ControlVideo: Training-free Controllable Text-to-Video Generation

- 23/10 Notion에 썼던 글을 다시 복습하는 차원에서 포스팅
Abstract
- training cost문제. 또한 appearance inconsistency 또는 structural flickers 때문에 비디오 생성은 어려운 task.
- ControlVideo는 두 문제 다 해결.
- 세가지 방법 제시.
- self-attention modules에 fully cross-frame interaction 추가. Text2Video-Zero와 다름.
- structural flickers를 해결하기 위해 interleaved-frame smoother 도입 (alternated frames에 frame interpolation 적용함)
- 전체적인 coherency를 유지하며 긴 비디오를 잘 만들기 위해 짧은 clip들을 개별적으로 synthesize하기 위해 hierarchical sampler 활용.
- sota 성능 달성. NVIDIA 2080Ti로 생성가능
1. Introduction
- 과도한 훈련 비용을 줄이기 위해 저자들은 controllable text-to-video generation with text-to-image models을 연구함.
- 이들은 textual description 와 motion sequences 모두를 condition으로 video를 생성하고자함. 저자들은 text-image-model의 생성 능력과, motion sequence의 대략적인 temporal consistency(시간 일치성)를 활용하여 생생한 비디오를 생성함.
- Text2video-zero와 tune-a-video에서 기존의 self-attention을 대체한 attention을 제시했지만 여전히 아래와 같은 문제가 발생.
- 일부 프레임 사이에서 inconsistent 함
- 큰 motion video에서의 visible한 artifact들
- 프레임 전환 간에 structural flickers
- 1, 2에 대해서, sparser cross-frame mechanism은 기존의 self-attention의 q와 k의 불일치를 증가시킴, 따라서 기존의 text-to-image model의 consistent한, high-quality한 특성 사라짐. 3에 대해서, input motion sequences는 비디오 생성에 대한 대략적인 구조만 제공하므로, 연속 적인 프레임간의 부드러운 변환은 하지 못함.
- 이 논문에서, training-free하며 고품질이고 일관된 control이 가능한 비디오를 생성하는 모델인 ControlVideo를 제안함. 이는 structural smoothness를 향상시키기 위해 interleaved-frame smoother를 사용함.
- ControlVideo는 ControlNet의 weight를 그대로 상속받으며, 비디오에 맞게 fully cross-frame interaction을 사용하여 self-attention를 확장함. 이전 논문(Text2Video-Zero 등)들과 달리 fully cross-frame interaction는 모든 프레임을 연결하기 때문에 “large image”가 될 수 있다고 함.
- Interleaved-frame smoother는 선택한 순차적인 timesteps에서 interleaved interpolation을 통해 전체 비디오를 deflicker(덜깜빡이게)함. t에 따라 frame들을 보간하여 전체적으로 매끄러운 frame을 생성함. 이 smoothing은 몇몇 스텝에서만 적용되기 때문에 interpolated된 frame의 퀄리티와 독립성은 denosing step을 지나더라도 잘 유지된다.
- long-term coherency(통일성) 를 유지하는 짧은 분리된 clip을 제공하기 위해 hierarchical sampler를 도입.
- 먼저 전체 비디오를 key frame이 있는 clip으로 분해하고, long-range coherence를 유지하기 위해서 key frame들에 fully cross-frame attention을 도입.
- pairs of key frames가 있으므로 global consistency를 유지하면서 중간의 짧은 비디오 클립을 순차적으로 합성함.
- 성능은 sota이고, xformer를 사용하면 NVIDIA 2080Ti 하나에서 짧은, 긴 비디오를 모두 합성할 수 있다.
Contribution
- fully cross-frame interaction, interleaved-frame smoother, and hierarchical sampler을 사용하여 controllable text-to-video generation이 가능한 training-free ControlVideo를 제안.
- fully cross-attention은 좋은 퀄리티와 모습 일관성을 보여주고, interleaved-frame smoother는 structural flickers 문제를 를 줄여준다.
- hierarchical sampler는 상용 GPU에서 효율적으로 long-video generation이 가능하게 해준다.
2. Background
- 생략
3. ControlVideo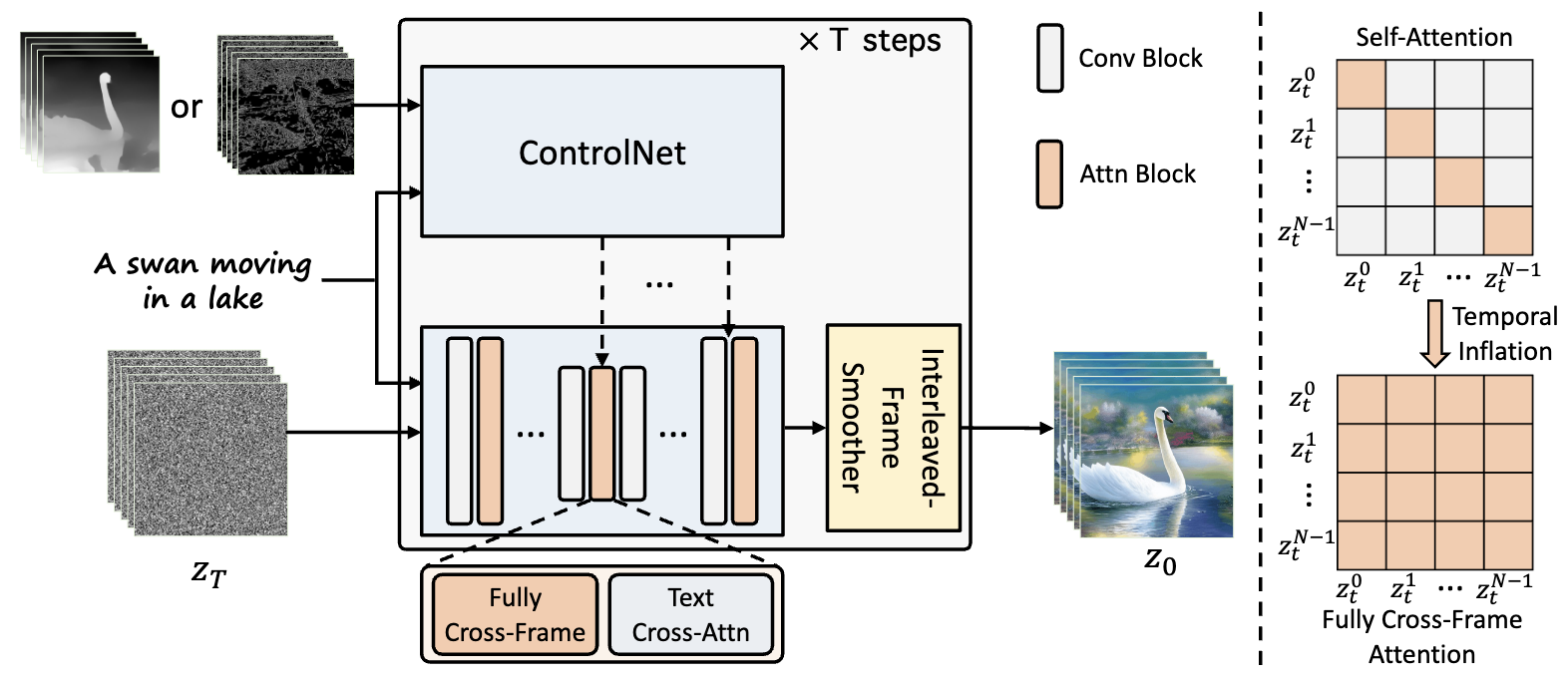
- Controllable text-to-video는 motion sequences c = {}와 text prompt 에 대한 video를 생성하는 것을 목표로 함. 위 그림은 전체적인 ControlVideo의 구조.
Fully cross-frame interaction.
-
video생성에서 temporal consistency를 보존하는 것이 중요. motion sequence를 ControlNet과 활용하여 대략적인 구조의 일관성을 줄 순 있다. 하지만 ControlNet을 그냥 사용하면 그래도 불일치가 생김.
-
일관성을 유지하여 비디오 프레임들을 concatenate 하여 “large image”라는 것을 만들어야 함. inter-frame interaction을 통해 content는 유지 될 수 있음. SD는 attention으로 외관이 많이 바뀌므로 attention-based fully cross-frame interaction를 사용함하여 통일성을 주려 함.
-
ControlVideo는 ControlNet에서의 auxiliary UNet를 유지하면서 시간 축을 따라 확장시킴. 3 × 3 커널을 1 × 3 × 3 커널로 대체함. 또한 모든 프레임에서 interaction을 추가하여 self-attention을 확장시킴.
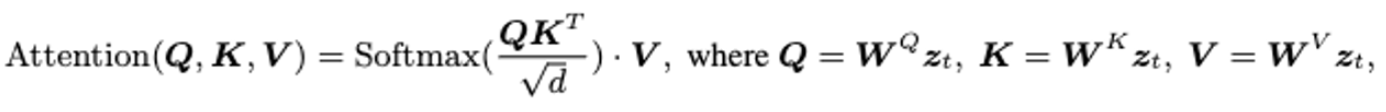 (Text2Video-Zero에서는 첫번째 frame과의 attention만 계산했었음)
(Text2Video-Zero에서는 첫번째 frame과의 attention만 계산했었음) -
= {}에서는 t에 따른 latent frame을 나타내고, 는 를 q,k,v에 projection 시킨 것. Tune-A-Video, Text2Video-Zero에서는 모든 프레임들은 첫번째 프레임과의 attention만을 연산하여 대략적인 cross-frame mechanism을 구하는 방식으로 self-attention을 대체. 이 방식은 self-attention의 q와 k간의 불일치를 증가시켜 일관성을 저하시키는 문제가 있음. 하지만 저자들이 제안하는 fully cross-frame mechanism 방법은 모든 frame을 large image로 결합하고, text-to-image model과 생성 gap이 적음.
Interleaved-frame smoother.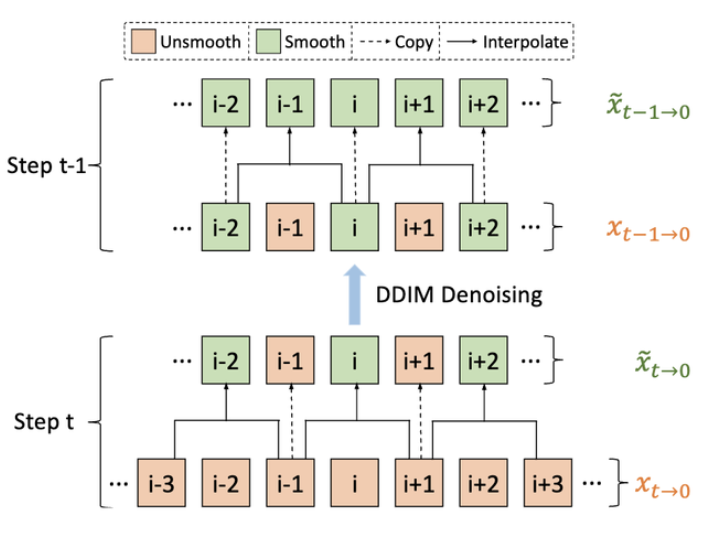
-
appearance의 일관성은 유지될 수 있지만, frame들의 깜빡임 현상은 여전하다. input motion sequences는 대략적인 구조적 일관성으로 합성된 비디오의 보장하고, 연속적인 프레임 간의 부드러운 전환은 유지할 수 없다. 문제 해결하기 위해 interleaved-frame smoother 적용.
-
이 방법은 중간 프레임을 interpolation하여 각 3프레임을 부드럽게 하는 것이다. 이를 interleaved 방식으로 반복하여 전체 비디오를 smooth하는 것이다.
-
interleaved-frame smoother는 연속적인 timestep에서 예측된 RGB 프레임에 대해서 수행한다. 각 시간 단계에서 짝수 또는 홀수 프레임을 보간하여 해당하는 3개의 frame clip을 매끄럽게 함. 이렇게 두개의 연속적인 timestep에서, smoothed된 3개의 프레임은 전체적인 비디오를 defilker 한다.
-
t에서 interleaved-frame smoother를 적용하기 전에, 아래 수식과 같이 를 사용하여 깨끗한 비디오 latent 를 예측
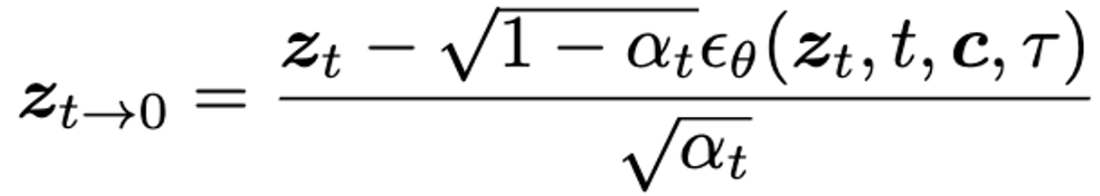
-
그 후 를 디코더 D에 태워 를 만듬. 그후 interleaved-frame smoother를 통해. 로 전환. 그다음 인코더 에 태워 를 만듬. 그 후 아래 DDIM 식으로 denosing 하여 을 만듬.
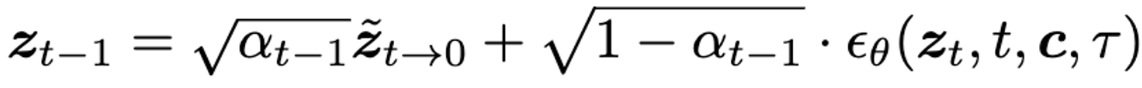
-
-
위 방법을 사용하면 선택한 중간 step에서만 (저자들은 {30, 31}에서만 수행함.) 수행하기 때문에 두가지 장점이 있음. 1: 새로 계산하는 부담은 무시할 수 있고, 2: 다음 denosing step에서, 보간되는 프레임의 특성과 퀄리티는 유지할 수 있음.
Hierarchical sampler.
-
video 생성은 frame만큼 이미지를 생성해야하기 때문에 GPU 사용량이 많다. 따라서 clip-by-clip manner로 긴 비디오를 생성하는 방법을 제시한다. 각 timestep에서 긴 비디오t = { }는 선택된 key frame = { }을 사용하여 여러개의 작은 비디오 클립으로 분리된다. 각 클립의 길이는 -1이고 k-th 클립은 다음과 같이 표현된다.
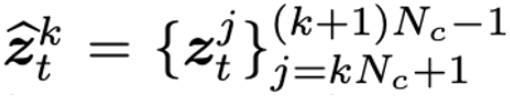
-
그런다음 long-range coherence를 위한 fully cross-frame attention으로 key frames을 미리 생성한다. q,k,v는 다음과같다.
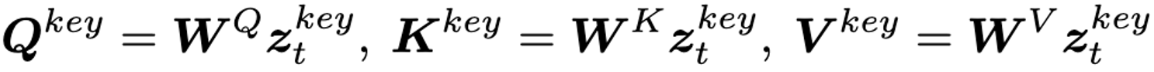
-
각 key frame 쌍을 조건으로, 전체적인 일관성을 유지하면서 해당하는 clip을 순차적으로 합성한다.
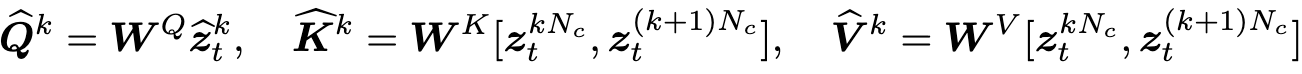
4. Experiments
- Frame Consistency, Prompt Consistency를 평가하기 위해 CLIP 사용.
Qualitative results. 
Quantitative results.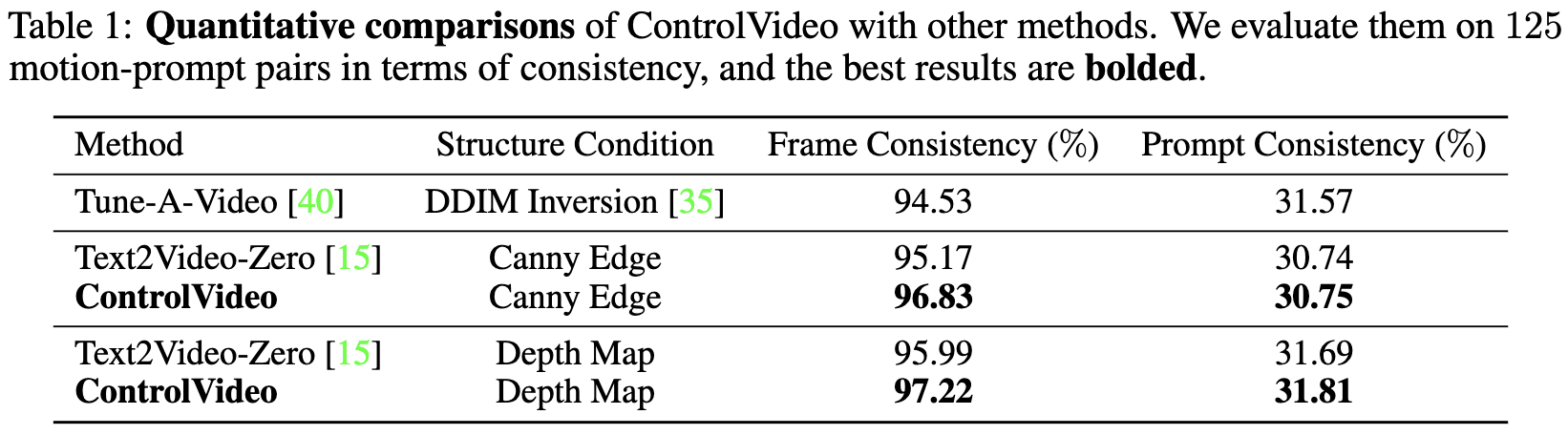
Ablation study
Qualitative ablation studies.
- fully cross-frame interaction, interleaved-frame smoother의 효과를 비교.

Quantitative ablation studies.

