Redis 란 ?
- redis란 Remoete Dictionary Server의 약자로 캐시 서버로 널리 쓰이고 있는 Key - Value 기반의 In-Memory 데이터 저장소 즉 비관계형 데이터베이스이다. 즉, 사용에 따라 데이터베이스로도 사용될 수 있으며, Cache로도 사용될 수 있다.
- Key - Value 기반이기 때문에 쿼리를 따로 할 필요 없이 결과를 바로 가져올 수 있다.
- 또한 디스크에 데이터를 쓰는 구조가 아니라 메모리에서 데이터를 처리하기 때문에 속도가 상당히 빠르다는 특징을 가지고 있다.
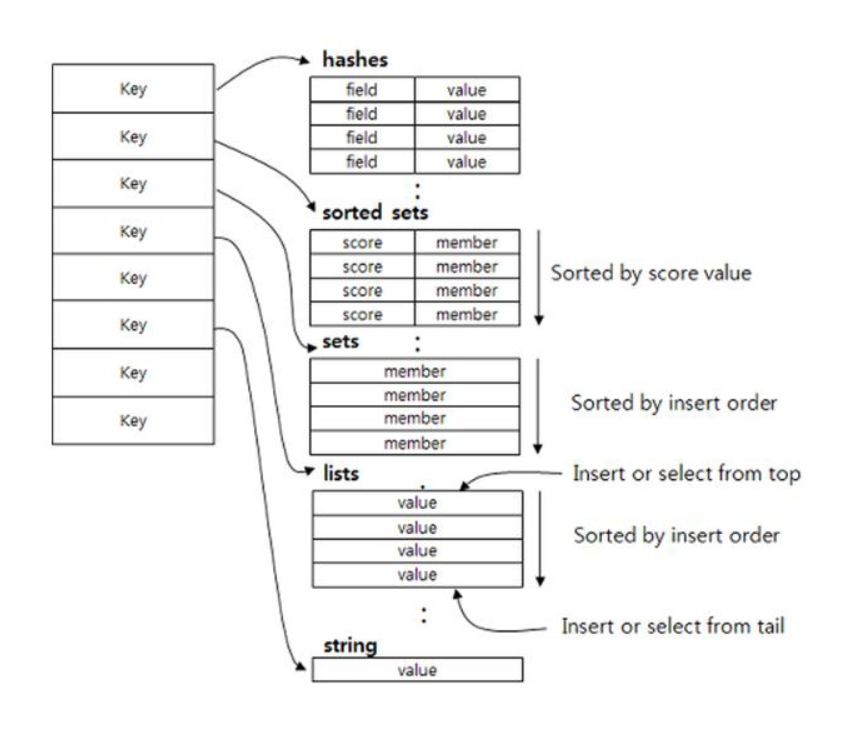
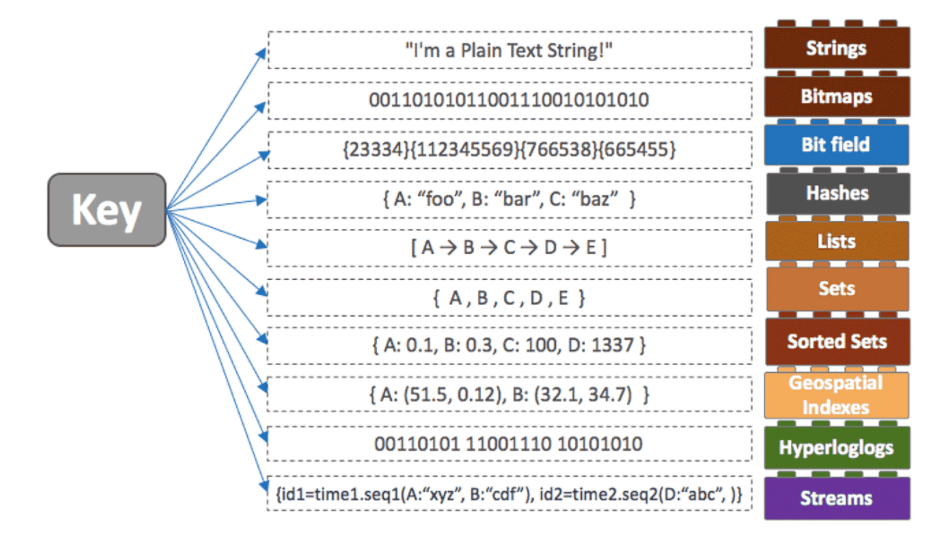
Redis의 데이터 구조(Collection)
| 데이터 구조 | 설명 |
|---|---|
| String | 가장 일반적인 형태로, key - value 로 저장하는 형태이다. |
| List | Array 형식의 데이터 구조로 List를 사용하면 처음과 끝에 데이터를 넣고 빼는것은 속도가 빠르지만 중간에 데이터를 삽입할 때는 어려움이 있다. |
| Set | 순서가 없는 Strings 데이터 집합으로 Sets 에서는 중복된 데이터는 하나로 처리하기 때문에, 중복에 대한 걱정을 할 필요가 없다. |
| Sorted Set | 위의 Sets와 같은 구조이지만 Score를 통해 순서를 정할 수 있다. Sorted Sets를 사용하면 Leaderboard와 같은 기능을 쉽게 구현할 수 있다. |
| Hashes | Key-Value 구조를 여러개 가진 object 타입을 저장하기 좋은 구조이다. |
Redis의 특징
- 디스크가 아닌 메모리 기반의 데이터 저장소이다. (In-Memory data structure store)
- 인메모리 기반이기 때문에 저장용량은 적지만 속도는 훨씬 빠르다는 장점을 가지고 있다.
- NoSQL & Cache 솔루션이며 메모리 기반으로 구성된다.
- 명시적으로 삭제, expire를 설정하지 않으면 데이터는 삭제되지 않는다. (영구적 보존)
- 여러대의 서버 구성이 가능하다 ( 마스터 - 슬레이브 구조 )
- 데이터베이스로 사용될 수도 있으며, Cache로도 사용될 수 있다.
Redis의 장점
-
- 리스트, 배열과 같은 데이터를 처리하는데 유용하다.
-
value 값으로 문자열, 리스트, Set, Sorted set, Hash 등 여러 데이터 형식을 지원.
-
따라서 다양한 방식으로 데이터를 활용할 수 있다.
-
리스트형 데이터 입력과 삭제가 MySQL에 비해서 10배정도 빠르다고 한다.
-
- 메모리를 활용하면서 영속적인 데이터 보존
-
명령어로 명시적으로 삭제, expires를 설정하지 않으면 데이터가 삭제되지 않는다.
-
스냅샷(기억장치) 기능을 제공하여 메모리의 내용을 *.rdb 파일로 저장하여 해당 시점으로 복구할 수 있다.
-
- Redis Server는 1개의 싱글 쓰레드로 수행되며, 따라서 서버 하나에 여러개의 서버를 띄우는 것이 가능하다.
-
Single Thread로 동작하기 때문에 동시에 처리할 수 있는 명령어는 하나이다.
-
Master - Slave 형식으로 구성이 가능함
-
데이터 분실 위험을 없애주는 것이 바로 위 Master - Slave 방식이다.
Redis 기본 명령어
String
-
set
- set key value [EX seconds][PX milliseconds] [NX|XX]
- NX 옵션은 데이터베이스에 같은 키가 없을 경우에만 저장된다
- 단일 명령으로 데이터가 있는지 확인하고 저장까지 가능하기 때문에 lock 처리에 주로 사용된다.
- XX 옵션은 데이터베이스에 이미 키가 존재하는 경우에만 저장된다.
- set은 redis에 key-value 매핑을 설정하기 위해 사용하며 EX나 PX 등을 통해 해당 매핑에 expire(유효기간)을 설정할 수 있다.
- EX 옵션은 지정한 초(second) 이후에 데이터가 지워지는 옵션으로 만료 시간을 갖는 데이터를 저장할 때 유용하게 사용된다.
- PX 옵션은 지정한 밀리초(millisecond) 이후에 데이터가 지워지기 때문에 세밀한 만료 시간을 지정할 때 사용한다.
-
get
- get [key]
- key에 해당하는 value를 반환하며, 존재하지 않는 경우 (nil)을 반환한다. redis는 key들을 해시하므로 시간복잡도는 O(1)로 고정된다.
-
incr, decr
- incr [key], decr [key]
- incr과 decr 각각 key에 해당하는 value를 숫자로 평가 가능한지 판단한 이후, 1 증가시키거나 감소시킨다.
- value를 숫자로 평가할 수 없는 경우 (error) ERR value is not an integer or out of range 메세지를 반환하며 에러가 발생한다.
-
exists
- exists [key ...]
- 1개 이상의 key들을 받아 각각 redis에 존재하는지 검사하고 존재하는 매핑의 수를 반환한다.
- exists 예제
127.0.0.1:6379> set b 3
OK
127.0.0.1:6379> exists a
(integer) 1
127.0.0.1:6379> exists a b
(integer) 2
127.0.0.1:6379> exists a b abc cde q s
(integer) 2- del
- del [key ...]
- 1개 이상의 key들을 받아 해당하는 매핑을 제거하고 제거한 매핑의 수를 반환한다.
del 사용 예제
127.0.0.1:6379> set c 5
OK
127.0.0.1:6379> del a
(integer) 1
127.0.0.1:6379> del b c d e
(integer) 2Lists
- list 데이터 타입은 배열(Array)과 비슷한 데이터 구조로 list타입은 하나의 key에 여러개의 value를 저장할 수 있다.
| 명령어 | 내용 |
|---|---|
| LPUSH | 키에 저장된 목록의 맨 좌측에 지정된 값을 모두 삽입한다. 기존에 키가 없었다면 빈 목록으로 생성된 후 작업이 수행된다. |
| RPUSH | 키에 저장된 목록의 맨 우측에 지정된 값을 모두 삽입한다 . 기존에 키가 없었다면 빈 목록으로 생된 후 작업이 수행된다. |
| LPUSHX | 키가 이미 있고 목록이 있는 경우에만 키에 저장된 목록의 맨 좌측에 값을 삽입한다. ( 처음부터 사용할 수 없음 ) |
| RPUSHX | 키가 이미 있고 목록이 있는 경우에만 키에 저장된 목록의 맨 우측에 값을 삽입한다. ( 처음부터 사용할 수 없음 ) |
| LPOP | 맨 좌측에 있는 요소를 제거후 제거한 값을 리턴해준다. |
| RPOP | 맨 우측에 있는 요소를 제거후 제거한 값을 리턴해준다. |
| LLEN | 키에 저장된 list의 길이를 반환 , 키가 없으면 빈목록으로 인식하고 0을 반환 , 만약 키가 list가 아니라면 오류를 반환 |
| LREM | 키에 저장된 목록중에서 값과 동일한 요소들을 삭제하는데 count가 0보다 작다면 우측부터 , 크다면 좌측부터 , 같다면 모든 값들을 삭제한다. |
| LSET | 해당 index에 대한 값을 입력받은 값으로 변경한다. |
| LRANGE | list에 담고있는 요소들의 값들을 startIndex, endIndex를 통해 목록을 보여준다. |
| RPOPPUSH | RPOP 후 LPUSH를한다. return은 POP해서 PUSH로 넣은 요소를 출력한다. |
Sets
-
Sets 자료구조는 유일한 값들의 모임인 자료구조로 순서는 유지되지 않는 Strings의 집합 자료구조이다.
-
또한 Set이기 때문에 동일한 value를 추가해도 추가되지 않기 때문에 같은 value 2개가 공존하지 않는다.
- Sets에서는 집합이라는 의미에서 value를 member라고 지칭한다.
-
Sets 관련 명령어
- SET : SADD, SMOVE
- GET : SMEMBERS, SCARD, SRANDMEMBER, SISMEMBER, SSCAN
- POP : SPOP
- REM : SREM
- 집합연산 : SUNION, SINTER, SDIFF, SUNIONSTORE, SINTERSTORE, SDIFFSTORE
| 명령어 | 문법 | 설명 |
|---|---|---|
| SADD | SADD key member [member ...] | 집합에 member를 추가 |
| SREM | SREM key member [member ...] | 집합에서 member를 삭제 |
| SMEMBERS | SMEMBERS key | 집합의 모든 member를 조회 |
| SCARD | SCARD key | 집합에 속한 member의 갯수를 조회 |
| SUNION | SUNION key [key ...] | 합집합을 구함 |
| SINTER | SINTER key [key ...] | 교집합을 구함 |
| SDIFF | SDIFF key [key ...] | 차집합을 구함 |
| SUNIONSTORE | SUNIONSTORE dest_key src_key [src_key ...] | 합집합을 구해서 새로운 집합에 저장 |
| SINTERSTORE | SINTERSTORE dest_key src_key [src_key ...] | 교집합을 구해서 새로운 집합에 저장 |
| SDIFFSTORE | SDIFFSTORE dest_key src_key [src_key ...] | 차집합을 구해서 새로운 집합에 저장 |
| SISMEMBER | SISMEMBER key member | 집합에 member가 존재하는지 확인 |
| SMOVE | SMOVE src_key dest_key member | 소스 집합의 member를 목적 집합으로 이동 |
| SPOP | SPOP key [count] | 집합에서 무작위로 member를 가져옴 |
| SRANDMEMBER | SRANDMEMBER key [count] | 집합에서 무작위로 member를 조회 |
| SSCAN | SSCAN key cursor [MATCH pattern][COUNT count] | member를 일정 단위 갯수 만큼씩 조회 |
Sorted Sets (ZSets)
- Set + Hash 와 비슷한 데이터 타입으로 set과 동일하게 유일한 항목들로 구성되어 있으며 모든 항목들은 score 라는 floating point value를 가진다. (score를 통해 정렬됨)
- GT & LT 옵션은 기존의 값이 존재하지 않으면 그냥 추가하지만, 만약 기존 값이 존재한다면 값을 비교하여 연산을 진행한다.
- GT : 지금 추가하려는 멤버의 스코어가 더 크면 추가 (없으면 그냥 추가)
- LT : 지금 추가하려는 멤버의 스코어가 더 작으면 추가 (없으면 그냥 추가)
| 명령어 | 문법 | 설명 |
|---|---|---|
| ZADD | ZADD key [NX|XX] [GT|LT] [CH][INCR] score member [score member ...] | 해당 Key에 주어진 score와 함께 member를 추가 |
| ZREM | ZREM key member | 해당 Key에서 주어진 member를 제거 |
| ZCARD | ZCARD key | 주어진 Key의 Member의 수 반환 |
| ZINCRBY | ZINCRBY key increasement member | 멤버의 Score를 Increment만큼 증가 |
| ZCOUNT | ZCOUNT key min max | 주어진 범위안에 있는 score에 해당하는 멤버의 수를 반환 |
| ZRANK | ZRANK key member | 주어진 Member의 Rank를 반환 |
| ZSCORE | ZSCORE key member | 주어진 Member의 Socre를 반환 |
| ZRANGE | ZRANGE key start stop [WITHSCORES] | start과 stop사이의 member와 순위를 위한 score를 옵션으로 리턴 |
| ZREVRANGE | ZREVRANGE 'key-name' start stop [WITHSCORES] | start과 stop사이의 member와 순위를 위한 score를 내림차순으로 리턴 |
Hash

- Hash는 field - Value 쌍을 사용한 일반적인 해시이다. key에 대한 field의 갯수에는 제한이 없으므로 여러 방법으로 사용이 가능하다.
- field와 value로 구성된다는 면에서 hash는 RDB의 table과 비슷하다. Hash Key는 table의 PK, field는 column, Value는 Value로 볼 수 있다.
| 명령어 | 문법 | 설명 |
|---|---|---|
| HSET | HSET key field value [field value ...] | HSET으로 KEY에 저장된 해시 필드를 하나 또는 여러개 설정할 수 있다. |
| HMSET | HMSET key field value [field value ...] | HSET으로 KEY에 저장된 해시 필드를 여러개 설정할 수 있다. |
| HGET | HGET key field | key field에 저장된 값 조회하는 명령어이다. |
| HMGET | HMGET key field [field ...] | key field에 저장된 값 조회하는 명령어이다. |
| HGETALL | HGETALL key | key에 매핑되는 모든 필드와 그 값들을 조회한다. |
| HKEYS | HKEYS key | key에 저장된 모든 필드명을 가져온다. |
| HVALS | HVALS key | key에 저장된 모든 값들을 가져온다. |
| HEXISTS | HEXISTS key field | 특정 필드가 존재하는지 확인하는 명령어로 존재한다면 1을 존재하지 않으면 0을 리턴한다. |
| HSETNX | HSETNX key field value | Key에 필드가 아직 존재하지 않는 경우에만 저장한다. |
| HDEL | HDEL key field [field ...] | Key에 저장된 필드의 값을 삭제하는 명령어이다. |
| HINCRBY | HINCRBY key field increment | Key에 저장된 필드의 값을 증가 혹은 감소시킨다. |
| HINCRBYFLOAT | HINCRBYFLOAT key field increment | Key에 저장된 필드의 값을 증가 혹은 감소시킨다. (소수점 단위) |
| HLEN | HLEN key | Key에 저장된 필드의 개수를 리턴한다. |
| HSTRLEN | HSTRLEN key field | Key 필드에 저장된 Value의 길이를 리턴한다. |

Go-getter Developer