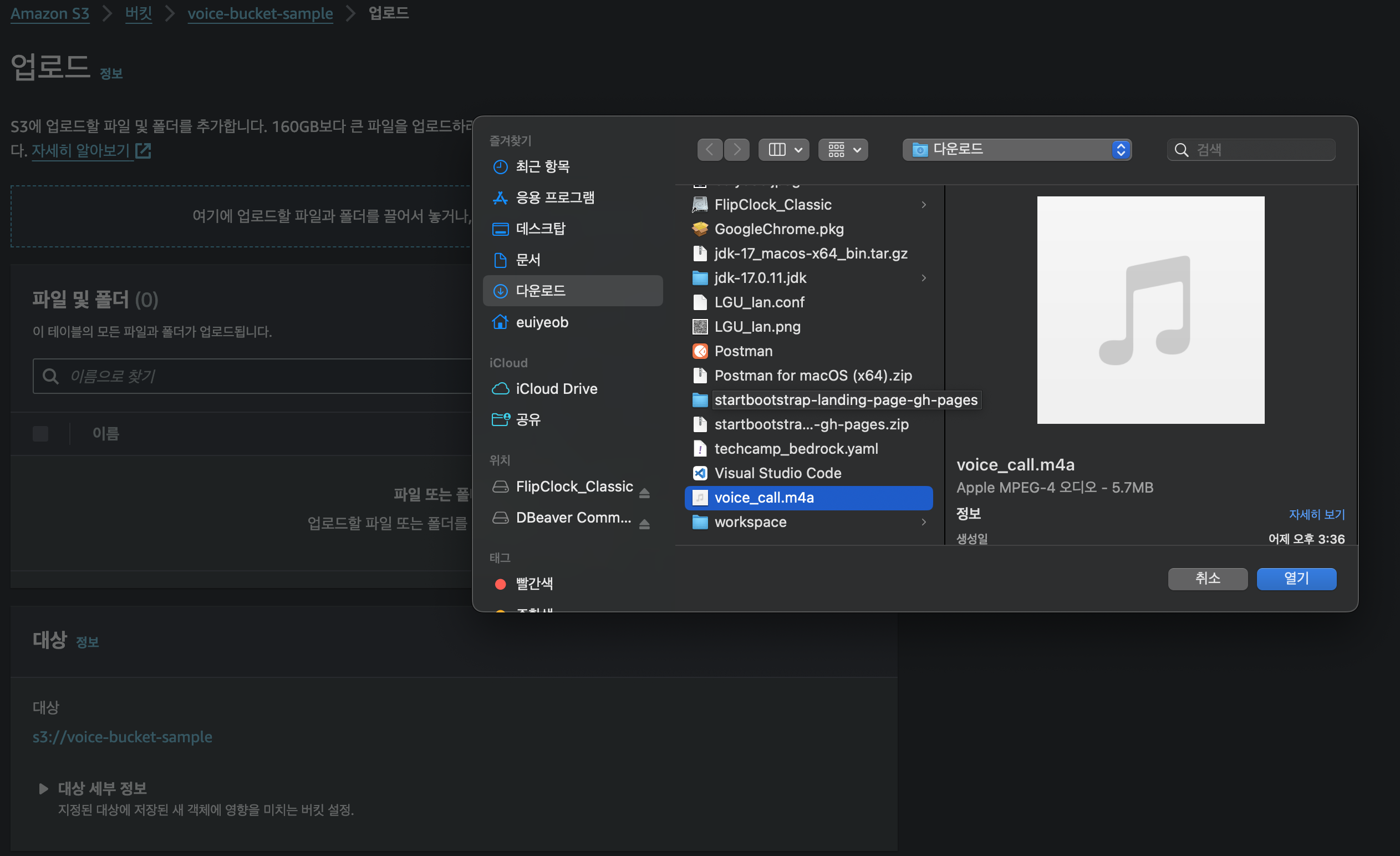
드래그드랍 및 파일 폴더 추가를 해서 해당 파일을 업로드한다.
그리고 해당 버킷에 대한 권한을 설정한다.
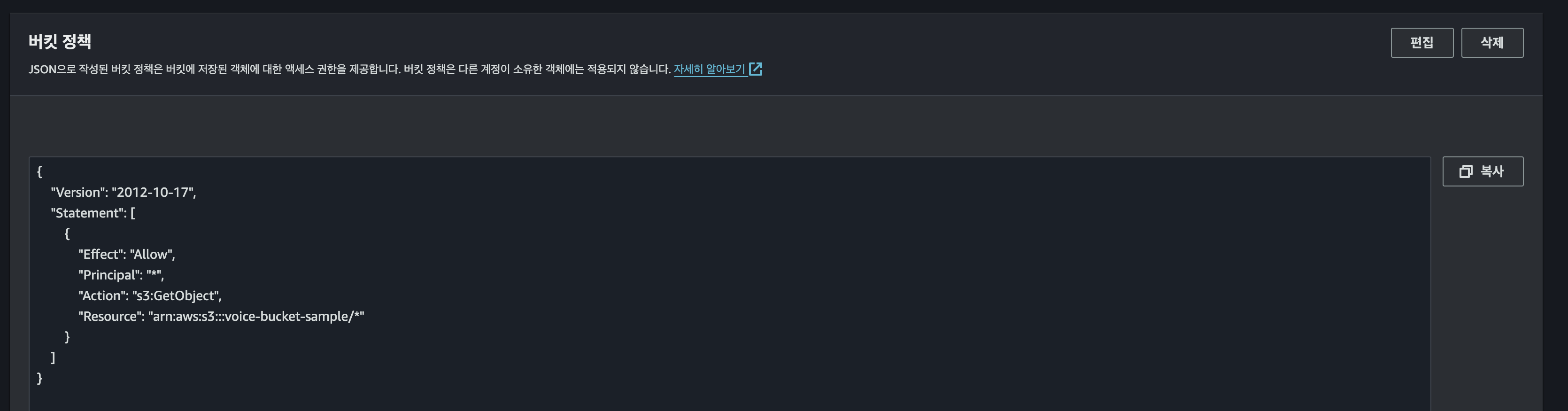
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::voice-bucket-sample/*"
}
]
}권한 의미는 해당 버킷을 get해오는것을 허용하겠다는 의미이다.
- 이제 lambda 함수를 생성한다.
해당 함수로 방금 올린 s3버킷을 가져온다음 transcribe job을 생성해서 텍스트파일을 변환해서 가져올것이다.

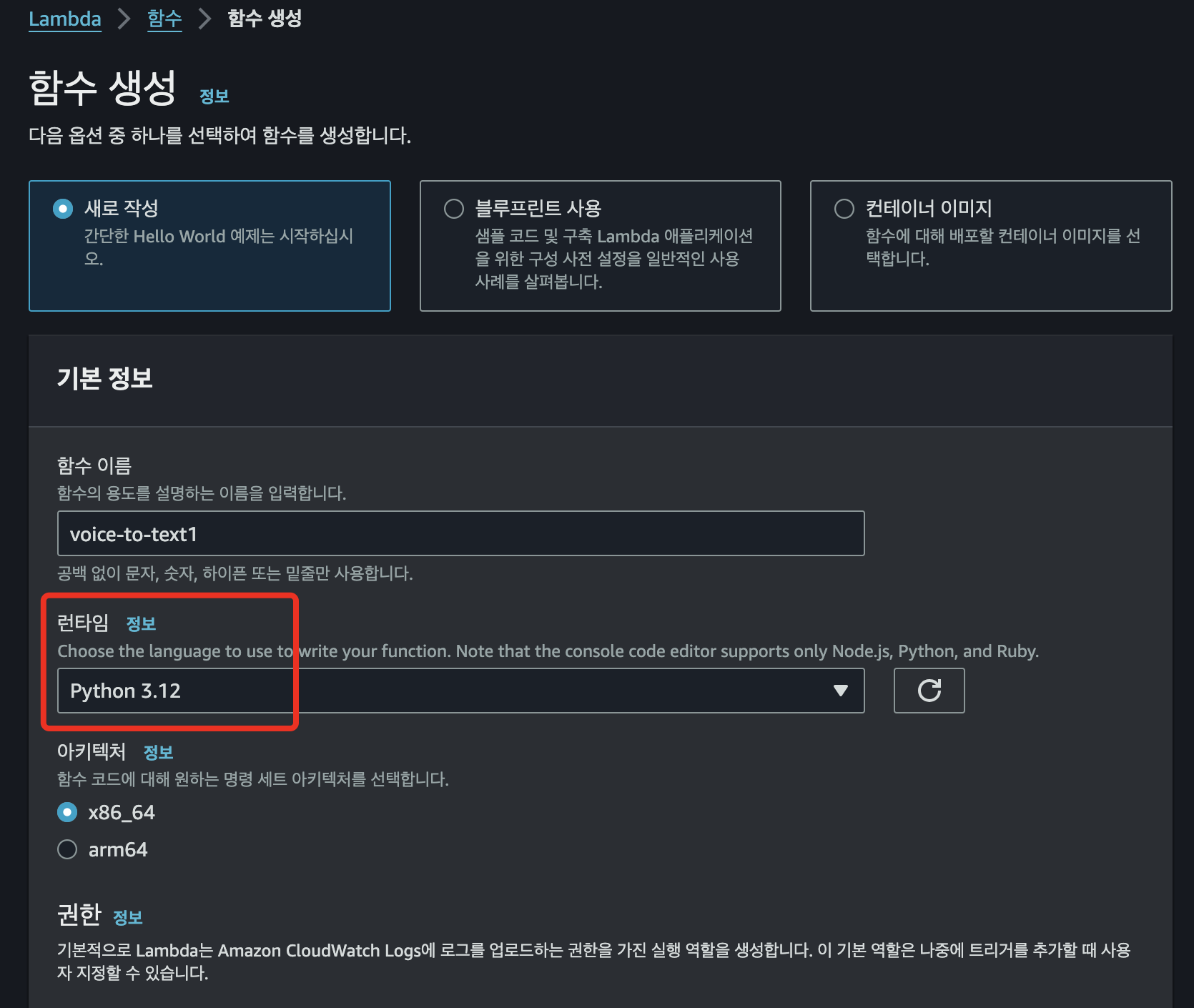
런타임은 python으로 설정한다. 주로 python코드가 래퍼런스가 많다고 생각한다.
해당 람다함수를 들어와서 코드를 작성한다.
import json
import boto3
import time
from datetime import datetime
def lambda_handler(event, context):
bucket_name = ''
file_key = ''
new_transcribe_name = 'new-transcribe'
response = start_transcription_job(bucket_name, file_key, new_transcribe_name)
if response is None:
return {
'statusCode': 500,
'body': json.dumps('Error starting transcription job')
}
job_status = get_transcription_result(new_transcribe_name)
return {
'statusCode': 200,
'body': json.dumps(job_status)
}
def start_transcription_job(bucket_name, file_key, job_name):
s3_file_uri = f's3://{bucket_name}/{file_key}'
transcribe = boto3.client('transcribe')
try:
response = transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': s3_file_uri},
MediaFormat='m4a',
LanguageCode='ko-KR'
)
print(f"Started transcription job: {job_name}")
return response
except Exception as e:
print(f"Error starting transcription job: {e}")
return None
def get_transcription_result(job_name):
transcribe = boto3.client('transcribe')
while True:
response = transcribe.get_transcription_job(TranscriptionJobName=job_name)
status = response['TranscriptionJob']['TranscriptionJobStatus']
if status in ['COMPLETED', 'FAILED']:
if status == 'COMPLETED':
transcript_uri = response['TranscriptionJob']['Transcript']['TranscriptFileUri']
print(f"Transcription completed. Transcript available at {transcript_uri}")
return {
'status': status,
'transcript_uri': transcript_uri,
'completion_time': response['TranscriptionJob']['CompletionTime'].isoformat() if 'CompletionTime' in response['TranscriptionJob'] else None
}
else:
print("Transcription failed.")
return {'status': status, 'message': 'Transcription failed'}
print("Waiting for transcription to complete...")
time.sleep(10)해당 코드는 s3버킷의 endpoint를 변수화한뒤 해당 버킷의 endpoint를 가지고 transcribe job을 생성하는것이다.
결과
Response
{
"statusCode": 200,
"body": "{\"status\": \"COMPLETED\", \"transcript_uri\": \"https://s3.ap-northeast-2.amazonaws.com/aws-transcribe-ap-northeast-2-prod/415349251062/euiyeob-new-transcribe/dc4d077a-9b44-463b-902c-5aa480c37261/asrOutput.json?X-Amz-Security8......\", \"completion_time\": \"2024-06-30T05:47:09.918000+00:00\"}"
}
- 이때 에러가 난다면 실제 에러 내용을 잘 파악할 필요가 있다.
주로 권한 에러가 날 경우가 대부분이다.
나는 해당 람다함수의 역할에 대한 권한을 줘야하는 에러가 나서 해당 권한을 추가해줬다.
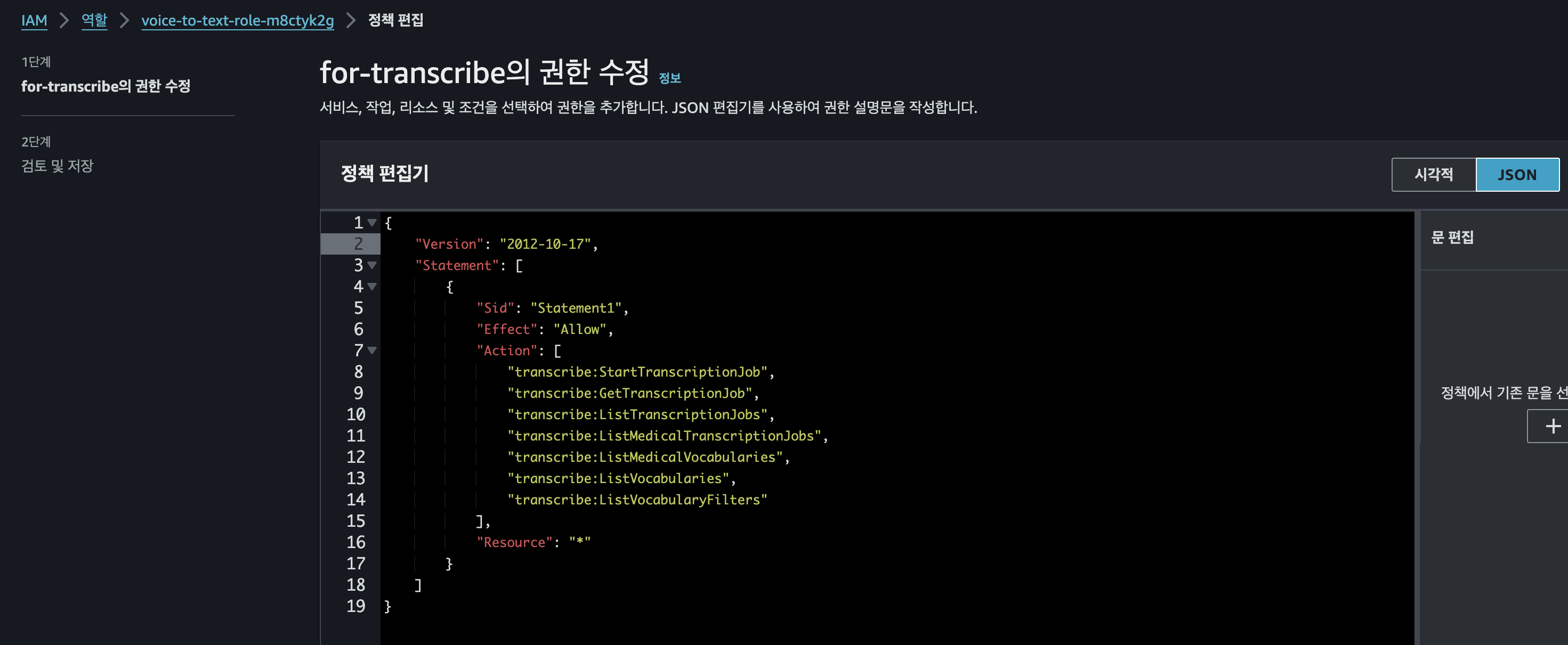
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": [
"transcribe:StartTranscriptionJob",
"transcribe:GetTranscriptionJob",
"transcribe:ListTranscriptionJobs",
"transcribe:ListMedicalTranscriptionJobs",
"transcribe:ListMedicalVocabularies",
"transcribe:ListVocabularies",
"transcribe:ListVocabularyFilters"
],
"Resource": "*"
}
]
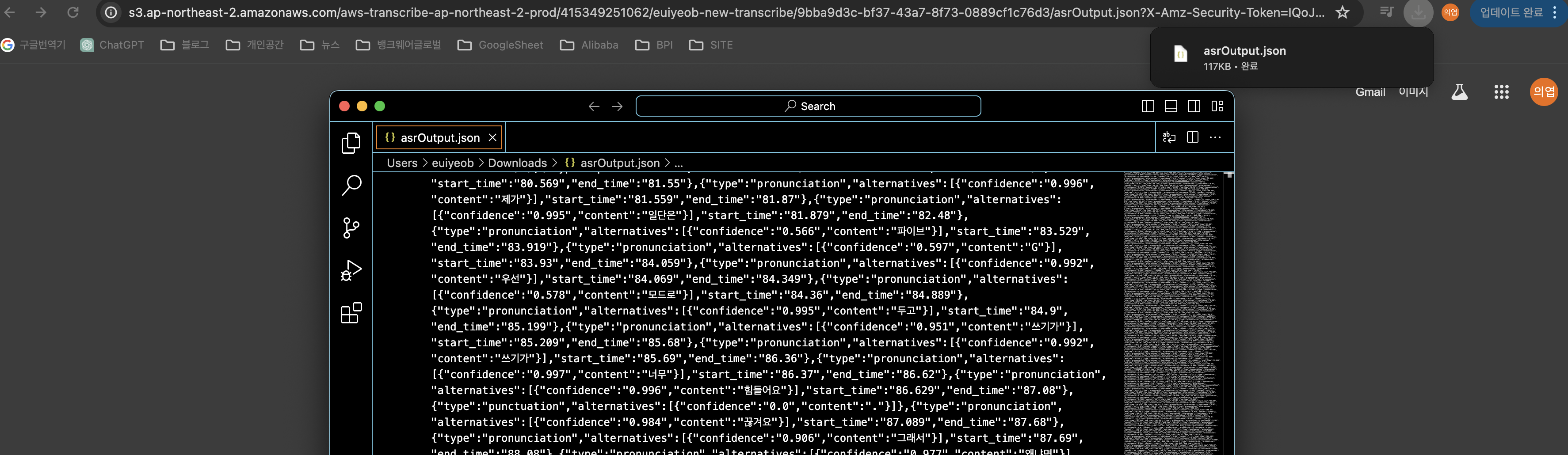
}- transcribe 생성된것을 확인하고 음성파일이 텍스트 파일로 잘 변환됬는지 확인한다.
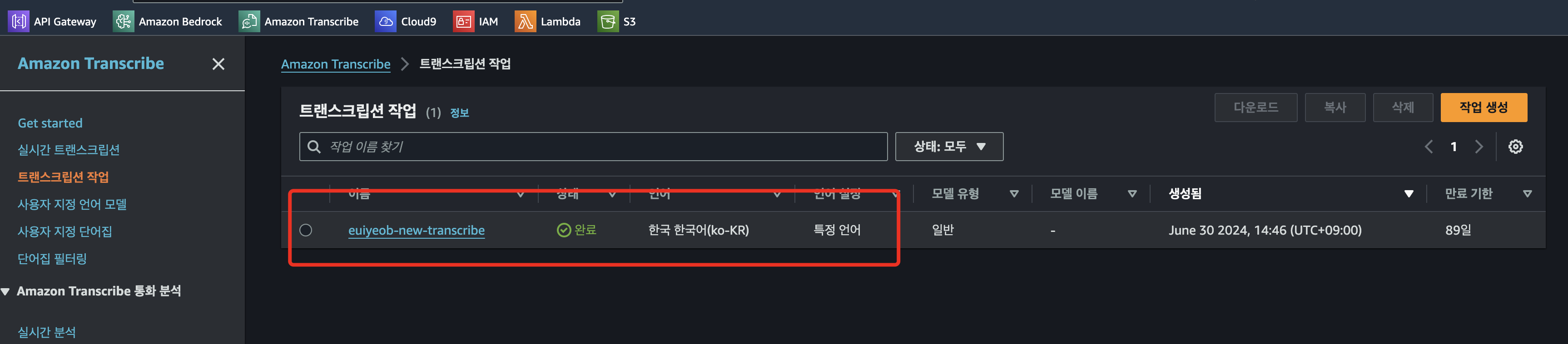
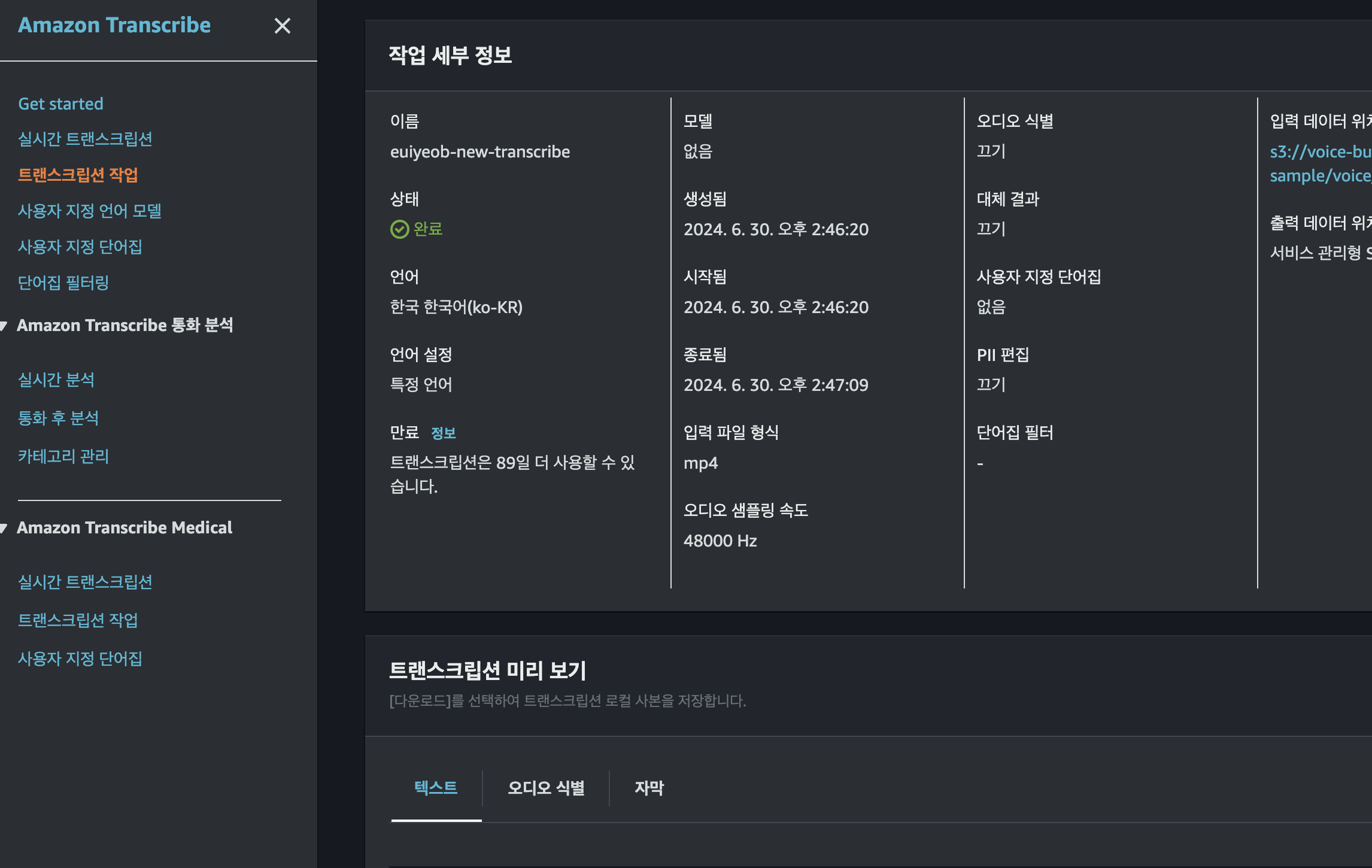
아래 텍스트부분이 잘변환된것을 확인할수있다. 개인정보가 들어있어서 내용은 생략하겠다.
마지막으로 response에 받은 transcribe endpoint를 들어가면 실제 json내용을 확인할수있다.