Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators 논문 리뷰
Dfifusion
목록 보기
6/6
text-image model들만 보다가 video에 대해서 공부해보고 싶어서 봤던 논문.
23/10 Notion에 정리했던 글을 복습하는 차원에서 다시 블로그에 포스팅.
Abstract
- 이 논문은 기존의 text-to-image의 힘을 활용하여 Zero-shot text-to-video를 제안한다. Key modification은
- global scene과 background time이 일정하게 유지되도록 motion dynamics를 사용해 생성된 frame의 latent code를 풍부하게 한다.
- 첫번째 frame에서 각 frame에 대한 cross-frame attention을 사용하여 frame-level의 self-attention을 reprogramming 함. 전경 객체의 context, appearance, identity를 보존할 수 있음.
- 또한 제안하는 방법은 text-to-video에 국한되지 않고, conditinoal video generation, Video Instruct Pix2Pix와 같은 다른 task에도 적용 가능. 예를 들어 instruction-guided video editing 등이 있음.
- 추가적인 video data가 없음에도 불구하고 성능이 이전 sota model 보다 좋거나, 비슷한 수준.
1. Introduction
- 이전 연구들에서 text-to-image diffusion model들을 잘 이용해서 video domain의 text-to-video generation을 시도해왔다. 결과는 좋았지만 상당한 비용의 데이터가 많이 필요한 문제가 있었다고 한다.
- 이 논문에서는 최적화나 파인튜닝 없는 text-to-video 모델을 제안한다. 저자들의 접근법의 핵심 방법은 pre-trained text-to-image model을 변형하여 이를 temproally하게 일관적으로 생성하도록 만드는 것. 이 방법은 text-to-image model의 훌륭한 Image generation 퀄리티를 이용하여 추가적인 train없이도 video domain에 대한 적용성을 향상시킨다.
- temporal consistency를 강화하기 위해서 저자들은 혁신적이고 가벼운 두가지의 수정 사항을 제시함.
- 생성된 frame의 latent code를 motion information으로 강화하여 global scence과 time consistent의 일관성을 유지한다.
- 그런 다음 첫 번째 frame에서 각 frame의 cross-frame attention을 사용하여 전체 시퀀스에서 foreground object의 context, 모양, identity를 보존한다.
- 이 모델은 text-to-video synthesis 뿐만 아니라 condition을 주는 것, specialized video genration, instruction-guided video editing도 가능하다.
2. Related Work
2.1 Text-to-Image Generation
- 생략
2.2 Text-to-Video Generation
- Video Diffusion Models(VDM)은 Diffusion model을 자연스럽게 확장하고 이미지와 비디오 데이터를 공동으로 학습함. Imagen Video는 cascade video diffusion model을 구성하고 utilizesspatial and temporal super resolution model을 사용하여 고해상도의 time-consistent video를 생성한다.
- Make-A-Video는 text-to-image 합성 모델을 기반으로 하며, unsupervised 기반의 비디오 데이터를 활용한다. Gen-1은 SD를 확장하여 원하는 출력의 visual or textual descriptions을 기반으로 structure 및 content-guided 비디오 편집 방법을 제안함.
- 위에서 언급한 방법과 달리 우리의 접근 방식은 훈련이 전혀 필요하지 않음. Tune-a-Video는 하나의 비디오만으로 tuning하는 것이므로 우리 방벙과 가장 가까움. 그러나 여전히 optimization이 필요하며 reference 비디오에 크게 의존함.
3. Method
3.1 Stable difusion
- 생략
3.2. Zero-Shot Text-to-Video Problem Formulation
- 기존의 Text-to-video 합성 방법은 데이터가 너무 많이 듬(1M ~ 15M). 따라서 저자들은 새로운 Zero-shot text-to-video synthesis 문제를 제안.
- text description τ와 양의 정수 m이 주어지면, 우리의 목표는 temporal consistency를 나타내는 비디오 frame V ∈ 를 output으로 하는 함수 F를 디자인 하는 것이다. 이때 F를 결정할때 비디오 data set에 대해서 train 및 fine tuning을 하면 안된다.
- Zero-shot text-to-video는 text-to-image model 퀄리티를 자연스럽게 활용한다.
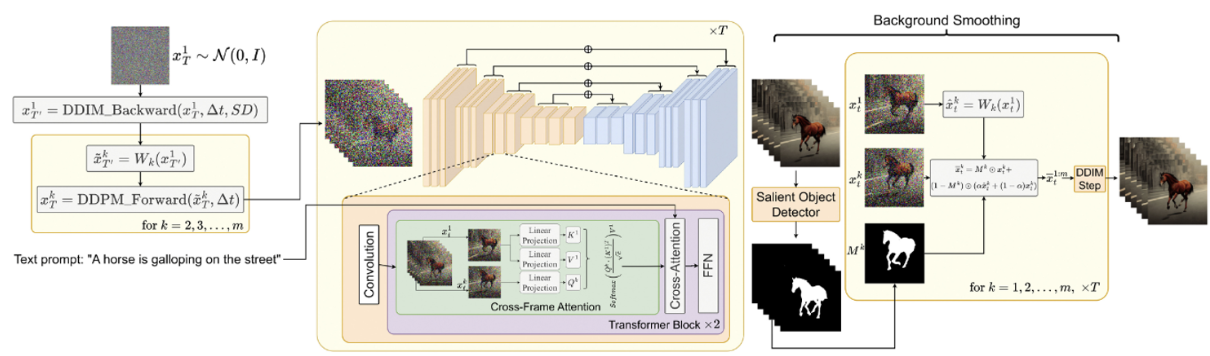
3.3. Method
- SD를 활용하며, image대신 video를 생성하기 위해선 latent codes의 sequence에서 작동해야한다. (당연히 안좋겠지만) 순수한 접근 방식은 m개의 latent code를 가우시간 분포에서 독립적으로 샘플링하는 것이다. , . . . , ~ N(0,I) 그리고 에(k = 1, . . . , m) 맞는 텐서를 얻기 위해 DDIM sampling을 적용한다. 그리고 decoding을 통해 generated video sequence({D()} ∈ )를 얻는다.
- 하지만 당연하게도 위의 방법은 text description τ에 의해서 설명되는 정보만 유지하고, 객체의 모양이나 모션 일관성은 전혀 고려하지 않는 완전한 radom한 image만 생성하게 된다. (1) : 이 문제를 해결하기 위해 , . . . , 사이에 motion dynamics를 주는 것을 제안한다. 이렇게 하면 global scene과 time consistent를 유지할 수 있다. (2) : 그리고 cross-frame attention mechanism을 사용하는 것을 제안한다. 이는 foreground object (사람이 걷고있는 영상일때 사람을 의미)의 identity와 apperance를 보존한다.
- 앞으로는 latent codes를 = [ , . . . , ] 이렇게 표현.
3.3.1 Motion Dynamics in Latent Codes
- 를 가우시안에서 랜덤하게 뽑는 것 대신 아래와 같은 방법으로 뽑자.
- 이 초기값은 N(0,I)에서 뽑자.
- ∆t ≥ 0인 t에 대해서 에 DDIM의 backward step을 거쳐서 를 구하자. 저자들은 = 881, T = 941로 설정했음
- global scene과 camera motion 에 대한 direction δ를 정의하자 δ = () ∈ . default δ는 main diagonal direction으로 될 수 있다. () = (1,1)
- 생성하고자 하는 각 frame k = 1,2,3,,,m 마다 global translation vector = λ·(k −1)δ 를 계산한다. λ는 global motion양을 조절하는 하이퍼 파라미터.
- 계산된 motion (translation) flow를 를 에 적용히고, 결과 시퀀스를
: for k = 1, 2, . . . , m라고 표현한다. 는 를 쓰는, translation을 위한 와핑 작업이다. - 각 latents 마다 ∆t 만큼 DDPM forward steps을 진행하고 상응하는 latent code 를 얻음.
- 정리하면 T에서 1-th frame에서 noise를 만들고, DDIM backward로 T'에서 1-th를 만듬. 그리고 W를 이용해서 m개의 frame을 만듬. 그 T'에서의 frame들을 다시 T로보내서 backward process의 시작점을 잡음. (맨 초기의 T는 정보가 부족해서 W함수를 사용해도 잘 와핑이 안되고 frame간에 서로 다른 정보들이 생성될 수 있기때문에 이렇게 하는 것 같다.)
- 최종적으로 얻은 를 backward diffusion process의 시작점으로 잡음. 결과적으로 제안된 motion dynamics로 생성된 latent code들은 배경 뿐만 아니라, global scene의 temporal consistency를 향상 시킨다. 하지만 초기의 latent codes는 특정 identities나 shape을 묘사하기에는 충분하지 않아 여전히 temporal inconsistencies가 발생함. 특히 foreground object에 대해서는 더욱 그렇다.
→ Warping을 했는데도 foreground object에 대해서 왜 identities를 묘사하기 힘들까? → diffusion이 backpropa를 하면서 stochastic하게 움직이기 때문이라고 생각한다. 따라서 3.3.2에서 나오는 방법처럼 diffusion process를 진행하면서 어떠한 처리를 해줘야함
-
warping에 대한 설명이 좀 부족해서 코드를 찾아봄
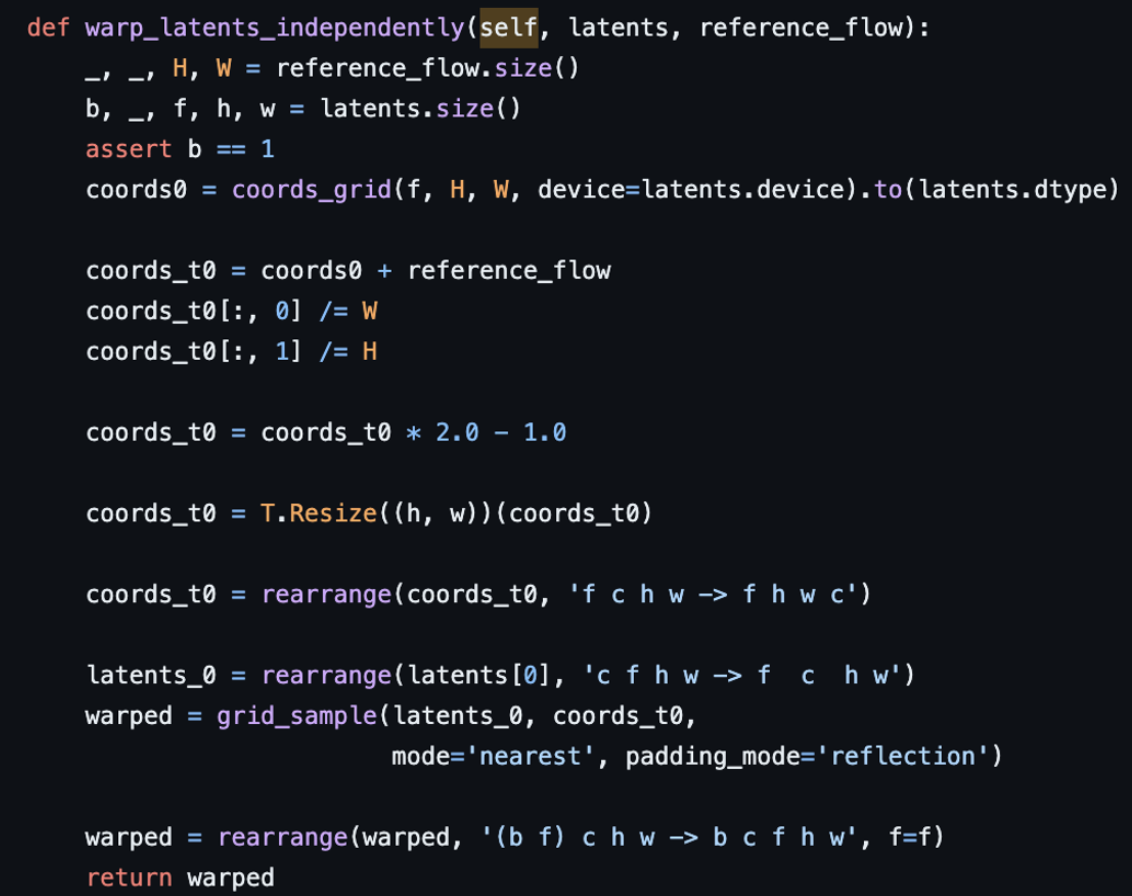
-
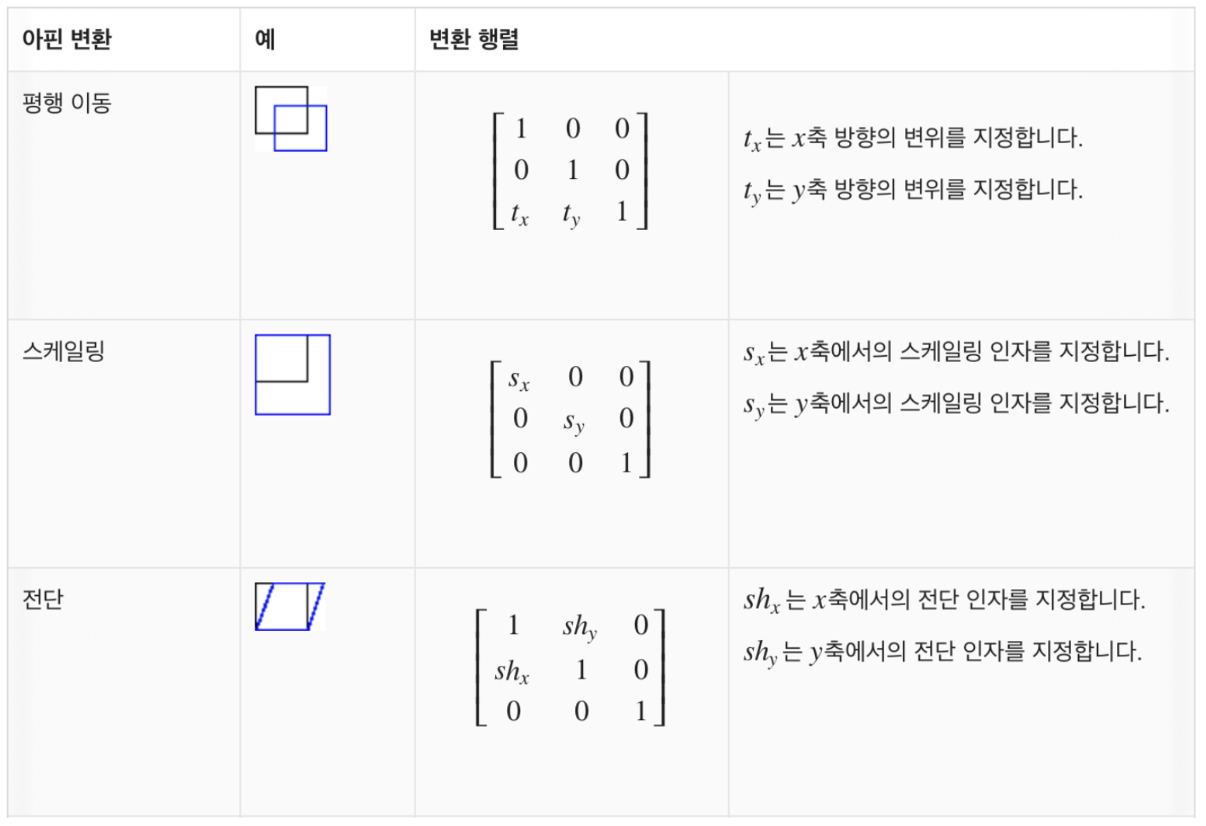
궁금해서 해본 warping (아핀변환) 코드 실습. 코랩 예시 링크 (coords(δ)를 이용해서 warping 가능)
-
아핀 변환
3.3.2 Reprogramming Cross-Frame Attention
- foreground object를 잘 인식하지 못하는 문제가 있음 → 이를 cross-frame attetnion mechanism을 사용하여 foreground object를 잘 인식
- 그림에서와 같이 기존의 self attention layer를 cross-frame attention으로 사용.

- 수식을 보면 알 수 있듯이, 각 m번째의 attention 결과는 첫번째 frame 과의 attention 연산을 거쳐 구하게 된다.
- 또한 위 그림을 보면, 기존의 self-attention대신 이 cross-frame-att를 적용하고, 원래대로 cross-att을 진행하여 text 정보를 넣어준다.
3.3.3 Background smoothing (Optional)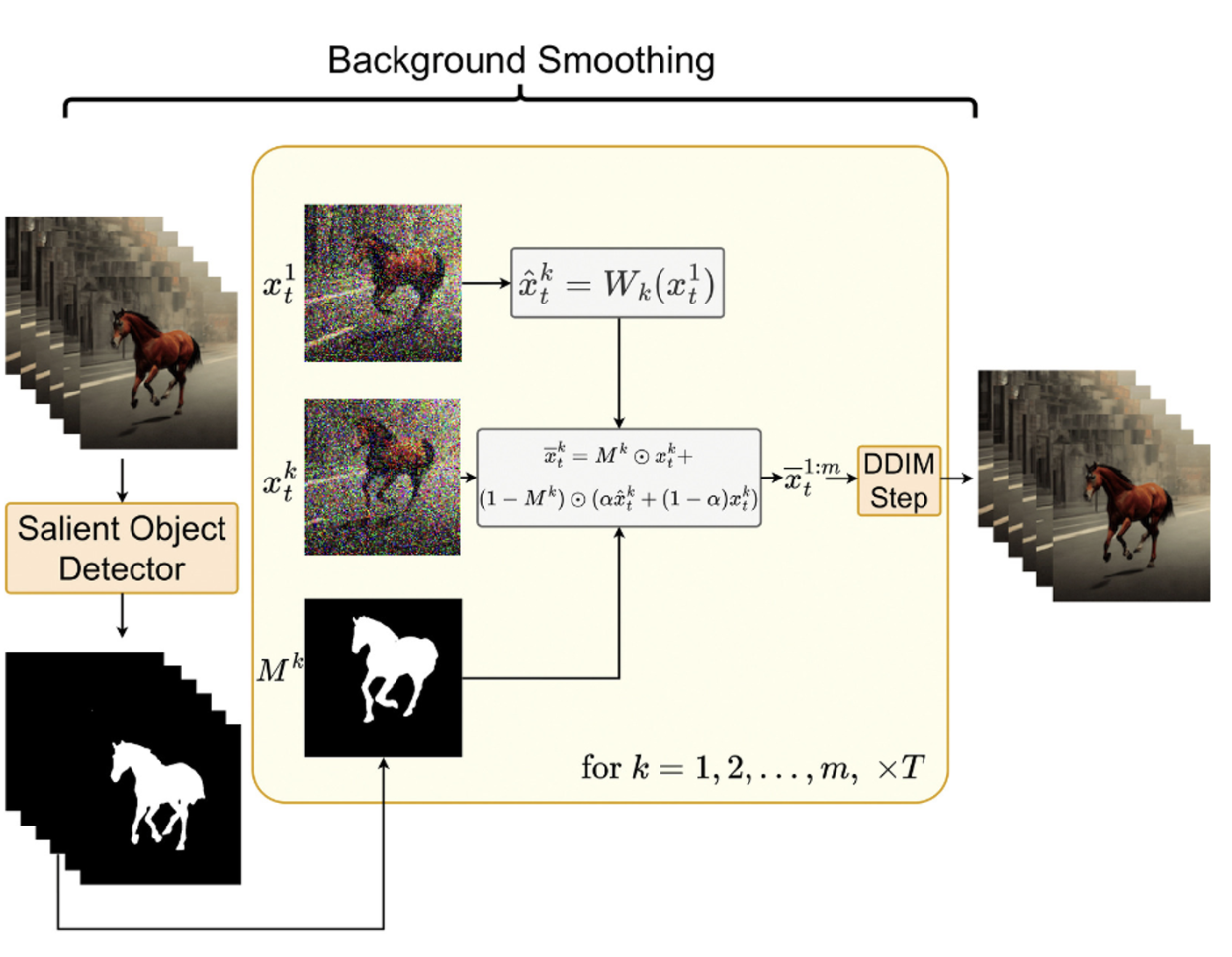
- 첫번째 frame과 k번째 frame간에 background-maksed latent codes를 convex combination 함
- 이 방법은 이미지가 하나도 주어지지 않고, text로만 비디오를 생성하고자 할때 특히 유용하다.
- 상세 방법
- 에 대해서 salient object detection(in-house solution) 수행하여 Mask 를 만듬.
- 를 이용해서 를 warping 하여 을 만듬.
- 최종 smoothing 수식은 아래와 같음.

- 실제 latent code : , 와핑된 latent code: , α는 하이퍼 파라미터 (0.6이 좋았음). 수식을 보면 α가 클수록 와핑된 x의 배경에 더 집중함.
- 최종적으로 에 DDIM이 적용되어 background smoothing으로 비디오 생성을 하게 된다. 이 방법은 guidance가 제공되지 않고, text generation하는 경우 사용한다.
3.4. Conditional and Specialized Text-to-Video
- ControlNet으로 Image에 다양한 condition을 줄 수 있음. 그냥 비디오에 controlnet을 적용하는 것은 좋지 않음. 저자들의 방법으로 더 consistent한 ControlNet 기반의 video 를 생성할 수 있음.
- ControlNet은 condition c와 를 받고, 기존의 Unet의 encoder 부분을 그대로 복사하여 학습시킨다. (이때 zero convolution 활용) 그리고 원래 layer에 skip-connection 방식으로 연결해준다. 여기서 c는 매우 다양한 입력 (seg map, pose 등)이 가능하다.
- 저자들은 기본 ControlNet방식에 자신들의 방법을 적용함. main UNet에 motion information과 cross-frame attention을 추가한다. 또한 DreamBooth weight를 추가함.

3.5. Video Instruct-Pix2Pix
- Prompt2Prompt와 같은 방법론이 등장하면서 text-guided video editing 방법론들이 나타나기 시작했지만 모두 훈련이 필요. 저자들은 훈련없이 video editing을 함.
- 저자들은 Instruct-Pix2Pix와 자신들의 방법을 적용함. Instruct-Pix2Pix의 self-attention mechanisms에 cross-frame attention을 적용함. → 성능이 좋음.

4 Experiment
4.1. Implementation Details
- m = 8, 512 × 512 resolution 사용. text-to-video 에선 T′ = 881, T = 941를 사용함. Video Instruct-Pix2Pix에서는 we take T ′ = T = 1000 사용.
4.4. Ablation Study
- Motion Dynamics를 사용하면 확실히 더 일치성이 좀더 생기지만, Cross-Frame Att을 함께 사용하면 성능이 더욱 좋아짐.

느낀점
- t2i만 공부하다가, t2v diffusion model은 처음 봤는데, 생각보다 이해가 쉽고 재밌다.
- text-to-image, Clip 등의 Background를 알고 있으면 읽기 쉬운 논문이었던 것 같다.
- 실무에서 Zero-shot model들의 유용함을 처음 느꼈는데, Zero-shot model에 재미를 붙인 것 같다.

이전 tistory 블로그 주소: https://dohwai-ai.tistory.com/ tistory는 정리하기가 너무 불편해서 velog로 블로그를 이전했습니다.