0. Anomaly Detection?
- 정상 데이터가 가진 특징을 기반으로 이와 다른 결과가(정상 데이터와의 분포의 차이) 발생했을 때 비정상 데이터로 감지.
1. Introduction
- 학습 과정없이 정상 데이터의 feature를 추출하여 비정상 이미지를 탐지.
- 적은 양의 정상 이미지 만으로도 높은 성능 달성
- 정상 데이터와 다른 해상도의 이미지도 적용가능한 구조
2. Related Works
MVTec AD dataset
- banchmark dataset, texture와 object로 구분되어 있고 15개 제품이 존재
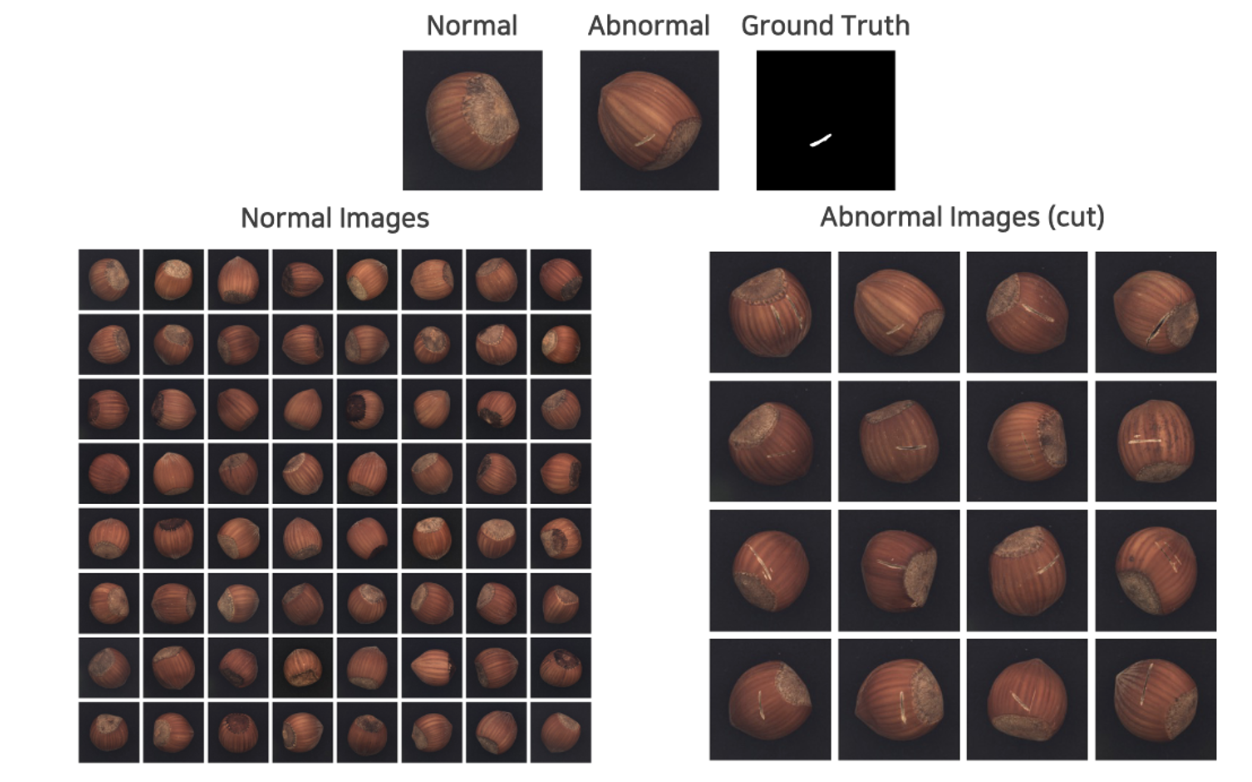 왼쪽이 정상, 오른쪽이 비정상 이미지
왼쪽이 정상, 오른쪽이 비정상 이미지
이상치 탐지를 위한 비지도 학습 방법
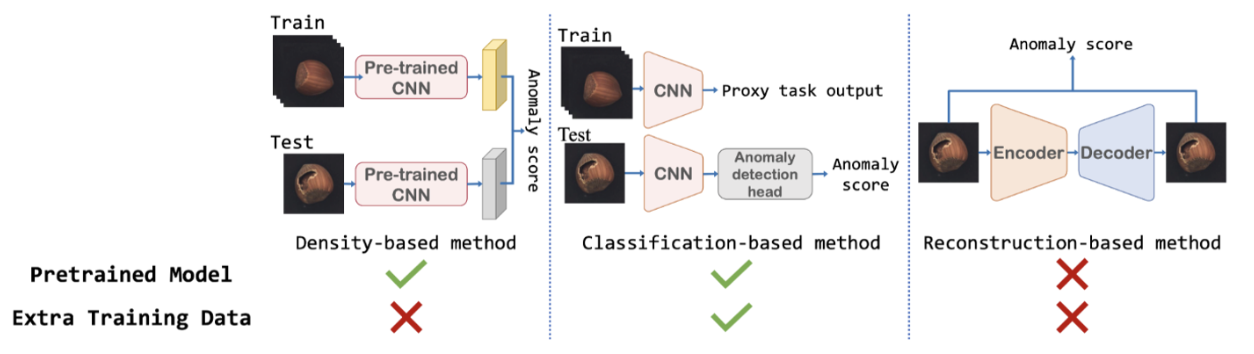
- Densitiy-based method: 정상 데이터의 분포를 통해 비정상 데이터를 탐지 → PatchCore
- pre-trained model로부터 추출한 feature map을 통해 이상치를 판단. → 학습과정 필요 없음.
- Classification-based method: proxy task(ssl과 같은 방법)를 정의하여 사전학습 수행 후 one-class classification 적용하여 비정상 데이터 탐지
- pre-trained model과 학습과정이 필요함.
- Recontruction-based method: 정상 데이터만을 복원하도록 학습하여 비정상 데이터 추론 시 재구축된 결과와 차이로 비정상 데이터 탐지
- GAN이나 AutoEncoder 같은 모델 사용
- PatchCore의 기반이 되는 모델
- SPADE : Sub-Image Anomaly Detection with Deep Pyramid Correspondences (2005)
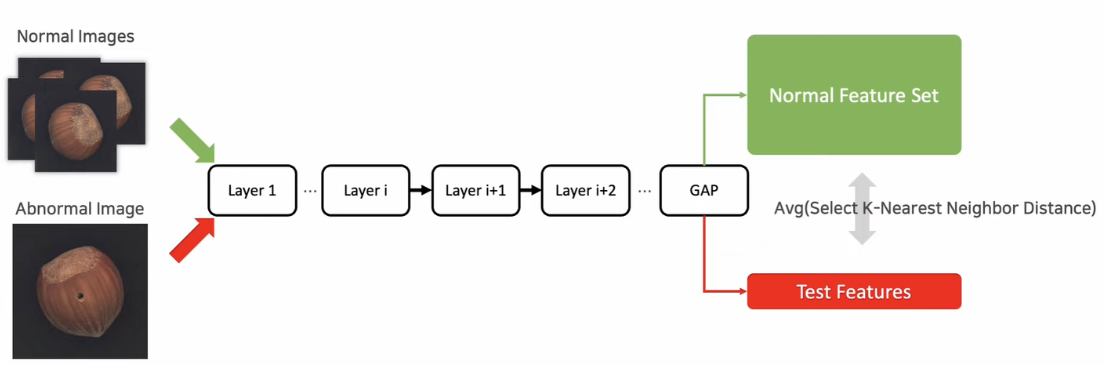 사전학습 모델을 사용하여 정상 데이터들로만 Global Average Pooling을 추출, Test도 추출하여 비교 (KNN Distance 사용)
사전학습 모델을 사용하여 정상 데이터들로만 Global Average Pooling을 추출, Test도 추출하여 비교 (KNN Distance 사용) - PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization (2011)
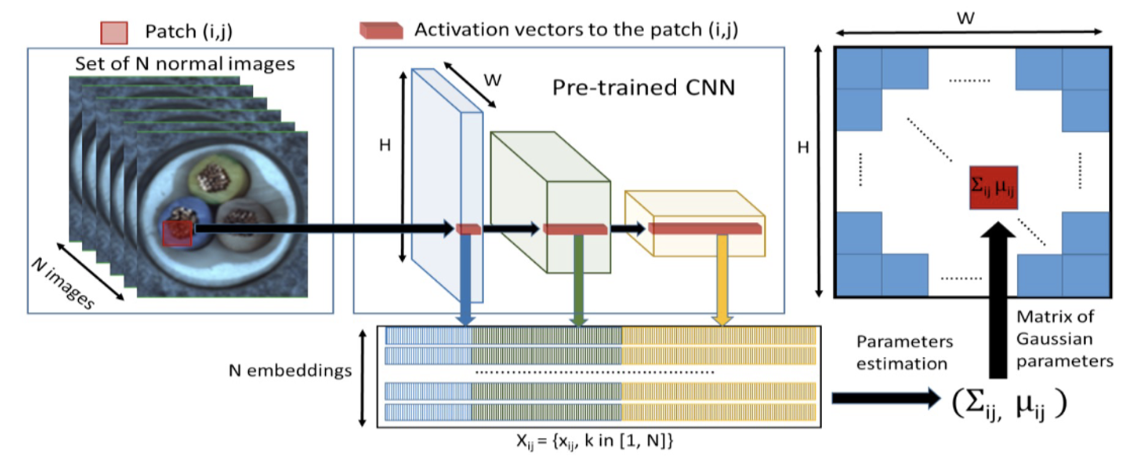 정상데이터에 대한 사전학습 모델의 각 layer의 output feature map을 모으고, 각 위치에 대해서 평균, 분산, 공분산 계산. test 시에 들어오는 새로운 데이터의 분포와 거리 비교(mahalanobis)하여 이상치를 판단
정상데이터에 대한 사전학습 모델의 각 layer의 output feature map을 모으고, 각 위치에 대해서 평균, 분산, 공분산 계산. test 시에 들어오는 새로운 데이터의 분포와 거리 비교(mahalanobis)하여 이상치를 판단
- SPADE : Sub-Image Anomaly Detection with Deep Pyramid Correspondences (2005)
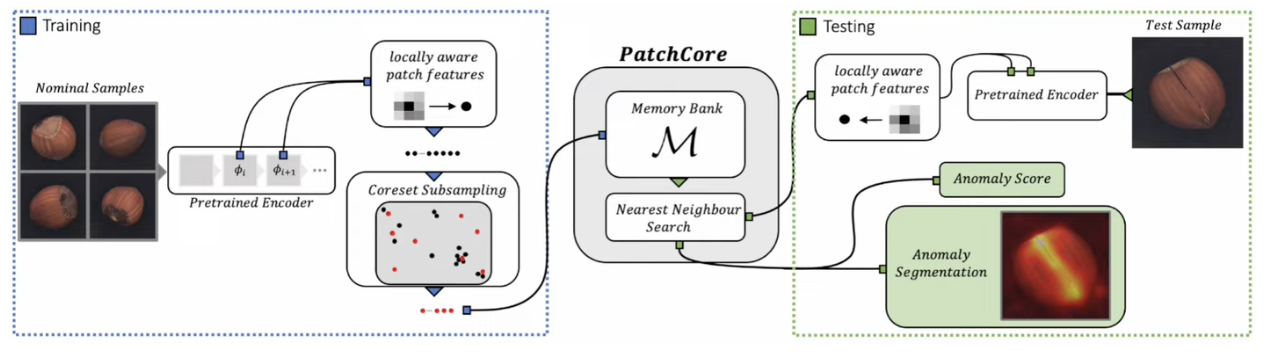
3. PatchCore
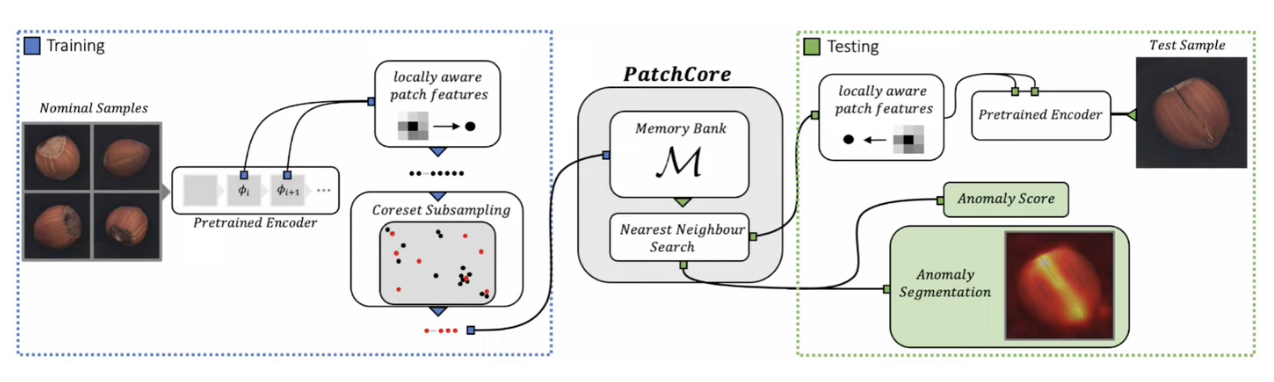
- Local patch features
- Coreset Subsampling
- Detection and Localization
Local patch features
-
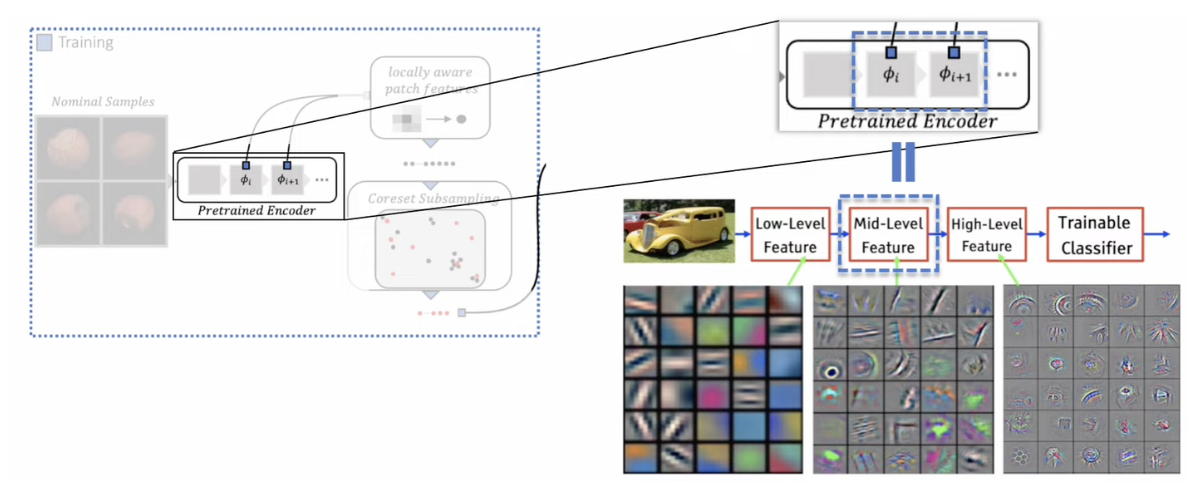
Mid-Level feature를 Local patch features로 사용
-
대부분 이상치 탐지 모델은 High-Level feature를 사용하지만 두 가지 문제점이 존재
-
(1) 공간적 정보의 손실이 큼 (2) ImageNet classification task에 대한 bias가 많이 존재함
-
중간 레이어의 몇개의 output을 사용함.
-
이유 : high level 같은 경우 local한 정보가 너무 사라지고 함축적인 정보가 크고, 보통 imagenet을 기반으로 훈련된 모델을 fine tuning 하기 때문에 마지막 레이어에 그 데이터 셋에 대한 bias가 반영이 되어 있다.
-
동작 예시
- 첫번째 layer
- Feature map: Cx6x6, patch size : 3, stride : 1
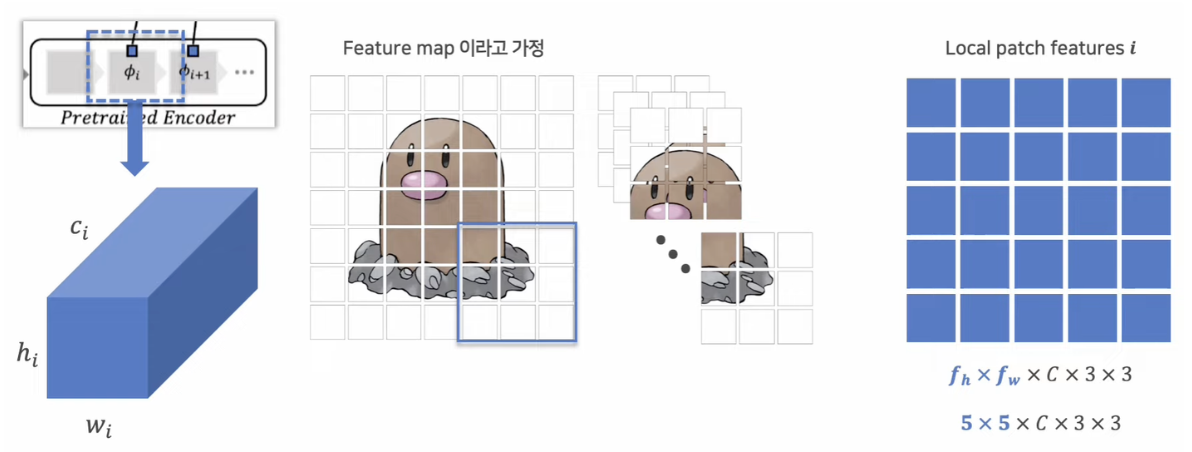
- 두번째 layer (일반적으로 첫번째 layer보다 feature map size가 적음)
- Feature map: Cx5x5, patch size : 3, stride : 1 → interplation
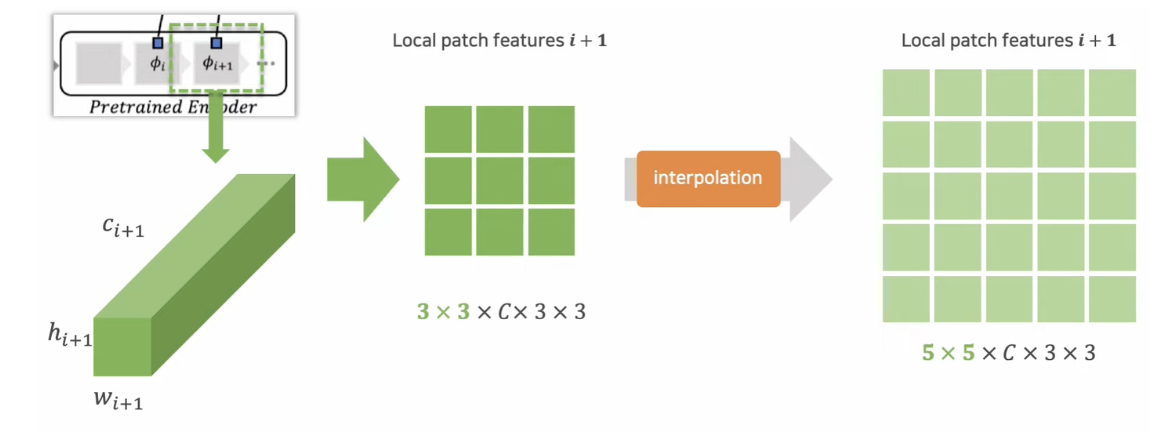
-
두 결과를 합쳐 GAP 적용
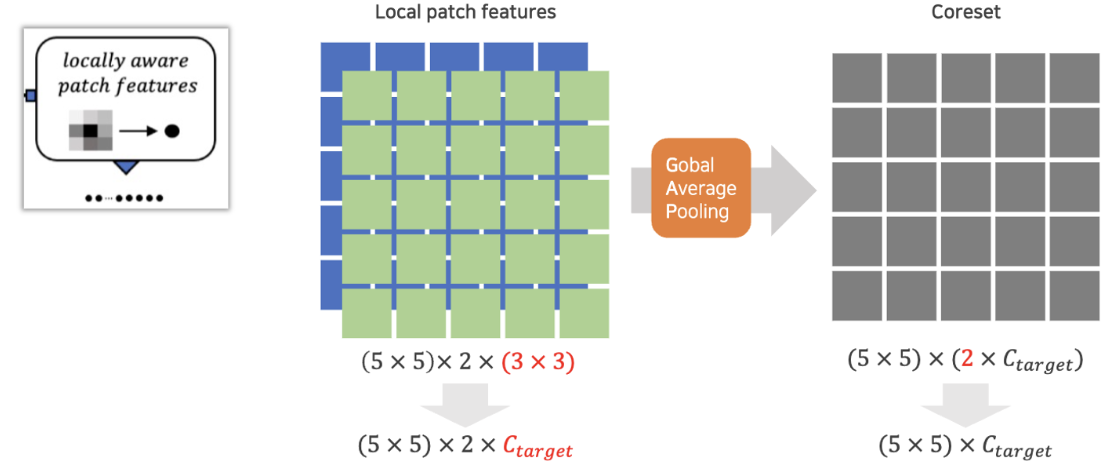
- 위와같이 정상 데이터셋에 대하여 coreset을 만듬
Coreset Subsampling
-
Greedy Search 방법으로 subsampling을 수행 → 정상데이터의 모든 정보를 가지고 있을 필요가 없기 때문. 중복 되거나 유사한 것들이 많아 unique한 정보만 가져오게 하기 위함.

- 처음 하나를 설정하고, 멀리있는 coreset을 가져옴 → Greedy 하게
-
Random Subsampling에 비해 중복된 비중이 적고 정상 feature가 고르게 선택됨
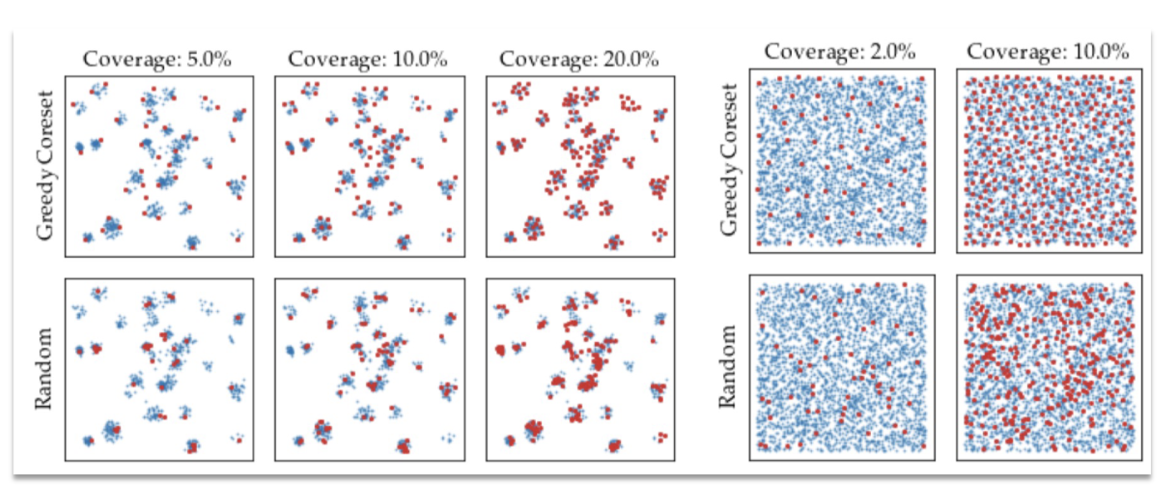
Detection and Localization
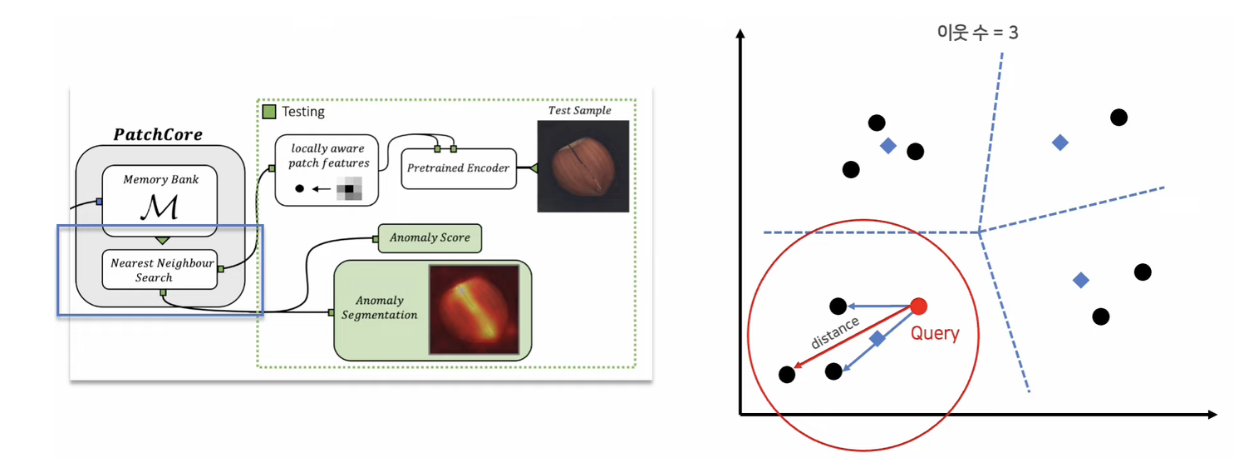
- Test image에 대한 local patch features 추출하여 각 patch features를 memory bank에 query로 사용 (정상 데이터셋의 coreset이 memory bank에 있다고 가정)
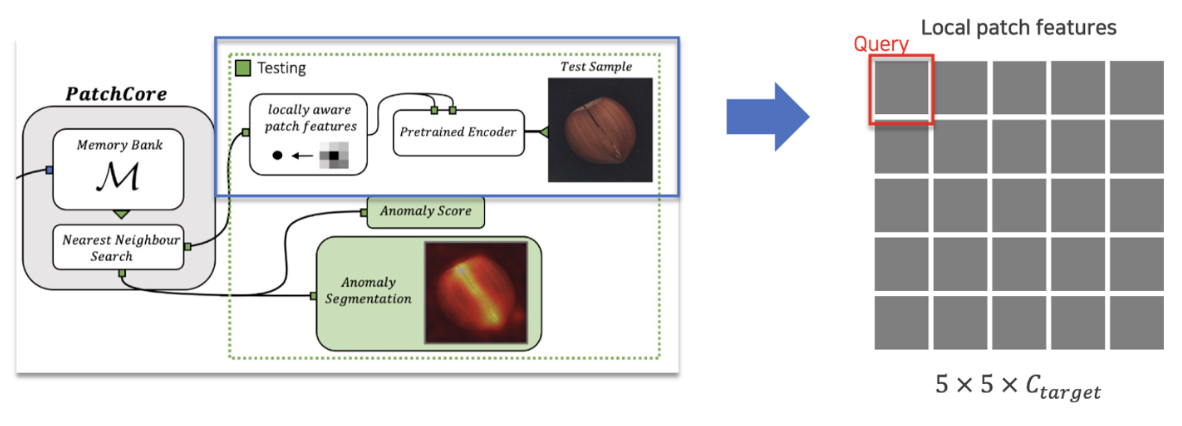
- Nearest Neighbor 방법을 통해 query와 coreset에 대한 distance 를 기준으로 anomaly score 계산
- Nearest Neigbhor는 faiss를 통해 빠르게 연산 가능
- Faiss는 모든 관측치와 비교하지 않고 cluster을 활용하여 효율적인 similarity 계산을 가능하게 함. (중심과 비교하며 가까운 클러스터 먼저 선택, 클러스터에서 가장 먼 distance를 해당 patch의 distance로 설정.)
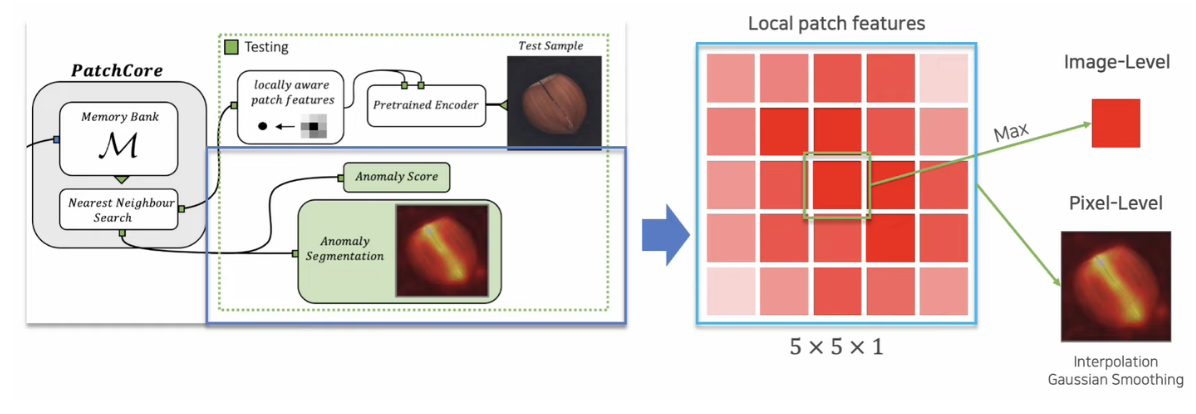
- 각 local patch feature에 대한 anomaly score는 Image / pixel–level 로 나누어 표현
- Image-Level: patch들 중 가장 큰 anomaly score를 image에 대한 anomaly score
- Pixel-Level: local patch에 대한 resolution을 원본 이미지 크기로 interpolation 후 gaussian smoothing을 적용
4. Experiments
Metric
- Image-AUROC : pixel 중 최대값을 선택하여 해당 이미지의 anomaly score로 나타낸 후 계산
- Pixel-AUROC : 각 pixel 별 anomaly score와 ground truth인 binary mask를 통해 pixel 단위로 계산
- AUPRO (Area Under the Per-Region-Overlap-curve) → IOU와 유사한 Metric
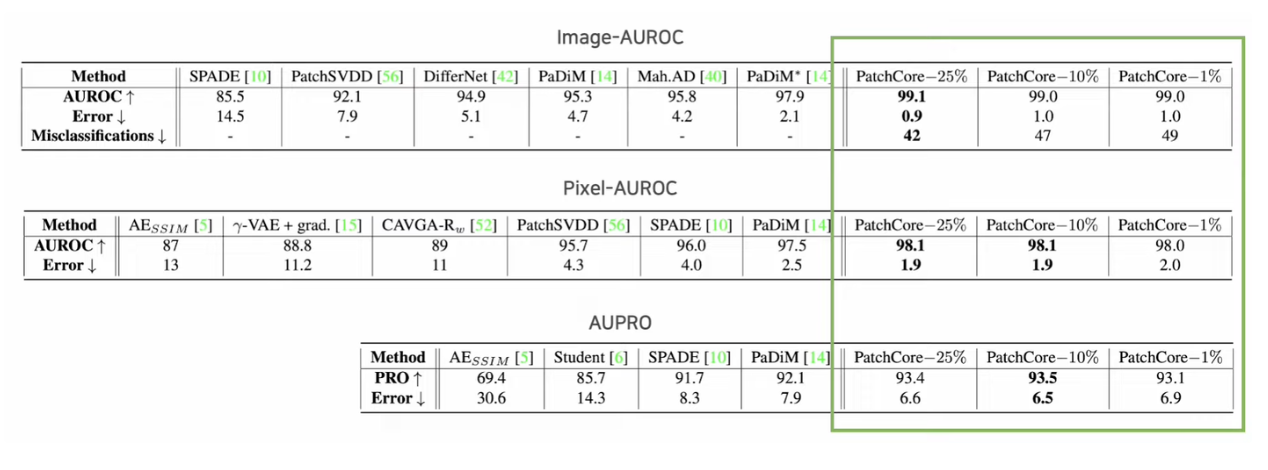
1. MVTec AD 결과
- ImageNet-1K에 사전학습 된 WideResNet-50 사용 (224 x 224 resolution)
- Memory Bank의 크기를 정상 데이터의 coreset을 1%만 활용하여도 기존 방법 대비 높은 성능
- Coreset의 sampling 비율에 따라 성능에 큰 차이를 보이지 않음 (효율적인 subsampling 방법 덕분에 정상 샘플을 효율적으로 저장)
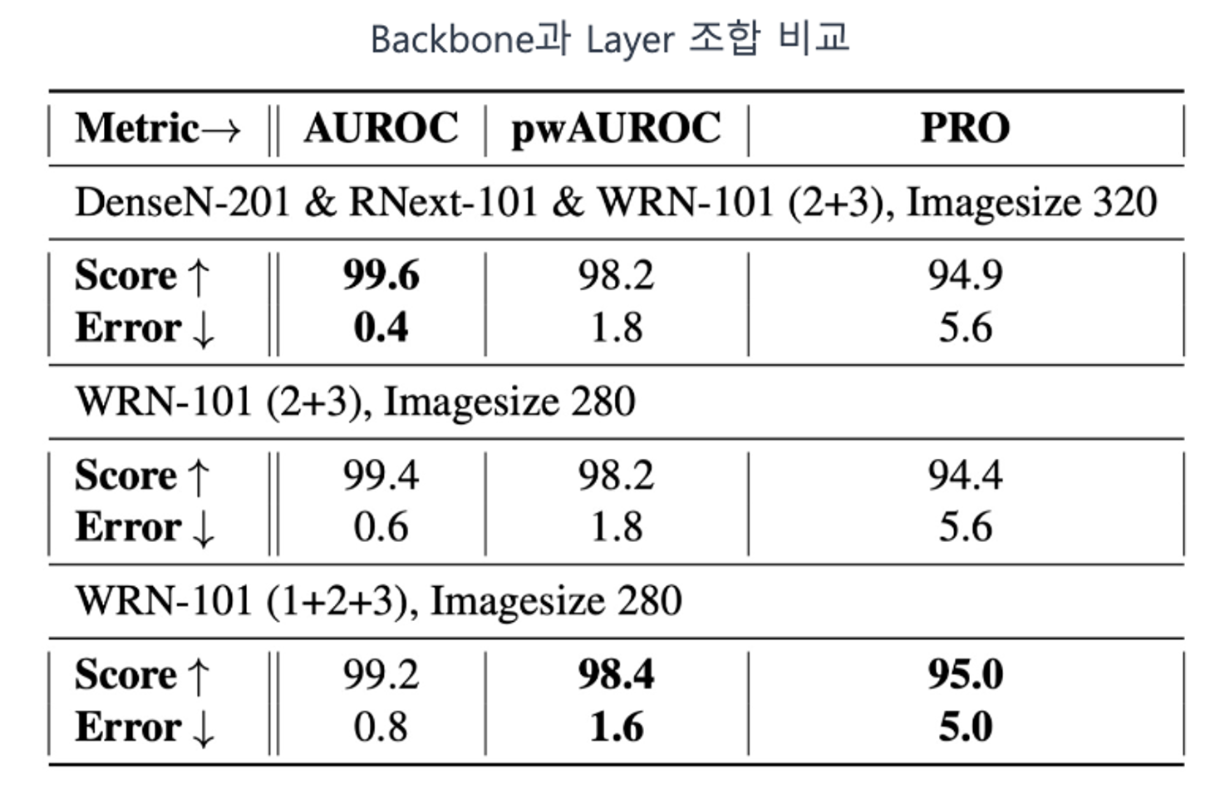
2 Backbone과 Layer 조합 비교
- Backbone의 classification 성능에 따라 모든 지표가 개선되지 않음
- Pixel-AUROC(pwAUROC)와 1,2, 그리고 3번째 layer의 local patch features를 사용하는 것이 가장 좋음
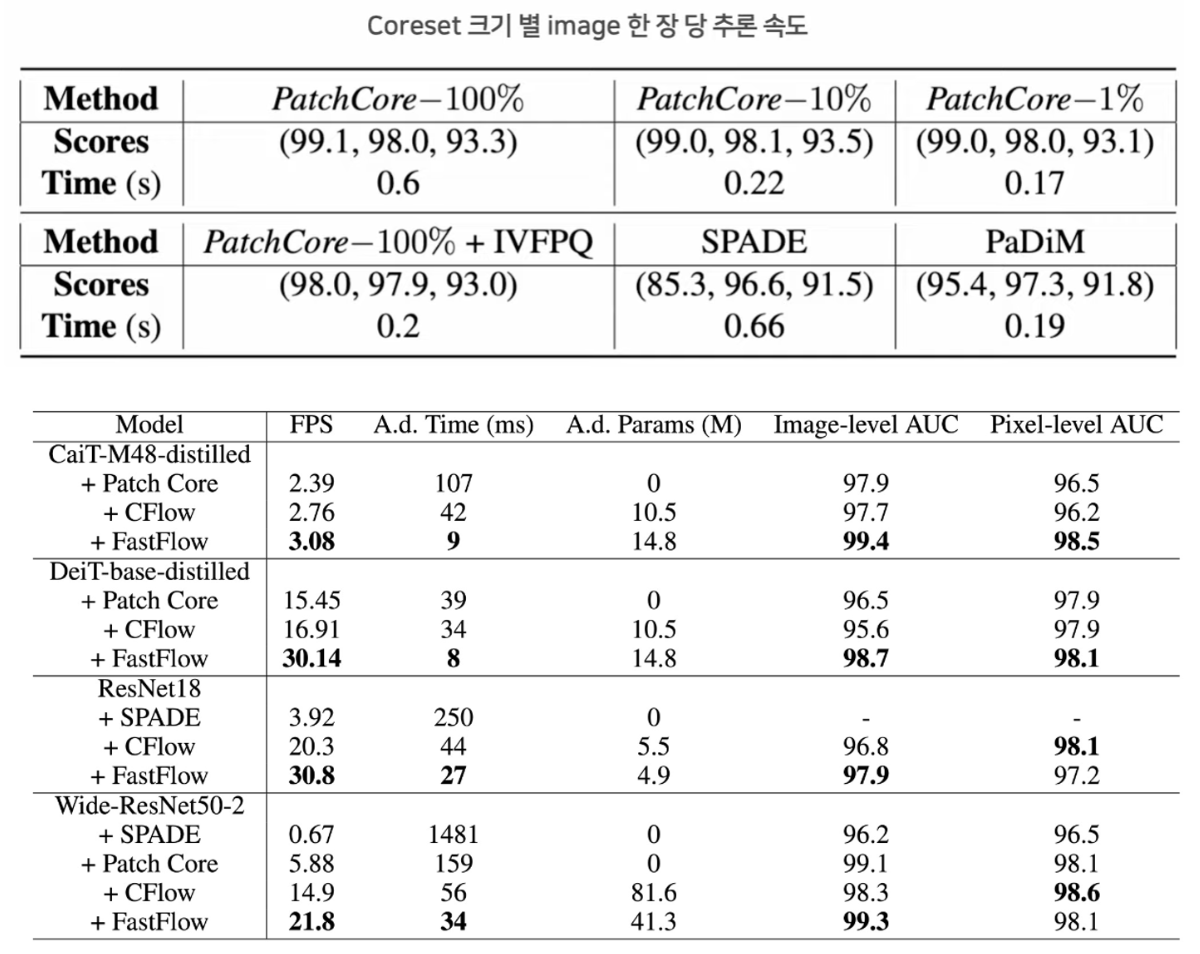
3 Coreset 크기 별 inference 속도
- Coreset에 따라 큰 성능 차이는 보이지 않지만 속도에서 큰 차이가 발생
- 현실에서 적용하기에 빠른 속도는 아니고 FastFlow와 비교해도 큰 차이가 남 (최대 4배)
4 정상 이미지 수에 따른 성능 비교
-
Prev. SOTA: WideResNet50을 backbone으로 사용한 PaDiM
-
적은 데이터 수에도 기존 방법 대비 높은 성능을 보임
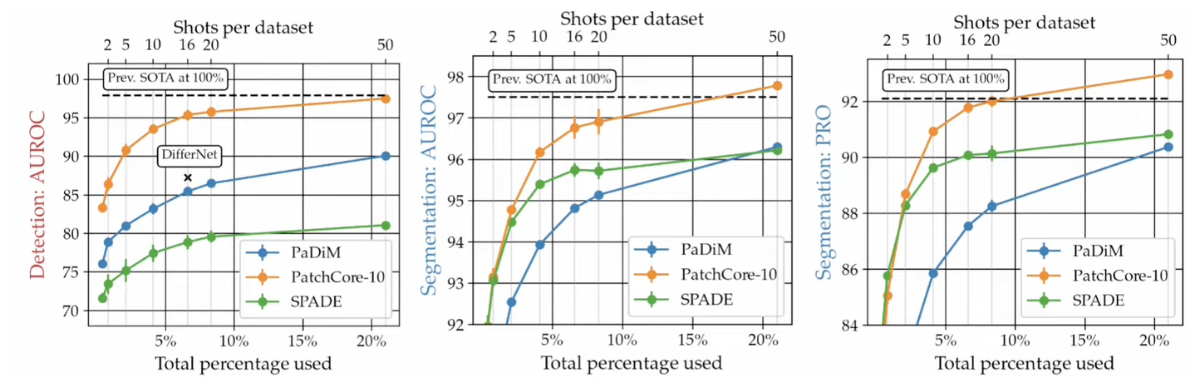
- subsampling을 통해서 적은양의 coreset의 으로 좋은 성능을 낼 수 있지만 애초에 학습 데이터가 적게 존재하는 상황에서도 좋다!!
5. Anomaly Detection Models
- 위에서 살펴봤던 Densitiy-based method, Classification-based method, Recontruction-based method 중 Densitiy-based method이 간단하지만 MVTec AD에 대해서 좋은 성능을 내고 있다.
- Densitiy-based method는 일반적으로Patch-based Model과 Normalizing Flow 의 두 큰 분야로 구분할 수 있다.
Patch-based Model
- 장점
- 적은 양의 학습 데이터 정보만으로도 높은 성능
- PatchCore or SPADE와 같은 경우 학습 과정이 필요하지 않음
- 단점
- 학습 데이터의 수량이 늘어나면 정상 데이터의 분포를 반영하는데 자원이 많이 필요함 (ex. Similarity 연산)
- 추론 시간이 빠른편은 아님
Normalizing Flow
- 장점
- 데이터의 양이 늘어나도 필요한 자원의 크기는 동일 (동일한 batch size를 사용한다는 가정)
- 추론 시간이 빠른편
- 단점
- 학습 시간이 필요함
- Layer 간 information 공유가 없음
6. Code
dsba의 세미나 영상을 참고하였습니다.

이전 tistory 블로그 주소: https://dohwai-ai.tistory.com/ tistory는 정리하기가 너무 불편해서 velog로 블로그를 이전했습니다.