[논문 리뷰] AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models
Anomaly Detection
0. Abstract
- MiniGPT-4, LLaVA 와 같은 모델들이 LLM이 image를 이해할 수 있다는 것을 보여주었음. LVLM은 인터넷 상의 매우 많은 데이터를 사용하여 common objects 를 학습했음. specific domain이나, object의 localized details를 이해하는데 부족하여 Industrial Anomaly Detection(IAD)에서는 그 효율성이 낮았음.
- 한편, IAD 분야에서는 anomaly scores를 계산하여 thresholds를 직접 지정해줘야해서 현실적인 구현에 제한이 있었다.
- 이 논문에서는 IAD의 위 문제를 해결하기 위해 LVLM을 활용한 AnomalyGPT를 제안한다.
- thresholds 지정 필요 없음. 이상치의 존재와, 위치를 directly하게 평가함.
- multi-turn dialogues가 가능함.
- few-shot in-context learning 에서 좋은 성능을 보임.
1. Introduction
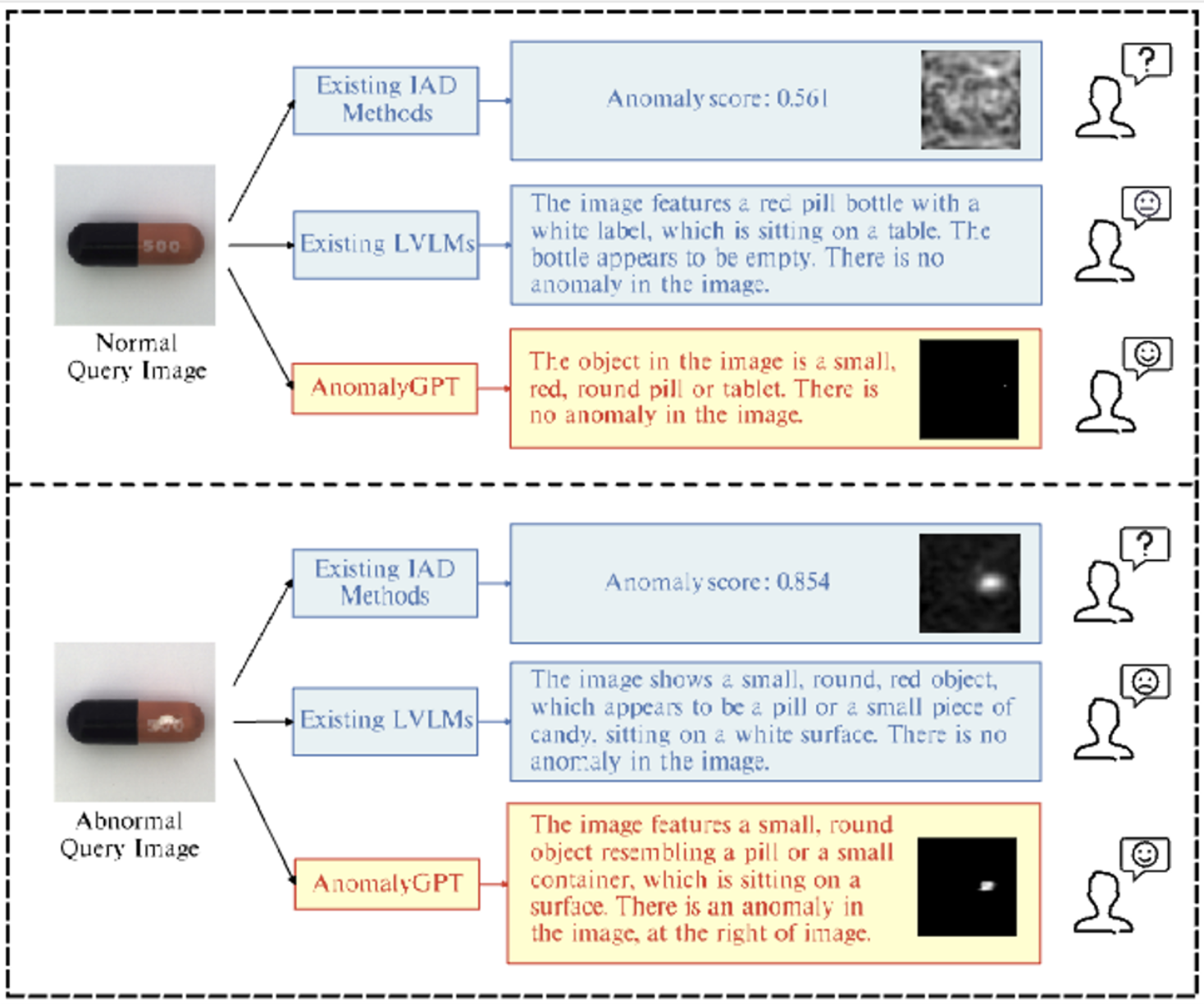
- IAD Method 와 LVLM, Anomaly GPT를 비교한것. IAD와 LVLM 모두 IAD problem을 완벽히 해결X
-
LVLM은 인터넷상의 방대한 양의 데이터를 학습했기에, domain-spcific knowledge가 부족하며 객체 내의 local details에 대한 sensifivity가 부족하기에 IAD task에서 성능이 좋지 않음.
-
IAD는 정상 샘플에 대해서만 학습하고, 이상치가 들어왔을때 그 이상치를 판별해야함. thresholds를 직접 설정해야 해서 production environments에서 적합하지 않음.
-
LVLM는
- 수동으로 thresholds를 설정할 필요가 없음.
- 이미지에 대한 정보도 제공하고 대화형 방식으로 user들은 필요에 맞게 질문들을 할 수 있다.
- 적은 수의 정상 샘플들을 사용한 in context learning을 통해, 이전에 보지 못했던 객체에 대해서 swift adaptation이 가능하다.
-
LVLM을 synthesized anomalous visual-textual data를 사용하여 파인튜닝하는 방식으로 IAD의 지식을 모델에 전파한다.
- LVLM을 학습했던 양에 비하여 데이터 수가 너무 적기(160k → few k개) 때문에 오버피팅과 사전 지식에 대한 망각현상이 일어날 수 있다. 따라서 LVLM을 직접 튜닝하는 것이 아니라 프롬프트 임베딩을 통해 파인튜닝한다.
-
pixel-level로 anomaly localization 결과를 생성하기 위해 가벼운 visual-textual feature-matching-based decoder 제안
- 디코더의 아웃풋은 원래 test image의 prompt embedding과 함께 LVLM에 도입된다. → 두 정보를 모두 활용하여 이상판단 정확도 향상.
Contributions
- threshold 필요없고, 대화 형식도 지원함 LVLM을 IAD에 사용한 것의 최초 모델.
- 가벼운 visual-textual feature-matching-based decoder 제안하여 fine-grained semantic의 대한 식별능력이 부족한 한계를 해결.
- prompt embeddings을 사용하여 LLM을 튜닝하고, 이때 LVLM이 pre training 되는 동안 사용했던 데이터를 동시에 사용함. → LVLM의 고유 기능과 multi-turn 대화 기능이 보존될 수 있게 함.
3. Method
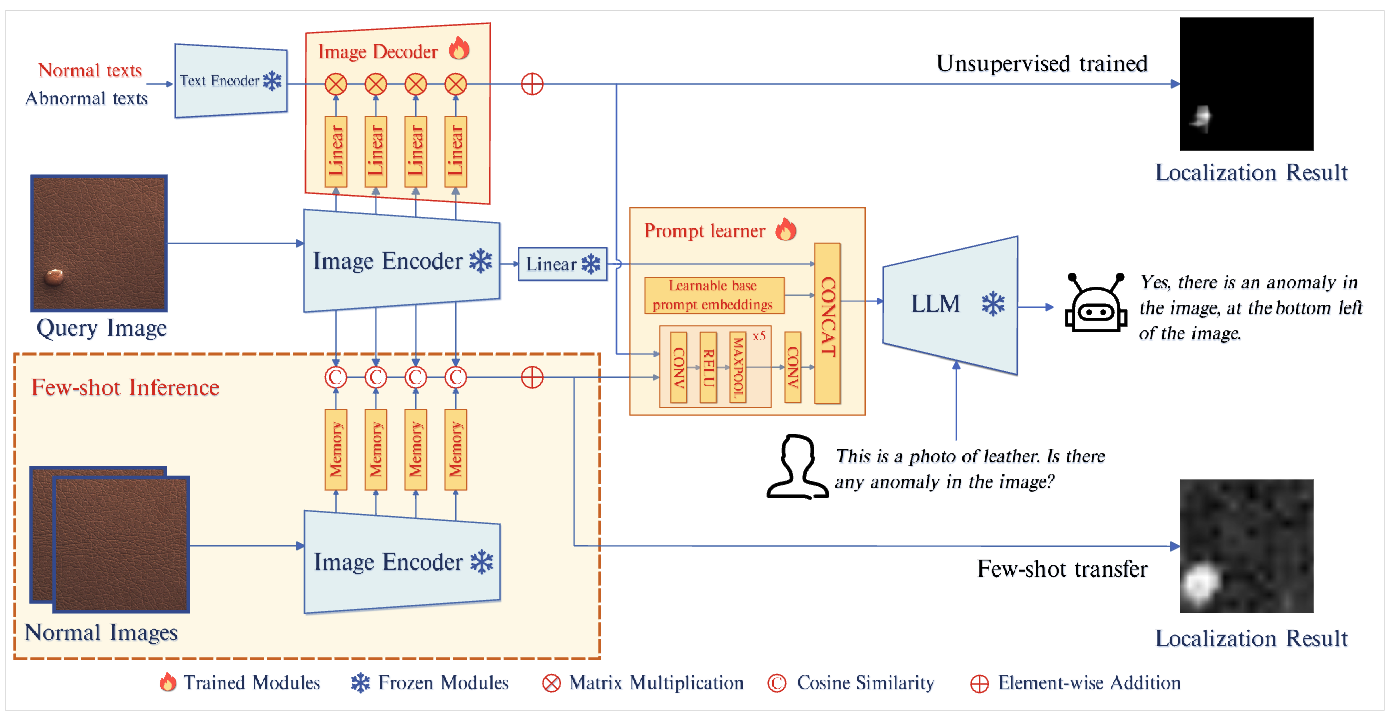
3.1 Model Architecture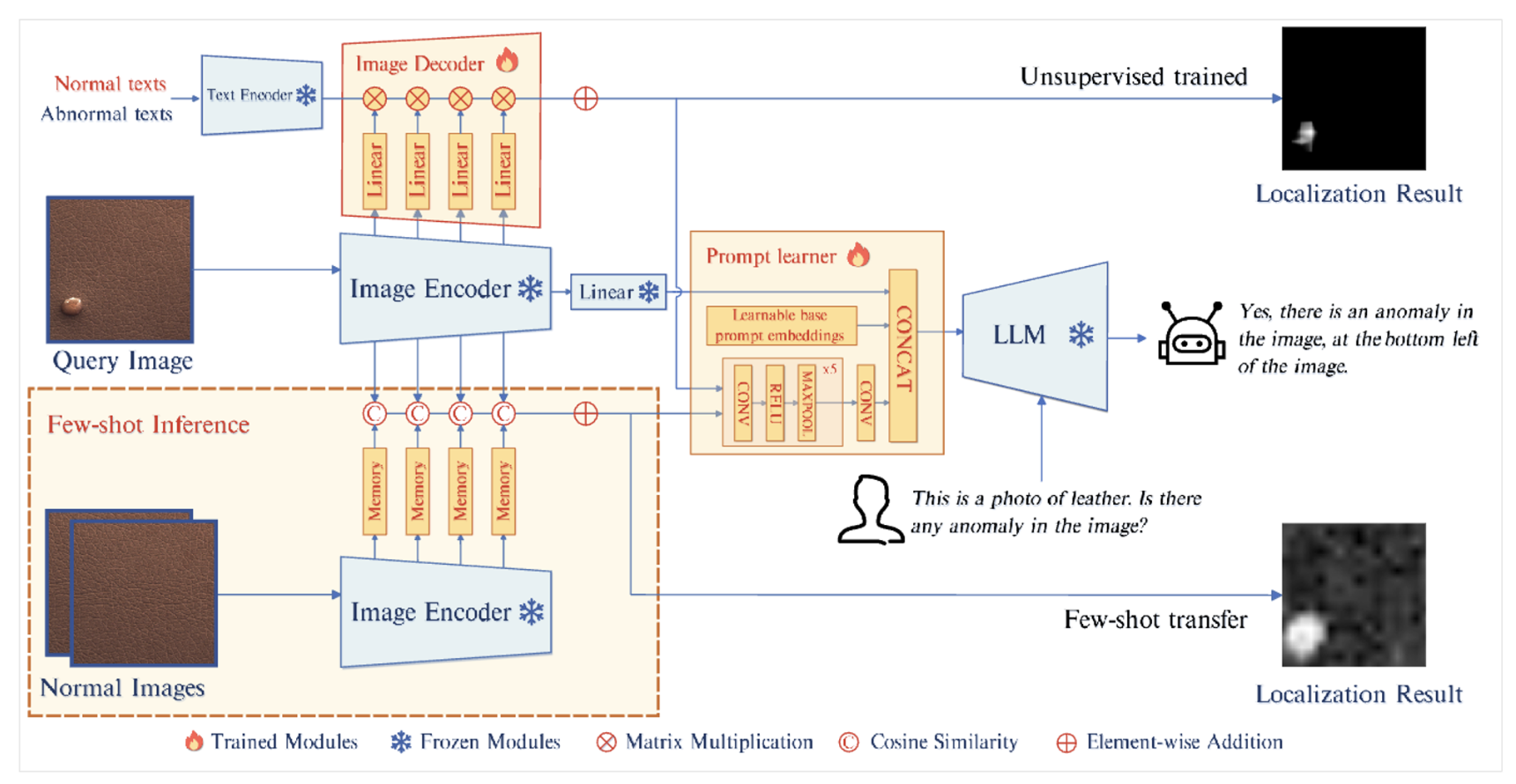
- query image가 주어지면 Image Encoder는 final features 를 추출함.
- 는 linear layer를 통과해 를 얻는다.
- unsupervised setting에서, 이미지 인코더의 중간 레이어에서 추출된 patch-level features는, 텍스트 정보와 함께 디코더로 들어간다. 그 디코더는 pixel-level anomaly localization results를 생성한다.
- few-shot setting에서, 쿼리 이미지의 패치와, 쿼리 이미지의 패치와 가장 유사한 memory banks 에 저장된 normal samples의 patch-level features와, 거리(코사인 유사도)를 계산하여 localization results를 얻는다.
- Localization results 는 prompt learner를 통해 prompt embedding으로 변환되어 LLM의 input으로 들어간다.
- LLM은 image input, prompt embedding, user가 제공한 textual input을 사용하여 이상치를 탐지하고, 이상치의 location과 user를 위한 응답을 생성한다.
3.2 Decoder and Prompt Learner
Decoder
- unsupervised IAD and few-shot IAD를 모두 지원함.
unsupervised IAD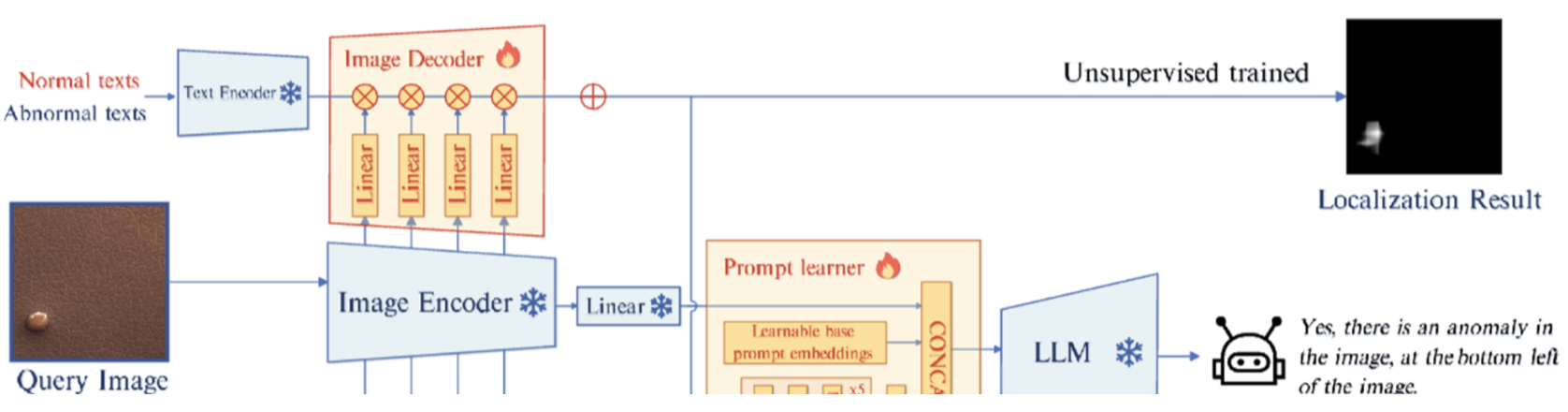
- 자연스러운 접근방법 :
- 먼저 그림에서와 같이 Image Encoder의 4개의 각 i-stage에서 pixel-level의 feature를 뽑아온다. → 그런다음, (정상)와 (이상치) 간의 유사도를 계산한다.
- → 이미지와 텍스트간 정렬이 되지 않음.
- 따라서 intermediate features를 projection 하는 linear layer를 하나 둔다. 그리고 정상 또는 비정상을 represent하는 text 와 intermediate features를 align 한다. →
- localizaion result 는 아래 식으로 얻는다.
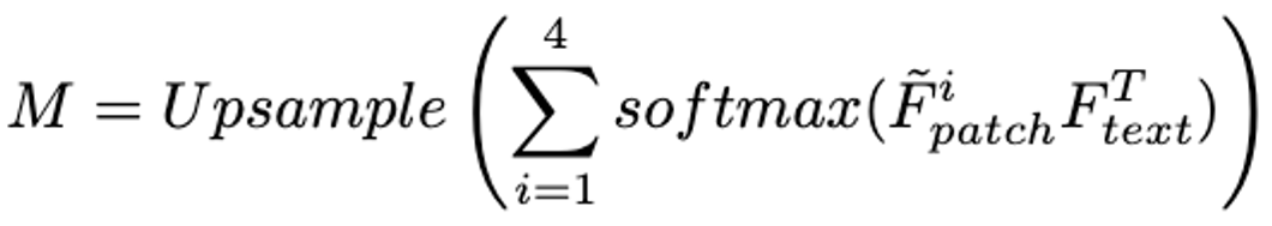
few-shot IAD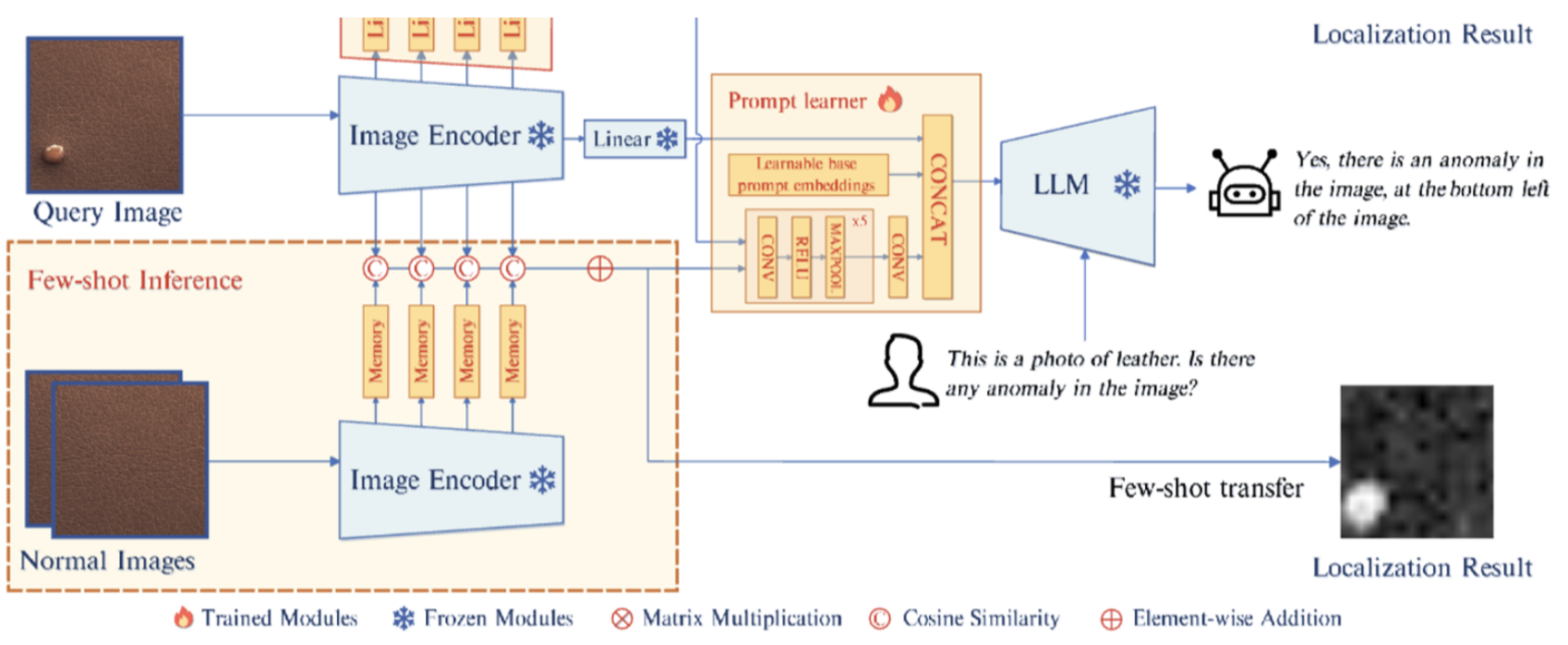
- 같은 Image Encoder를 사용. 똑같이 i-stage마다 intermediate patch-level features를 뽑고 memory banks에 넣는다. →
- patch-level features 의 경우 각 patch와, memory banks에서 가장 유사한 것의 patch 사이의 거리와, localization result M을 얻는다.
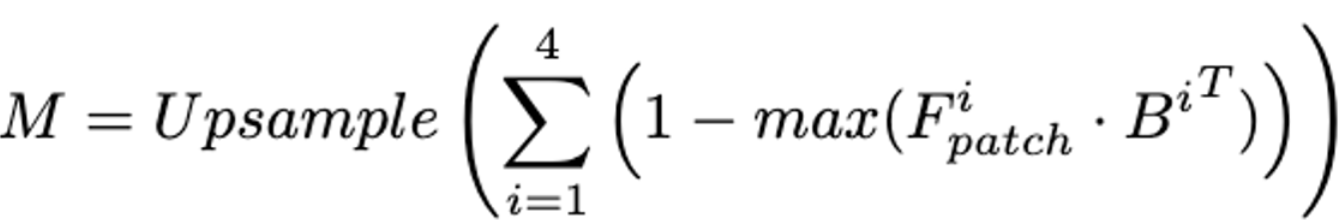
- patch-level features 의 경우 각 patch와, memory banks에서 가장 유사한 것의 patch 사이의 거리와, localization result M을 얻는다.
Prompt Learner
- 이미지의 fine-grained semantic 를 leverage하고, LLM과 decoder의 일관성을 유지하기 위해 Prompt Learner 도입.
- 또한 decoder의 output과는 관련 없는, 학습가능한 prompt embedding을 prompt learner에서 사용하여 IAD task에 대한 추가 정보를 제공한다. 이 prompt embedding은 이미지 정보와 함께 LLM에 주입된다.
- prompt learner는 학습가능한 prompt embedding 와 CNN으로 이루어져 있다. CNN은 localization result M을 prompt embedding인 으로 변환한다. 와 는 Concat되어 를 형성하고, 이는 LLM에 결합되어 들어간다.
3.3 Data for Image-Text Alignment
Anomaly Simulation
- Cut-paste는 무작위로 특정 이미지에서 crop한 부분을 붙여 넣는 방법인데, 너무 눈에 띄게 이상치가 생기게 된다. → simulated anomalous imges들은 IAD 성능을 크게 향상시킨다.
- Poisson edit method는 자연스럽게 이상치를 생성하는 방법임.

Question and Answer Content
-
LVLM에서 prompt tuning을 수행하기 위해 simulated anomalous imges에 상응하는 text 쿼리를 생성한다. 이 쿼리는 두가지 요소로 구성된다.
- 첫번째는 “This is a photo of leather, which should be brown and without any damage, flaw, defect, scratch, hole or broken part” 와 같이 input 이미지에 존재하는 객체와 그 객체의 예상 특성을 묘사해야한다.
- 두번째는 “Yes, there is an anomaly in the image, at the bottom left of the image. or No, there are no anomalies in the image.”와 같이 input image에 이상치가 존재하는지에 대한 쿼리이다. 이 쿼리는 이상치 개수와, 위치 정보에 대한 text가 포함한다. 위치 정보는 아래 그림을 보면된다.

- 이미지에 대한 content는 LVLM에 이미지의 foundational knowledge를 제공하여 모델이 image를 더 잘 이해하도록 돕는다. 하지만 실제 사용자는 이 descriptive input을 생략할 수 있으며, 그래도 모델은 image input만으로도 여전히 IAD task를 수행할 수 있다.
-
prompt는 아래와 같은 형식으로 LLM에 들어간다.
-
###Human <Img><Img> [Image Description] Is there any anomaly in the image?
###Assistant: -
는 Image Encoder와 linear Layer를 통과한 image embedding, 는 prompt learner가 생성한 prompt embedding이다. 또한 [Image Description]은 image의 textual description이다.
3.4. Loss Functions
- 세 loss를 사용. Cross-Entropy Loss, Focal Loss, Dice Loss.
- Focal Loss, Dice Loss는 디코더의 pixel-level localization 성능을 향상시키기위한 중요한 역학을 함.
Cross-Entropy Loss
- 모델이 생성한 text sequence와, target text sequence 사이의 loss. 가 i-th 토큰의 실제 레이블, 는 모델의 출력 확률.
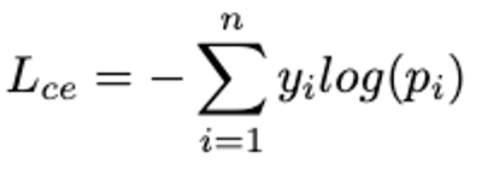
Focal Loss
-
Object Detection 또는 semantic segmentation 에서 자주 사용되는 Loss, 이는 를 도입하여 맞추기 어려운 샘플에 대한 가중치를 더 두는 방법.
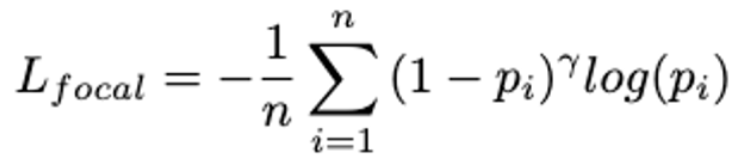
-
n 은 pixel의 전체 개수, 는 output 확률값.
Dice Loss
-
semantic segmentation에서 자주 쓰이는 loss.
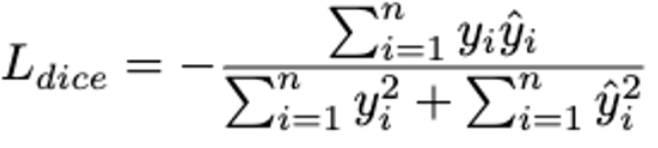
-
n은 전체 픽셀 수, 가 decoder가 뱉는 output, 가 true 값
최종 Loss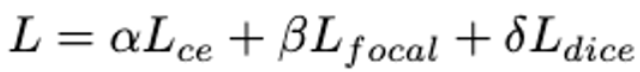
- 각 loss 앞에 가중치 coefficient를 둬서 최종 Loss 구성
4. Experiments
Datasets
- MVTec AD, ViSA 데이터 사용
- 훈련시에는 정상이미지만 사용하고 테스트 시에는 정상, 이상치 모두 사용.
- 이전 IAD와 동일한 실험 환경을 위해 훈련시 정상이미지만 사용함.
Evaluation Metrics
- 기존의 IAD 방법에서의 Metric으로는 Image-AUC , Pixel-AUC(AORUC)가 있는데, anomalyGPT는 thresholds가 필요없다. 따라서 image-level accuary를 사용하여 이 방법을 평가한다.
Implementation Details
- ImageBind-Huge를 이미지 인코더로 사용하고, Vicuna-7B를 inference LLM으로 사용한다. PandaGPT의 pre-trained parameter를 사용하여 모델을 초기화 함.
- image resolution을 224x224로 고정하고, 8,16,24,32 의 layer의 output을 image decoder에 주입한다.
- RTX-3090 2대를 사용. 16 배치, 50 에포크, PandaGPT의 pre-training data와 anomaly image-text data를 교대로 사용함.
- decoder와 prompt learner만 학습 하고 나머지는 freeze
4.1. Quantitative Results
Few-Shot Industrial Anomaly Detection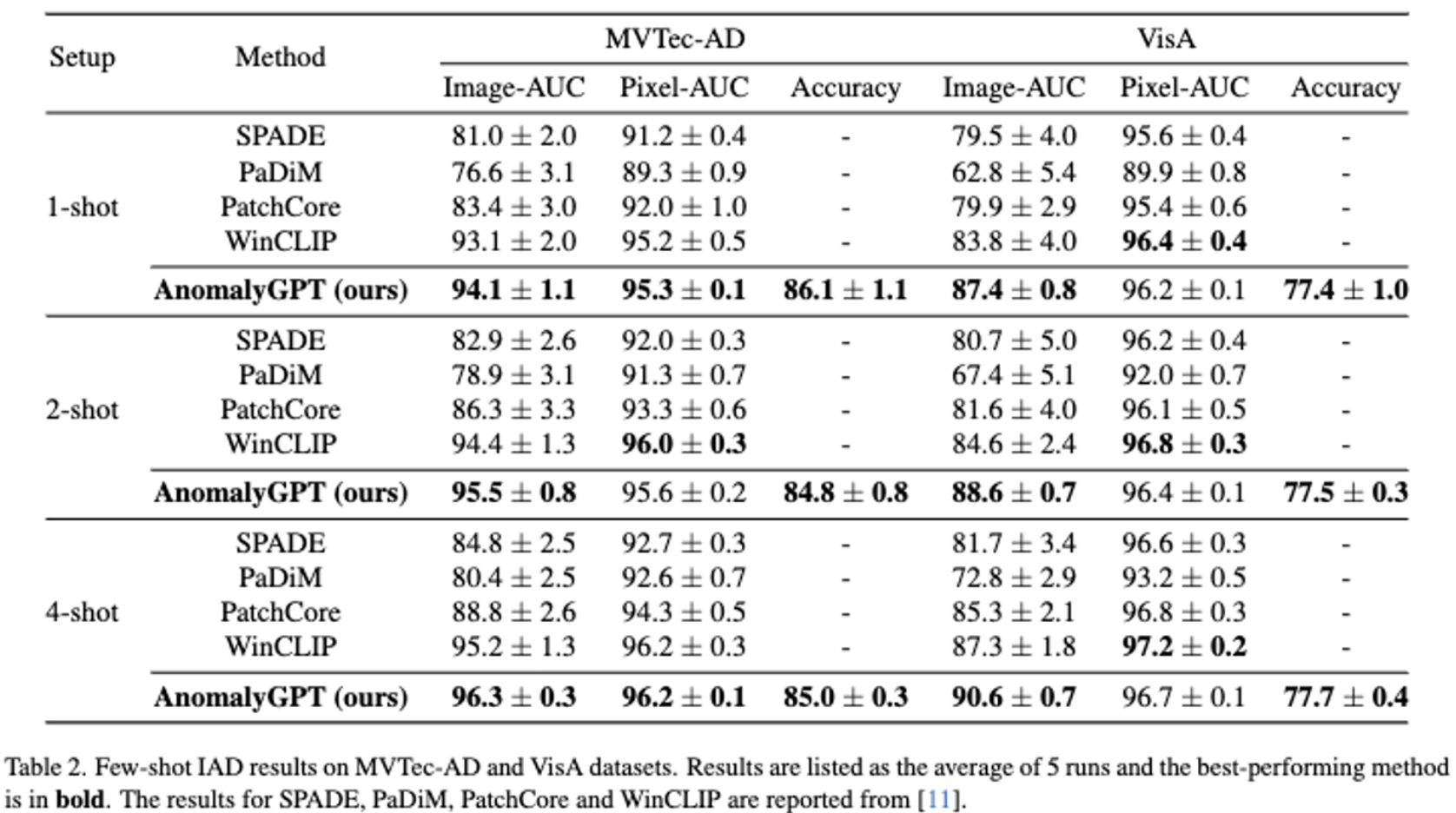
- image-AUC 에서 특히 좋은 성능을 보이고, pixel-AUC에서도 경쟁할만한 성능을 보인다.
Unsupervised Industrial Anomaly Detection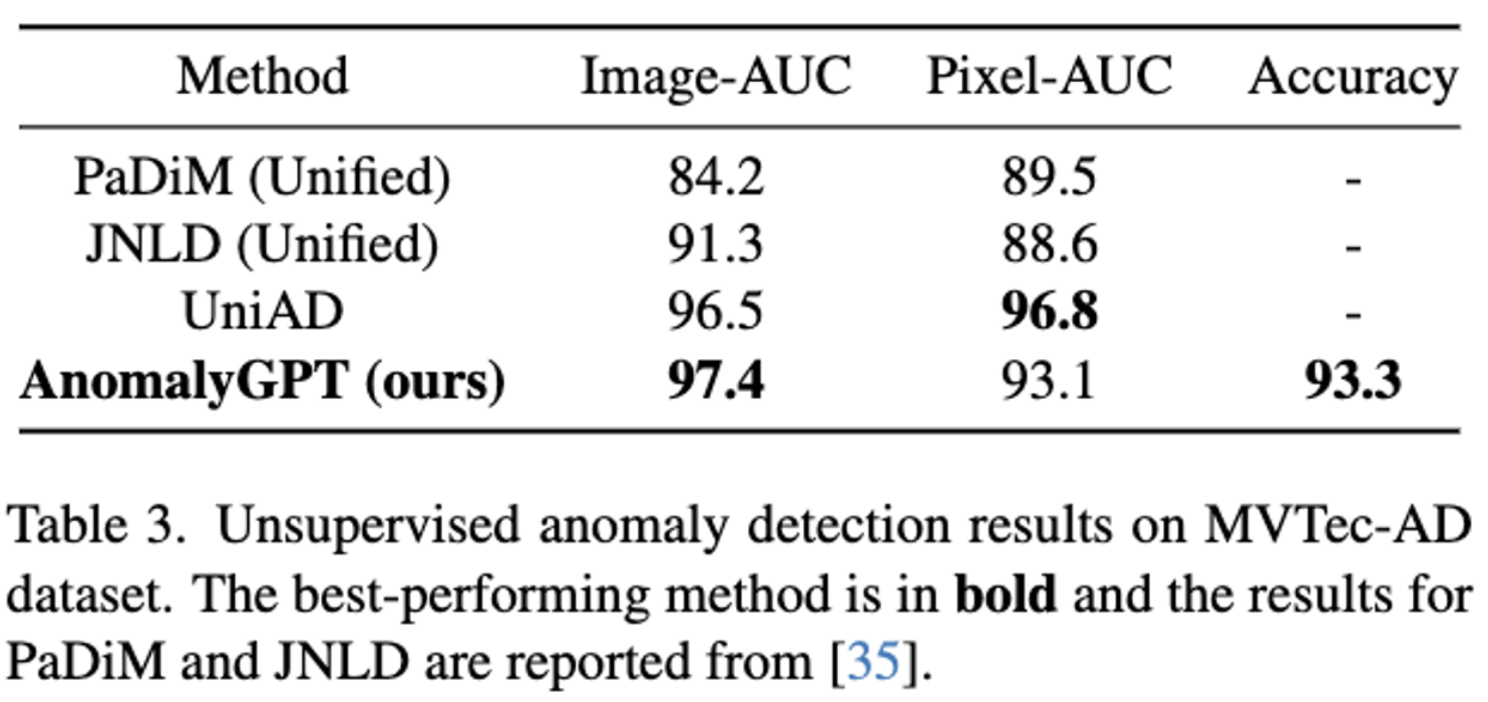
- 모든 class에 대해서 단일 모델을 학습하는 세팅의 모델인 UniAD와 비교하고, 동일한 세팅의 PaDiM과 JNLD의 성능과 비교.
4.2. Qualitative Examples
- anomalyGPT는 이상징후를 탐지하고, location을 찾아내며 (bottom, Top left 등), pixel 단위의 localization 또한 가능하다. 또한 user는 multi-turn 대화가 가능하다.
unsupervised anomaly detection
1-shot in-context learning
- 1-shot in-context learning setting에서는 학습과정이 없기 때문에 모델의 localization 성능이 unsupervised 세팅(학습함)에 비해서 약간 저하되는것을 볼 수 있다.

4.3. Ablation Studies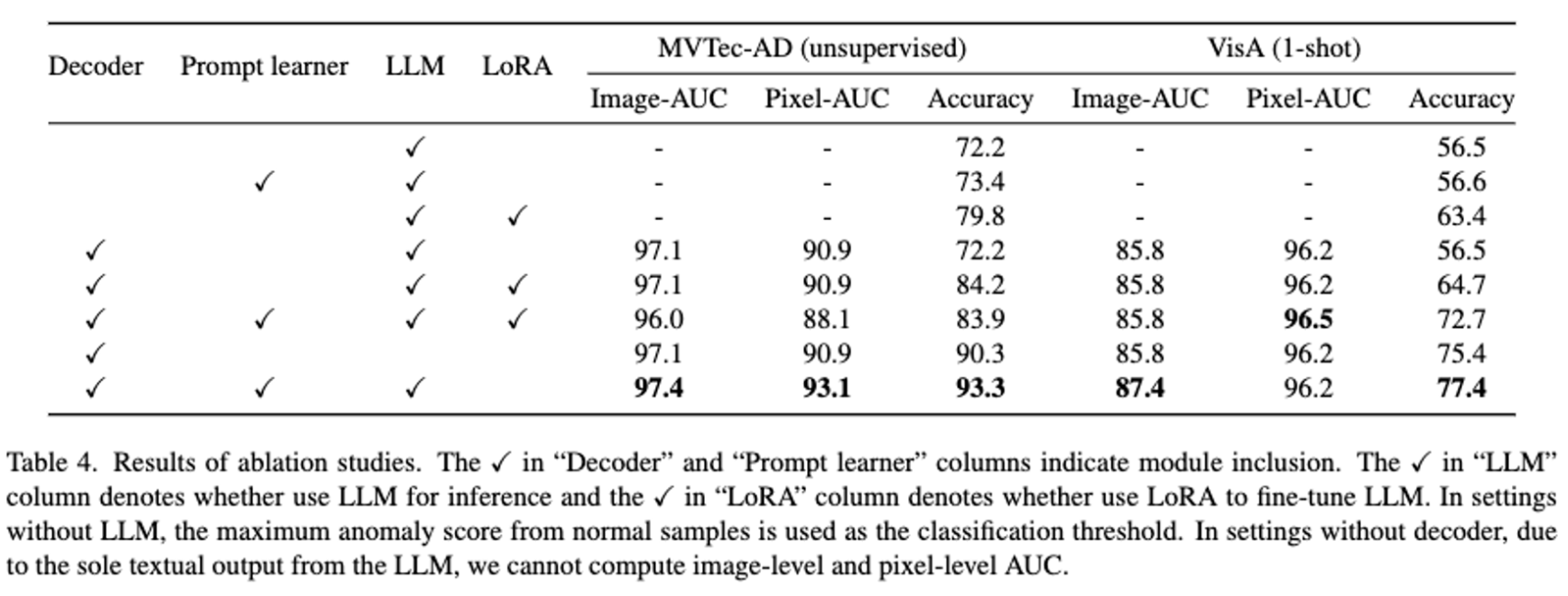
- decoder, prompt learner, inference를 위한 LLM 사용, Lora를 사용한 튜닝
- MVTec-AD 에서는 unsupervised 세팅에서의 성능, VisA에서는 one-shot performance를 계산
- decoder가 있는것이 pixel-level anomaly localization 성능이 좋음. thresholds를 설정하지 않은 LLM 은 더 높은 성능을 보이고 추가적인 기능 또한 할 수 있다. 또한 prompt tuning은 Lora 보다 성능이 뛰어남.
5. Conclusion
- AnomalyGPT는 threshold 없이 이상치를 감지할 수 있다. 또한 multi-turn dialogues 도 가능하다. few-shot in-context learning에서 좋은 성능을 보여준다.
추가 예시

Code
