- Transcribe 생성하기를 안했으면 블로그 생성하기 편을 참조해서 생성한다.
그럼 해당 transcribe의 uri (endpoint)를 응답받게 된다.
새로운 람다함수를 만들어서 이젠 해당 uri를 가지고 출력해보기다.
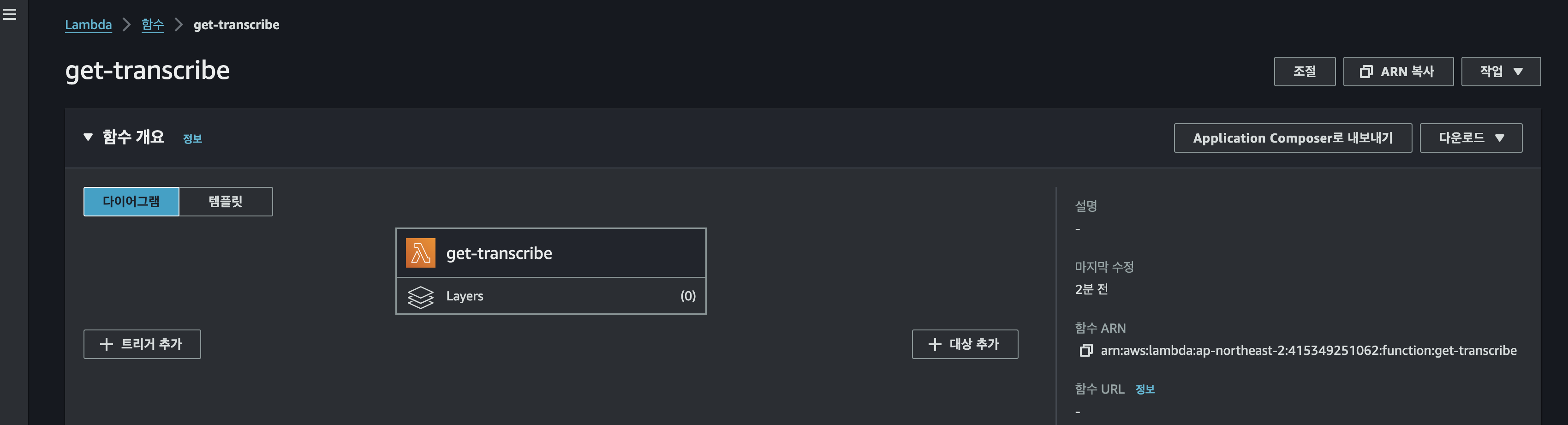
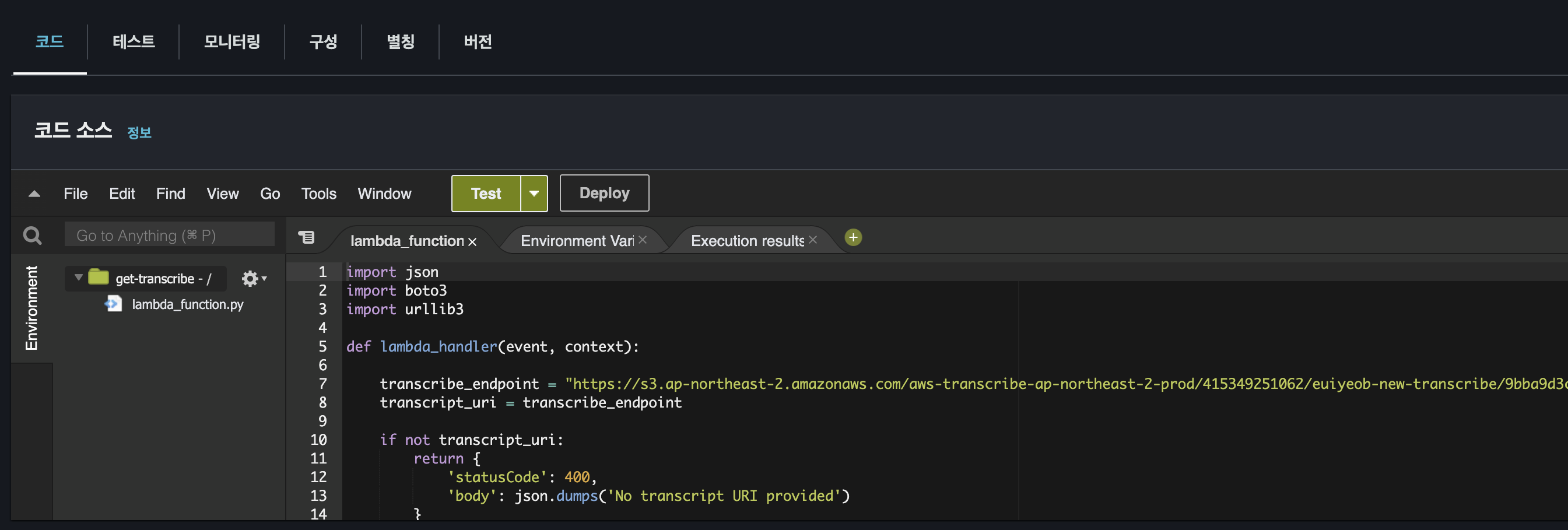
import json
import boto3
import urllib3
def lambda_handler(event, context):
#transcribe 생성시 받은 응답에 해당 주소가 있다.
transcribe_endpoint = "https://s3.ap-northeast-2.amazonaws.com/...."
transcript_uri = transcribe_endpoint
if not transcript_uri:
return {
'statusCode': 400,
'body': json.dumps('No transcript URI provided')
}
transcript_text = get_transcript_text(transcript_uri)
if transcript_text:
print(transcript_text)
return {
'statusCode': 200,
'body': json.dumps(transcript_text)
}
else:
return {
'statusCode': 500,
'body': json.dumps('Error reading transcript')
}
def get_transcript_text(transcript_uri):
http = urllib3.PoolManager()
try:
response = http.request('GET', transcript_uri)
if response.status == 200:
transcript = json.loads(response.data.decode('utf-8'))
return transcript['results']['transcripts'][0]['transcript']
else:
print(f"Error fetching transcript: {response.status}")
return None
except Exception as e:
print(f"Error reading transcript from URI: {e}")
return None
이렇게 코드를 실행하게 되면 transcribe안에 있는 텍스트를 받을수 있게된다.
- 이때 기본적으로 람다함수의 설정에 타임아웃 시간이 작게 되있으므로 방대한양을 응답받게 되거나 어떤 서비스를 생성할시 타임아웃 시간을 늘려주고 해야한다.
- 이제 해당 텍스트를 가지고 AWS의 bedrock ai 모델을 사용해서 해당 텍스트 내용을 요약및 다양한 처리를 요청해보자!
import json
import boto3
import urllib3
def lambda_handler(event, context):
transcribe_endpoint = "https://s3.ap-northeast-2.amazonaws.com/aws-transcribe-ap-northeast-2-prod/415349251062....."
transcript_uri = transcribe_endpoint
request_to_ai = "내용을 요약해줘"
if not transcript_uri:
return {
'statusCode': 400,
'body': json.dumps('No transcript URI provided')
}
transcript_text = get_transcript_text(transcript_uri)
print("===================================================")
print("transcript_text", transcript_text)
print("===================================================")
ai_result = get_summary_from_bedrock(transcript_text, request_to_ai)
print("===================================================")
print("ai_result", ai_result)
print("===================================================")
if ai_result:
return {
'statusCode': 200,
'body': json.dumps(ai_result)
}
else:
return {
'statusCode': 500,
'body': json.dumps('Error ai result')
}
def get_transcript_text(transcript_uri):
http = urllib3.PoolManager()
try:
response = http.request('GET', transcript_uri)
if (response.status == 200):
transcript = json.loads(response.data.decode('utf-8'))
return transcript['results']['transcripts'][0]['transcript']
else:
print(f"Error fetching transcript: {response.status}")
return None
except Exception as e:
print(f"Error reading transcript from URI: {e}")
return None
def get_summary_from_bedrock(text, request_to_ai):
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-west-2'
)
MODEL_ID = 'anthropic.claude-3-sonnet-20240229-v1:0'
user_prompt = text
system_prompt = f"""{request_to_ai}
Respond only in korean.
Skip the preamble.
"""
body = {
"system": system_prompt,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": user_prompt
}
]
}
],
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4096
}
response = bedrock_runtime.invoke_model(
modelId=MODEL_ID,
contentType='application/json',
accept='application/json',
body=json.dumps(body)
)
response_body = json.loads(response['body'].read())
text_content = response_body['content'][0]['text']
return text_content
대략 코드를 보면 어떤식으로 흘러갈지 파악이 된다.
transcribe의 endpoint에서 텍스트를 가져와서 해당 텍스트를 aws bedrock의 anthropic.claude-3-sonnet모델로 요약해달라고 부탁한것이다.
- 이때 bedrock에 permission 에러가 날수 있는데 IAM에서 아래에 권한을 부여하자!
에러 내용을 보면 어떤 역할에서 람다함수를 사용하다가 에러가 난지 파악이된다.
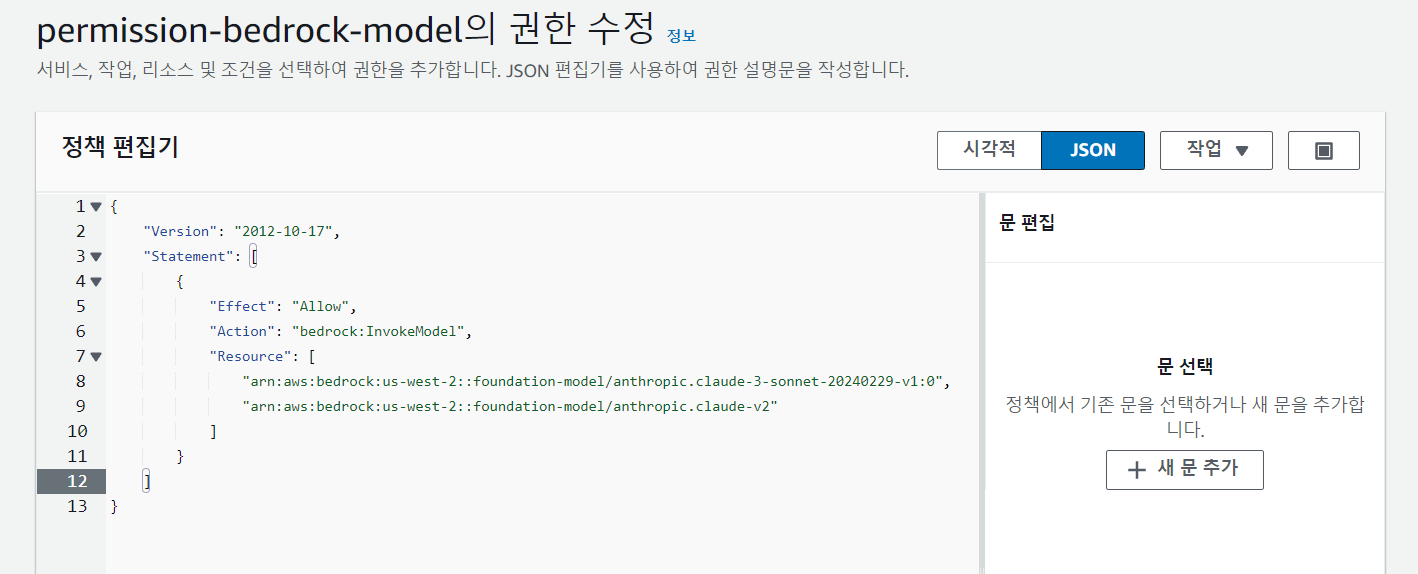
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": [
"arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0",
"arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-v2"
]
}
]
}연습하다가 2개의 모델을 사용해서 2개의 resource를 추가한것이다.
코드에서 사용하는 Model id만 넣어주면 된다.
===================================================
ai_result 요약하면 다음과 같습니다.
- 고객님은 KT 5G 서비스를 사용하고 계신데, 데이터와 음성 통화 시 자주 끊기는 현상이 발생하고 있습니다.
- 특히 실내에서 사용할 때 더 자주 끊기는 문제가 있습니다.
- 상담원은 고객님의 주소지(***)를 받아 전문 부서에 접수하여 신호 세기 점검을 진행하기로 했습니다.
- 고객님께서는 LG보다 KT 서비스 품질이 좋을 것으로 기대했지만 실제로는 만족스럽지 못한 상황입니다.
- 상담원은 KT가 지속적으로 5G 네트워크 개선 작업 중이라고 설명하며 불편을 해소하기 위해 노력하겠다고 말했습니다.
===================================================위와 같이 람다함수의 결과를 받을수 있고 이런식으로 transcribe, bedrock api를 사용해서 채팅 서비스도 구현할수있고 이런 상담내용을 신속하게 요약할수 있다.
