일반적인 생각
-
일반적으로 COUNT()는 빠를것으로 기대하지만 SELECT 보다 느린 경우가 있다.
-
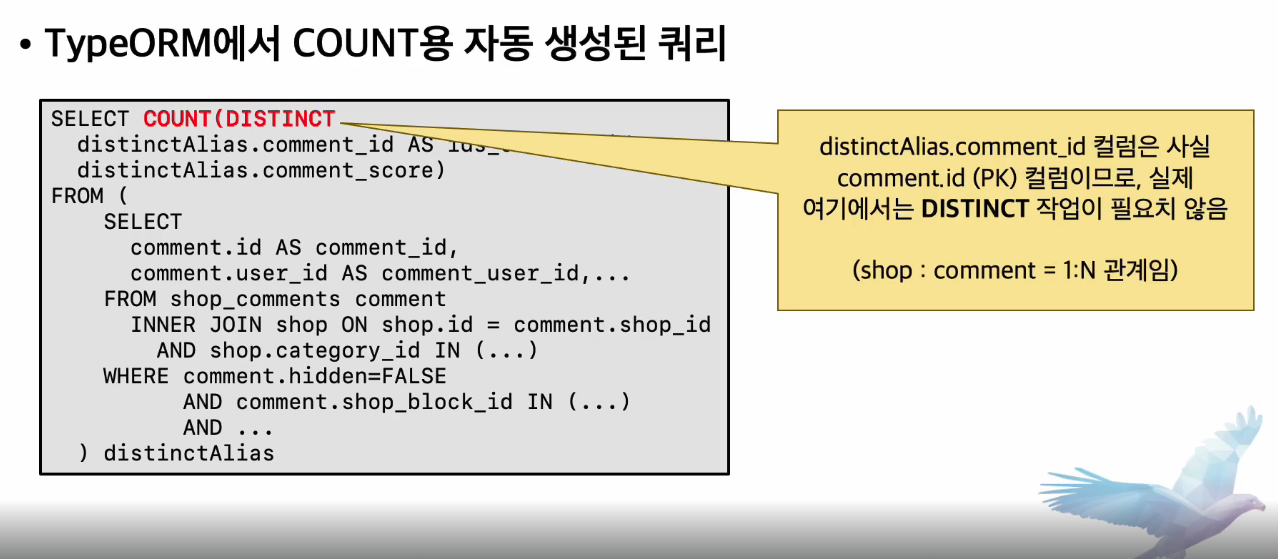
ORM에서 자동 생성된 쿼리는 훨씬 부하가 큰 COUNT(DISTINCT)를 실행하기도 한다.
-
SELECT 는 LIMIT와 동시에 사용되지만, COUNT()는 단독으로 사용된다. 따라서 데이터를 더 많이 읽는 경우가 생긴다.
성능 개선하기
- 커버링인덱스 사용한다. 그러나 where 조건에 많은 컬럼들이 사용되는데 이것들을 인덱스에 다 추가하게 되면, 커버링인덱스르 누리는 장점을 넘어서는 단점을 얻을 수도 있다.

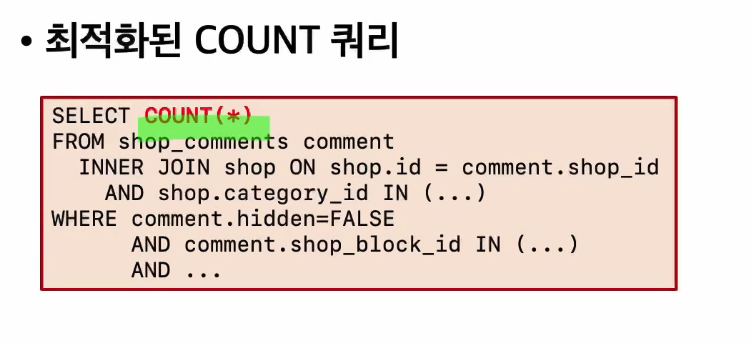
COUNT(*) vs COUNT(DISTINCT)
- COUNT(*)는 레코드 건수만 확인하지만, COUNT(DISTINCT)는 임시테이블로 중복을 제거 후 건수를 확인한다.
COUNT(*) 튜닝
-
최고의 튜닝은 COUNT(*) 자체를 사용하지 않는 것
- 전체 결과 건수 확인 쿼리 제거- 페이지 번호 없이, "이전" "이후" 페이지 이동
-
쿼리를 제거할 수 없다면, 대략적 건수 활용
- 부분 레코드 건수 조회- 임의의 페이지 번호는 표기: 첫 페이지에서 10개 페이지 표시 후, 실제 해당 페이지로 이동하면서 페이지 번호 보정
- 통계 정보 활용
-
제거 대상
- WHERE 조건없는 COUNT(*)- WHERE 조건에 일치하는 레코드 건수가 많은 COUNT(*)
-
인덱스를 활용하여 최적화 대상
- 정확한 COUNT(*)가 필요한 경우- COUNT(*) 대상 건수가 소량인 경우
- WHERE 조건이 인덱스로 처리될 수 있는 경우
COUNT(DISTINCT) 튜닝